Utveckla kod i Databricks-notebook-filer
Den här sidan beskriver hur du utvecklar kod i Databricks-notebook-filer, inklusive automatisk komplettering, automatisk formatering för Python och SQL, kombinerar Python och SQL i en notebook-fil och spårar versionshistoriken för notebook-filer.
Mer information om avancerade funktioner som är tillgängliga med redigeraren, till exempel automatisk komplettering, variabelval, stöd för flera markörer och sida vid sida-diffs, finns i Använda Databricks Notebook och filredigeraren.
När du använder notebook-filen eller filredigeraren är Databricks Assistant tillgängligt för att hjälpa dig att generera, förklara och felsöka kod. Mer information finns i Använda Databricks Assistant .
Databricks-notebook-filer innehåller också ett inbyggt interaktivt felsökningsprogram för Python-notebook-filer. Se Felsöka notebook-filer.
Få kodningshjälp från Databricks Assistant
Databricks Assistant är en kontextmedveten AI-assistent som du kan interagera med med ett konversationsgränssnitt, vilket gör dig mer produktiv i Databricks. Du kan beskriva din uppgift på engelska och låta assistenten generera Python-kod eller SQL-frågor, förklara komplex kod och automatiskt åtgärda fel. Assistenten använder Unity Catalog-metadata för att förstå dina tabeller, kolumner, beskrivningar och populära datatillgångar i företaget för att tillhandahålla anpassade svar.
Databricks Assistant kan hjälpa dig med följande uppgifter:
- Generera kod.
- Felsöka kod, inklusive att identifiera och föreslå korrigeringar för fel.
- Transformera och optimera kod.
- Förklara kod.
- Hjälp dig att hitta relevant information i Azure Databricks-dokumentationen.
Information om hur du använder Databricks Assistant för att hjälpa dig att koda mer effektivt finns i Använda Databricks Assistant. Allmän information om Databricks Assistant finns i DatabricksIQ-baserade funktioner.
Åtkomst till notebook-fil för redigering
Om du vill öppna en notebook-fil använder du funktionen Sök på arbetsytan eller använder arbetsytans webbläsare för att navigera till anteckningsboken och klickar på anteckningsbokens namn eller ikon.
Bläddra bland data
Använd schemawebbläsaren för att utforska Unity Catalog-objekt som är tillgängliga för notebook-filen. Klicka ![]() på vänster sida av anteckningsboken för att öppna schemawebbläsaren.
på vänster sida av anteckningsboken för att öppna schemawebbläsaren.
Knappen För dig visar bara de objekt som du har använt i den aktuella sessionen eller som tidigare markerats som en favorit.
När du skriver text i rutan Filter ändras visningen så att endast de objekt som innehåller den text som du skriver visas. Endast objekt som för närvarande är öppna eller har öppnats i den aktuella sessionen visas. Filterrutan gör inte en fullständig sökning av kataloger, scheman, tabeller och volymer som är tillgängliga för notebook-filen.
Om du vill öppna ![]() menyn för kebab hovra markören över objektets namn enligt följande:
menyn för kebab hovra markören över objektets namn enligt följande:
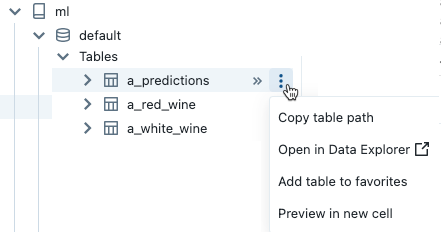
Om objektet är en tabell kan du göra följande:
- Skapa och kör en cell automatiskt för att visa en förhandsgranskning av data i tabellen. Välj Förhandsgranska i en ny cell på menyn för kebab för tabellen.
- Visa en katalog, ett schema eller en tabell i Katalogutforskaren. Välj Öppna i Katalogutforskaren på menyn för kebab. En ny flik öppnas som visar det markerade objektet.
- Hämta sökvägen till en katalog, ett schema eller en tabell. Välj Kopiera ... sökväg från kebabmenyn för objektet.
- Lägg till en tabell i Favoriter. Välj Lägg till i favoriter på kebabmenyn för tabellen.
Om objektet är en katalog, ett schema eller en volym kan du kopiera objektets sökväg eller öppna den i Katalogutforskaren.
Infoga ett tabell- eller kolumnnamn direkt i en cell:
- Klicka på markören i cellen på den plats där du vill ange namnet.
- Flytta markören över tabellnamnet eller kolumnnamnet i schemawebbläsaren.
- Klicka på den dubbelpil
 som visas till höger om objektets namn.
som visas till höger om objektets namn.
Kortkommandon för tangentbord
Om du vill visa kortkommandon väljer du Hjälp > kortkommandon. Vilka kortkommandon som är tillgängliga beror på om markören finns i en kodcell (redigeringsläge) eller inte (kommandoläge).
Kommandopalett
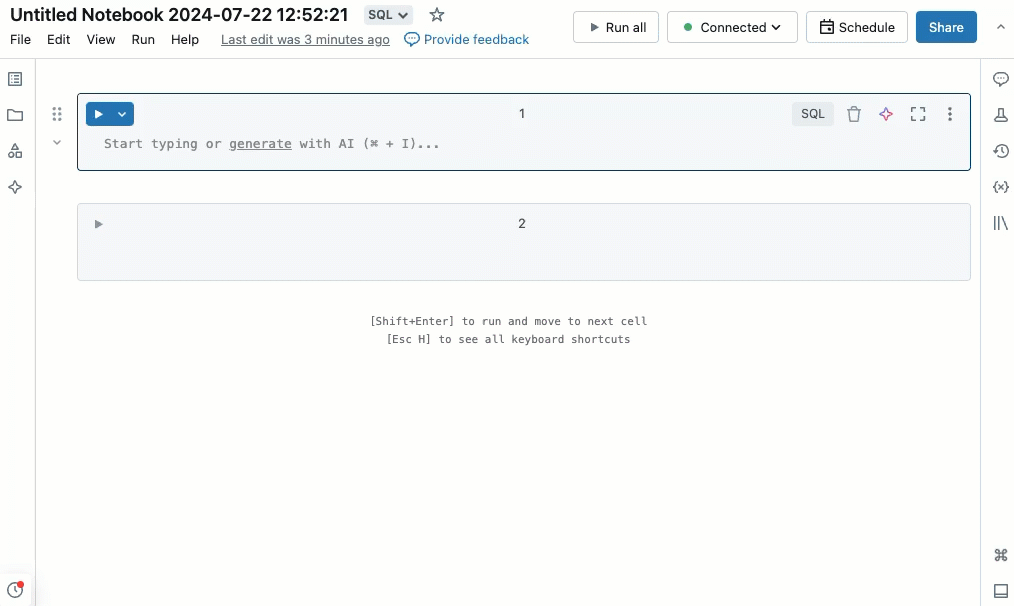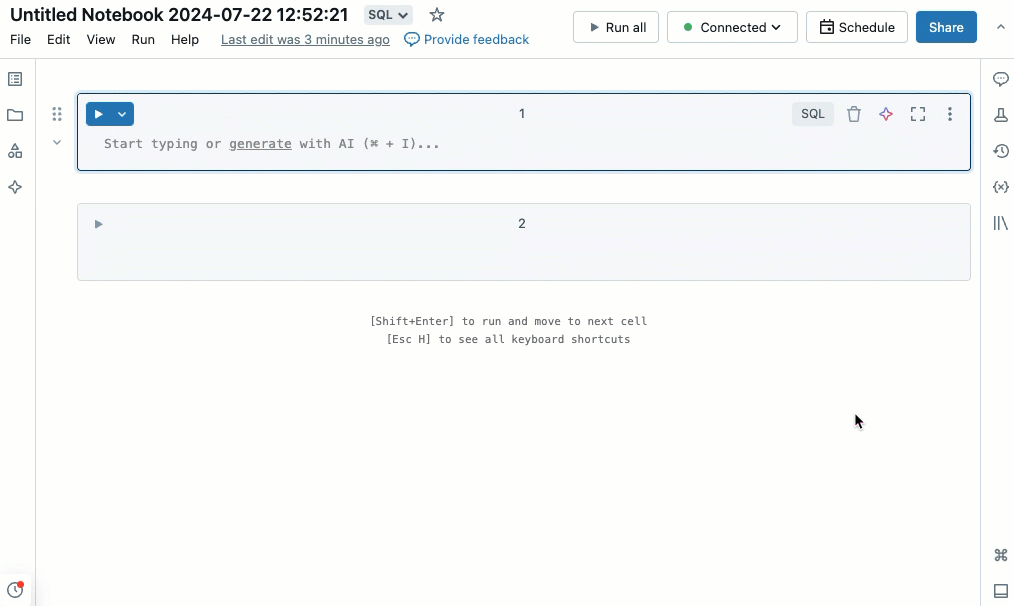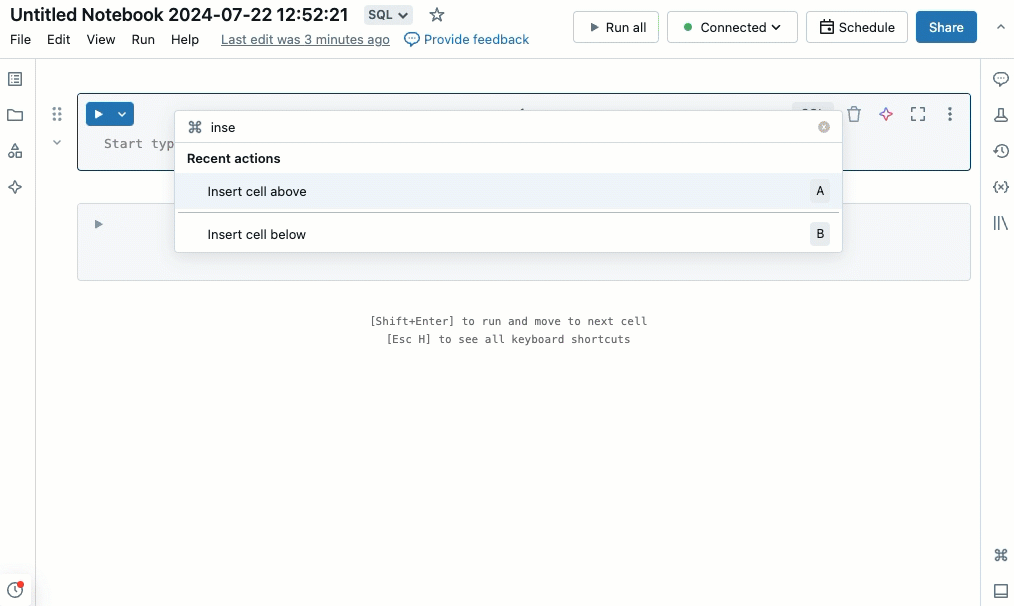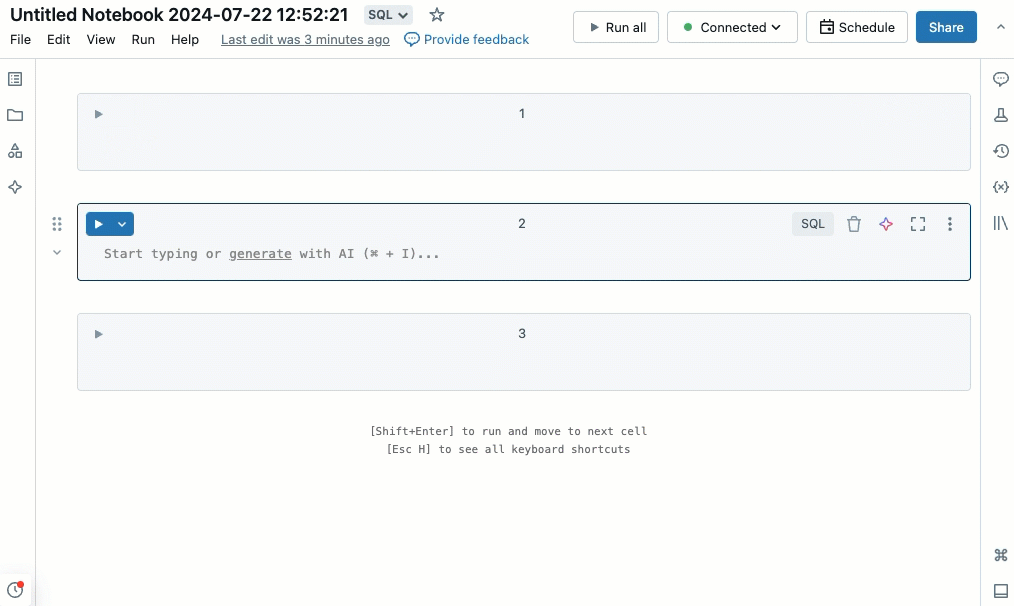
Du kan snabbt utföra åtgärder i notebook-filen med hjälp av kommandopaletten. Om du vill öppna en panel med notebook-åtgärder klickar du  i det nedre högra hörnet på arbetsytan eller använder genvägen Cmd + Skift + P på MacOS eller Ctrl + Skift + P i Windows.
i det nedre högra hörnet på arbetsytan eller använder genvägen Cmd + Skift + P på MacOS eller Ctrl + Skift + P i Windows.
Sök efter och ersätt text
Om du vill söka efter och ersätta text i en notebook-fil väljer du Redigera > Sök och Ersätt. Den aktuella matchningen är markerad i orange och alla andra matchningar är markerade i gult.
Om du vill ersätta den aktuella matchningen klickar du på Ersätt. Om du vill ersätta alla matchningar i anteckningsboken klickar du på Ersätt alla.
Om du vill flytta mellan matchningar klickar du på knapparna Föregående och Nästa . Du kan också trycka på skift+retur och retur för att gå till föregående respektive nästa matchningar.
Stäng verktyget sök och ersätt genom att klicka eller trycka på ![]() esc.
esc.
Köra markerade celler
Du kan köra en enskild cell eller en samling celler. Om du vill markera en enskild cell klickar du var som helst i cellen. Om du vill markera flera celler håller du ned Command nyckeln på MacOS eller Ctrl nyckeln i Windows och klickar i cellen utanför textområdet enligt skärmbilden.
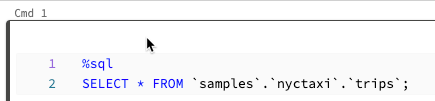
Om du vill köra det valda kommandot beror beteendet för det här kommandot på klustret som notebook-filen är kopplad till.
- I ett kluster som kör Databricks Runtime 13.3 LTS eller nedan körs markerade celler individuellt. Om ett fel uppstår i en cell fortsätter körningen med efterföljande celler.
- I ett kluster som kör Databricks Runtime 14.0 eller senare, eller på ett SQL-lager, körs markerade celler som en batch. Ett fel stoppar körningen och du kan inte avbryta körningen av enskilda celler. Du kan använda knappen Avbryt för att stoppa körningen av alla celler.
Modularisera koden
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Med Databricks Runtime 11.3 LTS och senare kan du skapa och hantera källkodsfiler på Azure Databricks-arbetsytan och sedan importera filerna till dina notebook-filer efter behov.
Mer information om hur du arbetar med källkodsfiler finns i Dela kod mellan Databricks-notebook-filer och Arbeta med Python- och R-moduler.
Kör markerad text
Du kan markera kod- eller SQL-uttryck i en notebook-cell och bara köra den markeringen. Detta är användbart när du snabbt vill iterera kod och frågor.
Markera de rader som du vill köra.
Välj Kör > kör markerad text eller använd kortkommandot
CtrlEnter+Shift+. Om ingen text är markerad kör Kör markerad text den aktuella raden.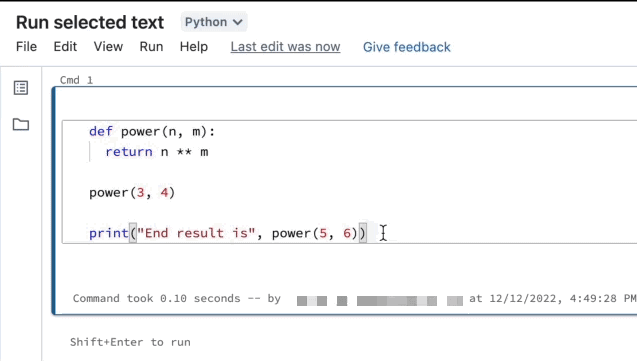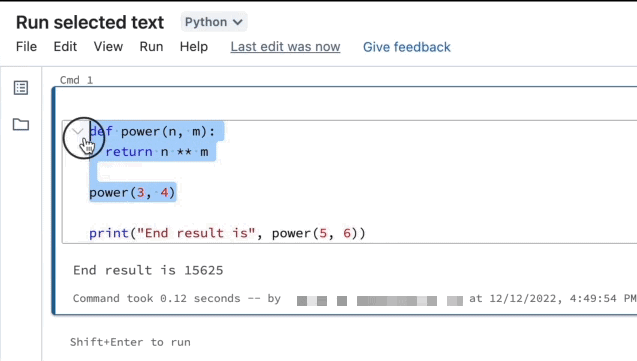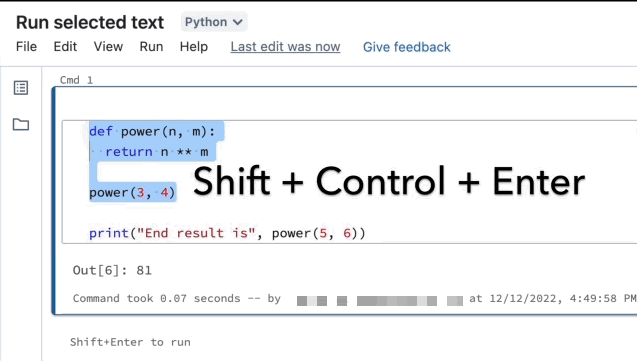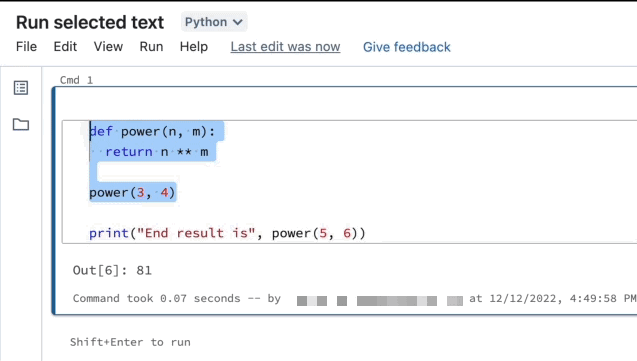
Om du använder blandade språk i en cell måste du inkludera %<language> raden i markeringen.
Kör markerad text kör också komprimerad kod, om det finns någon i den markerade markeringen.
Särskilda cellkommandon som %run, %pipoch %sh stöds.
Du kan inte använda Kör markerad text på celler som har flera utdataflikar (dvs. celler där du har definierat en dataprofil eller visualisering).
Formatera kodceller
Azure Databricks innehåller verktyg som gör att du snabbt och enkelt kan formatera Python- och SQL-kod i notebook-celler. De här verktygen minskar arbetet med att hålla koden formaterad och bidra till att tillämpa samma kodningsstandarder i dina notebook-filer.
Python black formatter library
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Azure Databricks stöder Python-kodformatering med svart i notebook-filen. Notebook-filen måste vara ansluten till ett kluster med black och tokenize-rt Python-paket installerade.
På Databricks Runtime 11.3 LTS och senare förinstallerar black Azure Databricks och tokenize-rt. Du kan använda formateringen direkt utan att behöva installera dessa bibliotek.
På Databricks Runtime 10.4 LTS och nedan måste du installera black==22.3.0 och tokenize-rt==4.2.1 från PyPI i notebook-filen eller klustret för att kunna använda Python-formatören. Du kan köra följande kommando i anteckningsboken:
%pip install black==22.3.0 tokenize-rt==4.2.1
eller installera biblioteket i klustret.
Mer information om hur du installerar bibliotek finns i Python-miljöhantering.
För filer och notebook-filer i Databricks Git-mappar kan du konfigurera Python-formaterare baserat på pyproject.toml filen. Om du vill använda den här funktionen skapar du en pyproject.toml fil i Git-mappens rotkatalog och konfigurerar den enligt formatet Svart konfiguration. Redigera avsnittet [tool.black] i filen. Konfigurationen tillämpas när du formaterar alla filer och anteckningsböcker i git-mappen.
Formatera Python- och SQL-celler
Du måste ha behörigheten KAN REDIGERA i anteckningsboken för att formatera kod.
Azure Databricks använder biblioteket Gethue/sql-formatter för att formatera SQL och svart kodformaterare för Python.
Du kan utlösa formateraren på följande sätt:
Formatera en enskild cell
- Kortkommando: Tryck på Cmd+Skift+F.
- Snabbmeny för kommando:
- Formatera SQL-cell: Välj Formatera SQL i listrutan kommandokontext i en SQL-cell. Det här menyalternativet är endast synligt i SQL Notebook-celler eller i de med språkmagi
%sql. - Formatera Python-cell: Välj Formatera Python i listrutan kommandokontext i en Python-cell. Det här menyalternativet är endast synligt i Python Notebook-celler eller i de med språkmagi
%python.
- Formatera SQL-cell: Välj Formatera SQL i listrutan kommandokontext i en SQL-cell. Det här menyalternativet är endast synligt i SQL Notebook-celler eller i de med språkmagi
- Menyn Redigera anteckningsbok: Välj en Python- eller SQL-cell och välj sedan Redigera > formatceller.
Formatera flera celler
Markera flera celler och välj sedan Redigera > formatceller. Om du väljer celler med fler än ett språk formateras endast SQL- och Python-celler. Detta inkluderar de som använder
%sqloch%python.Formatera alla Python- och SQL-celler i notebook-filen
Välj Redigera > anteckningsbok för format. Om notebook-filen innehåller mer än ett språk formateras endast SQL- och Python-celler. Detta inkluderar de som använder
%sqloch%python.
Begränsningar i kodformatering
- Black tillämpar PEP 8-standarder för 4-blankstegs indrag. Indrag kan inte konfigureras.
- Formatering av inbäddade Python-strängar i en SQL UDF stöds inte. På samma sätt stöds inte formatering av SQL-strängar i en Python UDF.
Versionshistorik
Azure Databricks-notebook-filer har en historik över notebook-versioner så att du kan visa och återställa tidigare ögonblicksbilder av notebook-filen. Du kan utföra följande åtgärder på versioner: lägga till kommentarer, återställa och ta bort versioner och rensa versionshistorik.
Du kan också synkronisera ditt arbete i Databricks med en fjärransluten Git-lagringsplats.
Om du vill komma åt notebook-versioner klickar du  i det högra sidofältet. Versionshistoriken för notebook-filen visas. Du kan också välja Filversionshistorik>.
i det högra sidofältet. Versionshistoriken för notebook-filen visas. Du kan också välja Filversionshistorik>.
Lägg till en kommentar
Så här lägger du till en kommentar i den senaste versionen:
Klicka på versionen.
Klicka på Spara nu.
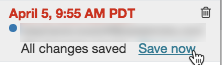
I dialogrutan Spara notebook-version anger du en kommentar.
Klicka på Spara. Notebook-versionen sparas med den angivna kommentaren.
Återställ en version
Så här återställer du en version:
Klicka på versionen.
Klicka på Återställ den här versionen.
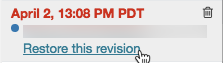
Klicka på Bekräfta. Den valda versionen blir den senaste versionen av notebook-filen.
Ta bort en version
Så här tar du bort en versionspost:
Klicka på versionen.
Klicka på papperskorgsikonen
 .
.
Klicka på Ja, radera. Den valda versionen tas bort från historiken.
Rensa versionshistorik
Versionshistoriken kan inte återställas efter att den har rensats.
Så här rensar du versionshistoriken för en notebook-fil:
- Välj Filrensningsversionshistorik>.
- Klicka på Ja, avmarkera. Versionshistoriken för notebook-filen har rensats.
Kodspråk i notebook-filer
Ange standardspråk
Standardspråket för notebook-filen visas bredvid notebook-namnet.

Om du vill ändra standardspråket klickar du på språkknappen och väljer det nya språket på den nedrullningsbara menyn. För att säkerställa att befintliga kommandon fortsätter att fungera prefixas kommandon för det tidigare standardspråket automatiskt med ett språkmagikommando.
Blanda språk
Som standard använder celler standardspråket för notebook-filen. Du kan åsidosätta standardspråket i en cell genom att klicka på språkknappen och välja ett språk i den nedrullningsbara menyn.
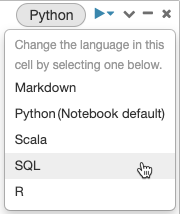
Alternativt kan du använda kommandot %<language> language magic i början av en cell. De magiska kommandon som stöds är: %python, %r, %scalaoch %sql.
Kommentar
När du anropar ett språkmagikommando skickas kommandot till REPL i körningskontexten för notebook-filen. Variabler som definierats på ett språk (och därmed i REPL för det språket) är inte tillgängliga i REPL för ett annat språk. REPL:er kan endast dela tillstånd via externa resurser, till exempel filer i DBFS eller objekt i objektlagring.
Notebook-filer har också stöd för några extra magiska kommandon:
%sh: Gör att du kan köra shell-kod i notebook-filen. Om du vill misslyckas med cellen om shell-kommandot har en slutstatus som inte är noll lägger du till alternativet-e. Det här kommandot körs bara på Apache Spark-drivrutinen och inte på arbetarna. Om du vill köra ett gränssnittskommando på alla noder använder du ett init-skript.%fs: Gör att du kan användadbutilsfilsystemkommandon. Om du till exempel vill köradbutils.fs.lskommandot för att visa filer kan du ange%fs lsi stället. Mer information finns i Arbeta med filer på Azure Databricks.%md: Gör att du kan inkludera olika typer av dokumentation, inklusive text, bilder och matematiska formler och ekvationer. Se nästa avsnitt.
SQL-syntaxmarkering och automatisk komplettering i Python-kommandon
Syntaxmarkering och automatisk komplettering av SQL är tillgängliga när du använder SQL i ett Python-kommando, till exempel i ett spark.sql kommando.
Utforska SQL-cellresultat i Python-notebook-filer med Hjälp av Python
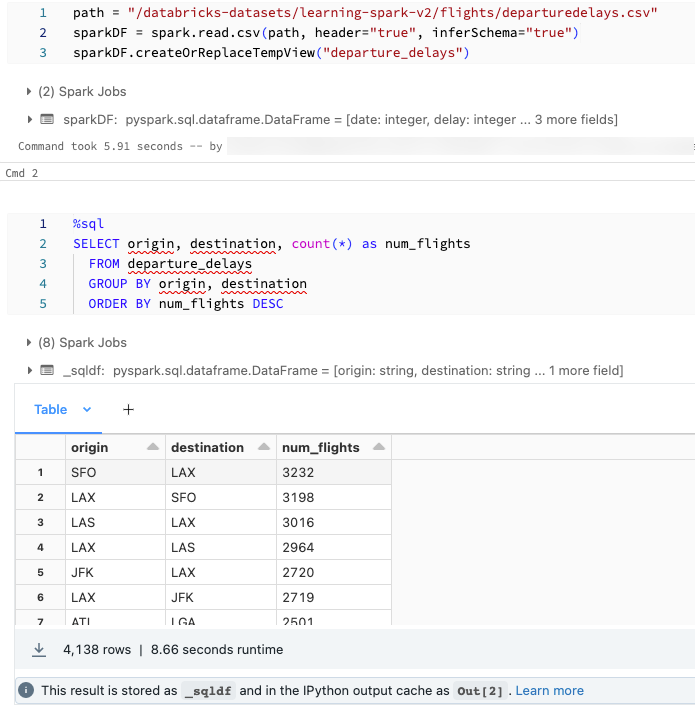
Du kanske vill läsa in data med SQL och utforska dem med Hjälp av Python. I en Databricks Python-notebook-fil görs tabellresultat från en SQL-språkcell automatiskt tillgängliga som en Python DataFrame tilldelad till variabeln _sqldf.
I Databricks Runtime 13.3 LTS och senare kan du också komma åt DataFrame-resultatet med hjälp av IPythons cachelagringssystem för utdata. Prompträknaren visas i utdatameddelandet som visas längst ned i cellresultatet. För det exempel som visas refererar du till resultatet som Out[2].
Kommentar
Variabeln
_sqldfkan tilldelas om varje gång en%sqlcell körs. Om du vill undvika att förlora referensen till DataFrame-resultatet tilldelar du det till ett nytt variabelnamn innan du kör nästa%sqlcell:new_dataframe_name = _sqldfOm frågan använder en widget för parameterisering är resultatet inte tillgängligt som en Python DataFrame.
Om frågan använder nyckelorden
CACHE TABLEellerUNCACHE TABLEär resultatet inte tillgängligt som en Python DataFrame.
Skärmbilden visar ett exempel:
Köra SQL-celler parallellt
När ett kommando körs och anteckningsboken är kopplad till ett interaktivt kluster kan du köra en SQL-cell samtidigt med det aktuella kommandot. SQL-cellen körs i en ny, parallell session.
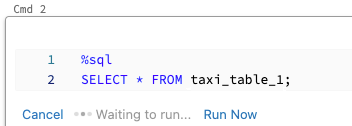
Så här kör du en cell parallellt:
Klicka på Kör nu. Cellen körs omedelbart.
Eftersom cellen körs i en ny session stöds inte tillfälliga vyer, UDF:er och implicita Python DataFrame (_sqldf) för celler som körs parallellt. Dessutom används standardkatalog- och databasnamnen under parallell körning. Om koden refererar till en tabell i en annan katalog eller databas måste du ange tabellnamnet med hjälp av namnområdet på tre nivåer (catalog.schema.table).
Köra SQL-celler på ett SQL-lager
Du kan köra SQL-kommandon i en Databricks-notebook-fil på ett SQL-lager, en typ av beräkning som är optimerad för SQL-analys. Se Använda en notebook-fil med ett SQL-lager.
Visa bilder
Azure Databricks stöder visning av bilder i Markdown-celler. Du kan visa bilder som lagras i Arbetsyta, Volymer eller FileStore.
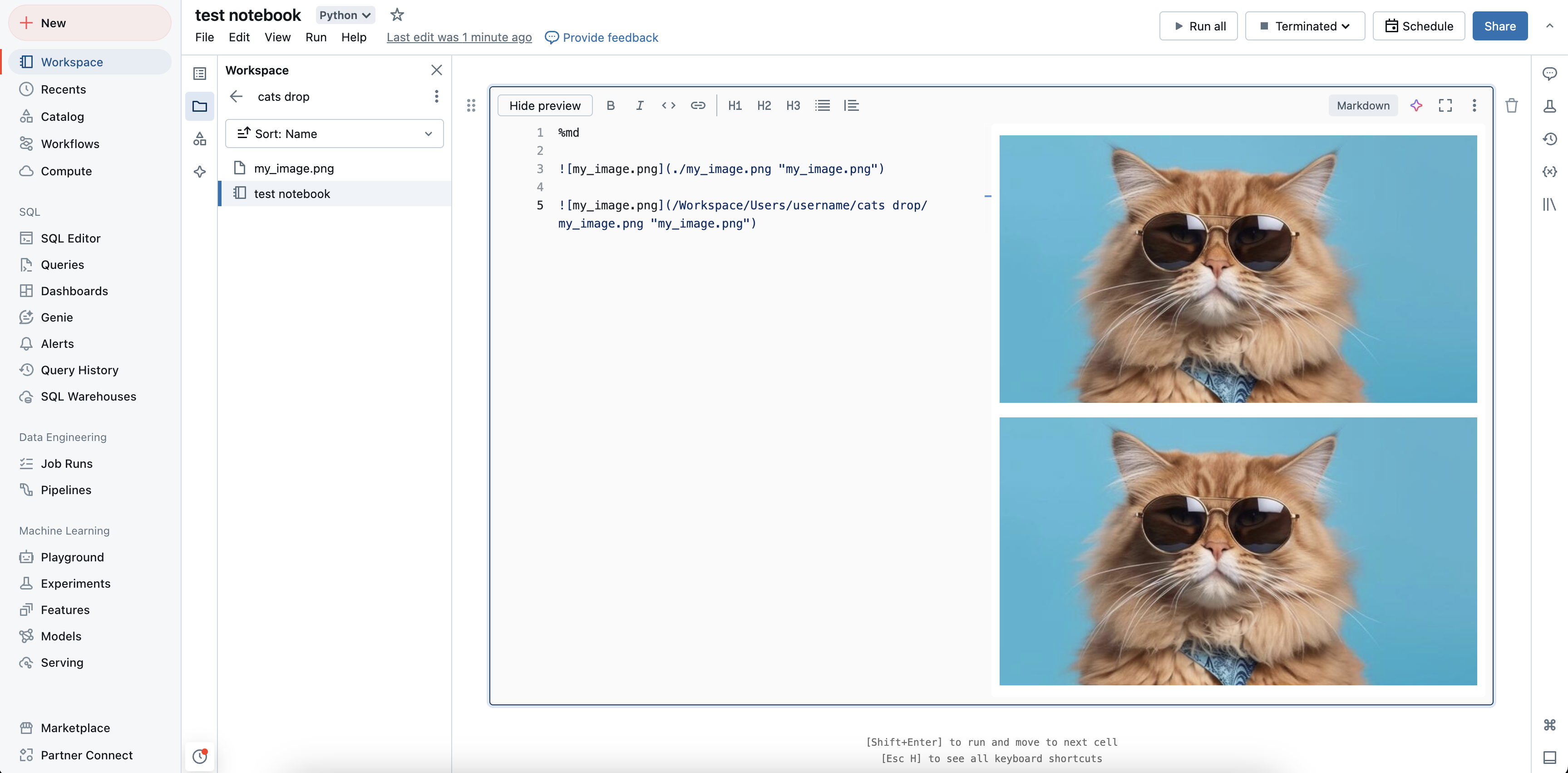
Visa bilder som lagras på arbetsytan
Du kan använda antingen absoluta sökvägar eller relativa sökvägar för att visa bilder som lagras på arbetsytan. Om du vill visa en bild som lagras på arbetsytan använder du följande syntax:
%md


Visa bilder som lagras i volymer
Du kan använda absoluta sökvägar för att visa bilder som lagras i Volymer. Om du vill visa en bild som lagras i Volymer använder du följande syntax:
%md

Visa bilder som lagras i FileStore
Om du vill visa bilder som lagras i FileStore använder du följande syntax:
%md

Anta till exempel att du har databricks-logotypens bildfil i FileStore:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
När du inkluderar följande kod i en Markdown-cell:

bilden återges i cellen:

Dra och släpp bilder
Du kan dra och släppa bilder från ditt lokala filsystem till Markdown-celler. Bilden laddas upp till den aktuella arbetsytans katalog och visas i cellen.
Visa matematiska ekvationer
Notebook-filer stöder KaTeX för att visa matematiska formler och ekvationer. Ett exempel:
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
renderas som:
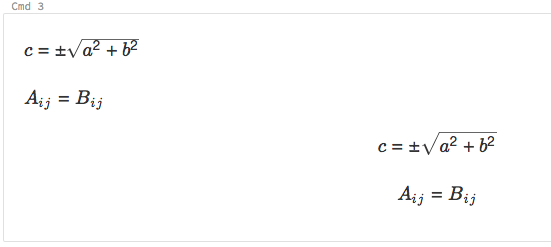
och
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
renderas som:
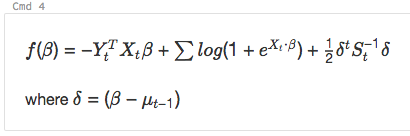
Inkludera HTML
Du kan inkludera HTML i en notebook-fil med hjälp av funktionen displayHTML. Se HTML, D3 och SVG i notebook-filer för ett exempel på hur du gör detta.
Kommentar
Iframe displayHTML hanteras från domänen databricksusercontent.com och iframe-sandbox-miljön innehåller attributet allow-same-origin . databricksusercontent.com måste vara tillgänglig från din webbläsare. Om den för närvarande blockeras av ditt företags nätverk måste den läggas till i en lista över tillåtna.
Länka till andra notebook-filer
Du kan länka till andra notebook-filer eller mappar i Markdown-celler med hjälp av relativa sökvägar. href Ange attributet för en fästpunktstagg som den relativa sökvägen, som börjar med en $ och följ sedan samma mönster som i Unix-filsystem:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>