Vad är Apache Kafka i Azure HDInsight
Apache Kafka är en distribuerad direktuppspelningsplattform med öppen källkod som kan användas för att skapa realtidsuppspelade datapipelines och program. Kafka tillhandahåller även funktionen för asynkron meddelandekö som liknar en meddelandekö där du kan publicera och prenumerera på namngivna dataströmmar.
Följande är kännetecknen för Kafka på HDInsight:
Det är en hanterad tjänst som tillhandahåller en förenklad konfigurationsprocess. Resultatet är en konfiguration som har testats av och som stöds av Microsoft.
Microsoft tillhandahåller ett 99,9 % serviceavtal (SLA) för Kafkas driftstid. Mer information finns i dokumentet SLA-information för HDInsight.
Den använder hanterade diskar i Azure som lagringsenhet för Kafka. Hanterade diskar kan tillhandahålla upp till 16 TB lagringsutrymme per asynkron Kafka-meddelandekö. Mer information om att konfigurera hanterade diskar med Kafka i HDInsight finns i Öka skalbarheten för Apache Kafka i HDInsight.
För mer information om hanterade diskar, se Hanterade Azure-diskar.
Kafka har utformats med en enda dimensionell vy av ett rack. Azure delar ett rack i två dimensioner – uppdateringsdomäner (UD) och feldomäner (FD). Microsoft tillhandahåller verktyg som balanserar om Kafka-partitioner och -repliker mellan uppdateringsdomäner och feldomäner.
Mer information finns i Hög tillgänglighet med Apache Kafka i HDInsight.
I HDInsight kan du ändra antalet arbetarnoder (som är värdar för den asynkrona Kafka-meddelandekön) när klustret har skapats. Uppåtskalning kan utföras från Azure-portalen, Azure PowerShell och andra Azure-hanteringsgränssnitt. För Kafka bör du balansera om partitionsrepliker efter eventuell skalning. När du balanserar om partitionerna kan Kafka dra nytta av nya antalet arbetarnoder.
HDInsight Kafka stöder inte nedskalning eller minskning av antalet asynkrona koordinatorer i ett kluster. Om ett försök görs att minska antalet noder returneras ett
InvalidKafkaScaleDownRequestErrorCodefel.Mer information finns i Hög tillgänglighet med Apache Kafka i HDInsight.
Azure Monitor-loggar kan användas för att övervaka Kafka på HDInsight. Med Azure Monitor-loggar kan du se information på virtuell dator-nivå såsom mått för diskar och nätverkskort samt JMX-mått från Kafka.
Mer information finns i Analysera loggar för Apache Kafka i HDInsight.
Apache Kafka på HDInsight-arkitektur
Följande diagram visar en typisk Kafka-konfiguration som använder konsumentgrupper, partitionering och replikering för att erbjuda parallell läsning av händelser med feltolerans:
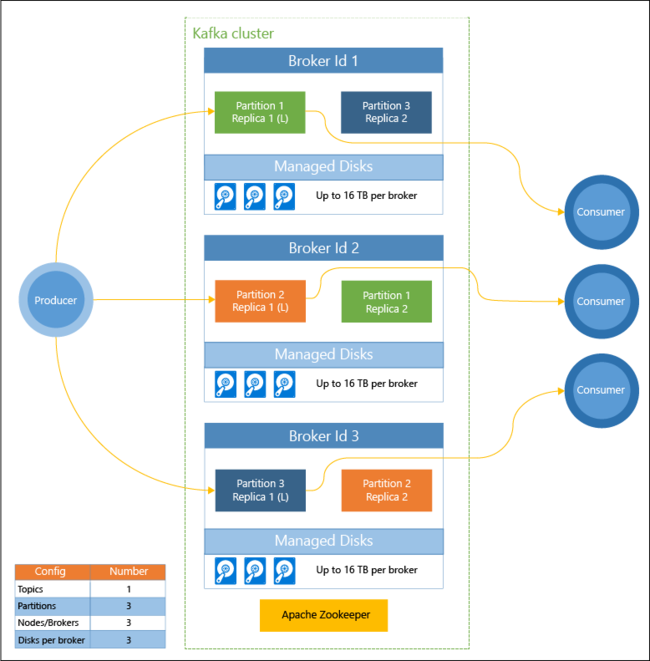
Apache ZooKeeper hanterar Kafka-klustrets status. Zookeeper är utformat för samtidiga och flexibla transaktioner med kort svarstid.
Kafka lagrar poster (data) i ämnen. Poster produceras av producenter, och används av konsumenter. Producenter skickar poster till asynkrona Kafka-meddelandeköer. Varje arbetsnod i HDInsight-klustret är en asynkron Kafka-meddelandekö.
Ämnen delar upp poster över meddelandeköer. När du förbrukar poster, kan du använda en konsument per partition för att uppnå parallell bearbetning av data.
Replikering används för att duplicera partitioner mellan noder, vilket skyddar mot avbrott på noder (meddelandeköer). En partition som är markerad med (L) i diagrammet är ledande för den angivna partitionen. Producenttrafik dirigeras till varje ledande nod med det tillstånd som hanteras av ZooKeeper.
Varför bör du använda Apache Kafka i HDInsight?
Följande är vanliga uppgifter och mönster som kan utföras med hjälp av Kafka på HDInsight:
| Använd | beskrivning |
|---|---|
| Replikering av Apache Kafka-data | Kafka innehåller verktyget MirrorMaker som replikerar data mellan olika Kafka-kluster. Information om hur du använder MirrorMaker finns i avsnittet om att replikera Apache Kafka-ämnen med Apache Kafka i HDInsight. |
| Mönster för publiceringsprenumereringsmeddelanden | Kafka innehåller ett producent-API för publicering av poster till ett Kafka-ämne. Konsument-API används när det finns en prenumererar på ett ämne. Mer information finns i Kom igång med Apache Kafka i HDInsight. |
| Dataströmbearbetning | Kafka används ofta med Spark för dataströmbearbetning i realtid. Kafka 2.1.1 och 2.4.1 (HDInsight version 4.0 och 5.0) stöder strömmande API:er som gör att du kan skapa strömningslösningar utan att kräva Spark. Mer information finns i Kom igång med Apache Kafka i HDInsight. |
| Horisontell skalning | Kafka partitionerar dataströmmar mellan noderna i HDInsight-klustret. Konsumentprocesser kan associeras med enskilda partitioner för att ge belastningsutjämning när poster används. Mer information finns i Kom igång med Apache Kafka i HDInsight. |
| Leverans i ordning | Inom varje partition lagras posterna i strömmen i den ordning som de togs emot. Genom att associera en konsumentprocess per partition bearbetas posterna garanterat i ordning. Mer information finns i Kom igång med Apache Kafka i HDInsight. |
| Meddelandetjänster | Eftersom Kafka stöder meddelandemönstret publicera-prenumerera används det ofta som en asynkron meddelandekö. |
| Aktivitetsspårning | Eftersom Kafka ger ordningsbaserad loggning av poster kan det användas för att spåra och återskapa aktiviteter. Till exempel användaråtgärder på en webbplats eller i ett program. |
| Aggregering | Med hjälp av strömbearbetning kan du sammanställa information från olika strömmar för att kombinera och centralisera information till användningsdata. |
| Transformering | Med dataströmsbearbetning kan du kombinera och utöka data från flera inkommande avsnitt i ett eller flera utdataämnen. |
Nästa steg
Använd följande länkar om du vill veta om hur du använder Apache Kafka på HDInsight: