Självstudie: Skapa ett Scala Maven-program för Apache Spark i HDInsight med hjälp av IntelliJ
I den här självstudien lär du dig att skapa ett Apache Spark-program som skrivits i Scala med hjälp av Apache Maven med IntelliJ IDEA. Artikeln använder Apache Maven som byggsystem. Och börjar med en befintlig Maven-arketyp för Scala som tillhandahålls av IntelliJ IDEA. Att skapa ett Scala-program i IntelliJ IDEA innefattar följande steg:
- Använd Maven som build-system.
- Uppdatera POM-filen (Project Object Model) för att hantera Spark-modulens beroenden.
- Skriv ditt program i Scala.
- Generera en jar-fil som kan skickas till HDInsight Spark-kluster.
- Kör programmet på ett Spark-kluster med Livy.
I den här självstudien lär du dig att:
- Installera plugin-programmet Scala för IntelliJ IDEA
- Använda IntelliJ till att utveckla ett Scala Maven-program
- Skapa ett fristående Scala-projekt
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
Oracle Java Development Kit. Den här kursen använder Java version 8.0.202.
En Java IDE. Den här artikeln använder IntelliJ IDEA Community 2018.3.4.
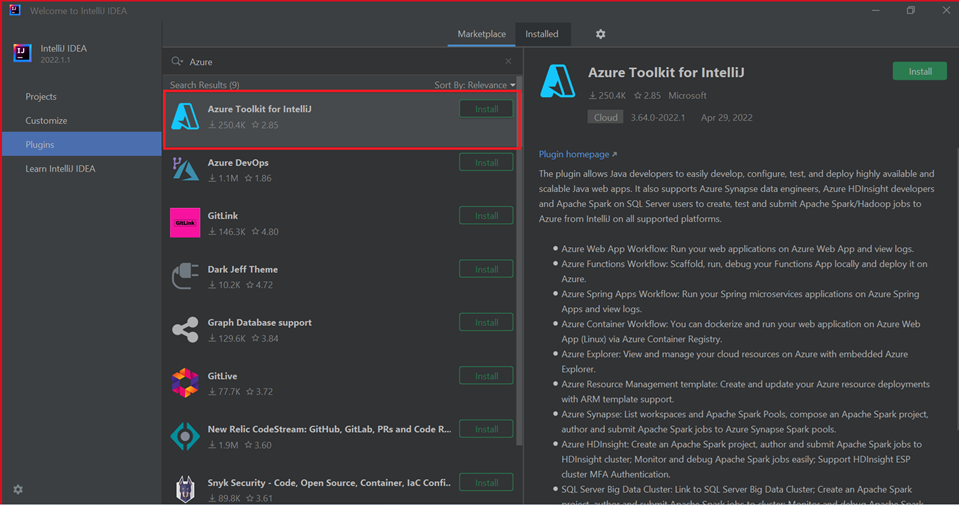
Azure Toolkit for IntelliJ. Se Installera Azure Toolkit för IntelliJ.
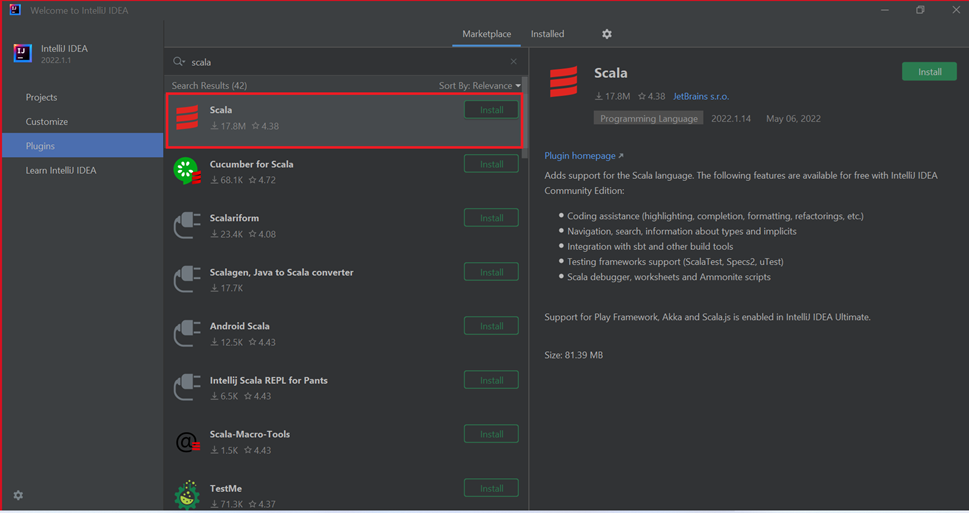
Installera plugin-programmet Scala för IntelliJ IDEA
Utför följande steg för att installera Scala-plugin-programmet:
Öppna IntelliJ IDEA.
På välkomstskärmen går du till Konfigurera>Plugin-program för att öppna fönstret Plugin-program.
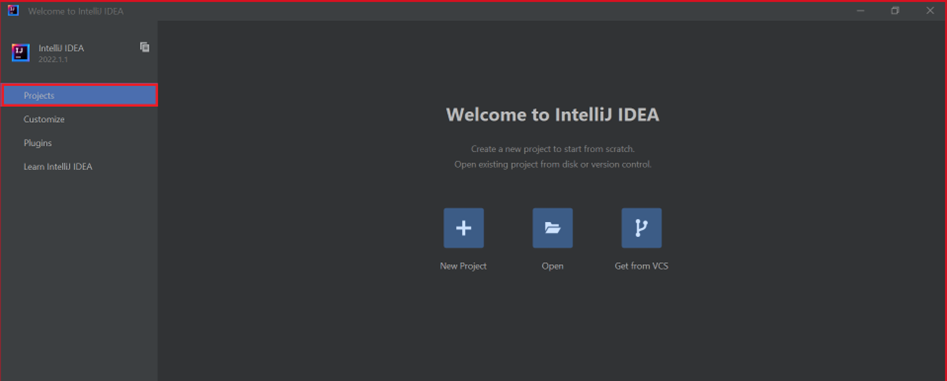
Välj Installera för Azure Toolkit för IntelliJ.
Välj Installera för det Scala-plugin-program som visas i det nya fönstret.
Du måste starta om IDE när plugin-programmet har installerats.
Använda IntelliJ till att skapa program
Starta IntelliJ IDEA och välj Skapa nytt projekt för att öppna fönstret Nytt projekt.
Välj Apache Spark/HDInsight i det vänstra fönstret.
Välj Spark-projekt (Scala) i huvudfönstret.
I listrutan Build tool (Skapa) väljer du något av följande värden:
- Maven för guidestöd när du skapar Scala-projekt.
- SBT för att hantera beroenden när du skapar Scala-projektet.
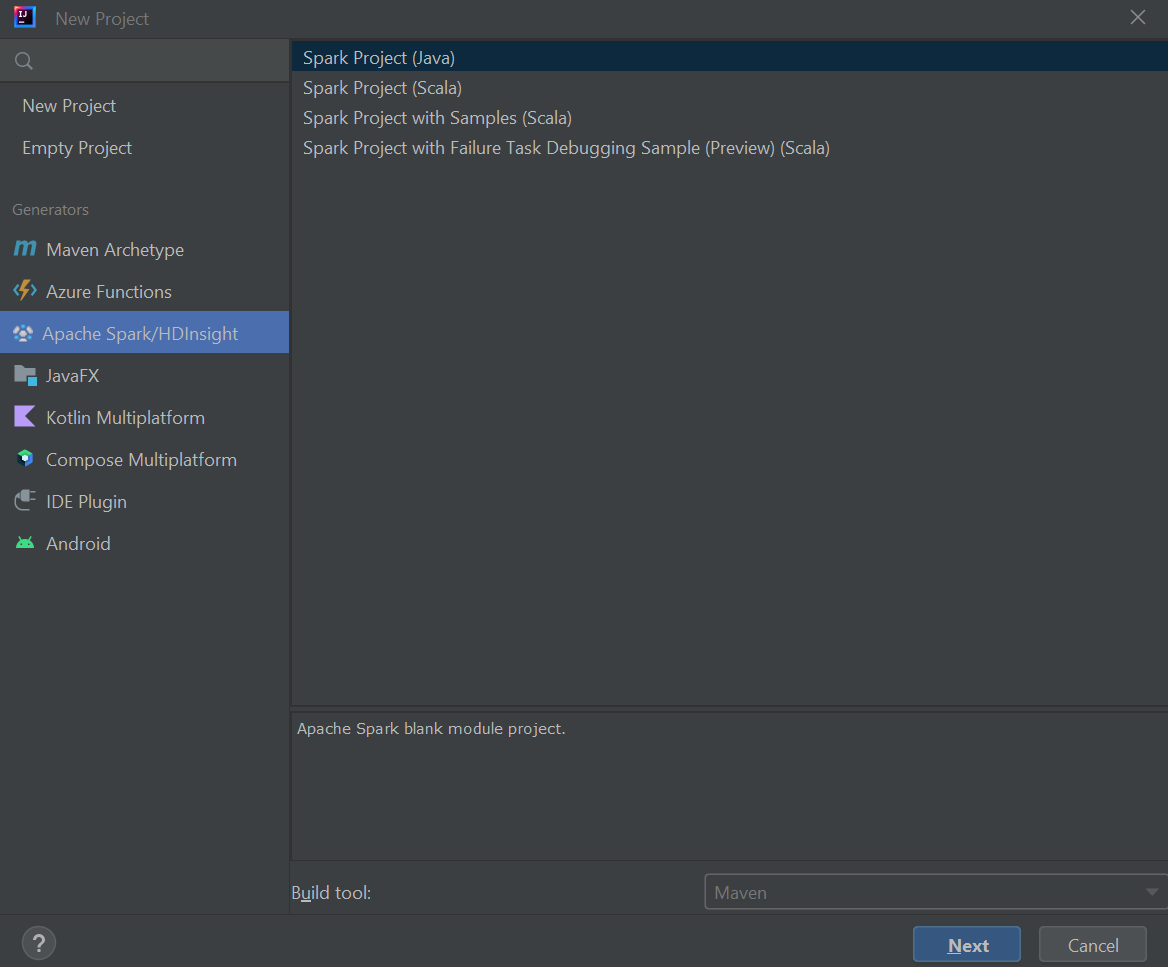
Välj Nästa.
I fönstret Nytt projekt anger du följande information:
Property beskrivning Projektnamn Ange ett namn. Projektplats Ange platsen där projektet ska sparas. Projekt-SDK Det här fältet kommer att vara tomt vid din första användning av IDEA. Välj Nytt... och navigera till din JDK. Spark-version Skapandeguiden integrerar rätt version för Spark SDK och Scala SDK. Om Sparks klusterversion är äldre än 2.0 väljer du Spark 1.x. Annars väljer du Spark 2.x. I det här exemplet används Spark 2.3.0 (Scala 2.11.8). 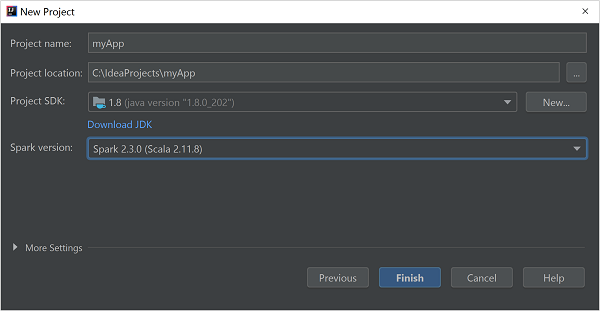
Välj Slutför.
Skapa ett fristående Scala-projekt
Starta IntelliJ IDEA och välj Skapa nytt projekt för att öppna fönstret Nytt projekt.
Välj Maven i den vänstra rutan.
Ange en Projekt-SDK. Om det är tomt väljer du Nytt... och går till installationskatalogen för Java.
Markera kryssrutan Create from archetype (Skapa från arketyp).
I listan över arketyper väljer du
org.scala-tools.archetypes:scala-archetype-simple. Den här arketypen skapar rätt katalogstruktur och laddar ned de beroenden som krävs för att skriva Scala-program.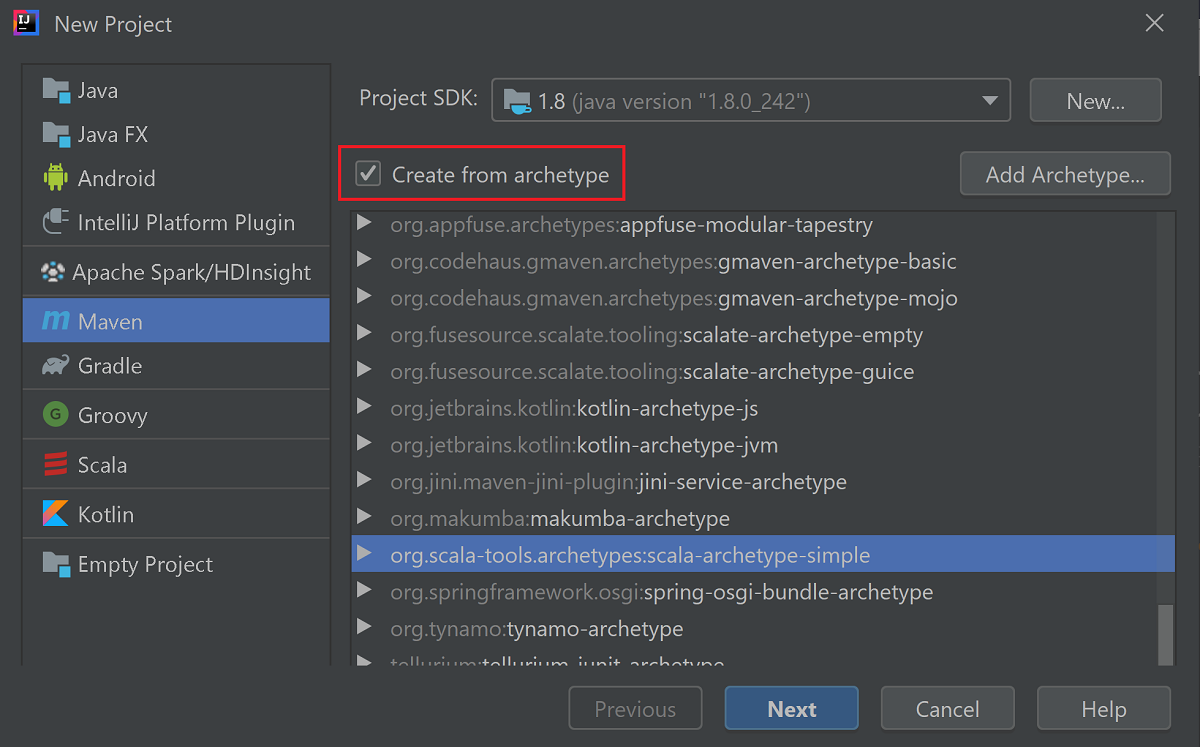
Välj Nästa.
Expandera Artefaktkoordinater. Ange relevanta värden för GroupId och ArtifactId. Namn och Plats fylls i automatiskt. I den här självstudien används följande värden:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
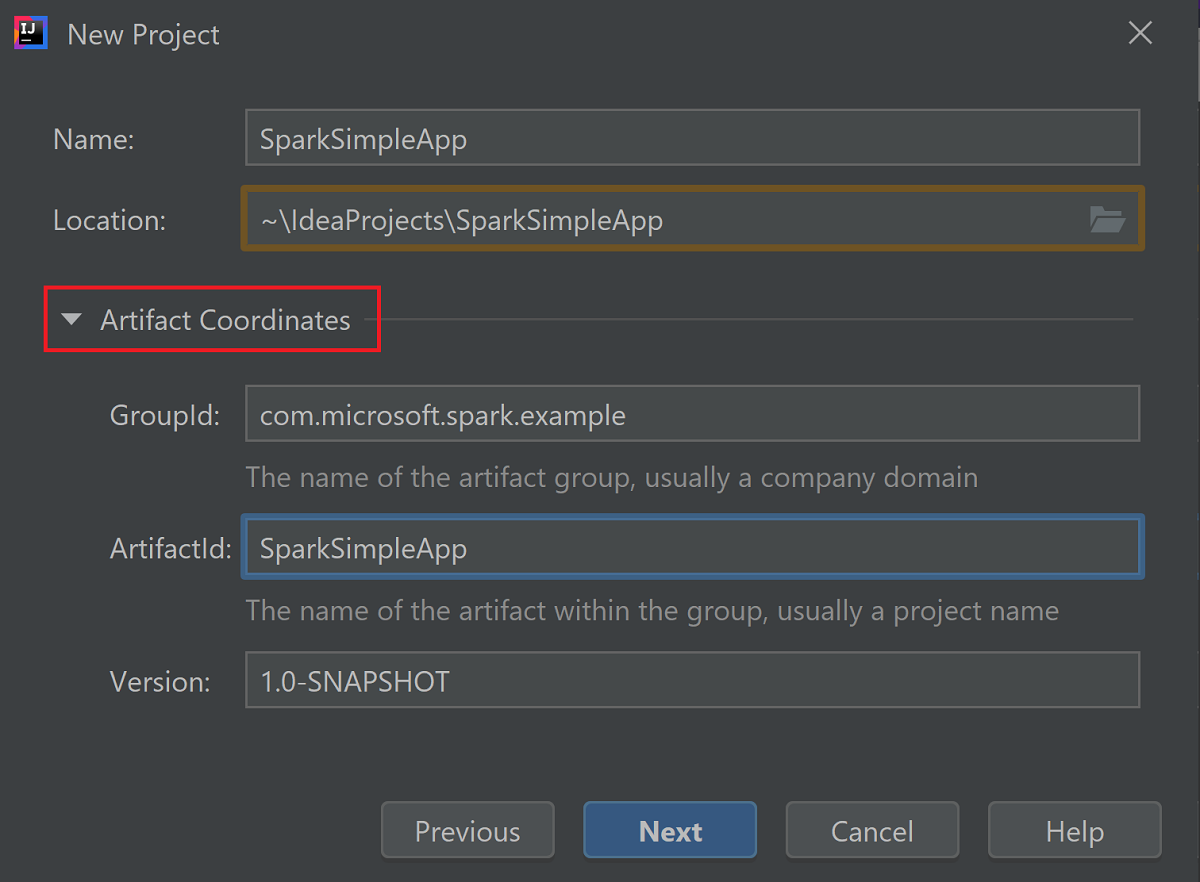
Välj Nästa.
Kontrollera inställningarna och välj sedan Nästa.
Kontrollera projektets namn och plats och välj sedan Slutför. Projektet kan ta några minuter att importeras.
När projektet har importerats går du i det vänstra fönstret till SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Högerklicka på MySpec och välj sedan Ta bort.... Du behöver inte den här filen för programmet. Välj OK i dialogrutan.
I de senare stegen uppdaterar du pom.xml för att definiera beroenden för Spark Scala-programmet. För att dessa beroenden ska laddas ned och matchas automatiskt måste du konfigurera Maven.
Från Arkiv-menyn väljer du Inställningar för att öppna fönstret Inställningar.
I fönstret Inställningar går du till Build, Execution, Deployment (Skapa, köra och distribuera)>Build Tools>Maven>Import.
Markera kryssrutan Import Maven projects automatically (Importera Maven-projekt automatiskt).
Tryck på Tillämpa och välj sedan OK. Sedan returneras du till projektfönstret.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::I den vänstra rutan går du till src>main>scala>com.microsoft.spark.example och dubbelklickar på App för att öppna App.scala.
Ersätt den befintliga exempelkoden med följande kod och spara ändringarna. Den här koden läser data från HVAC.csv (tillgänglig i alla HDInsight Spark-kluster). Hämtar de rader som bara har en siffra i den sjätte kolumnen. Och skriver utdata till /HVACOut under standardlagringscontainern för klustret.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }I den vänstra rutan dubbelklickar du på pom.xml.
I
<project>\<properties>lägger du till följande segment:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>I
<project>\<dependencies>lägger du till följande segment:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Skapa .jar-filen. Med IntelliJ IDEA går det att skapa JAR-filen som en artefakt av ett projekt. Följ dessa steg.
På Arkiv-menyn väljer du Projektstruktur....
I fönstret Projektstruktur går du till Artefakter>plustecknet +>JAR>From modules with dependencies... (Från moduler med beroenden...).
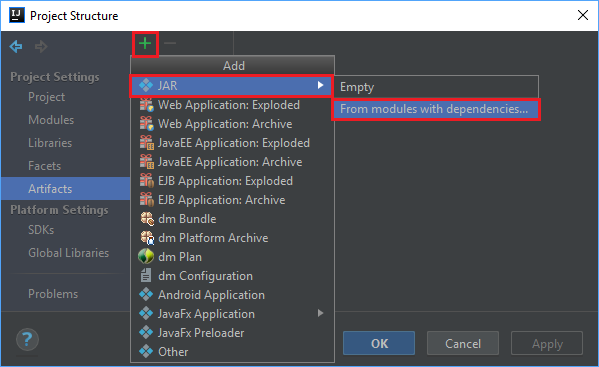
I fönstret Skapa JAR från moduler väljer du mappikonen i textrutan Main Class (Main-klass).
I fönstret Select Main Class (Välj Main-klass) väljer du den klass som visas som standard och sedan OK.
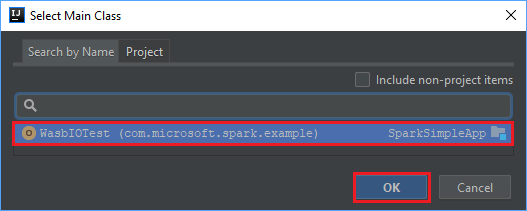
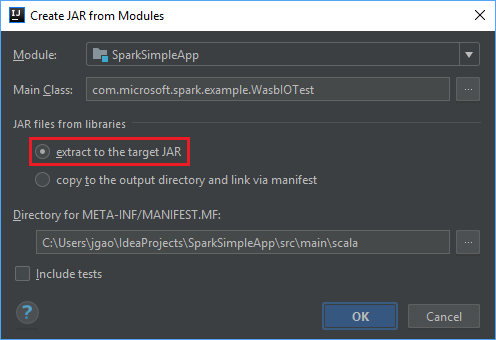
I fönstret Create JAR from Modules (Skapa JAR-fil från moduler) kontrollerar du att alternativet Extract to the target JAR (Extrahera till mål-JAR) är markerat. Välj sedan OK. Den här inställningen skapar en enda JAR-fil med alla beroenden.
Fliken Output Layout (Utdatalayout) visar alla jar-filer som ingår i Maven-projektet. Du kan markera och ta bort sådana som Scala-programmet inte har något direkt beroende till. För programmet skapar du här, du kan ta bort alla utom den sista (SparkSimpleApp kompilera utdata). Välj de jar-filer som ska tas bort och välj sedan minustecknet -.
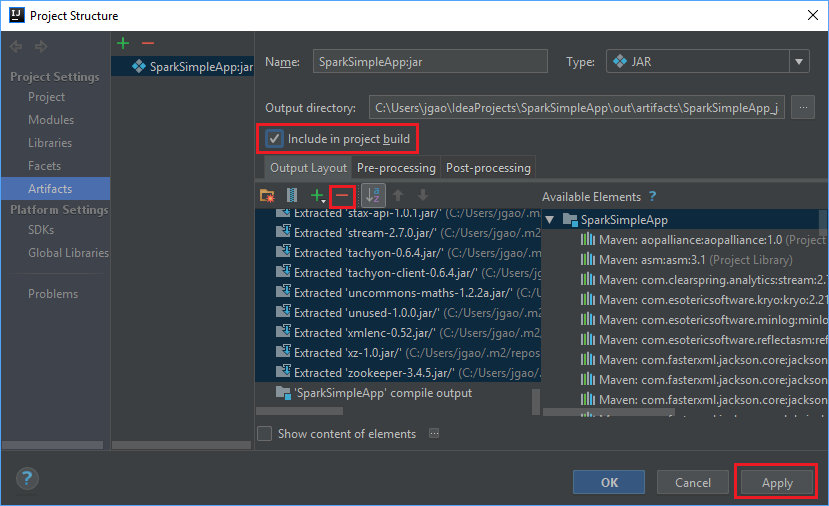
Kontrollera att kryssrutan Inkludera i projektversion är markerad. Det här alternativet säkerställer att jar-filen skapas varje gång projektet skapas eller uppdateras. Välj Applicera och sedan OK.
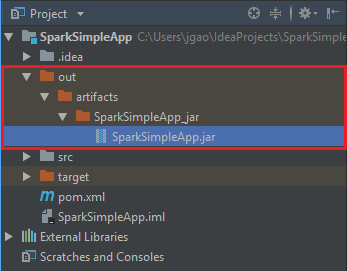
Skapa jar-filen genom att gå till Skapa>Build Artifacts (Skapa artefakter)>Skapa. Projektet kompileras inom cirka 30 sekunder. Utdatans jar-fil skapas under \out\artifacts.
Köra programmet på Apache Spark-klustret
Om du vill köra programmet på klustret, kan du använda följande metoder:
Kopiera programburken till Azure Storage-bloben som är associerad med klustret. Du kan använda kommandoradsverktyget AzCopy till att göra detta. Det finns även andra klienter som du kan använda för att ladda upp data. Det finns mer information om dem i Ladda upp data för Apache Hadoop-jobb i HDInsight.
Använd Apache Livy till att skicka ett programjobb via fjärranslutning till Spark-klustret. Spark-kluster i HDInsight innehåller Livy som gör REST-slutpunkter tillgängliga, så att man kan skicka Spark-jobb via en fjärranslutning. Mer information finns i Skicka Apache Spark-jobb via fjärranslutning med hjälp av Apache Livy med Spark-kluster i HDInsight.
Rensa resurser
Om du inte kommer att fortsätta att använda det här programmet tar du bort klustret som du skapade med följande steg:
Logga in på Azure-portalen.
I rutan Sök längst upp skriver du HDInsight.
Välj HDInsight-kluster under Tjänster.
I listan över HDInsight-kluster som visas väljer du ... bredvid klustret som du skapade för den här självstudien.
Välj Ta bort. Välj Ja.
Gå vidare
I den här artikeln har du lärt dig att skapa ett Apache Spark Scala-program. Gå vidare till nästa artikel om du vill lära dig att köra programmet på ett HDInsight Spark-kluster med Livy.