Visualiseringstyper
Den här artikeln beskriver de typer av visualiseringar som är tillgängliga att använda i Azure Databricks Notebooks och i Databricks SQL, och visar hur du skapar ett exempel på varje visualiseringstyp.
Kommentar
Mer information om vilka visualiseringstyper som är tillgängliga för AI/BI-instrumentpaneler finns i visualiseringstyper för instrumentpaneler.
Stapeldiagram
Stapeldiagram representerar förändringen i mått över tid eller för att visa proportionalitet, liknande ett cirkeldiagram .
Kommentar
Stapeldiagram stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen.
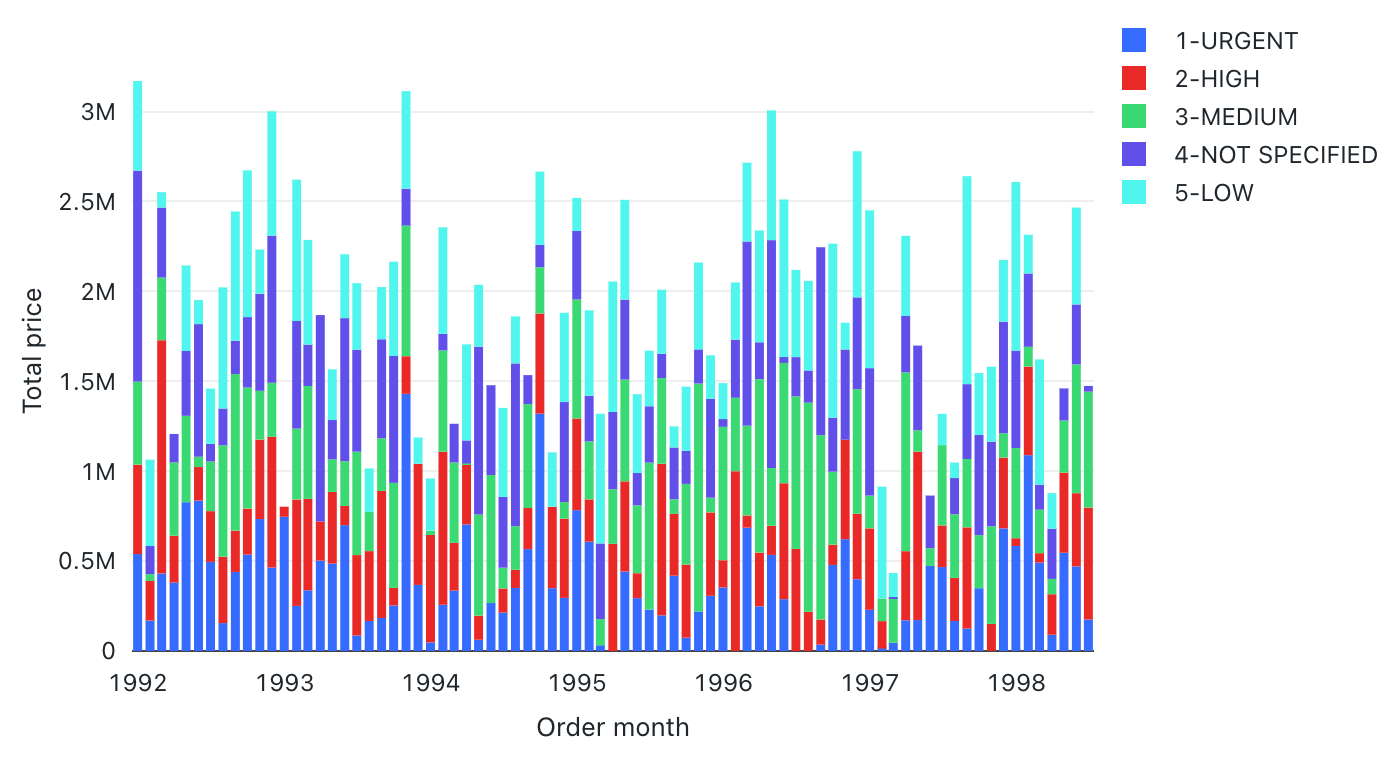
Konfigurationsvärden: För den här visualiseringen av stapeldiagram har följande värden angetts:
- X-kolumn:
- Datauppsättningskolumn:
o_orderdate - Datumnivå:
Months
- Datauppsättningskolumn:
- Y-kolumner:
- Datauppsättningskolumn:
o_totalprice - Sammansättningstyp:
Sum
- Datauppsättningskolumn:
- Gruppera efter (datamängdskolumn):
o_orderpriority - Stapling:
Stack - X-axelnamn (åsidosätt standardvärde):
Order month - Y-axelnamn (åsidosätt standardvärde):
Total price
Konfigurationsalternativ: Information om konfigurationsalternativ för stapeldiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här stapeldiagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Linjediagram
Linjediagram visar ändringen i ett eller flera mått över tid.
Kommentar
Linjediagram stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen.
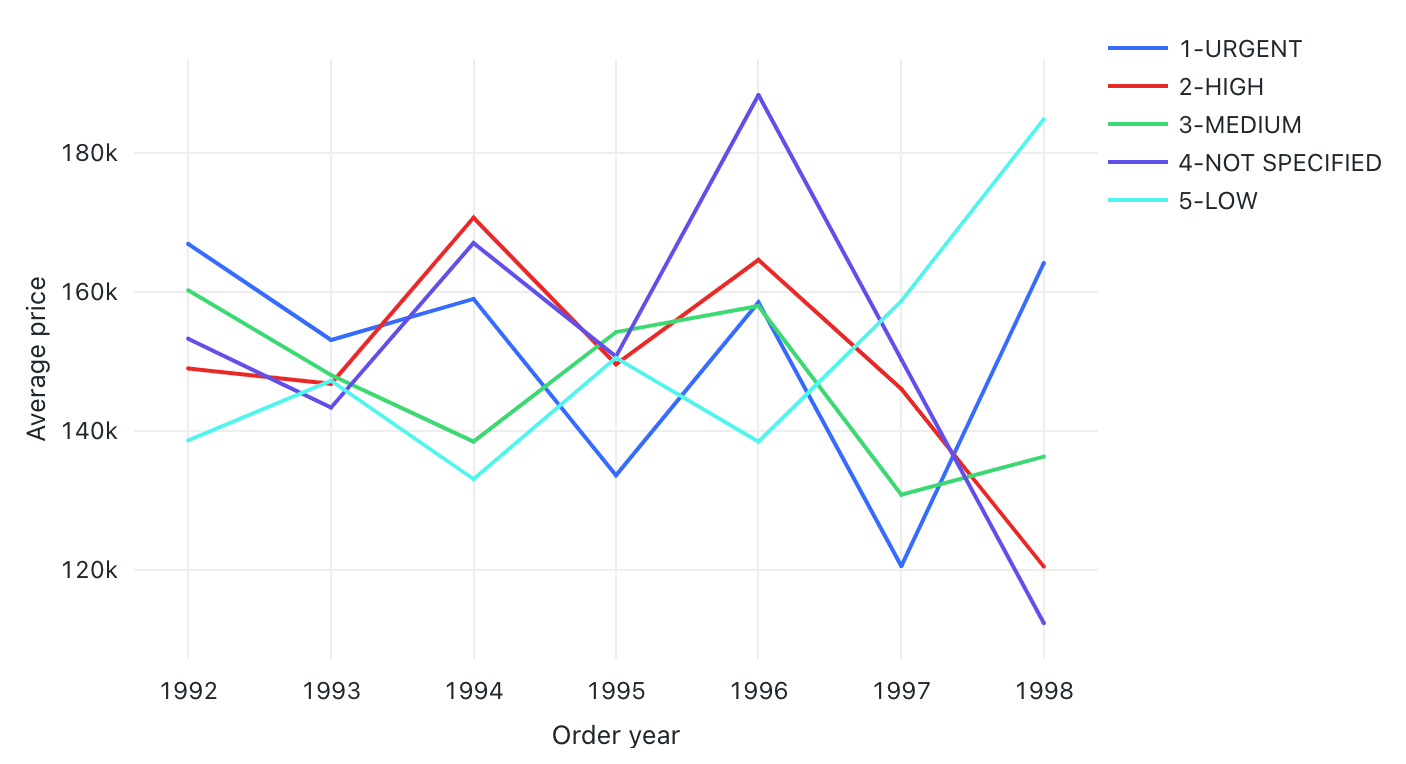
Konfigurationsvärden: För den här linjediagramvisualiseringen har följande värden angetts:
- X-kolumn:
- Datauppsättningskolumn:
o_orderdate - Datumnivå:
Years
- Datauppsättningskolumn:
- Y-kolumner:
- Datauppsättningskolumn:
o_totalprice - Sammansättningstyp:
Average
- Datauppsättningskolumn:
- Gruppera efter (datamängdskolumn):
o_orderpriority - X-axelnamn (åsidosätt standardvärde):
Order year - Y-axelnamn (åsidosätt standardvärde):
Average price
Konfigurationsalternativ: Information om konfigurationsalternativ för linjediagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här linjediagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Ytdiagram
Ytdiagram kombinerar linje- och stapeldiagrammet för att visa hur en eller flera gruppers numeriska värden ändras jämfört med förloppet för en andra variabel, vanligtvis tidsvariabeln. De används ofta för att visa ändringar i försäljningstratten genom tid.
Kommentar
Områdesdiagram stöder databassammandragningar, vilket ger support för frågor som returnerar fler än 64 000 datarader utan att resultatet kapas.
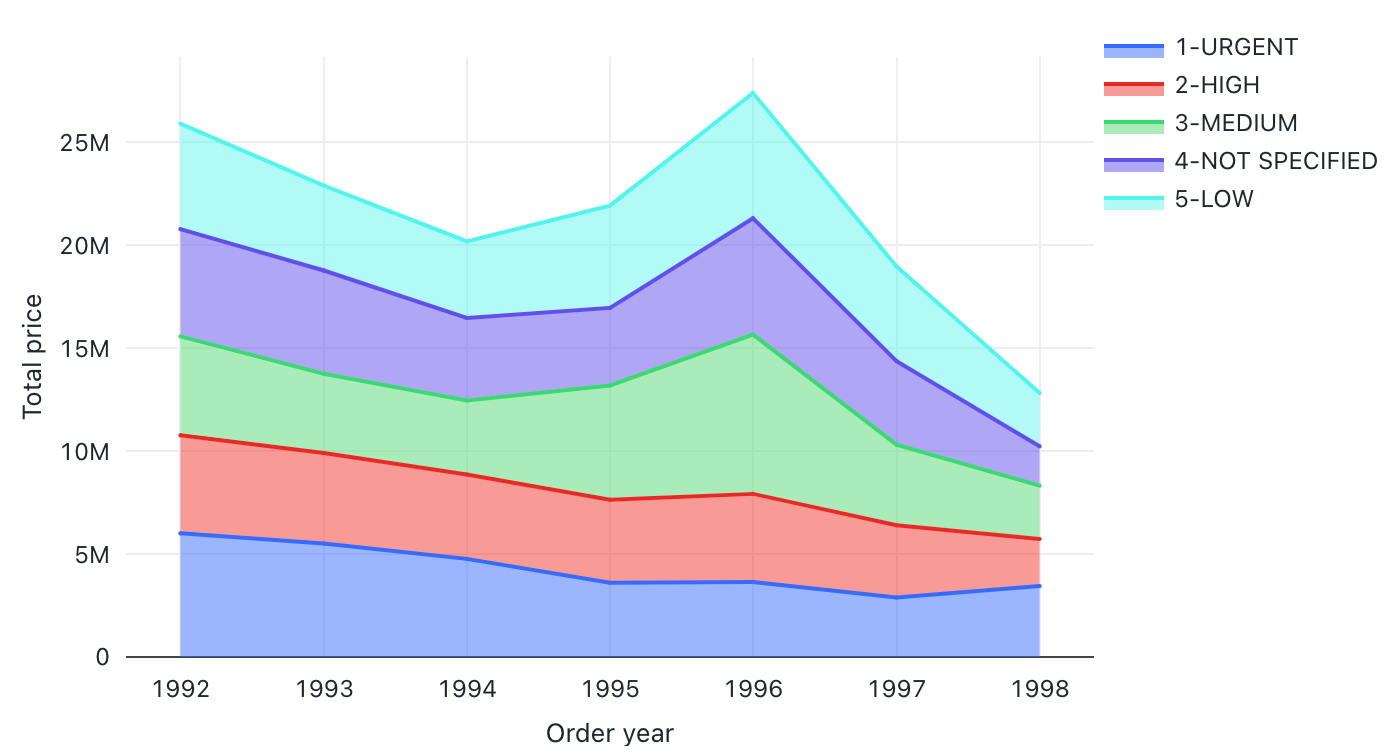
Konfigurationsvärden: För den här visualiseringen av ytdiagram har följande värden angetts:
- X-kolumn:
- Datauppsättningskolumn:
o_orderdate - Datumnivå:
Years
- Datauppsättningskolumn:
- Y-kolumner:
- Datauppsättningskolumn:
o_totalprice - Sammansättningstyp:
Sum
- Datauppsättningskolumn:
- Gruppera efter (datamängdskolumn):
o_orderpriority - Stapling:
Stack - X-axelnamn (åsidosätt standardvärde):
Order year - Y-axelnamn (åsidosätt standardvärde):
Total price
Konfigurationsalternativ: Information om konfigurationsalternativ för ytdiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här visualiseringen av ytdiagram användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Cirkeldiagram
Cirkeldiagram visar proportionalitet mellan mått. De är inte avsedda att förmedla tidsseriedata.
Kommentar
Cirkeldiagram stöder serverdelsaggregeringar och ger stöd för frågor som returnerar mer än 64 000 rader data utan att förkorta resultatuppsättningen.
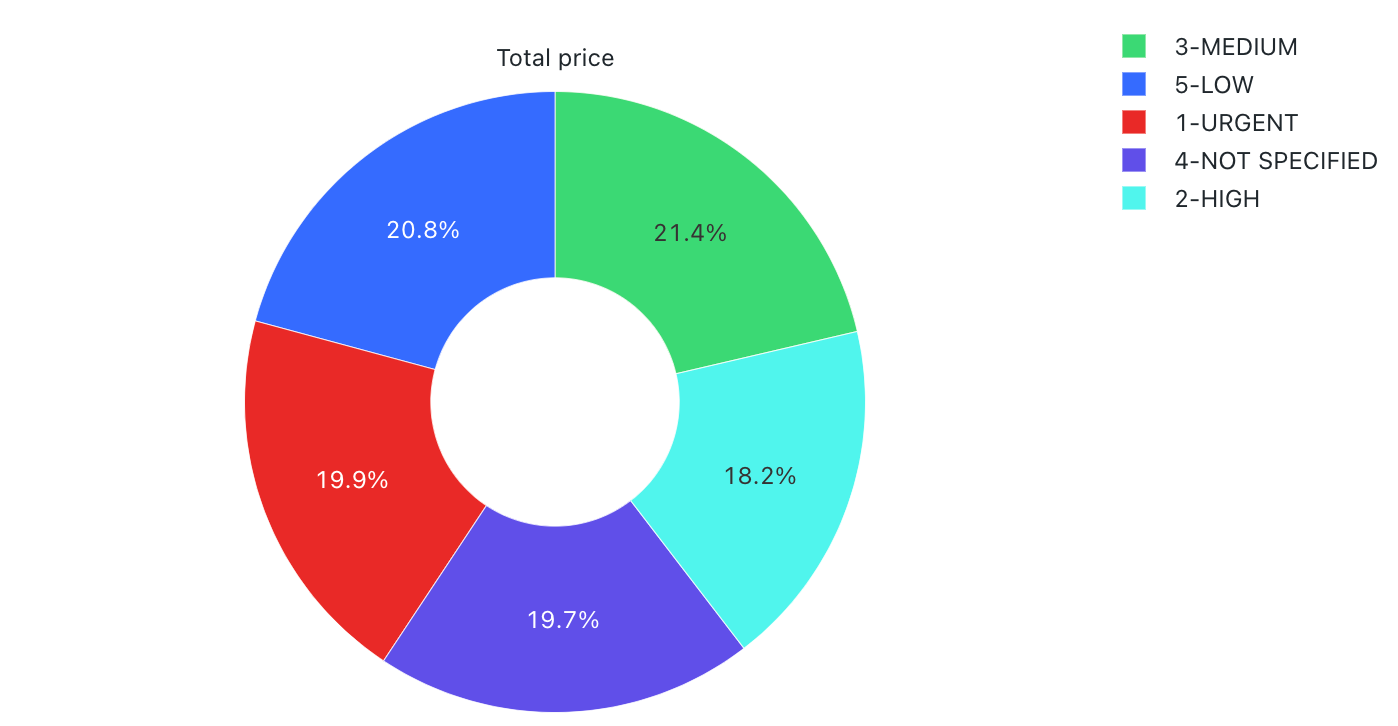
Konfigurationsvärden: För den här cirkeldiagramvisualiseringen angavs följande värden:
- X-kolumn (datamängdskolumn):
o_orderpriority - Y-kolumner:
- Datauppsättningskolumn:
o_totalprice - Sammansättningstyp:
Sum
- Datauppsättningskolumn:
- Etikett (åsidosätt standardvärde):
Total price
Konfigurationsalternativ: Information om konfigurationsalternativ för cirkeldiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här cirkeldiagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Histogramdiagram
Ett histogram ritar frekvensen som ett angivet värde inträffar i en datauppsättning. Ett histogram hjälper dig att förstå om en datauppsättning har värden som är grupperade runt ett litet antal intervall eller som är mer utspridda. Ett histogram visas som ett stapeldiagram där du styr antalet distinkta staplar (kallas även lagerplatser).
Kommentar
Histogramdiagram stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen.
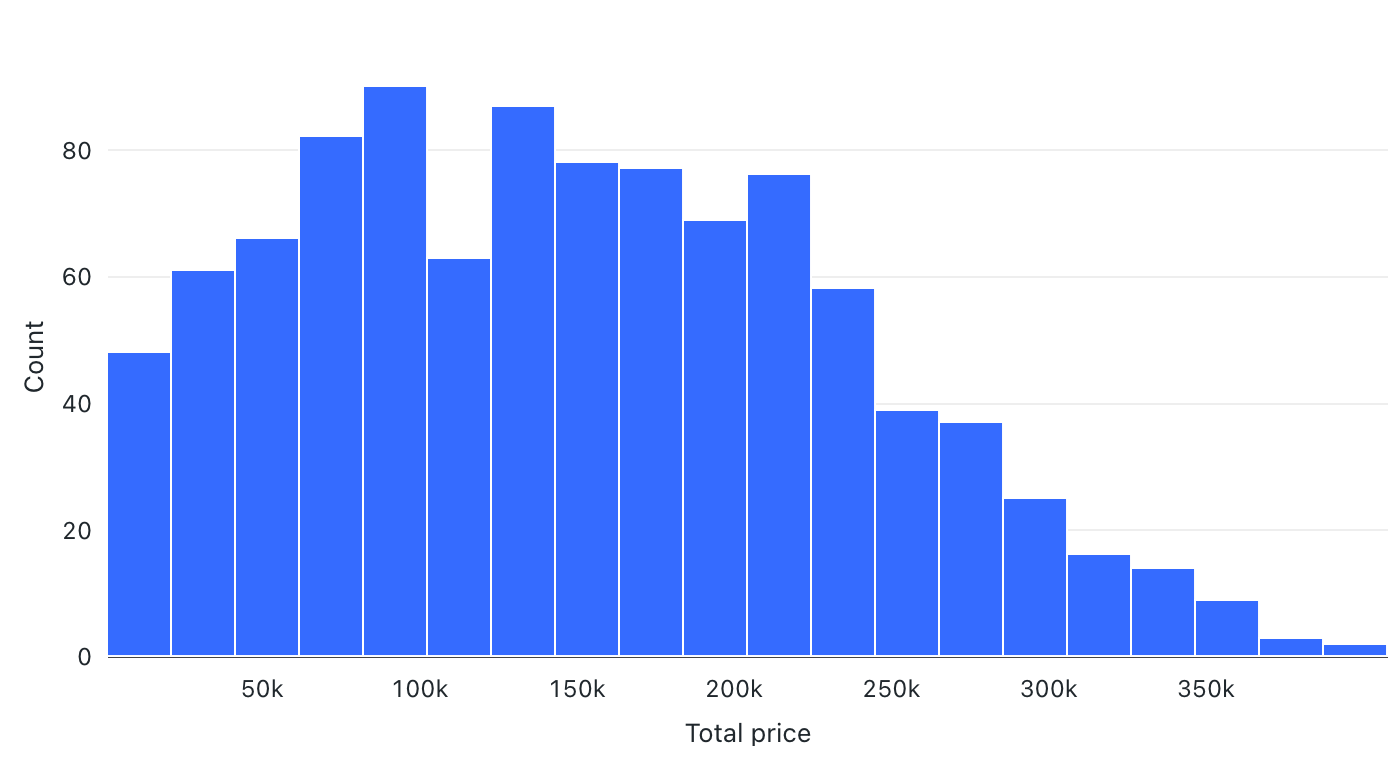
Konfigurationsvärden: För den här histogramdiagramvisualiseringen angavs följande värden:
- X-kolumn (datamängdskolumn):
o_totalprice - Antal lagerplatser: 20
- X-axelnamn (åsidosätt standardvärde):
Total price
Konfigurationsalternativ: Information om konfigurationsalternativ för histogramdiagram finns i konfigurationsalternativ för histogramdiagram.
SQL-fråga: För den här histogramdiagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Heatmap-diagram
Med termiska diagram blandas funktioner i stapeldiagram, stapling och bubbeldiagram så att du kan visualisera numeriska data med hjälp av färger. En gemensam färgpalett för en värmekarta visar de högsta värdena med varmare färger, till exempel orange eller rött, och de lägsta värdena med hjälp av svalare färger, som blått eller lila.
Tänk till exempel på följande värmekarta som visualiserar de mest förekommande avstånden för taxiresor varje dag och grupperar resultatet efter veckodagen, avståndet och det totala priset.
Kommentar
Heatmap-diagram stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen.
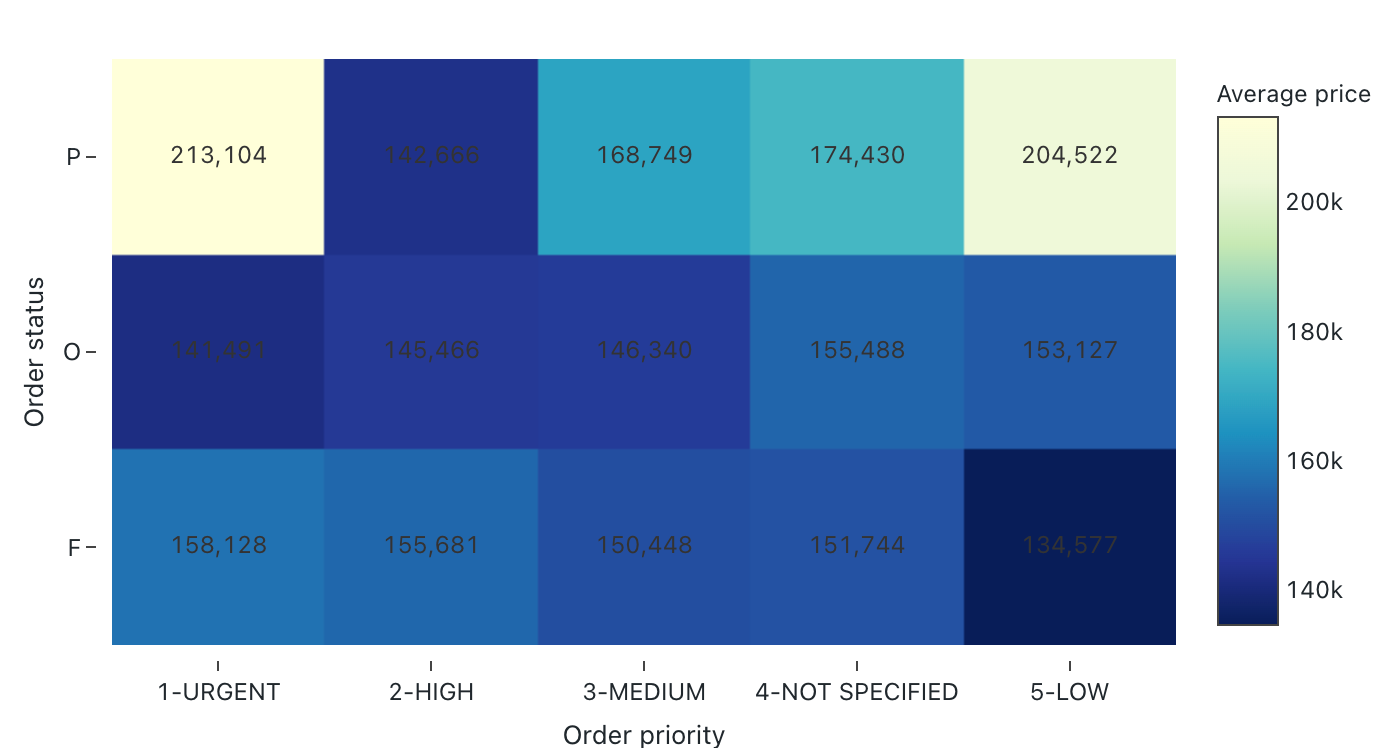
Konfigurationsvärden: För den här visualiseringen av värmekartor har följande värden angetts:
- X-kolumn (datamängdskolumn):
o_orderpriority - Y-kolumner (datamängdskolumn):
o_orderstatus - Färgkolumn:
- Datauppsättningskolumn:
o_totalprice - Sammansättningstyp:
Average
- Datauppsättningskolumn:
- X-axelnamn (åsidosätt standardvärde):
Order priority - Namn på Y-axel (åsidosätt standardvärde):
Order status - Färgnamn (åsidosätt standardvärde):
Average price - Färgschema (åsidosätt standardvärde):
YIGnBu
Konfigurationsalternativ: Information om konfigurationsalternativ för värmekarta finns i konfiguationsalternativ för heatmap-diagram.
SQL-fråga: För den här visualiseringen av heatmap-diagrammet användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.orders
Punktdiagram
Punktvisualiseringar används ofta för att visa relationen mellan två numeriska variabler. Dessutom kan en tredje dimension kodas med färg för att visa hur de numeriska variablerna skiljer sig mellan grupper.
Kommentar
Punktdiagram stöder back-end aggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan avkortning av resultatuppsättningen.
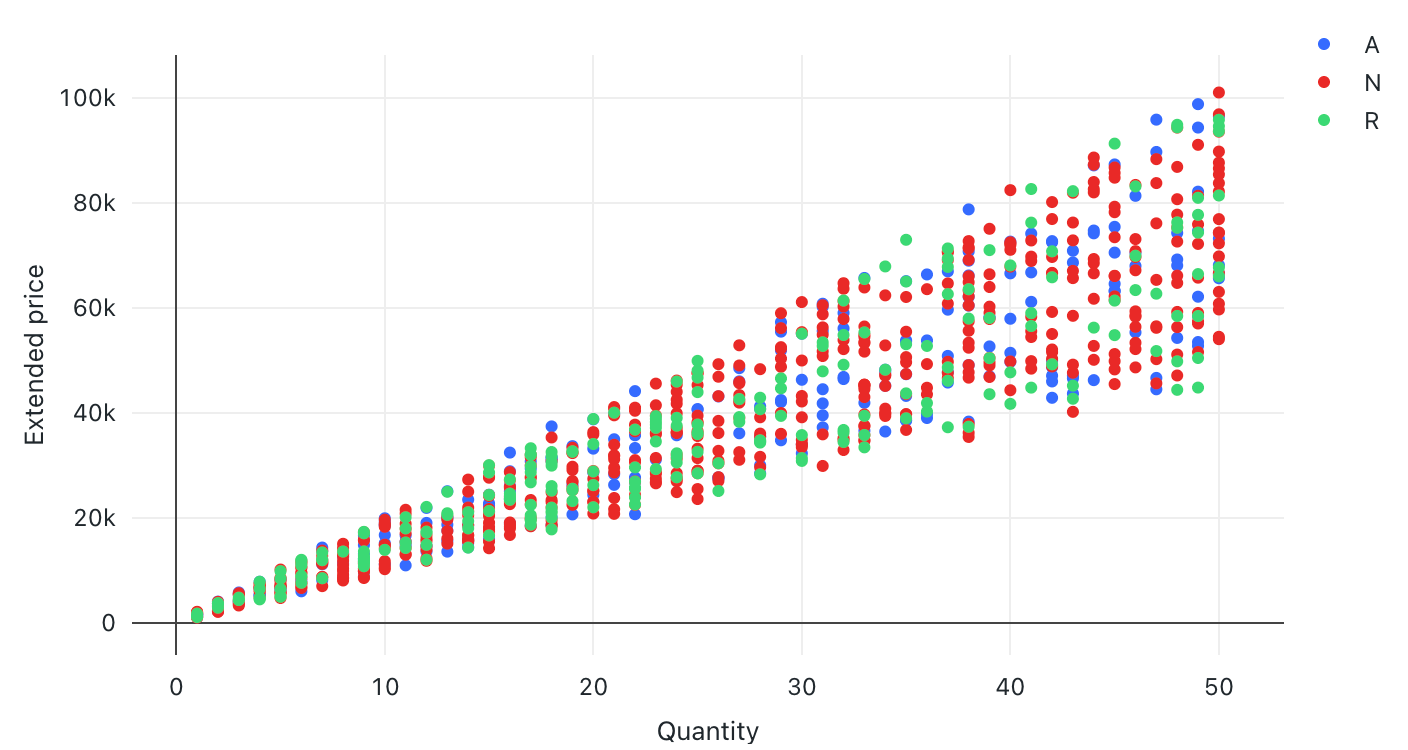
Konfigurationsvärden: För den här punktdiagramvisualiseringen angavs följande värden:
- X-kolumn (datamängdskolumn):
l_quantity - Y-kolumn (datamängdskolumn):
l_extendedprice - Gruppera efter (datamängdskolumn):
l_returnflag - X-axelnamn (åsidosätt standardvärde):
Quantity - Y-axelnamn (åsidosätt standardvärde):
Extended price
Konfigurationsalternativ: Information om konfigurationsalternativ för punktdiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här punktdiagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.lineitem
Bubbeldiagram
Bubbeldiagram är punktdiagram där storleken på varje punktmarkör återspeglar ett relevant mått.
Kommentar
Bubbeldiagram stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen.
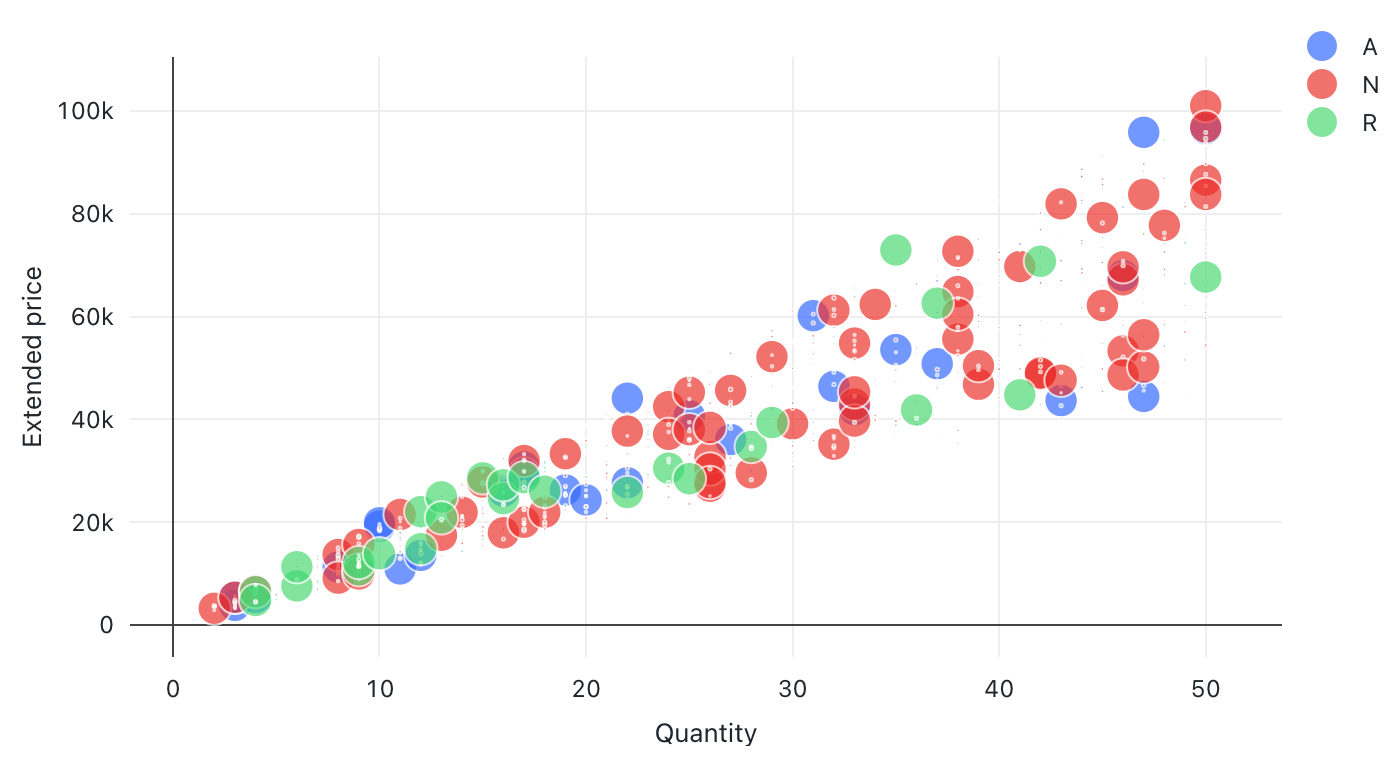
Konfigurationsvärden: För den här visualiseringen av bubbeldiagram har följande värden angetts:
- X (datauppsättningskolumn):
l_quantity - Y-kolumner (datamängdskolumn):
l_extendedprice - Gruppera efter (datamängdskolumn):
l_returnflag - Kolumn för bubbelstorlek (datamängdskolumn):
l_tax - Koefficient för bubbelstorlek: 20
- Bubbelstorlek proportionell mot:
Area - X-axelnamn (åsidosätt standardvärde):
Quantity - Y-axelnamn (åsidosätt standardvärde):
Extended price
Konfigurationsalternativ: Information om konfigurationsalternativ för bubbeldiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här visualiseringen av bubbeldiagram användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.lineitem where l_quantity < 45
Rutdiagram
Visualiseringen i rutdiagrammet visar distributionssammanfattningen av numeriska data, eventuellt grupperade efter kategori. Med hjälp av en visualisering av rutor kan du snabbt jämföra värdeintervallen mellan kategorier och visualisera lokalitets-, spridnings- och skevhetsgrupperna för värdena via deras kvarttiler. I varje ruta visar den mörkare linjen mellankvartilområdet. Mer information om hur du tolkar visualiseringar av rutor finns i boxdiagramsartikeln på Wikipedia.
Kommentar
Låddiagram stöder endast aggregering för upp till 64 000 rader. Om en datauppsättning är större än 64 000 rader trunkeras data.
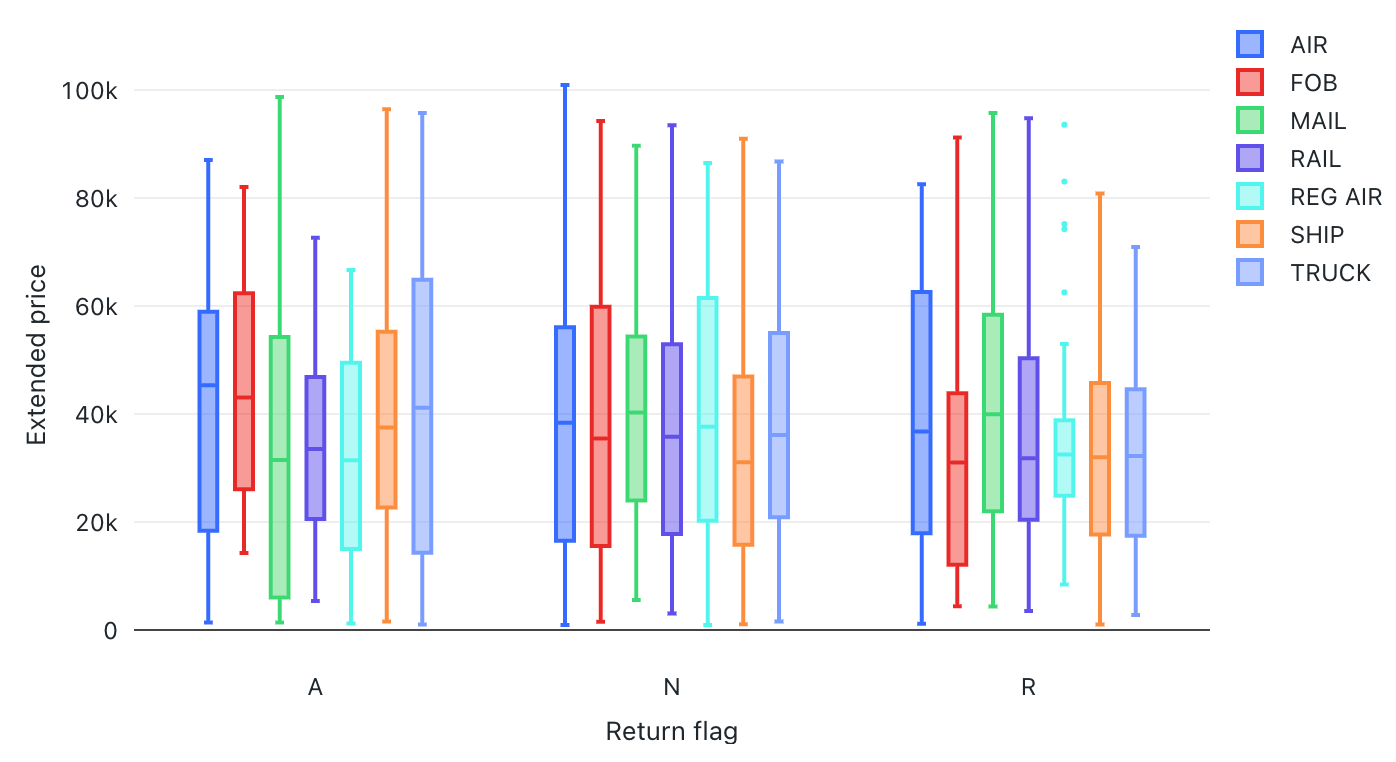
Konfigurationsvärden: Följande värden har angetts för visualiseringen av det här rutdiagrammet:
- X-kolumn (datamängdskolumn):
l_returnflag - Y-kolumner (datamängdskolumn):
l_extendedprice - Gruppera efter (datamängdskolumn):
l_shipmode - X-axelnamn (åsidosätt standardvärde):
Return flag - Y-axelnamn (åsidosätt standardvärde):
Extended price
Konfigurationsalternativ: För konfigurationsalternativ för rutdiagram, se alternativ för rutdiagramkonfiguation.
SQL-fråga: För den här visualiseringen av rutdiagram användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.lineitem
Kombinationsdiagram
Kombinationsdiagram kombinerar linje- och stapeldiagram för att presentera ändringarna över tid med proportionalitet.
Kommentar
Kombinationsdiagrammen stöder backend-aggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan avkortning av resultatuppsättningen.
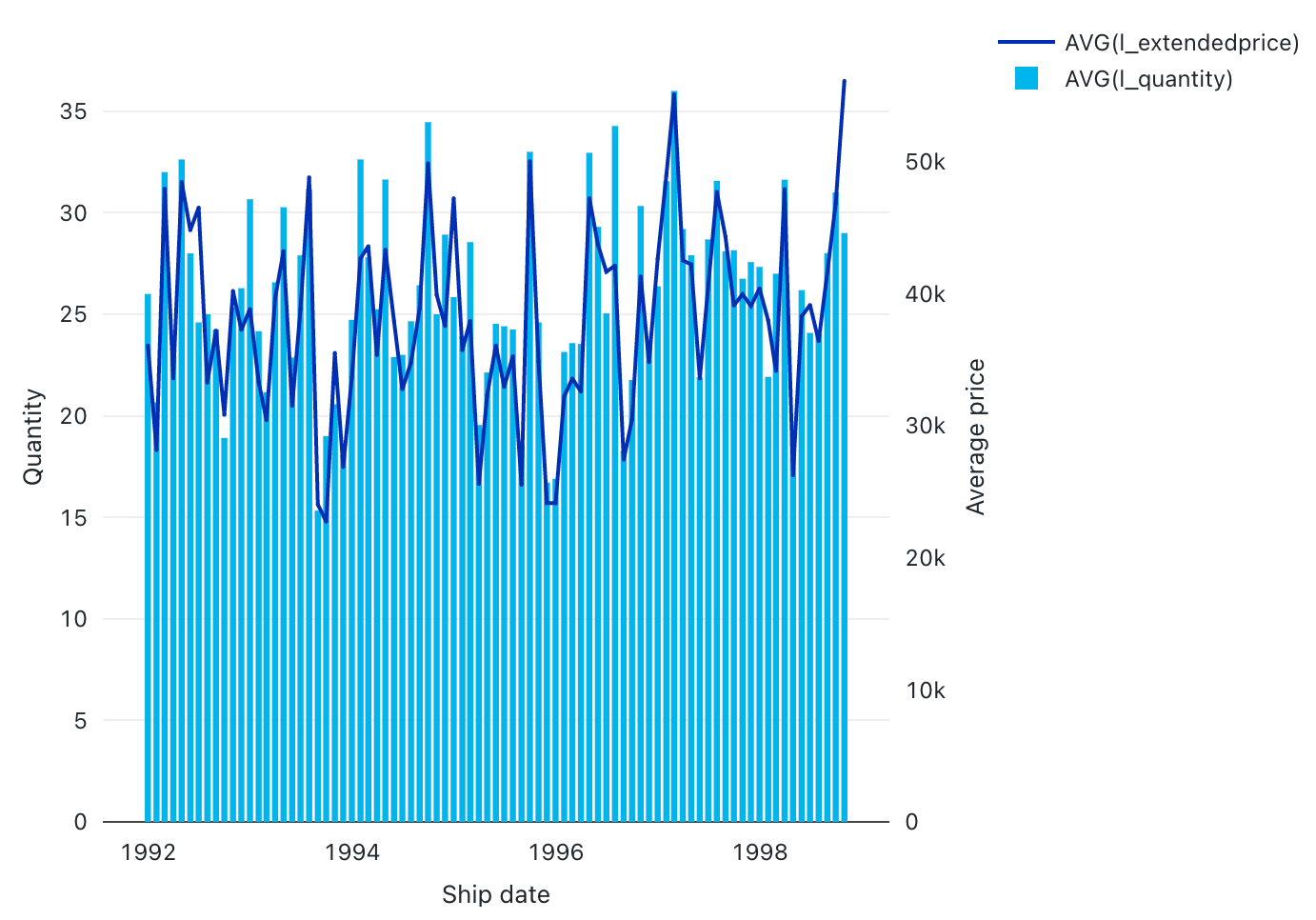
Konfigurationsvärden: För den här visualiseringen av kombinationsdiagram har följande värden angetts:
- X-kolumn:
- Datauppsättningskolumn:
l_shipdate - Datumnivå:
Months
- Datauppsättningskolumn:
- Y-kolumner:
- Första datamängdskolumnen:
l_extendedprice - Sammansättningstyp: medelvärde
- Andra datamängdskolumnen:
l_quantity - Sammansättningstyp: medelvärde
- Första datamängdskolumnen:
- X-axelnamn (åsidosätt standardvärde):
Ship date - Vänster Y-axelnamn (åsidosätt standardvärde):
Quantity - Höger Y-axelnamn (åsidosätt standardvärde):
Average price - Serie:
- Order1 (datauppsättningskolumn):
AVG(l_extendedprice) - Y-axel: höger
- Typ: Rad
- Order2 (kolumn i datasetet):
AVG(l_quantity) - Y-axel: vänster
- Typ: Stapel
- Order1 (datauppsättningskolumn):
Konfigurationsalternativ: Information om konfigurationsalternativ för kombinationsdiagram finns i konfigurationsalternativ för diagram.
SQL-fråga: För den här kombinationsdiagramvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.lineitem
Kohortanalys
En kohortanalys undersöker resultatet av förutbestämda grupper, så kallade kohorter, när de går igenom en uppsättning steg. Kohortvisualiseringen aggregeras endast över datum (det tillåter månatliga aggregeringar). Den utför inte några andra aggregeringar av data i resultatuppsättningen. Alla andra aggregeringar görs i själva frågan.
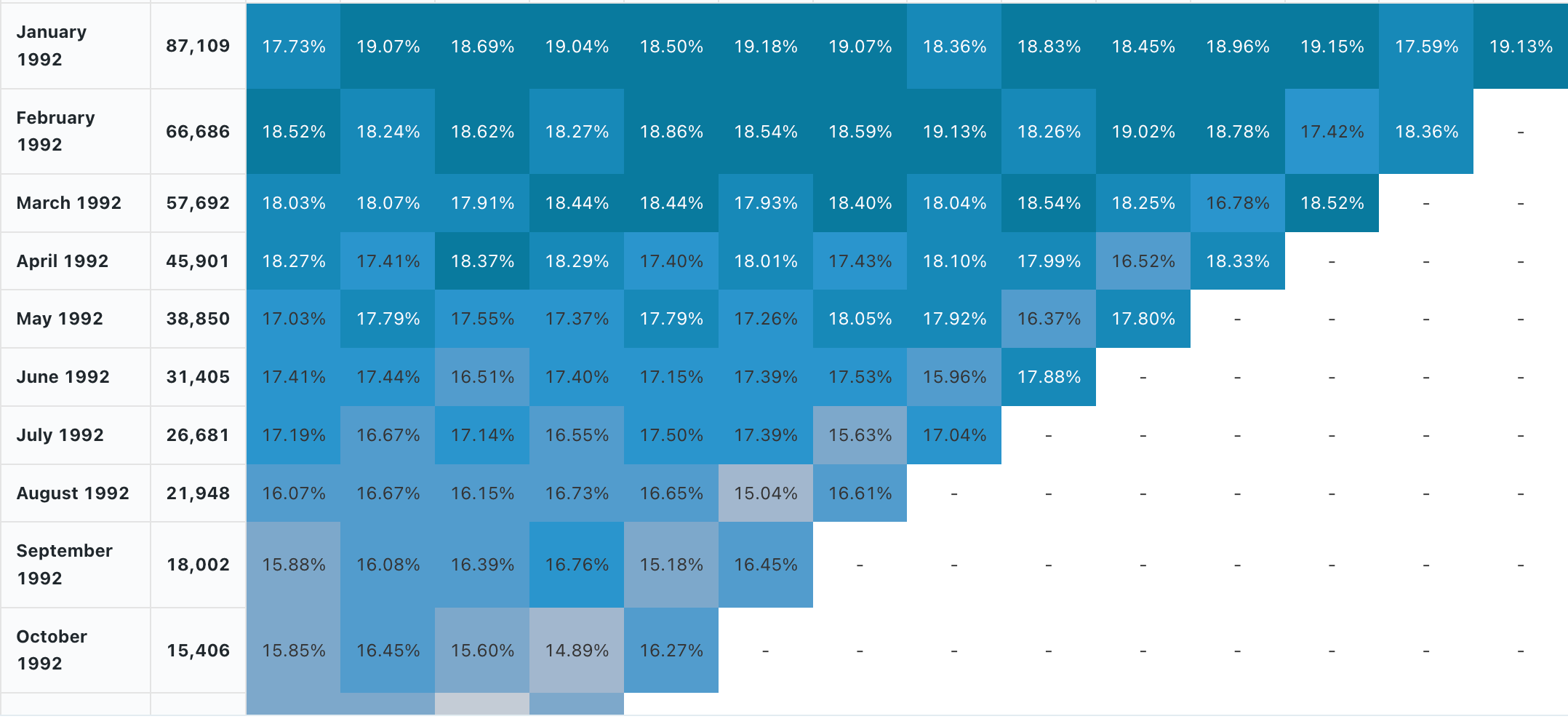
Konfigurationsvärden: För den här kohortvisualiseringen angavs följande värden:
- Datum (bucket) (databaskolumn):
cohort_month - Fas (databaskolumn):
months - Bucketpopulationsstorlek (databaskolumn):
size - Stegvärde (databaskolumn):
active - Tidsintervall:
monthly
Konfigurationsalternativ: Information om konfigurationsalternativ för kohort finns i configuationsalternativ för kohortdiagram.
SQL-fråga: För den här kohortvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
-- match each customer with its cohort by month
with cohort_dates as (
SELECT o_custkey, min(date_trunc('month', o_orderdate)) as cohort_month
FROM samples.tpch.orders
GROUP BY 1
),
-- find the size of each cohort
cohort_size as (
SELECT cohort_month, count(distinct o_custkey) as size
FROM cohort_dates
GROUP BY 1
)
-- for each cohort and month thereafter, find the number of active customers
SELECT
cohort_dates.cohort_month,
ceil(months_between(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month)) as months,
count(distinct samples.tpch.orders.o_custkey) as active,
first(size) as size
FROM samples.tpch.orders
left join cohort_dates on samples.tpch.orders.o_custkey = cohort_dates.o_custkey
left join cohort_size on cohort_dates.cohort_month = cohort_size.cohort_month
WHERE datediff(date_trunc('month', samples.tpch.orders.o_orderdate), cohort_dates.cohort_month) != 0
GROUP BY 1, 2
ORDER BY 1, 2
Visning av räknare
Räknare visar ett enda värde på ett framträdande sätt, med ett alternativ för att jämföra dem med ett målvärde. Om du vill använda räknare anger du vilken rad med data som ska visas i räknarvisualiseringen för Value Column och Target Column.
Kommentar
Räknaren stöder endast sammansättning för upp till 64 000 rader. Om en datauppsättning är större än 64 000 rader trunkeras data.
Konfigurationsvärden: För den här räknarvisualiseringen angavs följande värden:
- Värdekolumn
- Datauppsättningskolumn:
avg(o_totalprice) - Rad 1:
- Datauppsättningskolumn:
- Målkolumn:
- Datauppsättningskolumn:
avg(o_totalprice) - Rad 2:
- Datauppsättningskolumn:
- Formatera målvärde: Aktivera
SQL-fråga: För den här räknarvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select o_orderdate, avg(o_totalprice)
from samples.tpch.orders
GROUP BY 1
ORDER BY 1 DESC
Trattvisualisering
Trattvisualiseringen hjälper till att analysera ändringen i ett mått i olika steg. För att använda tratten anger du en step-kolumn och en value-kolumn.
Kommentar
Tratten stöder endast sammansättning för upp till 64 000 rader. Om en datauppsättning är större än 64 000 rader trunkeras data.
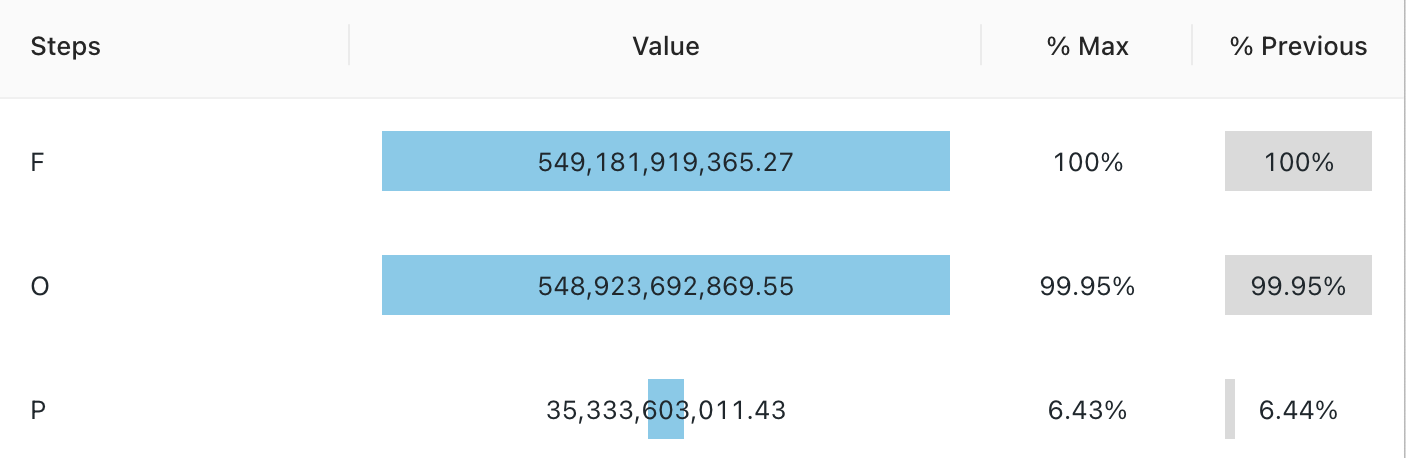
Konfigurationsvärden: För den här trattvisualiseringen angavs följande värden:
- Stegkolumn (datauppsättningskolumn):
o_orderstatus - Värdekolumn (datamängdskolumn):
Revenue
SQL-fråga: För den här trattvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
SELECT o_orderstatus, sum(o_totalprice) as Revenue
FROM samples.tpch.orders
GROUP BY 1
visualisering av karta (Choropleth)
I choropleth-visualiseringar färgas geografiska platser, till exempel länder eller stater, enligt aggregerade värden för varje nyckelkolumn. Frågan måste returnera geografiska platser efter namn.
Kommentar
Choropleth-visualiseringar utför inga aggregeringar av data i resultatuppsättningen. Alla sammansättningar måste beräknas i själva frågan.
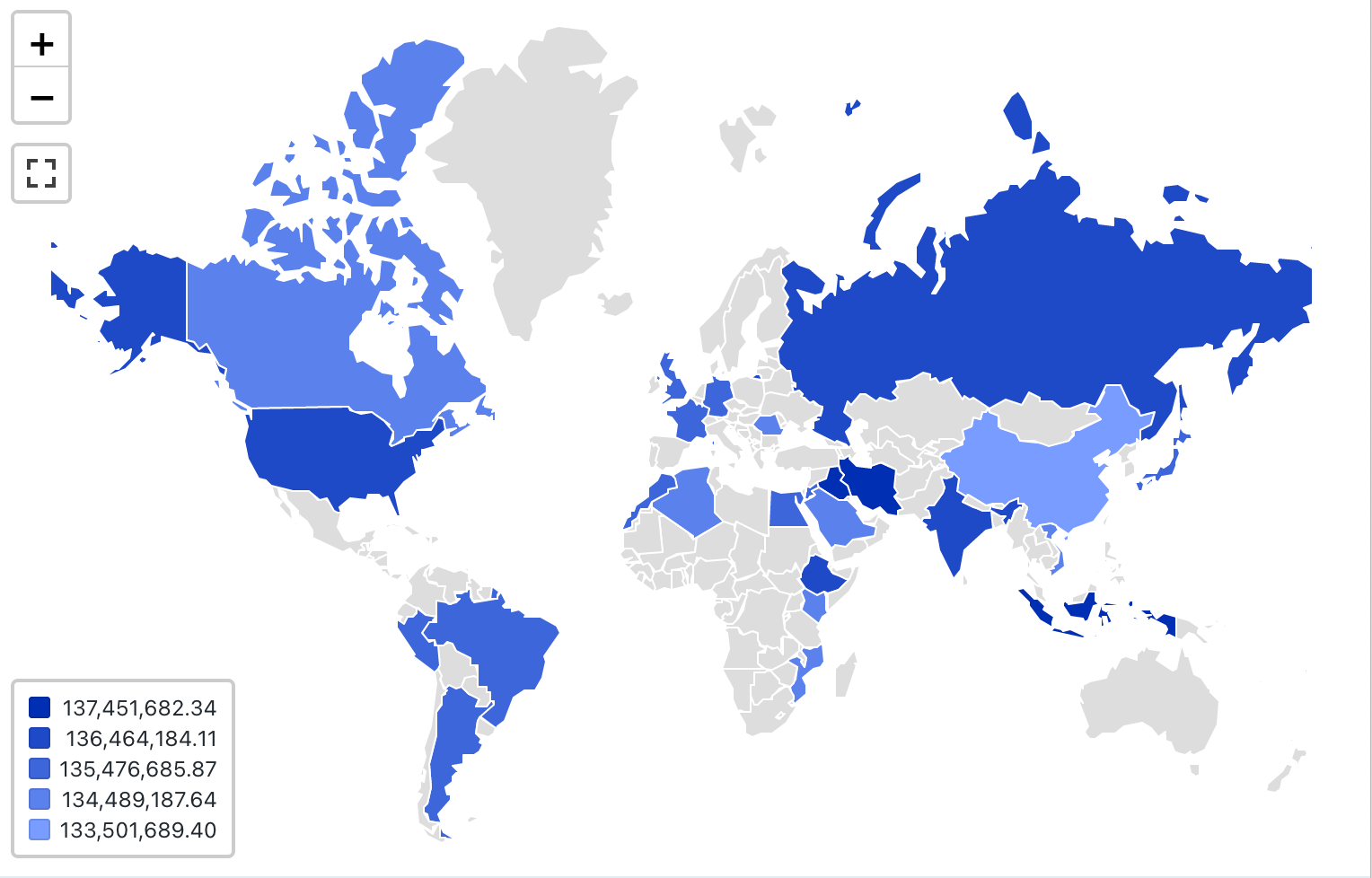
Konfigurationsvärden: För den här choropleth-visualiseringen angavs följande värden:
- Karta (datauppsättningskolumn):
Countries - Geografisk kolumn (datamängdskolumn):
Country - Geografisk typ: Kort namn
- Värdekolumn (datamängdskolumn):
Revenue - Klustringsläge: likvärdigt
Konfigurationsalternativ: Information om konfigurationsalternativ för choropleth finns i alternativ för choropleth configuation.
SQL-fråga: För den här choropleth-visualiseringen användes följande SQL-fråga för att generera datauppsättningen.
SELECT
initcap(n_name) as Country,
sum(c_acctbal)
FROM samples.tpch.customer
join samples.tpch.nation where n_nationkey = c_nationkey
GROUP BY 1
Visualisering av markörkarta
I markörvisualiseringar placeras en markör vid en uppsättning koordinater på kartan. Frågeresultatet måste returnera latitud- och longitudpar.
Kommentar
Markören utför inga aggregeringar av data i resultatuppsättningen. Alla sammansättningar måste beräknas i själva frågan.
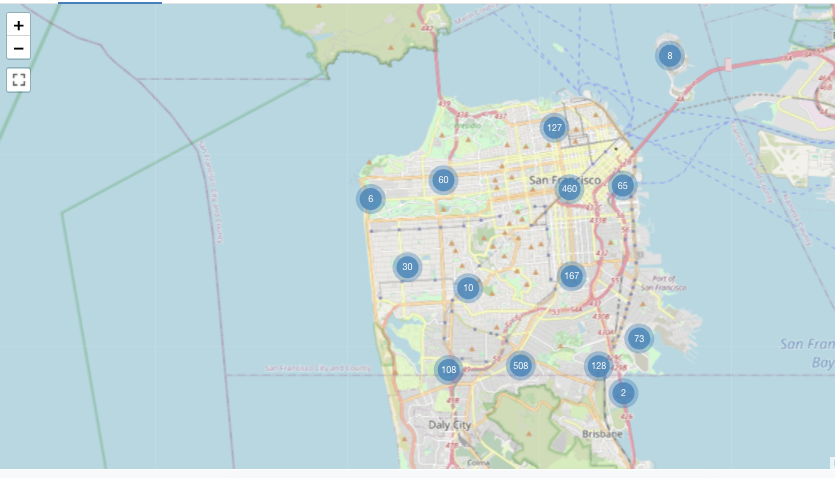
Det här markörexemplet genereras från en datamängd som innehåller både latitud- och longitudvärden – som inte är tillgängliga i Databricks-exempeldatauppsättningarna. Konfigurationsalternativ för choropleth finns i alternativ för markörkonfiguration.
visualisering av pivottabell
En pivottabellvisualisering aggregerar poster från ett frågeresultat till en ny tabellvisning. Det liknar PIVOT eller GROUP BY -instruktioner i SQL. Du konfigurerar pivottabellvisualiseringen med dra och släpp-fält.
Kommentar
Pivottabeller stöder serverdelsaggregeringar, vilket ger stöd för frågor som returnerar mer än 64 000 rader data utan trunkering av resultatuppsättningen. Pivottabellen (äldre) stöder dock endast aggregering för upp till 64 000 rader. Om en datauppsättning är större än 64 000 rader trunkeras data.
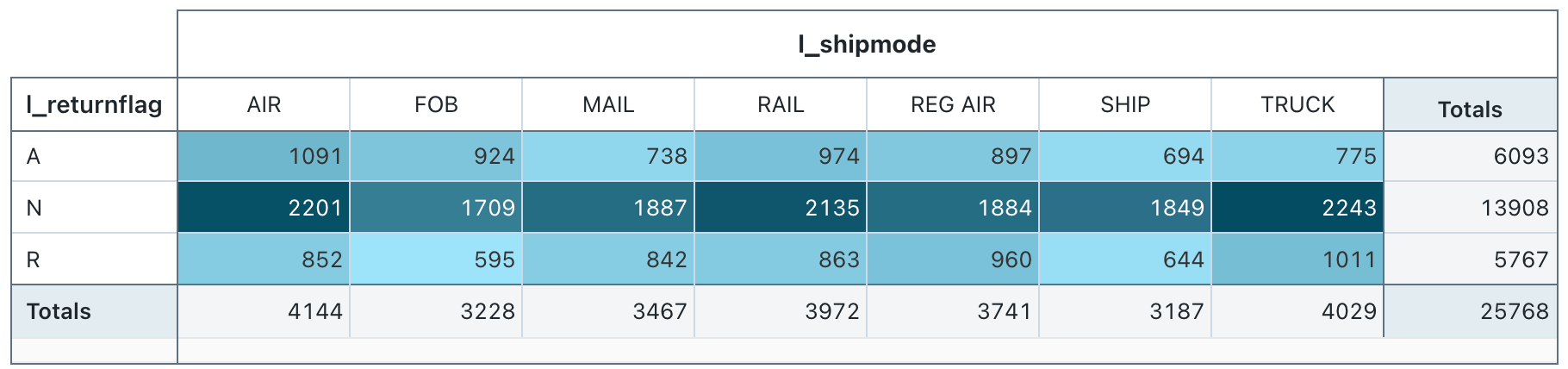
Konfigurationsvärden: För den här pivottabellvisualiseringen har följande värden angetts:
- Välj rader (datamängdskolumn):
l_returnflag - Välj kolumner (datauppsättningskolumn):
l_shipmode - Cell
- Datauppsättningskolumn:
l_quantity - Sammansättningstyp: Summa
- Färgceller efter värde: På
- Datauppsättningskolumn:
SQL-fråga: För den här pivottabellvisualiseringen användes följande SQL-fråga för att generera datauppsättningen.
select * from samples.tpch.lineitem
Sankey
Ett sankey-diagram visualiserar flödet från en uppsättning värden till en annan.
Kommentar
Sankey-visualiseringar utför inga aggregeringar av data i resultatuppsättningen. Alla sammansättningar måste beräknas i själva frågan.

SQL-fråga: För den här Sankey-visualiseringen användes följande SQL-fråga för att generera datauppsättningen.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Solstrålesekvens
Ett sunburst-diagram hjälper till att visualisera hierarkiska data med hjälp av koncentriska cirklar.
Kommentar
Sunburst-sekvensen utför inga aggregeringar av data i resultatuppsättningen. Alla sammansättningar måste beräknas i själva frågan.
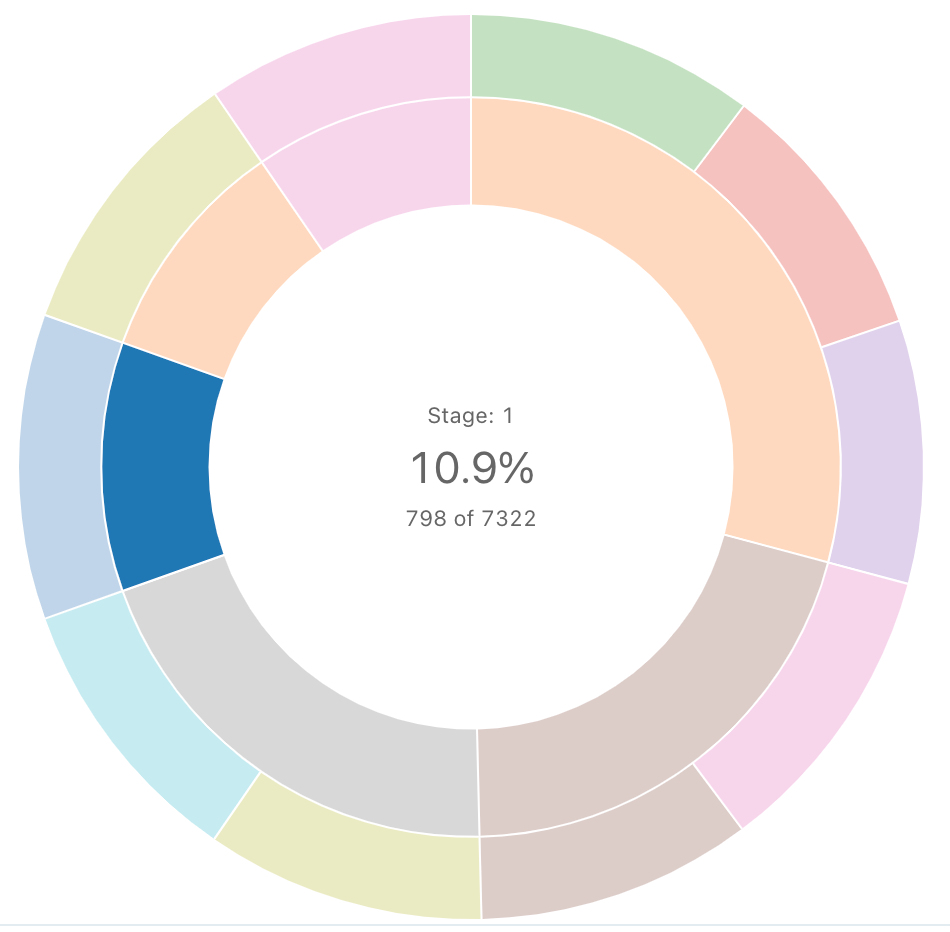
SQL-fråga: För den här sunburst-visualiseringen användes följande SQL-fråga för att generera datauppsättningen.
SELECT pickup_zip as stage1, dropoff_zip as stage2, sum(fare_amount) as value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10
Bord
Tabellvisualiseringen visar data i en standardtabell, men med möjlighet att manuellt ordna om, dölja och formatera data. Se Tabellalternativ.
Kommentar
Tabellvisualiseringar utför inga aggregeringar av data i resultatuppsättningen. Alla sammansättningar måste beräknas i själva frågan.
Information om konfigurationsalternativ för tabeller finns i tabellkonfigurationsalternativ.
Word-moln
Ett ordmoln representerar visuellt hur ofta ett ord förekommer i data.
Kommentar
Word Cloud stöder endast aggregering för upp till 64 000 rader. Om en datauppsättning är större än 64 000 rader trunkeras data.
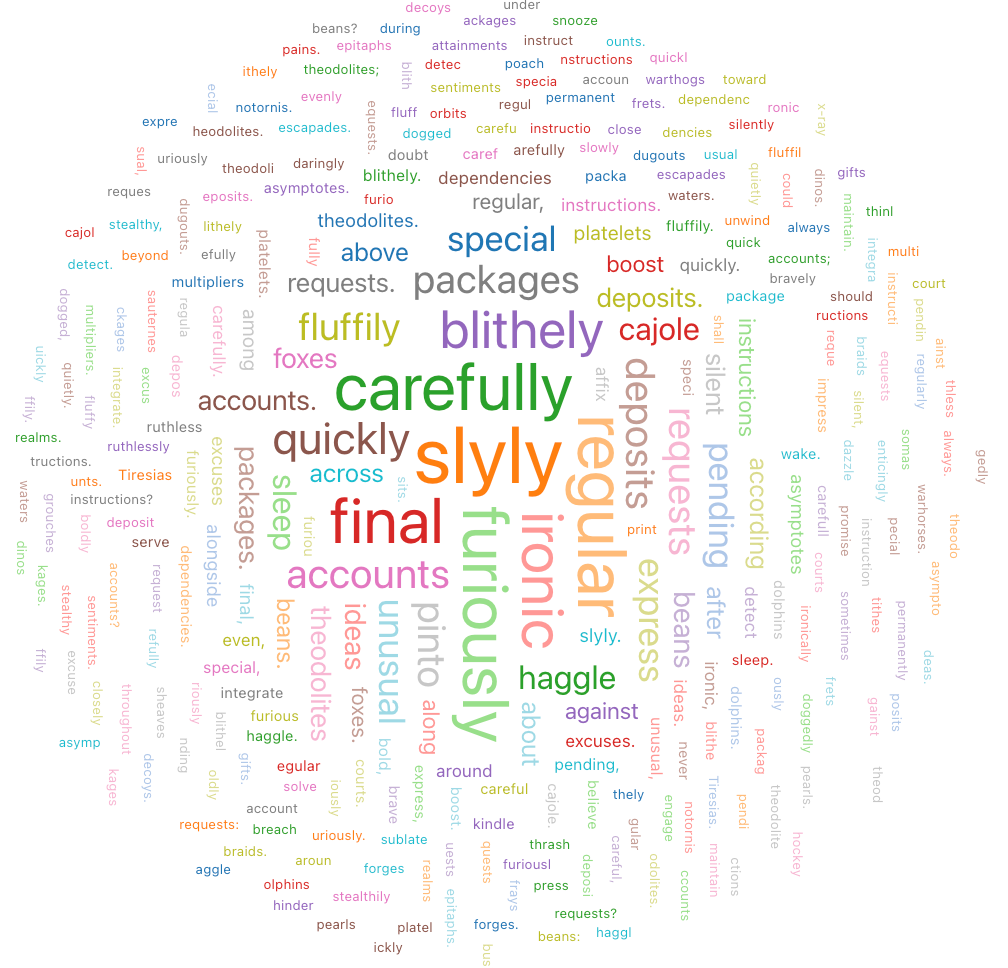
Konfigurationsvärden: För den här ordbolmsvisualiseringen har följande värden angetts: test
- Ordkolumn (datauppsättningskolumn):
o_comment - Ordlängdsgräns: Min = 5
- Frekvensgräns: Min = 2
SQL-fråga: För den här ordmolnsvisualiseringen användes den följande SQL-frågan för att generera datauppsättningen.
select * from samples.tpch.orders