Prognostisering i stor skala: många modeller och distribuerad träning
Den här artikeln handlar om att träna prognosmodeller på stora mängder historiska data. Instruktioner och exempel för modeller för träningsprognoser i AutoML finns i vår artikel om att konfigurera AutoML för tidsserieprognoser .
Tidsseriedata kan vara stora på grund av antalet serier i data, antalet historiska observationer eller både och. Många modeller och hierarkiska tidsserier, eller HTS, är skalningslösningar för det tidigare scenariot, där data består av ett stort antal tidsserier. I dessa fall kan det vara fördelaktigt för modellens noggrannhet och skalbarhet att partitionera data i grupper och träna ett stort antal oberoende modeller parallellt i grupperna. Det finns däremot scenarier där en eller några modeller med hög kapacitet är bättre. Distribuerad DNN-utbildning riktar sig mot det här fallet. Vi granskar begrepp kring dessa scenarier i resten av artikeln.
Många modeller
Med de många modellkomponenterna i AutoML kan du träna och hantera miljontals modeller parallellt. Anta till exempel att du har historiska försäljningsdata för ett stort antal butiker. Du kan använda många modeller för att starta parallella AutoML-träningsjobb för varje butik, som i följande diagram:

Träningskomponenten för många modeller tillämpar AutoML:s modells svepning och val oberoende av varje butik i det här exemplet. Den här modellens oberoende underlättar skalbarheten och kan vara till nytta för modellens noggrannhet, särskilt när butikerna har olika försäljningsdynamik. En enskild modellmetod kan dock ge mer exakta prognoser när det finns vanliga försäljningsdynamiker. Mer information om det fallet finns i avsnittet distribuerad DNN-utbildning .
Du kan konfigurera datapartitioneringen, AutoML-inställningarna för modellerna och graden av parallellitet för många modellers träningsjobb. Exempel finns i vårt guideavsnitt om många modellkomponenter.
Prognostisering för hierarkisk tidsserie
Det är vanligt att tidsserier i affärsprogram har kapslade attribut som utgör en hierarki. Geografi- och produktkatalogattribut är ofta kapslade, till exempel. Tänk dig ett exempel där hierarkin har två geografiska attribut, tillstånds- och butiks-ID och två produktattribut, kategori och SKU:

Den här hierarkin illustreras i följande diagram:

Det är viktigt att försäljningskvantiteterna på lövnivån (SKU) uppgår till de aggregerade försäljningskvantiteterna på status- och totalförsäljningsnivå. Hierarkiska prognosmetoder bevarar dessa aggregeringsegenskaper vid prognostisering av den kvantitet som säljs på valfri nivå i hierarkin. Prognoser med den här egenskapen är sammanhängande med avseende på hierarkin.
AutoML stöder följande funktioner för hierarkisk tidsserie (HTS):
- Träning på valfri nivå i hierarkin. I vissa fall kan lövnivådata vara bullriga, men aggregeringar kan vara mer anpassningsbara till prognoser.
- Hämtar punktprognoser på valfri nivå i hierarkin. Om prognosnivån är "under" träningsnivån delas prognoserna från träningsnivån upp via genomsnittliga historiska proportioner eller andelar av historiska medelvärden. Prognoser på träningsnivå summeras enligt aggregeringsstrukturen när prognosnivån är "över" träningsnivån.
- Hämtar kvantil-/probabilistiska prognoser för nivåer på eller "under" träningsnivån. Aktuella modelleringsfunktioner stöder disaggregering av probabilistiska prognoser.
HTS-komponenter i AutoML bygger på många modeller, så HTS delar de skalbara egenskaperna för många modeller. Exempel finns i vår guideavsnitt om HTS-komponenter.
Distribuerad DNN-utbildning (förhandsversion)
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Datascenarier med stora mängder historiska observationer och/eller ett stort antal relaterade tidsserier kan dra nytta av en skalbar, enkel modellmetod. Därför stöder AutoML distribuerad träning och modellsökning på TCN-modeller (temporal convolutional network), som är en typ av djup neuralt nätverk (DNN) för tidsseriedata. Mer information om AutoML:s TCN-modellklass finns i vår DNN-artikel.
Distribuerad DNN-träning uppnår skalbarhet med hjälp av en algoritm för datapartitionering som respekterar tidsseriegränser. Följande diagram illustrerar ett enkelt exempel med två partitioner:
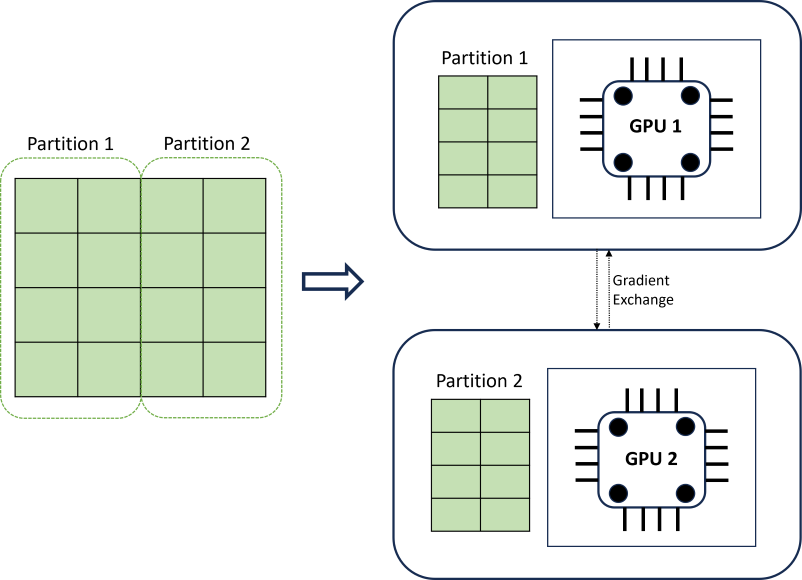
Under träningen läser DNN-datainläsarna på varje beräkning in precis vad de behöver för att slutföra en iteration av bakåtspridning. hela datamängden läss aldrig in i minnet. Partitionerna distribueras ytterligare över flera beräkningskärnor (vanligtvis GPU:er) på eventuellt flera noder för att påskynda träningen. Samordning mellan beräkningar tillhandahålls av Horovod-ramverket.
Nästa steg
- Läs mer om hur du konfigurerar AutoML för att träna en prognosmodell för tidsserier.
- Lär dig mer om hur AutoML använder maskininlärning för att skapa prognosmodeller.
- Lär dig mer om djupinlärningsmodeller för prognostisering i AutoML