Automatisk loggning av Databricks
Den här sidan beskriver hur du anpassar Databricks Autologging, som automatiskt samlar in modellparametrar, mått, filer och ursprungsinformation när du tränar modeller från en mängd populära maskininlärningsbibliotek. Utbildningssessioner registreras som MLflow-spårningskörningar. Modellfiler spåras också så att du enkelt kan logga dem till MLflow Model Registry.
Kommentar
För att aktivera spårningsloggning för generativa AI-arbetsbelastningar stöder MLflow automatisk loggning av OpenAI.
Följande video visar Databricks Autologging med en scikit-learn-modellträningssession i en interaktiv Python-anteckningsbok. Spårningsinformation samlas in automatiskt och visas i sidofältet Experimentkörningar och i användargränssnittet för MLflow.
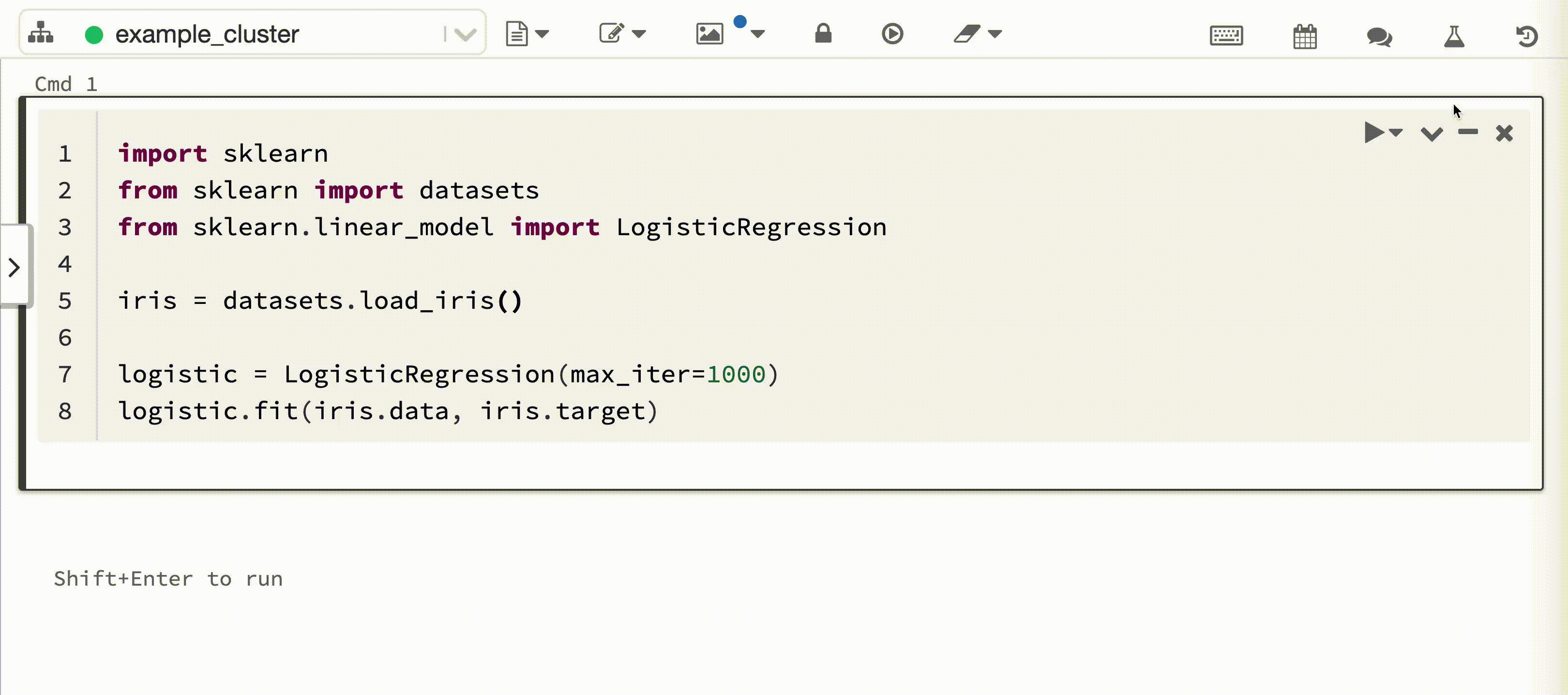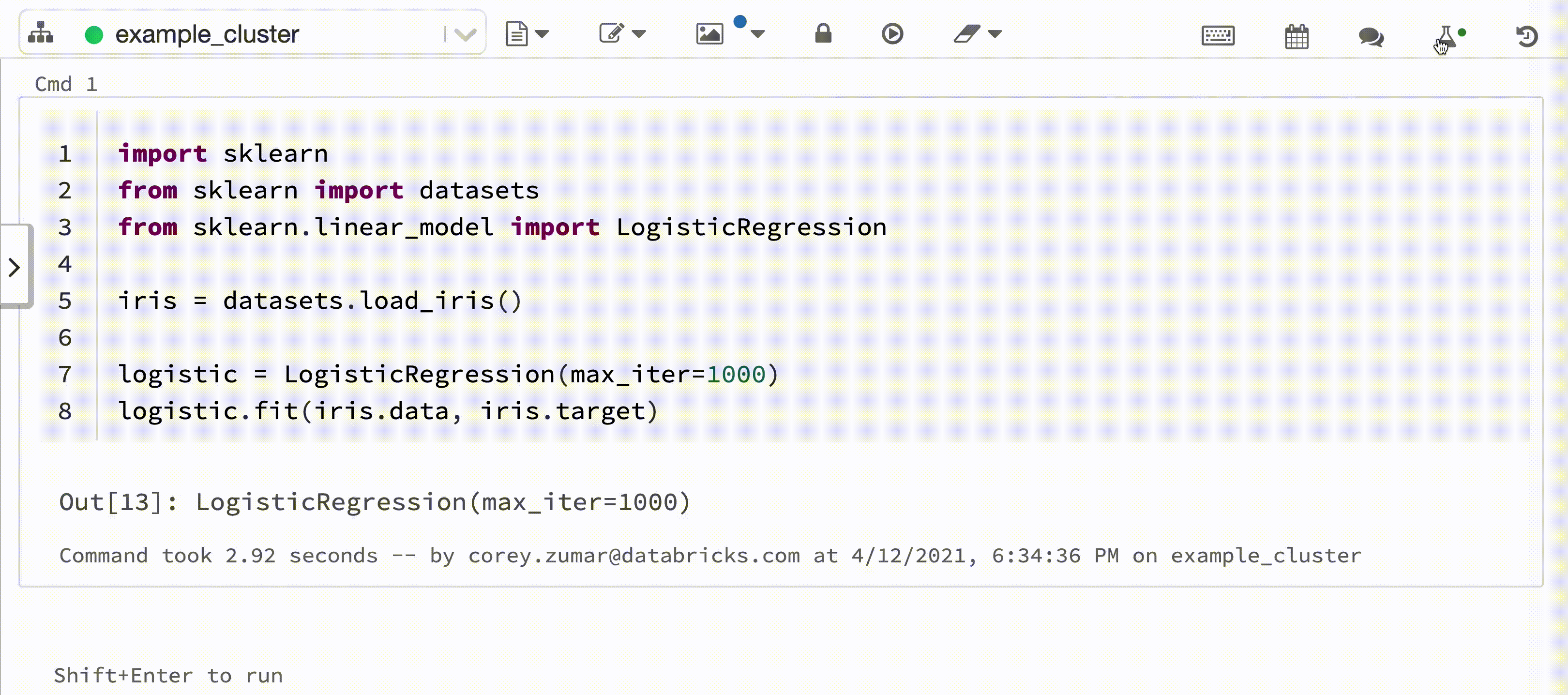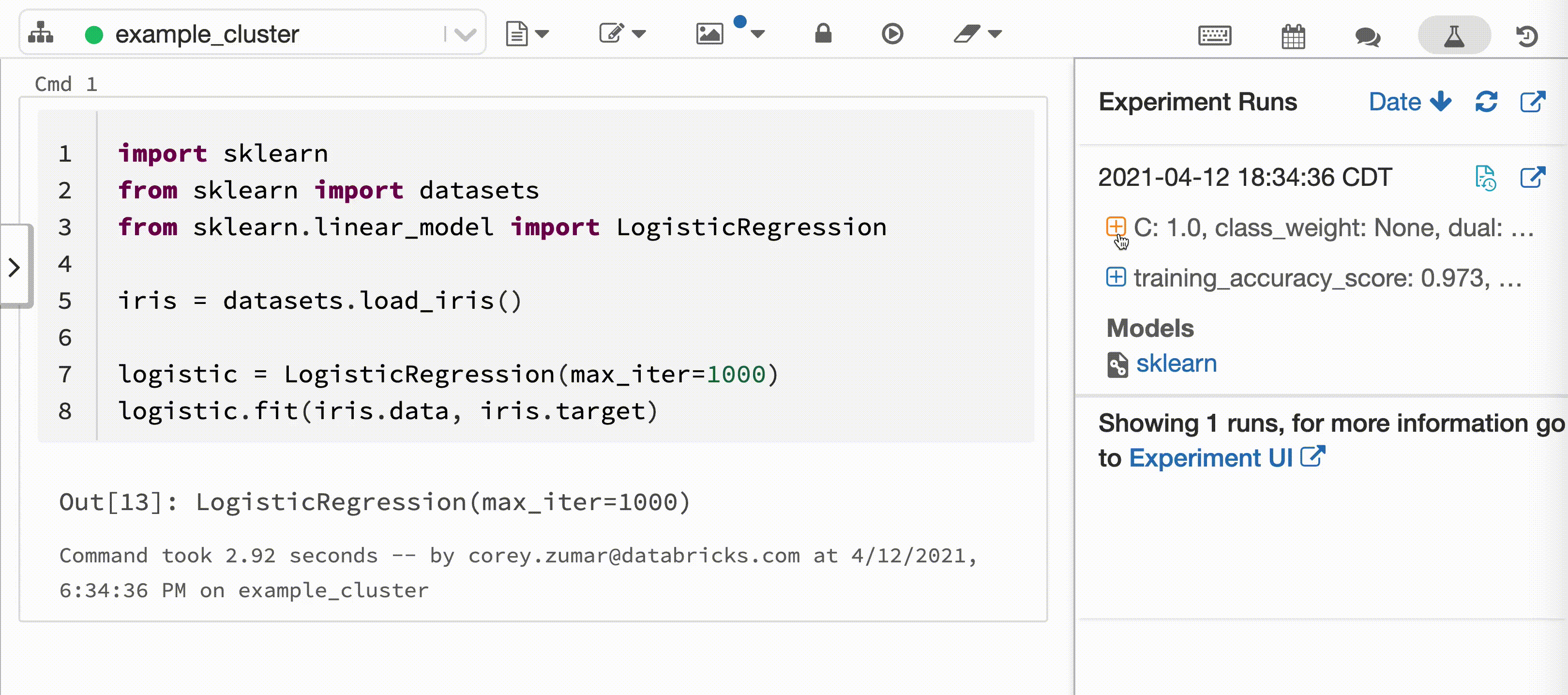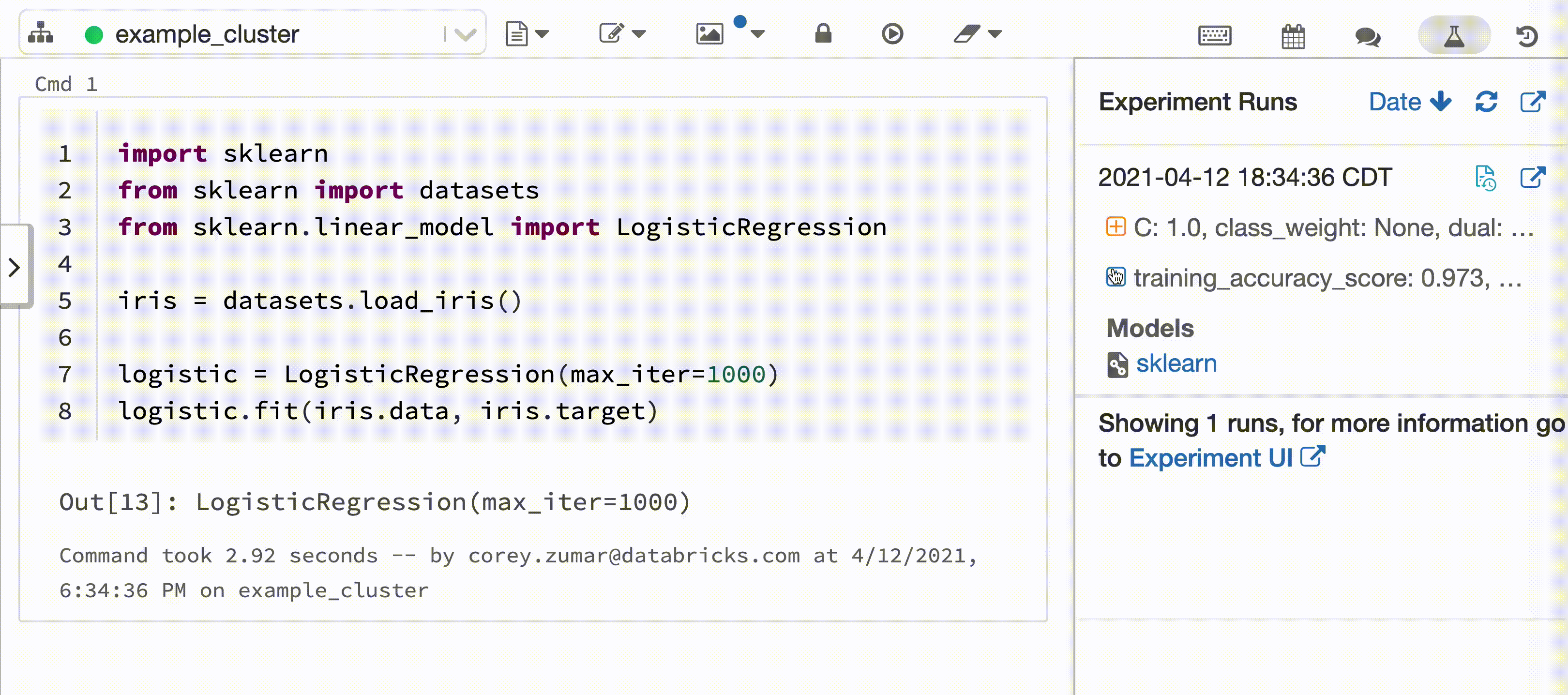
Krav
- Automatisk databricks-loggning är allmänt tillgänglig i alla regioner med Databricks Runtime 10.4 LTS ML eller senare.
- Automatisk databricks-loggning är tillgänglig i utvalda förhandsgranskningsregioner med Databricks Runtime 9.1 LTS ML eller senare.
Hur det fungerar
När du kopplar en interaktiv Python-anteckningsbok till ett Azure Databricks-kluster anropar Databricks Autologging mlflow.autolog() för att konfigurera spårning för dina modellträningssessioner. När du tränar modeller i notebook-filen spåras modellträningsinformation automatiskt med MLflow Tracking. Information om hur den här modellträningsinformationen skyddas och hanteras finns i Säkerhet och datahantering.
Standardkonfigurationen för anropet mlflow.autolog() är:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Du kan anpassa konfigurationen för automatisk loggning.
Användning
Om du vill använda Databricks Autologging tränar du en maskininlärningsmodell i ett ramverk som stöds med hjälp av en interaktiv Azure Databricks Python-anteckningsbok. Automatisk loggning av Databricks registrerar automatiskt information om modellens ursprung, parametrar och mått till MLflow Tracking. Du kan också anpassa beteendet för Automatisk dataloggning i Databricks.
Kommentar
Automatisk databricks-loggning tillämpas inte på körningar som skapats med hjälp av MLflow fluent API med mlflow.start_run(). I dessa fall måste du anropa mlflow.autolog() för att spara automatiskt loggat innehåll i MLflow-körningen. Se Spåra ytterligare innehåll.
Anpassa loggningsbeteende
Om du vill anpassa loggning använder du mlflow.autolog().
Den här funktionen tillhandahåller konfigurationsparametrar för att aktivera modellloggning (log_models), loggdatauppsättningar (log_datasets), samla in indataexempel (log_input_examples), logga modellsignaturer (log_model_signatures), konfigurera varningar (silent) med mera.
Spåra ytterligare innehåll
Följ dessa steg i en interaktiv Python-notebook-fil i Azure Databricks för att spåra ytterligare mått, parametrar, filer och metadata med MLflow-körningar som skapats av Databricks Autologging:
- Anropa mlflow.autolog() med
exclusive=False. - Starta en MLflow-körning med mlflow.start_run ().
Du kan omsluta det här anropet i
with mlflow.start_run(). När du gör det avslutas körningen automatiskt när den har slutförts. - Använd MLflow Tracking-metoder, till exempel mlflow.log_param(), för att spåra förträningsinnehåll.
- Träna en eller flera maskininlärningsmodeller i ett ramverk som stöds av Automatisk dataloggning i Databricks.
- Använd MLflow Tracking-metoder, till exempel mlflow.log_metric(), för att spåra innehåll efter träningen.
- Om du inte använde
with mlflow.start_run()i steg 2 avslutar du MLflow-körningen med mlflow.end_run().
Till exempel:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Inaktivera automatisk databricks-loggning
Om du vill inaktivera Automatisk databricks-loggning i en interaktiv Python-notebook-fil i Azure Databricks anropar du mlflow.autolog() med disable=True:
import mlflow
mlflow.autolog(disable=True)
Administratörer kan också inaktivera Automatisk loggning av Databricks för alla kluster på en arbetsyta från fliken Avancerat på sidan administratörsinställningar. Kluster måste startas om för att den här ändringen ska börja gälla.
Miljöer och ramverk som stöds
Automatisk databricks-loggning stöds i interaktiva Python-notebook-filer och är tillgängligt för följande ML-ramverk:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels
- Paddelpaddle
- OpenAI
- LangChain
Mer information om vart och ett av de ramverk som stöds finns i automatisk MLflow-loggning.
MLflow-spårningsaktivering
MLflow Tracing använder autolog funktionen inom respektive modellramverksintegrering för att styra aktivering eller inaktivering av spårningsstöd för integreringar som stöder spårning.
Om du till exempel vill aktivera spårning när du använder en LlamaIndex-modell använder du mlflow.llama_index.autolog() med log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
De integreringar som stöds som har spårningsaktivering i implementeringarna för automatisk inloggning är:
Säkerhet och datahantering
All modellträningsinformation som spåras med Databricks Autologging lagras i MLflow Tracking och skyddas av MLflow-experimentbehörigheter. Du kan dela, ändra eller ta bort modellträningsinformation med hjälp av MLflow Tracking API eller UI.
Administration
Administratörer kan aktivera eller inaktivera Automatisk loggning av Databricks för alla interaktiva notebook-sessioner på arbetsytan på fliken Avancerat på sidan administratörsinställningar. Ändringarna börjar inte gälla förrän klustret har startats om.
Begränsningar
- Automatisk databricks-loggning stöds inte i Azure Databricks-jobb. Om du vill använda automatisk loggning från jobb kan du uttryckligen anropa mlflow.autolog().
- Automatisk databricks-loggning är endast aktiverat på drivrutinsnoden i ditt Azure Databricks-kluster. Om du vill använda automatisk loggning från arbetsnoder måste du uttryckligen anropa mlflow.autolog() inifrån koden som körs på varje arbetare.
- XGBoost scikit-learn-integrering stöds inte.
Apache Spark MLlib, Hyperopt och automatiserad MLflow-spårning
Automatisk databricks-loggning ändrar inte beteendet för befintliga automatiserade MLflow-spårningsintegreringar för Apache Spark MLlib och Hyperopt.
Kommentar
I Databricks Runtime 10.1 ML inaktiverar inaktivering av den automatiserade MLflow-spårningsintegrering för Apache Spark MLlib CrossValidator och TrainValidationSplit modeller även funktionen Databricks Autologging för alla Apache Spark MLlib-modeller.