Ange jobb i din pipeline
Azure DevOps Services | Azure DevOps Server 2022 – Azure DevOps Server 2019
Du kan organisera din pipeline i jobb. Varje pipeline har minst ett jobb. Ett jobb är en serie steg som körs sekventiellt som en enhet. Med andra ord är ett jobb den minsta arbetsenheten som kan schemaläggas att köras.
Mer information om viktiga begrepp och komponenter som utgör en pipeline finns i Viktiga begrepp för nya Azure Pipelines-användare.
Azure Pipelines stöder inte jobbprioritet för YAML-pipelines. Om du vill styra när jobb körs kan du ange villkor och beroenden.
Definiera ett enda jobb
I det enklaste fallet har en pipeline ett enda jobb. I så fall behöver du inte uttryckligen använda nyckelordet job om du inte använder en mall. Du kan ange stegen direkt i YAML-filen.
Den här YAML-filen har ett jobb som körs på en Microsoft-värdbaserad agent och utdata Hello world.
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Du kanske vill ange fler egenskaper för jobbet. I så fall kan du använda nyckelordet job .
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Din pipeline kan ha flera jobb. I så fall använder du nyckelordet jobs .
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
Din pipeline kan ha flera steg, var och en med flera jobb. I så fall använder du nyckelordet stages .
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
Den fullständiga syntaxen för att ange ett jobb är:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
Den fullständiga syntaxen för att ange ett jobb är:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Om det primära syftet med jobbet är att distribuera din app (i stället för att skapa eller testa din app) kan du använda en särskild typ av jobb som kallas distributionsjobb.
Syntaxen för ett distributionsjobb är:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Även om du kan lägga till steg för distributionsuppgifter i en jobrekommenderar vi att du i stället använder ett distributionsjobb. Ett distributionsjobb har några fördelar. Du kan till exempel distribuera till en miljö, vilket inkluderar fördelar som att kunna se historiken för det du har distribuerat.

Typer av jobb
Jobb kan vara av olika typer, beroende på var de körs.
- Agentpoolsjobb körs på en agent i en agentpool.
- Serverjobb körs på Azure DevOps Server.
- Containerjobb körs i en container på en agent i en agentpool. Mer information om hur du väljer containrar finns i Definiera containerjobb.
Agentpooljobb
Det här är den vanligaste typen av jobb och de körs på en agent i en agentpool.
- När du använder Microsoft-värdbaserade agenter får varje jobb i en pipeline en ny agent.
- Använd krav med lokalt installerade agenter för att ange vilka funktioner en agent måste ha för att köra jobbet. Du kan få samma agent för efterföljande jobb, beroende på om det finns fler än en agent i din agentpool som matchar pipelinens krav. Om det bara finns en agent i poolen som matchar pipelinens krav väntar pipelinen tills agenten är tillgänglig.
Kommentar
Krav och funktioner är utformade för användning med lokalt installerade agenter så att jobb kan matchas med en agent som uppfyller kraven för jobbet. När du använder Microsoft-värdbaserade agenter väljer du en avbildning för agenten som matchar kraven för jobbet, så även om det är möjligt att lägga till funktioner i en Microsoft-värdbaserad agent behöver du inte använda funktioner med Microsoft-värdbaserade agenter.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
Eller flera krav:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Läs mer om agentfunktioner.
Serverjobb
Uppgifter i ett serverjobb samordnas av och körs på servern (Azure Pipelines eller TFS). Ett serverjobb kräver inte någon agent eller måldatorer. Endast ett fåtal uppgifter stöds i ett serverjobb nu. Den maximala tiden för ett serverjobb är 30 dagar.
Uppgifter som stöds av agentlösa jobb
För närvarande stöds endast följande uppgifter direkt för agentlösa jobb:
- Fördröj uppgift
- Anropa Azure Function-uppgift
- Anropa REST API-uppgift
- Manuell valideringsuppgift
- Publicera till Azure Service Bus-uppgift
- Fråga Azure Monitor-aviseringar
- Frågeuppgift för arbetsobjekt
Eftersom aktiviteter är utökningsbara kan du lägga till fler agentlösa uppgifter med hjälp av tillägg. Standardtidsgränsen för agentlösa jobb är 60 minuter.
Den fullständiga syntaxen för att ange ett serverjobb är:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Du kan också använda den förenklade syntaxen:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Beroenden
När du definierar flera jobb i en enda fas kan du ange beroenden mellan dem. Pipelines måste innehålla minst ett jobb utan beroenden. Som standard körs Azure DevOps YAML-pipelinejobb parallellt om inte dependsOn värdet har angetts.
Kommentar
Varje agent kan bara köra ett jobb i taget. Om du vill köra flera jobb parallellt måste du konfigurera flera agenter. Du behöver också tillräckligt med parallella jobb.
Syntaxen för att definiera flera jobb och deras beroenden är:
jobs:
- job: string
dependsOn: string
condition: string
Exempeljobb som skapas sekventiellt:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Exempeljobb som skapas parallellt (inga beroenden):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Exempel på fläkt ut:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Exempel på inaktivering:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
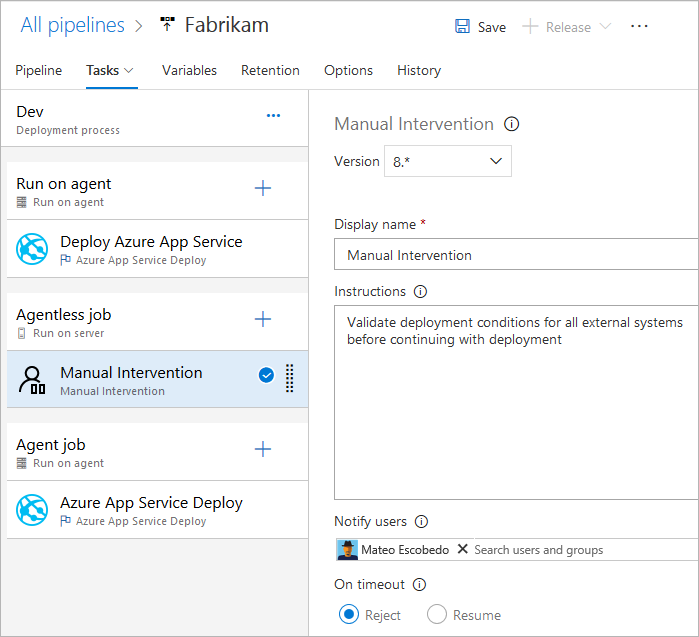
Villkor
Du kan ange under vilka villkor varje jobb körs. Som standard körs ett jobb om det inte är beroende av något annat jobb, eller om alla jobb som det är beroende av har slutförts och slutförts. Du kan anpassa det här beteendet genom att tvinga ett jobb att köras även om ett tidigare jobb misslyckas eller genom att ange ett anpassat villkor.
Exempel för att köra ett jobb baserat på statusen för att köra ett tidigare jobb:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Exempel på användning av ett anpassat villkor:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
Du kan ange att ett jobb ska köras baserat på värdet för en utdatavariabel som angetts i ett tidigare jobb. I det här fallet kan du bara använda variabler som angetts i direkt beroende jobb:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Timeouter
För att undvika att ta upp resurser när jobbet inte svarar eller väntar för länge är det en bra idé att ange en gräns för hur länge jobbet får köras. Använd timeout-inställningen för jobb för att ange gränsen i minuter för att köra jobbet. Om värdet anges till noll kan jobbet köras:
- För evigt på lokalt installerade agenter
- I 360 minuter (6 timmar) på Microsoft-värdbaserade agenter med ett offentligt projekt och en offentlig lagringsplats
- Under 60 minuter på Microsoft-värdbaserade agenter med ett privat projekt eller en privat lagringsplats (om inte ytterligare kapacitet betalas för)
Tidsgränsen börjar när jobbet börjar köras. Det inkluderar inte den tid då jobbet placeras i kö eller väntar på en agent.
timeoutInMinutes Tillåter att en gräns anges för jobbkörningstiden. När det inte anges är standardvärdet 60 minuter. När 0 anges används den maximala gränsen (beskrivs ovan).
cancelTimeoutInMinutes Tillåter att en gräns anges för jobbets avbrutna tid när distributionsaktiviteten är inställd på att fortsätta köras om en tidigare aktivitet misslyckades. När det inte anges är standardvärdet 5 minuter. Värdet ska vara i intervallet 1 till 35790 minuter.
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Tidsgränser har följande prioritetsnivå.
- På Microsoft-värdbaserade agenter är jobben begränsade i hur länge de kan köras baserat på projekttyp och om de körs med ett betalt parallellt jobb. När tidsgränsintervallet för Microsoft-värdbaserat jobb förflutit avslutas jobbet. På Microsoft-värdbaserade agenter kan jobb inte köras längre än det här intervallet, oavsett eventuella tidsgränser på jobbnivå som anges i jobbet.
- Tidsgränsen som konfigurerats på jobbnivå anger den maximala varaktigheten för jobbet som ska köras. När tidsgränsintervallet på jobbnivå förflutit avslutas jobbet. Om jobbet körs på en Microsoft-värdbaserad agent har det ingen effekt att ange tidsgränsen för jobbnivå till ett intervall som är större än den inbyggda tidsgränsen på Microsoft-värdbaserad jobbnivå och tidsgränsen för Det Microsoft-värdbaserade jobbet används.
- Du kan också ange tidsgränsen för varje aktivitet individuellt – se alternativ för aktivitetskontroll. Om tidsgränsintervallet på jobbnivå förflutit innan aktiviteten slutförs avslutas det jobb som körs, även om aktiviteten har konfigurerats med ett längre tidsgränsintervall.
Konfiguration av flera jobb
Från ett enda jobb som du skapar kan du köra flera jobb på flera agenter parallellt. Vissa exempel inkluderar:
Flerkonfigurationsversioner: Du kan skapa flera konfigurationer parallellt. Du kan till exempel skapa en Visual C++-app för både
debugochreleasekonfigurationer på bådex86plattformar ochx64plattformar. Mer information finns i Visual Studio Build – flera konfigurationer för flera plattformar.Distributioner med flera konfigurationer: Du kan köra flera distributioner parallellt, till exempel till olika geografiska regioner.
Testning med flera konfigurationer: Du kan köra test av flera konfigurationer parallellt.
Flera konfigurationer genererar alltid minst ett jobb, även om en variabel för flera konfigurationer är tom.
Strategin matrix gör att ett jobb kan skickas flera gånger med olika variabeluppsättningar. Taggen maxParallel begränsar mängden parallellitet. Följande jobb skickas tre gånger med värdena för Plats och Webbläsare angivna. Men bara två jobb körs samtidigt.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Kommentar
Matriskonfigurationsnamn (som US_IE ovan) får endast innehålla grundläggande latinska alfabetsbeteckningar (A-Z, a-z), siffror och understreck (_).
De måste börja med en bokstav.
Dessutom måste de vara högst 100 tecken.
Du kan också använda utdatavariabler för att generera en matris. Detta kan vara praktiskt om du behöver generera matrisen med hjälp av ett skript.
matrix accepterar ett körningsuttryck som innehåller ett strängifierat JSON-objekt.
Det JSON-objektet måste, när det expanderas, matcha matrissyntaxen.
I exemplet nedan har vi hårdkodat JSON-strängen, men den kan genereras av ett skriptspråk eller kommandoradsprogram.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Skivning
Ett agentjobb kan användas för att köra en uppsättning tester parallellt. Du kan till exempel köra en stor uppsättning med 1 000 tester på en enda agent. Eller så kan du använda två agenter och köra 500 tester på var och en parallellt.
För att tillämpa segmentering bör uppgifterna i jobbet vara tillräckligt smarta för att förstå vilken sektor de tillhör.
Visual Studio-testaktiviteten är en sådan uppgift som stöder testslicering. Om du har installerat flera agenter kan du ange hur Visual Studio-testaktiviteten ska köras parallellt på dessa agenter.
Strategin parallel gör att ett jobb kan dupliceras många gånger.
Variabler System.JobPositionInPhase och System.TotalJobsInPhase läggs till i varje jobb. Variablerna kan sedan användas i skripten för att dela upp arbetet mellan jobben.
Se Parallell och flera körningar med agentjobb.
Följande jobb skickas fem gånger med värdena System.JobPositionInPhase för och System.TotalJobsInPhase inställt på rätt sätt.
jobs:
- job: Test
strategy:
parallel: 5
Jobbvariabler
Om du använder YAML kan du ange variabler i jobbet. Variablerna kan skickas till uppgiftsindata med hjälp av makrosyntaxen $(variableName) eller nås i ett skript med hjälp av stegvariabeln.
Här är ett exempel på hur du definierar variabler i ett jobb och använder dem i aktiviteter.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Information om hur du använder ett villkor finns i Ange villkor.
Arbetsyta
När du kör ett agentpooljobb skapas en arbetsyta på agenten. Arbetsytan är en katalog där den laddar ned källan, kör steg och genererar utdata. Arbetsytans katalog kan refereras till i ditt jobb med hjälp av Pipeline.Workspace variabeln . Under detta skapas olika underkataloger:
Build.SourcesDirectoryär där uppgifter laddar ned programmets källkod.Build.ArtifactStagingDirectoryär där uppgifter laddar ned artefakter som behövs för pipelinen eller laddar upp artefakter innan de publiceras.Build.BinariesDirectoryär där uppgifter skriver sina utdata.Common.TestResultsDirectoryär där uppgifter laddar upp sina testresultat.
Och $(Build.ArtifactStagingDirectory) $(Common.TestResultsDirectory) tas alltid bort och återskapas före varje version.
När du kör en pipeline på en lokalt installerad agent rensas som standard ingen annan underkatalog än $(Build.ArtifactStagingDirectory) och $(Common.TestResultsDirectory) rensas mellan två på varandra följande körningar. Därför kan du göra inkrementella byggen och distributioner, förutsatt att uppgifter implementeras för att använda det. Du kan åsidosätta det här beteendet med hjälp av workspace inställningen för jobbet.
Viktigt!
Alternativen för att rensa arbetsytan gäller endast för lokalt installerade agenter. Jobb körs alltid på en ny agent med Microsoft-värdbaserade agenter.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
När du anger något av clean alternativen tolkas de på följande sätt:
outputs: Ta bortBuild.BinariesDirectoryinnan du kör ett nytt jobb.resources: Ta bortBuild.SourcesDirectoryinnan du kör ett nytt jobb.all: Ta bort helaPipeline.Workspacekatalogen innan du kör ett nytt jobb.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Kommentar
Beroende på dina agentfunktioner och pipelinekrav kan varje jobb dirigeras till en annan agent i din egen värdbaserade pool. Därför kan du få en ny agent för efterföljande pipelinekörningar (eller faser eller jobb i samma pipeline), så att inte rensa är inte en garanti för att efterföljande körningar, jobb eller faser kommer att kunna komma åt utdata från tidigare körningar, jobb eller faser. Du kan konfigurera agentfunktioner och pipelinekrav för att ange vilka agenter som används för att köra ett pipelinejobb, men om det inte bara finns en enda agent i poolen som uppfyller kraven finns det ingen garanti för att efterföljande jobb använder samma agent som tidigare jobb. Mer information finns i Ange krav.
Förutom att rensa arbetsytan kan du även konfigurera rensning genom att konfigurera inställningen Rensa i användargränssnittet för pipelineinställningar. När inställningen Rensa är true, som också är dess standardvärde, motsvarar den att ange för varje utcheckningssteg clean: true i pipelinen. När du anger clean: truekör git clean -ffdx du följt av git reset --hard HEAD innan git-hämtningen. Så här konfigurerar du inställningen Rensa :
Redigera din pipeline, välj ...och välj Utlösare.
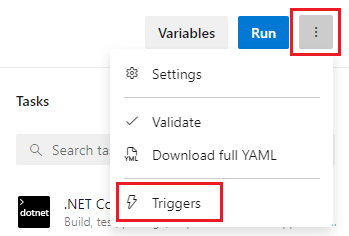
Välj YAML, Hämta källor och konfigurera önskad clean-inställning . Standardvärdet är sant.
Nedladdning av artefakt
Den här YAML-exempelfilen publicerar artefakten WebSite och laddar sedan ned artefakten till $(Pipeline.Workspace). Distributionsjobbet körs bara om build-jobbet lyckas.
# test and upload my code as an artifact named WebSite
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishBuildArtifacts@1
inputs:
pathtoPublish: '$(System.DefaultWorkingDirectory)'
artifactName: WebSite
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadBuildArtifacts@0
displayName: 'Download Build Artifacts'
inputs:
artifactName: WebSite
downloadPath: $(Pipeline.Workspace)
dependsOn: Build
condition: succeeded()
Information om hur du använder dependsOn och villkor finns i Ange villkor.
Åtkomst till OAuth-token
Du kan tillåta att skript som körs i ett jobb får åtkomst till den aktuella säkerhetstoken för Azure Pipelines eller TFS OAuth. Token kan användas för att autentisera till REST-API:et för Azure Pipelines.
OAuth-token är alltid tillgänglig för YAML-pipelines.
Den måste uttryckligen mappas till uppgiften eller steget med hjälp av env.
Här är ett exempel:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)