Skapa anpassade modellserverslutpunkter
Den här artikeln beskriver hur du skapar modellserverslutpunkter som hanterar anpassade modeller med databricks-modellservering.
Modellservern innehåller följande alternativ för att skapa slutpunkter:
- Användargränssnittet för servering
- REST-API
- SDK för MLflow-distributioner
Information om hur du skapar slutpunkter som hanterar generativa AI-modeller finns i Skapa grundmodell som betjänar slutpunkter.
Krav
- Din arbetsyta måste finnas i en region som stöds.
- Om du använder anpassade bibliotek eller bibliotek från en privat speglingsserver med din modell kan du läsa Använda anpassade Python-bibliotek med modellservern innan du skapar modellslutpunkten.
- Om du vill skapa slutpunkter med MLflow Deployments SDK måste du installera MLflow-distributionsklienten. Installera den genom att köra:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Åtkomstkontroll
Information om alternativ för åtkomstkontroll för modell som betjänar slutpunkter för slutpunktshantering finns i Hantera behörigheter för din modell som betjänar slutpunkten.
Du kan också lägga till miljövariabler för att lagra autentiseringsuppgifter för modellservering. Se Konfigurera åtkomst till resurser från modellserverslutpunkter
Skapa en slutpunkt
Serveringsgränssnitt
Du kan skapa en slutpunkt för modell som betjänar med användargränssnittet för servering .
Klicka på Servering i sidopanelen för att visa användargränssnittet för servering.
Klicka på Skapa serverdelsslutpunkt.
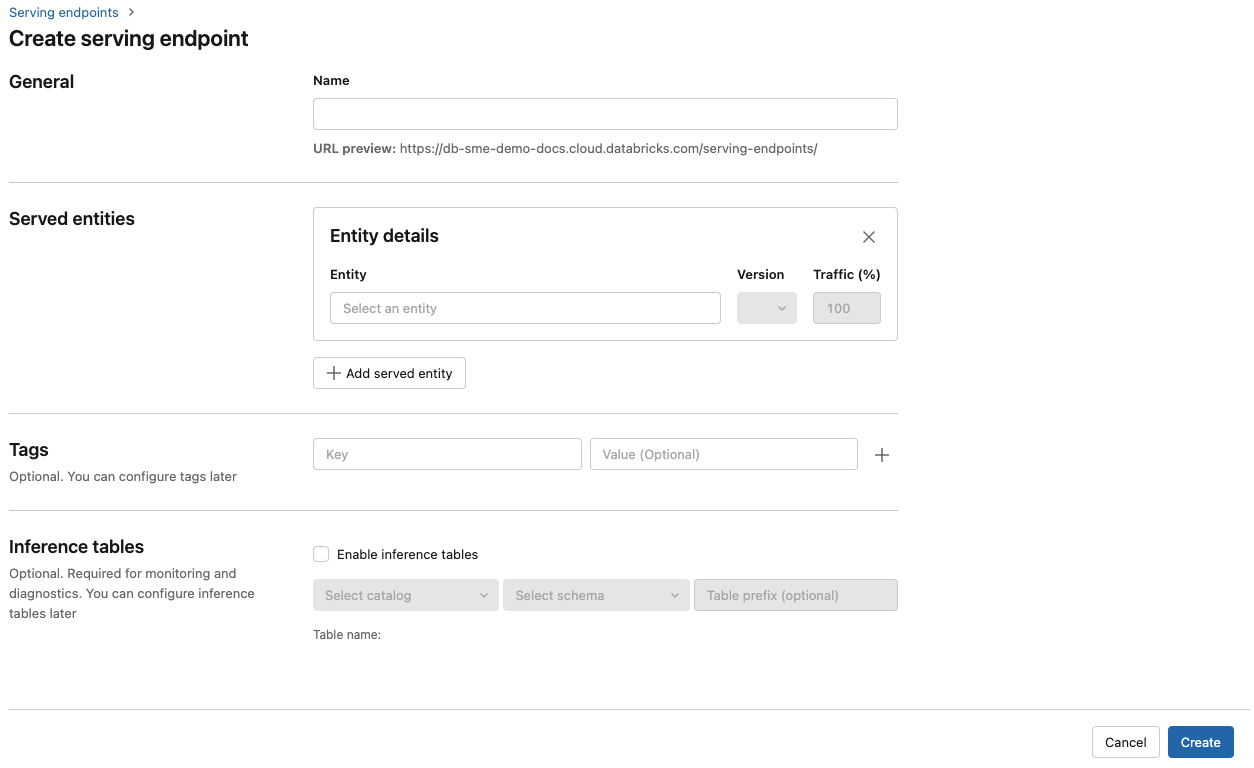
För modeller som registrerats i arbetsytans modellregister eller modeller i Unity Catalog:
I fältet Namn anger du ett namn för slutpunkten.
I avsnittet Serverade entiteter
- Klicka i fältet Entitet för att öppna formuläret Välj hanterad entitet.
- Välj den typ av modell som du vill hantera. Formuläret uppdateras dynamiskt baserat på ditt val.
- Välj vilken modell och modellversion du vill tillhandahålla.
- Välj procentandelen trafik som ska dirigeras till din betjänade modell.
- Välj vilken storleksberäkning som ska användas. Du kan använda CPU- eller GPU-beräkningar för dina arbetsbelastningar. Mer information om tillgängliga GPU-beräkningar finns i GPU-arbetsbelastningstyper .
- Välj vilken storleksberäkning som ska användas. Du kan använda CPU- eller GPU-beräkningar för dina arbetsbelastningar. Mer information om tillgängliga GPU-beräkningar finns i GPU-arbetsbelastningstyper .
- Under Beräkna utskalningväljer du storleken på beräkningsskalningen som motsvarar antalet begäranden som den här hanterade modellen kan bearbeta samtidigt. Det här talet ska vara ungefär lika med QPS x modellkörningstid.
- Tillgängliga storlekar är Små för 0–4 begäranden, Mellan 8–16 begäranden och Stor för 16–64 begäranden.
- Ange om slutpunkten ska skalas till noll när den inte används.
Klicka på Skapa. Sidan Serveringsslutpunkter visas med tillståndet Serveringsslutpunkt som visas som Inte redo.
REST-API
Du kan skapa slutpunkter med hjälp av REST-API:et. Se POST /api/2.0/serving-endpoints för slutpunktskonfigurationsparametrar.
I följande exempel skapas en slutpunkt som hanterar den första versionen av ads1-modellen som är registrerad i Unity Catalog-modellregistret. Om du vill ange en modell från Unity Catalog anger du det fullständiga modellnamnet, inklusive den överordnade katalogen och schemat, till exempel catalog.schema.example-model.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Följande är ett exempelsvar. Slutpunktens config_update tillstånd är NOT_UPDATING och den betjänade modellen är i ett READY tillstånd.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "catalog.schema.my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
SDK för MLflow-distributioner
MLflow-distributioner tillhandahåller ett API för att skapa, uppdatera och ta bort uppgifter. API:erna för dessa uppgifter accepterar samma parametrar som REST-API:et för att betjäna slutpunkter. Se POST /api/2.0/serving-endpoints för slutpunktskonfigurationsparametrar.
I följande exempel skapas en slutpunkt som hanterar den tredje versionen av my-ads-model modell som är registrerad i Unity Catalog-modellregistret. Du måste ange det fullständiga modellnamnet inklusive överordnad katalog och schema, till exempel catalog.schema.example-model.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
Du kan även:
Aktivera slutsatsdragningstabeller för att automatiskt samla in inkommande begäranden och utgående svar till din modell som betjänar slutpunkter.
GPU-arbetsbelastningstyper
GPU-distributionen är kompatibel med följande paketversioner:
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 och senare
Om du vill distribuera dina modeller med hjälp av GPU:er inkluderar du fältet workload_type i slutpunktskonfigurationen när slutpunkten skapas eller som en uppdatering av slutpunktskonfigurationen med hjälp av API:et. Om du vill konfigurera slutpunkten för GPU-arbetsbelastningar med användargränssnittet Server väljer du önskad GPU-typ i listrutan Beräkningstyp.
{
"served_entities": [{
"entity_name": "catalog.schema.ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
I följande tabell sammanfattas de tillgängliga GPU-arbetsbelastningstyper som stöds.
| GPU-arbetsbelastningstyp | GPU-instans | GPU-minne |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Ändra en anpassad modellslutpunkt
När du har aktiverat en slutpunkt för en anpassad modell kan du uppdatera beräkningskonfigurationen efter behov. Den här konfigurationen är särskilt användbar om du behöver ytterligare resurser för din modell. Arbetsbelastningens storlek och beräkningskonfiguration spelar en viktig roll i vilka resurser som allokeras för att betjäna din modell.
Tills den nya konfigurationen är klar fortsätter den gamla konfigurationen att betjäna förutsägelsetrafik. Det pågår en uppdatering, men det går inte att göra någon annan uppdatering. Du kan dock avbryta en pågående uppdatering från användargränssnittet för servering.
Serveringsgränssnitt
När du har aktiverat en modellslutpunkt väljer du Redigera slutpunkt för att ändra beräkningskonfigurationen för slutpunkten.
Du kan göra följande:
- Välj mellan några arbetsbelastningsstorlekar och automatisk skalning konfigureras automatiskt inom arbetsbelastningsstorleken.
- Ange om slutpunkten ska skalas ned till noll när den inte används.
- Ändra procentandelen av trafiken så att den dirigeras till din betjänade modell.
Du kan avbryta en pågående konfigurationsuppdatering genom att välja Avbryt uppdatering längst upp till höger på slutpunktens informationssida. Den här funktionen är endast tillgänglig i användargränssnittet för servering.
REST-API
Följande är ett exempel på en slutpunktskonfigurationsuppdatering med hjälp av REST-API:et. Se PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
SDK för MLflow-distributioner
SDK:n för MLflow-distributioner använder samma parametrar som REST-API:et, se PUT /api/2.0/serving-endpoints/{name}/config för information om begäran och svarsschema.
Följande kodexempel använder en modell från Unity Catalog-modellregistret:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Bedömning av en modellslutpunkt
Skicka begäranden till den modell som betjänar slutpunkten för att bedöma din modell.
Ytterligare resurser
- Hantera modell som betjänar slutpunkter.
- Externa modeller i Mosaic AI Model Serving.
- Om du föredrar att använda Python kan du använda Databricks realtidsservering av Python SDK.
Notebook-exempel
Följande notebook-filer innehåller olika Databricks-registrerade modeller som du kan använda för att komma igång med modellserverslutpunkter. Ytterligare exempel finns i Självstudie: Distribuera och utföra en förfrågan på en anpassad modell.
Modellexemplen kan importeras till arbetsytan genom att följa anvisningarna i Importera en notebook-fil. När du har valt och skapat en modell från ett av exemplen registrera den i Unity Catalogoch följ sedan arbetsflödet för användargränssnitt steg för modellservering.