Apache Spark-åtgärder som stöds av Hive Warehouse Connector i Azure HDInsight
Den här artikeln visar spark-baserade åtgärder som stöds av Hive Warehouse Connector (HWC). Alla exempel som visas körs via Apache Spark-gränssnittet.
Förutsättningar
Slutför installationsstegen för Hive Warehouse Connector.
Komma igång
Gör följande för att starta en spark-shell-session:
Använd ssh-kommandot för att ansluta till ditt Apache Spark-kluster. Redigera kommandot genom att ersätta CLUSTERNAME med namnet på klustret och ange sedan kommandot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netFrån ssh-sessionen kör du följande kommando för att notera
hive-warehouse-connector-assemblyversionen:ls /usr/hdp/current/hive_warehouse_connectorRedigera koden med den
hive-warehouse-connector-assemblyversion som identifierades ovan. Kör sedan kommandot för att starta spark-gränssnittet:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseNär du har startat spark-shell kan en Hive Warehouse Connector-instans startas med följande kommandon:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Skapa Spark DataFrames med Hive-frågor
Resultatet av alla frågor som använder HWC-biblioteket returneras som en DataFrame. Följande exempel visar hur du skapar en grundläggande hive-fråga.
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
Resultatet av frågan är Spark DataFrames, som kan användas med Spark-bibliotek som MLIB och SparkSQL.
Skriva ut Spark DataFrames till Hive-tabeller
Spark har inte inbyggt stöd för att skriva till Hive-hanterade ACID-tabeller. Men med HWC kan du skriva ut valfri DataFrame till en Hive-tabell. Du kan se den här funktionen på jobbet i följande exempel:
Skapa en tabell med namnet
sampletable_coloradooch ange dess kolumner med följande kommando:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()Filtrera tabellen
hivesampletabledär kolumnenstateärColoradolika med . Den här hive-frågan returnerar en Spark DataFrame och resultatet sparas i Hive-tabellensampletable_coloradomed hjälp avwritefunktionen .hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()Visa resultatet med följande kommando:
hive.table("sampletable_colorado").show()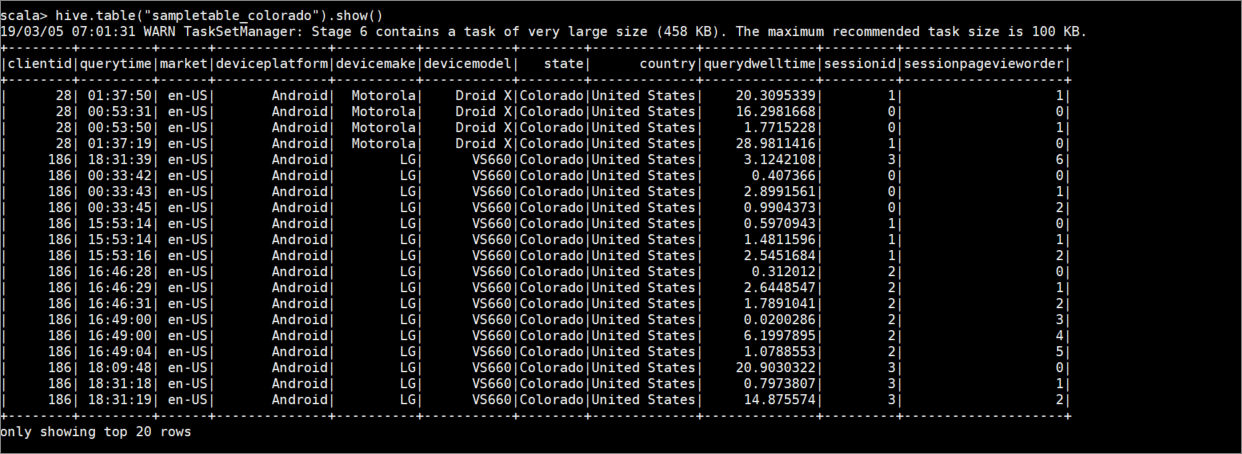
Strukturerade direktuppspelningsskrivningar
Med Hive Warehouse Connector kan du använda Spark-direktuppspelning för att skriva data till Hive-tabeller.
Viktigt!
Strukturerade direktuppspelningsskrivningar stöds inte i ESP-aktiverade Spark 4.0-kluster.
Följ stegen för att mata in data från en Spark-ström på localhost-port 9999 till en Hive-tabell via. Hive Warehouse Connector.
Starta en Spark-ström från ditt öppna Spark-gränssnitt med följande kommando:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()Generera data för Spark-strömmen som du skapade genom att göra följande:
- Öppna en andra SSH-session i samma Spark-kluster.
- I kommandotolken skriver du
nc -lk 9999. Det här kommandot användernetcatverktyget för att skicka data från kommandoraden till den angivna porten.
Gå tillbaka till den första SSH-sessionen och skapa en ny Hive-tabell för att lagra strömmande data. I spark-shell anger du följande kommando:
hive.createTable("stream_table").column("value","string").create()Skriv sedan strömmande data till den nyligen skapade tabellen med följande kommando:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()Viktigt!
Alternativen
metastoreUriochdatabasemåste anges manuellt på grund av ett känt problem i Apache Spark. Mer information om det här problemet finns i SPARK-25460.Gå tillbaka till den andra SSH-sessionen och ange följande värden:
foo HiveSpark barGå tillbaka till den första SSH-sessionen och notera den korta aktiviteten. Använd följande kommando för att visa data:
hive.table("stream_table").show()
Använd Ctrl + C för att stoppa netcat den andra SSH-sessionen. Använd :q för att avsluta Spark-Shell på den första SSH-sessionen.