Installera och använda Hue i HDInsight Hadoop-kluster
Lär dig hur du installerar Hue i HDInsight-kluster och använder tunneltrafik för att dirigera begäranden till Hue.
Kommentar
Hue stöds inte i HDInsight 4.0 och senare.
Vad är Hue?
Hue är en uppsättning webbprogram som används för att interagera med ett Apache Hadoop-kluster. Du kan använda Hue för att bläddra i lagringen som är associerad med ett Hadoop-kluster (WASB, när det gäller HDInsight-kluster), köra Hive-jobb och Pig-skript och så vidare. Följande komponenter är tillgängliga med Hue-installationer i ett HDInsight Hadoop-kluster.
- Beeswax Hive-redigerare
- Apache Pig
- Metaarkivhanterare
- Apache Oozie
- FileBrowser (som pratar med WASB-standardcontainern)
- Jobbwebbläsare
Varning
Komponenter som medföljer HDInsight-klustret stöds fullt ut och Microsoft Support hjälper till att isolera och lösa problem som rör dessa komponenter.
Anpassade komponenter får kommersiellt rimligt stöd för att hjälpa dig att ytterligare felsöka problemet. Detta kan leda till att du löser problemet eller ber dig att engagera tillgängliga kanaler för öppen källkod tekniker där djup expertis för den tekniken finns. Det finns till exempel många community-webbplatser som kan användas, till exempel: Microsoft Q&A-frågesida för HDInsight, https://stackoverflow.com. Även Apache-projekt har projektwebbplatser på https://apache.org, till exempel: Hadoop.
Installera Hue med hjälp av skriptåtgärder
Använd informationen i tabellen nedan för din skriptåtgärd. Mer information om hur du använder skriptåtgärder finns i Anpassa HDInsight-kluster med Skriptåtgärder .
Kommentar
För att installera Hue på HDInsight-kluster är den rekommenderade huvudnodstorleken minst A4 (8 kärnor, 14 GB minne).
| Property | Värde |
|---|---|
| Typ av skript: | -Anpassade |
| Name | Installera Hue |
| Bash-skript-URI | https://hdiconfigactions.blob.core.windows.net/linuxhueconfigactionv02/install-hue-uber-v02.sh |
| Nodtyper: | Head |
Köra en Hive-fråga
I Hue-portalen väljer du Power Query-redigeraren och sedan Hive för att öppna Hive-redigeraren.
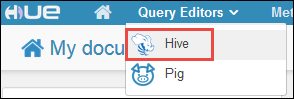
På fliken Assist under Databas bör du se hivesampletable. Det här är en exempeltabell som levereras med alla Hadoop-kluster i HDInsight. Ange en exempelfråga i den högra rutan och se utdata på fliken Resultat i fönstret nedan, enligt skärmbilden.
Du kan också använda fliken Diagram för att se en visuell representation av resultatet.
Bläddra i klusterlagringen
I Hue-portalen väljer du Filläsare i det övre högra hörnet i menyraden.
Som standard öppnas filwebbläsaren i katalogen /user/myuser . Välj snedstrecket direkt före användarkatalogen i sökvägen för att gå till roten för azure-lagringscontainern som är associerad med klustret.
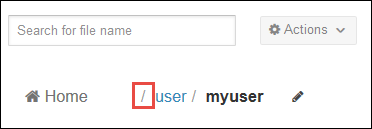
Högerklicka på en fil eller mapp för att se tillgängliga åtgärder. Använd knappen Ladda upp i det högra hörnet för att ladda upp filer till den aktuella katalogen. Använd knappen Nytt för att skapa nya filer eller kataloger.
Kommentar
Hue-filläsaren kan bara visa innehållet i standardcontainern som är associerad med HDInsight-klustret. Eventuella ytterligare lagringskonton/containrar som du kanske har associerat med klustret kommer inte att vara tillgängliga med hjälp av filläsaren. De ytterligare containrar som är associerade med klustret kommer dock alltid att vara tillgängliga för Hive-jobben. Om du till exempel anger kommandot dfs -ls wasbs://newcontainer@mystore.blob.core.windows.net i Hive-redigeraren kan du även se innehållet i ytterligare containrar. I det här kommandot är newcontainer inte standardcontainern som är associerad med ett kluster.
Viktigt!
Skriptet som används för att installera Hue installerar det endast på klustrets primära huvudnod.
Under installationen startas flera Hadoop-tjänster (HDFS, YARN, MR2, Oozie) om för att uppdatera konfigurationen. När skriptet har installerat Hue kan det ta lite tid innan andra Hadoop-tjänster startas. Detta kan påverka Hues prestanda från början. När alla tjänster har startats kommer Hue att fungera fullt ut.
Hue förstår inte Apache Tez-jobb, vilket är den aktuella standardinställningen för Hive. Om du vill använda MapReduce som Hive-körningsmotor uppdaterar du skriptet så att följande kommando används i skriptet:
set hive.execution.engine=mr;Med Linux-kluster kan du ha ett scenario där dina tjänster körs på den primära huvudnoden medan Resource Manager kan köras på den sekundära. Ett sådant scenario kan resultera i fel (visas nedan) när du använder Hue för att visa information om KÖRNINGsjobb i klustret. Du kan dock visa jobbinformationen när jobbet har slutförts.
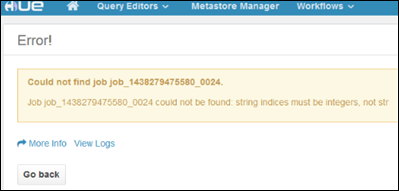
Detta beror på ett känt problem. Som en lösning kan du ändra Ambari så att den aktiva Resource Manager också körs på den primära huvudnoden.
Hue förstår WebHDFS medan HDInsight-kluster använder Azure Storage med .
wasbs://Det anpassade skriptet som används med skriptåtgärden installerar därför WebWasb, som är en WebHDFS-kompatibel tjänst för att prata med WASB. Så även om Hue-portalen säger HDFS på platser (som när du flyttar musen över filwebbläsaren), bör den tolkas som WASB.