Kom igång med DICOM-data i analysarbetsbelastningar
I den här artikeln beskrivs hur du kommer igång med DICOM-data® i analysarbetsbelastningar med Azure Data Factory och Microsoft Fabric.
Förutsättningar
Slutför följande steg innan du kommer igång:
- Skapa ett lagringskonto med Azure Data Lake Storage Gen2-funktioner genom att aktivera ett hierarkiskt namnområde:
- Skapa en container för att lagra DICOM-metadata, till exempel med namnet
dicom.
- Skapa en container för att lagra DICOM-metadata, till exempel med namnet
- Distribuera en instans av DICOM-tjänsten.
- (Valfritt) Distribuera DICOM-tjänsten med Data Lake Storage för att aktivera direkt åtkomst till DICOM-filer.
- Skapa en Data Factory-instans :
- Aktivera en systemtilldelad hanterad identitet.
- Skapa ett sjöhus i Fabric.
- Lägg till rolltilldelningar till den systemtilldelade hanterade identiteten för DICOM-tjänsten och Data Lake Storage Gen2-lagringskontot:
- Lägg till rollen DICOM-dataläsare för att bevilja behörighet till DICOM-tjänsten.
- Lägg till rollen Storage Blob Data Contributor för att bevilja behörighet till Data Lake Storage Gen2-kontot.
Konfigurera en Data Factory-pipeline för DICOM-tjänsten
I det här exemplet används en Data Factory-pipeline för att skriva DICOM-attribut för instanser, serier och studier till ett lagringskonto i ett Delta-tabellformat.
Öppna Data Factory-instansen från Azure-portalen och välj Starta studio för att börja.

Skapa länkade tjänster
Data Factory-pipelines läser från datakällor och skriver till datamottagare, som vanligtvis är andra Azure-tjänster. Dessa anslutningar till andra tjänster hanteras som länkade tjänster.
Pipelinen i det här exemplet läser data från en DICOM-tjänst och skriver dess utdata till ett lagringskonto, så en länkad tjänst måste skapas för båda.
Skapa en länkad tjänst för DICOM-tjänsten
I Azure Data Factory Studio väljer du Hantera på menyn till vänster. Under Anslutningar väljer du Länkade tjänster och sedan Nytt.
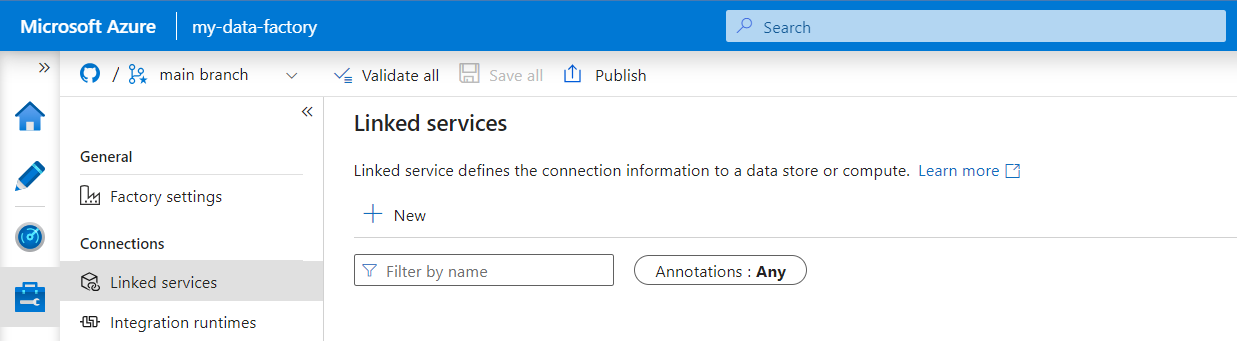
I fönstret Ny länkad tjänst söker du efter REST. Välj REST-panelen och välj sedan Fortsätt.
Ange ett namn och en beskrivning för den länkade tjänsten.

I fältet Bas-URL anger du tjänst-URL:en för DICOM-tjänsten. Till exempel har en DICOM-tjänst med namnet
contosoclinicpåcontosohealtharbetsytan tjänstens URLhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.Som Autentiseringstyp väljer du Systemtilldelad hanterad identitet.
För AAD-resurs anger du
https://dicom.healthcareapis.azure.com. Den här URL:en är densamma för alla DICOM-tjänstinstanser.När du har fyllt i de obligatoriska fälten väljer du Testa anslutning för att säkerställa att identitetens roller är korrekt konfigurerade.
När anslutningstestet har slutförts väljer du Skapa.



Skapa en länkad tjänst för Azure Data Lake Storage Gen2
I Data Factory Studio väljer du Hantera på menyn till vänster. Under Anslutningar väljer du Länkade tjänster och sedan Nytt.
I fönstret Ny länkad tjänst söker du efter Azure Data Lake Storage Gen2. Välj panelen Azure Data Lake Storage Gen2 och välj sedan Fortsätt.

Ange ett namn och en beskrivning för den länkade tjänsten.

Som Autentiseringstyp väljer du Systemtilldelad hanterad identitet.
Ange lagringskontoinformationen genom att ange URL:en till lagringskontot manuellt. Du kan också välja Azure-prenumerationen och lagringskontot i listrutorna.
När du har fyllt i de obligatoriska fälten väljer du Testa anslutning för att säkerställa att identitetens roller är korrekt konfigurerade.
När anslutningstestet har slutförts väljer du Skapa.


Skapa en pipeline för DICOM-data
Data Factory-pipelines är en samling aktiviteter som utför en uppgift, som att kopiera DICOM-metadata till Delta-tabeller. Det här avsnittet beskriver skapandet av en pipeline som regelbundet synkroniserar DICOM-data till Delta-tabeller när data läggs till, uppdateras i och tas bort från en DICOM-tjänst.
Välj Författare på menyn till vänster. I fönstret Fabriksresurser väljer du plustecknet (+) för att lägga till en ny resurs. Välj Pipeline och välj sedan Mallgalleri på menyn.
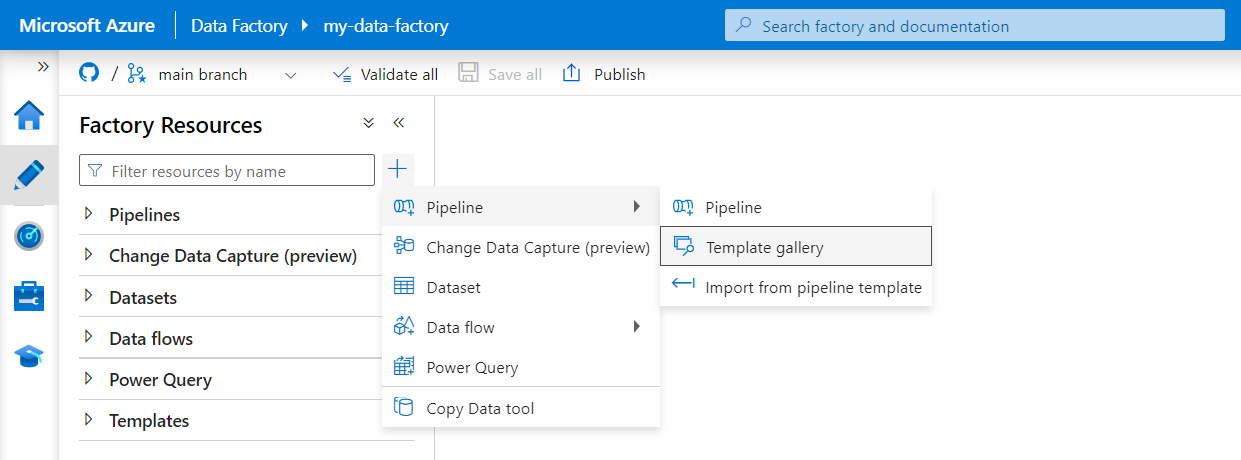
Sök efter DICOM i mallgalleriet. Välj panelen Kopiera DICOM-metadataändringar till ADLS Gen2 i deltaformat och välj sedan Fortsätt.

I avsnittet Indata väljer du de länkade tjänster som tidigare skapats för DICOM-tjänsten och Data Lake Storage Gen2-kontot.

Välj Använd den här mallen för att skapa den nya pipelinen.



Skapa en pipeline för DICOM-data
Om du har skapat DICOM-tjänsten med Azure Data Lake Storage, i stället för att använda mallen från mallgalleriet, måste du använda en anpassad mall för att inkludera en ny fileName parameter i metadatapipelinen. Så här konfigurerar du pipelinen.
Ladda ned mallen från GitHub. Mallfilen är en komprimerad mapp (zippad). Du behöver inte extrahera filerna eftersom de redan har laddats upp i komprimerat format.
I Azure Data Factory väljer du Författare på den vänstra menyn. I fönstret Fabriksresurser väljer du plustecknet (+) för att lägga till en ny resurs. Välj Pipeline och välj sedan Importera från pipelinemall.
I fönstret Öppna väljer du den mall som du laddade ned. Välj Öppna.
I avsnittet Indata väljer du de länkade tjänster som skapats för DICOM-tjänsten och Azure Data Lake Storage Gen2-kontot.
Välj Använd den här mallen för att skapa den nya pipelinen.
Schemalägga en pipeline
Pipelines schemaläggs av utlösare. Det finns olika typer av utlösare. Schemautlösare gör att pipelines kan utlösas för att köras vid specifika tider på dagen, till exempel varje timme eller varje dag vid midnatt. Manuella utlösare utlöser pipelines på begäran, vilket innebär att de körs när du vill.
I det här exemplet används en utlösare för rullande fönster för att regelbundet köra pipelinen baserat på en startpunkt och ett regelbundet tidsintervall. Mer information om utlösare finns i Pipelinekörning och utlösare i Azure Data Factory eller Azure Synapse Analytics.
Skapa en ny utlösare för rullande fönster
Välj Författare på menyn till vänster. Välj pipelinen för DICOM-tjänsten och välj Lägg till utlösare och Ny/Redigera på menyraden.

I fönstret Lägg till utlösare väljer du listrutan Välj utlösare och väljer sedan Ny.
Ange ett namn och en beskrivning för utlösaren.

Välj Rullande fönster som Typ.
Om du vill konfigurera en pipeline som körs varje timme anger du Upprepning till 1 timme.
Expandera avsnittet Avancerat och ange en fördröjning på 15 minuter. Med den här inställningen kan väntande åtgärder i slutet av en timme slutföras innan bearbetningen.
Ange Maximal samtidighet till 1 för att säkerställa konsekvens mellan tabeller.
Välj OK för att fortsätta konfigurera parametrarna för utlösarkörningen.


Konfigurera parametrar för utlösarkörning
Utlösare definierar när en pipeline körs. De innehåller även parametrar som skickas till pipelinekörningen. Mallen Kopiera DICOM-metadataändringar till Delta definierar parametrar som beskrivs i följande tabell. Om inget värde anges under konfigurationen används det angivna standardvärdet för varje parameter.
| Parameternamn | beskrivning | Standardvärde |
|---|---|---|
| BatchSize | Det maximala antalet ändringar som ska hämtas åt gången från ändringsflödet (högst 200) | 200 |
| ApiVersion | API-versionen för Azure DICOM-tjänsten (minst 2) | 2 |
| StartTime | Inkluderande starttid för DICOM-ändringar | 0001-01-01T00:00:00Z |
| EndTime | Den exklusiva sluttiden för DICOM-ändringar | 9999-12-31T23:59:59Z |
| ContainerName | Containernamnet för de resulterande Delta-tabellerna | dicom |
| InstanceTablePath | Sökvägen som innehåller Delta-tabellen för DICOM SOP-instanser i containern | instance |
| SeriesTablePath | Sökvägen som innehåller Delta-tabellen för DICOM-serien i containern | series |
| StudyTablePath | Sökvägen som innehåller Delta-tabellen för DICOM-studier i containern | study |
| RetentionHours | Maximal kvarhållning i timmar för data i Delta-tabellerna | 720 |
I fönstret Parametrar för körning av utlösare anger du värdet ContainerName som matchar namnet på den lagringscontainer som skapades i förutsättningarna.
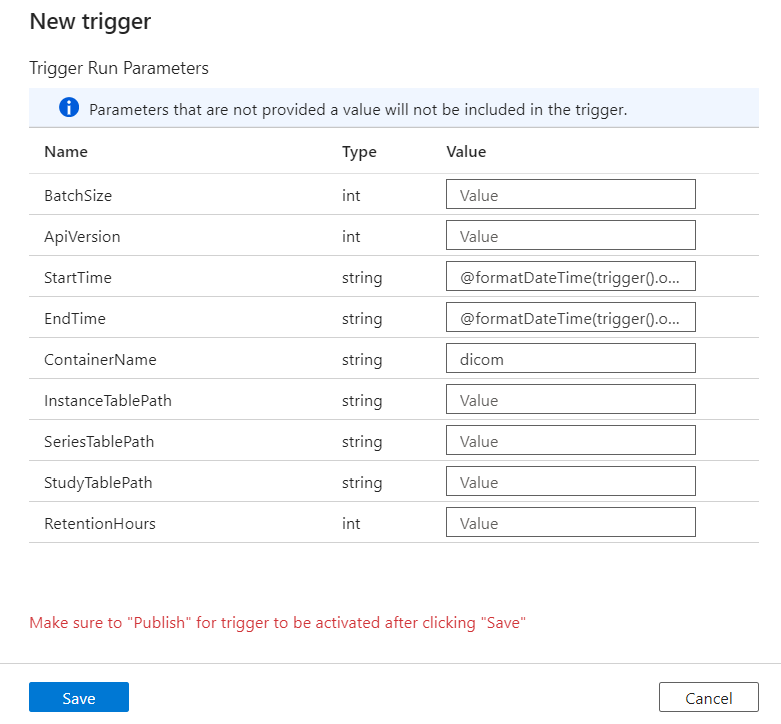
För StartTime använder du systemvariabeln
@formatDateTime(trigger().outputs.windowStartTime).För EndTime använder du systemvariabeln
@formatDateTime(trigger().outputs.windowEndTime).Kommentar
Endast utlösare för rullande fönster stöder systemvariablerna:
@trigger().outputs.windowStartTimeoch@trigger().outputs.windowEndTime.
Schemautlösare använder olika systemvariabler:
@trigger().scheduledTimeoch@trigger().startTime.
Läs mer om utlösartyper.
Välj Spara för att skapa den nya utlösaren. Välj Publicera för att starta utlösaren som körs enligt det definierade schemat.



När utlösaren har publicerats kan den utlösas manuellt med hjälp av alternativet Utlösare nu . Om starttiden har angetts för ett värde tidigare startar pipelinen omedelbart.
Övervaka pipelinekörningar
Du kan övervaka utlösta körningar och deras associerade pipelinekörningar på fliken Övervaka . Här kan du bläddra när varje pipeline kördes och hur lång tid det tog att köra. Du kan också eventuellt felsöka eventuella problem som uppstod.

Microsoft Fabric
Fabric är en allt-i-ett-analyslösning som finns ovanpå Microsoft OneLake. Med hjälp av ett Infrastruktursjöhus kan du hantera, strukturera och analysera data i OneLake på en enda plats. Alla data utanför OneLake, skrivna till Data Lake Storage Gen2, kan anslutas till OneLake med hjälp av genvägar för att dra nytta av Fabrics uppsättning verktyg.
Skapa genvägar till metadatatabeller
Gå till lakehouse som skapats i förutsättningarna. I utforskarvyn väljer du ellipsmenyn (...) bredvid mappen Tabeller.
Välj Ny genväg för att skapa en ny genväg till lagringskontot som innehåller DICOM-analysdata.

Välj Azure Data Lake Storage Gen2 som källa för genvägen.

Under Anslutningsinställningar anger du den URL som du använde i avsnittet Länkade tjänster .
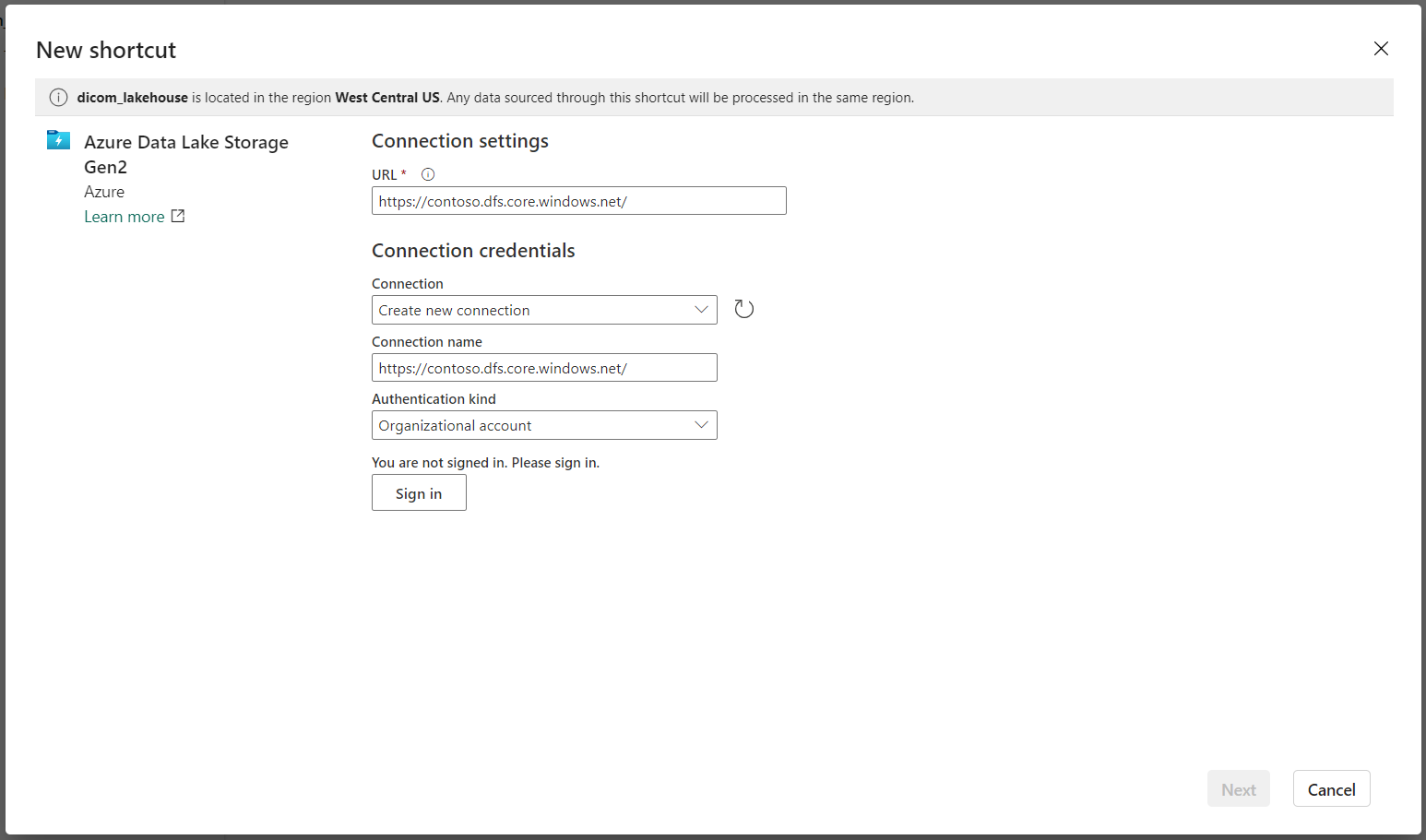
Välj en befintlig anslutning eller skapa en ny anslutning genom att välja den typ av autentisering som du vill använda.
Kommentar
Det finns några alternativ för autentisering mellan Data Lake Storage Gen2 och Fabric. Du kan använda ett organisationskonto eller ett huvudnamn för tjänsten. Vi rekommenderar inte att du använder kontonycklar eller signaturtoken för delad åtkomst.
Välj Nästa.
Ange ett genvägsnamn som representerar data som skapats av Data Factory-pipelinen. För deltatabellen
instancebör genvägsnamnet till exempel förmodligen vara instans.Ange den undersökväg som matchar parametern
ContainerNamefrån körningsparametrars konfiguration och namnet på tabellen för genvägen. Använd till exempel/dicom/instanceför deltatabellen med sökvägeninstancei containerndicom.Välj Skapa för att skapa genvägen.
Upprepa steg 2 till 9 för att lägga till de återstående genvägarna till de andra Delta-tabellerna i lagringskontot (till exempel
seriesochstudy).



När du har skapat genvägarna expanderar du en tabell för att visa namnen och typerna av kolumnerna.

Skapa genvägar till filer
Om du använder en DICOM-tjänst med Data Lake Storage kan du dessutom skapa en genväg till DICOM-fildata som lagras i datasjön.
Gå till lakehouse som skapats i förutsättningarna. I utforskarvyn väljer du ellipsmenyn (...) bredvid mappen Filer.
Välj Ny genväg för att skapa en ny genväg till lagringskontot som innehåller DICOM-data.

Välj Azure Data Lake Storage Gen2 som källa för genvägen.
Under Anslutningsinställningar anger du den URL som du använde i avsnittet Länkade tjänster .
Välj en befintlig anslutning eller skapa en ny anslutning genom att välja den typ av autentisering som du vill använda.
Välj Nästa.
Ange ett genvägsnamn som beskriver DICOM-data. Till exempel contoso-dicom-files.
Ange den undersökväg som matchar namnet på lagringscontainern och mappen som används av DICOM-tjänsten. Om du till exempel vill länka till rotmappen skulle undersökvägen vara /dicom/AHDS. Rotmappen är alltid
AHDS, men du kan också länka till en underordnad mapp för en specifik arbetsyta eller DICOM-tjänstinstans.Välj Skapa för att skapa genvägen.


Köra notebook-filer
När tabellerna har skapats i lakehouse kan du fråga dem från Fabric Notebooks. Du kan skapa anteckningsböcker direkt från lakehouse genom att välja Öppna anteckningsbok från menyraden.
På anteckningsbokssidan kan innehållet i lakehouse visas till vänster, inklusive nyligen tillagda tabeller. Längst upp på sidan väljer du språket för notebook-filen. Språket kan också konfigureras för enskilda celler. I följande exempel används Spark SQL.
Fråga efter tabeller med hjälp av Spark SQL
I cellredigeraren anger du en Spark SQL-fråga som en SELECT instruktion.
SELECT * from instance
Den här frågan väljer allt innehåll från instance tabellen. När du är klar väljer du Kör cell för att köra frågan.

Efter några sekunder visas resultatet av frågan i en tabell under cellen som i följande exempel. Tiden kan vara längre om den här Spark-frågan är den första i sessionen eftersom Spark-kontexten måste initieras.

Få åtkomst till DICOM-fildata i notebook-filer
Om du använde en mall för att skapa pipelinen och skapade en genväg till DICOM-fildata kan du använda filePath kolumnen i instance tabellen för att korrelera instansmetadata till fildata.
SELECT sopInstanceUid, filePath from instance

Sammanfattning
I den här artikeln lärde du dig att:
- Använd Data Factory-mallar för att skapa en pipeline från DICOM-tjänsten till ett Data Lake Storage Gen2-konto.
- Konfigurera en utlösare för att extrahera DICOM-metadata enligt ett schema varje timme.
- Använd genvägar för att ansluta DICOM-data i ett lagringskonto till en Infrastruktursjöhus.
- Använd notebook-filer för att fråga efter DICOM-data i lakehouse.
Nästa steg
Kommentar
DICOM® är ett registrerat varumärke som tillhör National Electrical Manufacturers Association för dess standarder publikationer som rör digital kommunikation av medicinsk information.