Djupinlärning jämfört med maskininlärning i Azure Machine Learning
Den här artikeln beskriver djupinlärning kontra maskininlärning och hur de passar in i den bredare kategorin artificiell intelligens. Lär dig mer om djupinlärningslösningar som du kan bygga vidare på Azure Mašinsko učenje, till exempel bedrägeriidentifiering, röst- och ansiktsigenkänning, attitydanalys och prognostisering av tidsserier.
Vägledning om hur du väljer algoritmer för dina lösningar finns i fuskbladet Mašinsko učenje algoritm.
Grundmodeller i Azure Mašinsko učenje är förtränade djupinlärningsmodeller som kan finjusteras för specifika användningsfall. Läs mer om Foundation Models (förhandsversion) i Azure Mašinsko učenje och hur du använder Foundation Models i Azure Mašinsko učenje (förhandsversion).
Djupinlärning, maskininlärning och AI
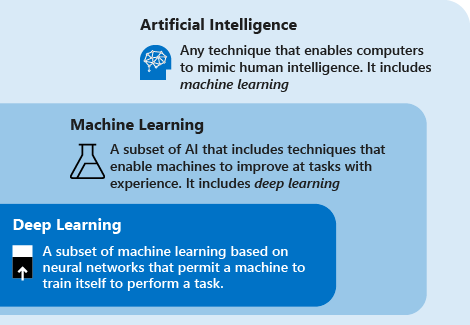
Överväg följande definitioner för att förstå djupinlärning jämfört med maskininlärning jämfört med AI:
Djupinlärning är en delmängd av maskininlärning som baseras på artificiella neurala nätverk. Inlärningsprocessen är djup eftersom strukturen för artificiella neurala nätverk består av flera indata, utdata och dolda lager. Varje lager innehåller enheter som omvandlar indata till information som nästa lager kan använda för en viss förutsägelseuppgift. Tack vare den här strukturen kan en dator lära sig genom sin egen databehandling.
Maskininlärning är en delmängd av artificiell intelligens som använder tekniker (till exempel djupinlärning) som gör det möjligt för datorer att använda erfarenhet för att förbättra uppgifter. Inlärningsprocessen baseras på följande steg:
- Mata in data i en algoritm. (I det här steget kan du ge ytterligare information till modellen, till exempel genom att utföra extrahering av funktioner.)
- Använd dessa data för att träna en modell.
- Testa och distribuera modellen.
- Använd den distribuerade modellen för att utföra en automatiserad förutsägelseuppgift. (Med andra ord anropar och använder du den distribuerade modellen för att ta emot förutsägelserna som returneras av modellen.)
Artificiell intelligens (AI) är en teknik som gör det möjligt för datorer att efterlikna mänsklig intelligens. Den innehåller maskininlärning.
Generativ AI är en delmängd av artificiell intelligens som använder tekniker (till exempel djupinlärning) för att generera nytt innehåll. Du kan till exempel använda generativ AI för att skapa bilder, text eller ljud. Dessa modeller utnyttjar omfattande förtränad kunskap för att generera det här innehållet.
Genom att använda maskininlärnings- och djupinlärningstekniker kan du skapa datorsystem och program som utför uppgifter som ofta är associerade med mänsklig intelligens. Dessa uppgifter omfattar bildigenkänning, taligenkänning och språköversättning.
Tekniker för djupinlärning jämfört med maskininlärning
Nu när du har översikten över maskininlärning jämfört med djupinlärning ska vi jämföra de två teknikerna. I maskininlärning måste algoritmen få veta hur man gör en korrekt förutsägelse genom att använda mer information (till exempel genom att utföra extrahering av funktioner). I djupinlärning kan algoritmen lära sig att göra en korrekt förutsägelse genom sin egen databearbetning, tack vare den artificiella neurala nätverksstrukturen.
I följande tabell jämförs de två teknikerna mer detaljerat:
| All maskininlärning | Endast djupinlärning | |
|---|---|---|
| Antal datapunkter | Kan använda små mängder data för att göra förutsägelser. | Behöver använda stora mängder träningsdata för att göra förutsägelser. |
| Maskinvaruberoenden | Kan fungera på lågslutsdatorer. Den behöver inte en stor mängd beräkningskraft. | Beror på avancerade datorer. Den utför till sin natur ett stort antal matris multiplikationsåtgärder. En GPU kan effektivt optimera dessa åtgärder. |
| Funktionaliseringsprocess | Kräver att funktioner identifieras och skapas korrekt av användare. | Lär dig funktioner på hög nivå från data och skapar nya funktioner på egen hand. |
| Inlärningsmetod | Delar upp inlärningsprocessen i mindre steg. Sedan kombineras resultatet från varje steg till en utdata. | Går igenom inlärningsprocessen genom att lösa problemet från slutpunkt till slutpunkt. |
| Körningstid | Tar jämförelsevis lite tid att träna, allt från några sekunder till några timmar. | Det tar vanligtvis lång tid att träna eftersom en djupinlärningsalgoritm omfattar många lager. |
| Output | Utdata är vanligtvis ett numeriskt värde, till exempel en poäng eller en klassificering. | Utdata kan ha flera format, till exempel en text, en poäng eller ett ljud. |
Vad är överföringsinlärning?
Att träna djupinlärningsmodeller kräver ofta stora mängder träningsdata, avancerade beräkningsresurser (GPU, TPU) och en längre träningstid. I scenarier där du inte har något av dessa tillgängliga kan du genväg till träningsprocessen med hjälp av en teknik som kallas överföringsinlärning.
Överföringsinlärning är en teknik som tillämpar kunskap från att lösa ett problem på ett annat men relaterat problem.
På grund av strukturen för neurala nätverk innehåller den första uppsättningen lager vanligtvis funktioner på lägre nivå, medan den sista uppsättningen lager innehåller funktioner på högre nivå som ligger närmare domänen i fråga. Genom att återanvända de sista lagren för användning i en ny domän eller ett problem kan du avsevärt minska mängden tid, data och beräkningsresurser som behövs för att träna den nya modellen. Om du till exempel redan har en modell som känner igen bilar kan du återanvända modellen med hjälp av överföringsinlärning för att även identifiera lastbilar, motorcyklar och andra typer av fordon.
Lär dig hur du tillämpar överföringsinlärning för bildklassificering med hjälp av ett ramverk med öppen källkod i Azure Mašinsko učenje : Träna en PyTorch-modell för djupinlärning med hjälp av överföringsinlärning.
Användningsfall för djupinlärning
På grund av den artificiella neurala nätverksstrukturen utmärker sig djupinlärning för att identifiera mönster i ostrukturerade data som bilder, ljud, video och text. Därför omvandlar djupinlärning snabbt många branscher, inklusive sjukvård, energi, ekonomi och transport. Dessa branscher omprövar nu traditionella affärsprocesser.
Några av de vanligaste programmen för djupinlärning beskrivs i följande stycken. I Azure Mašinsko učenje kan du använda en modell som du har skapat från ett ramverk med öppen källkod eller skapa modellen med hjälp av de verktyg som tillhandahålls.
Igenkänning med namngiven entitet
Namngiven entitetsigenkänning är en djupinlärningsmetod som tar en text som indata och omvandlar den till en fördefinierad klass. Den här nya informationen kan vara ett postnummer, ett datum, ett produkt-ID. Informationen kan sedan lagras i ett strukturerat schema för att skapa en lista med adresser eller fungera som ett riktmärke för en identitetsverifieringsmotor.
Objektidentifiering
Djupinlärning har tillämpats i många användningsfall för objektidentifiering. Objektidentifiering används för att identifiera objekt i en bild (till exempel bilar eller personer) och ange en specifik plats för varje objekt med en avgränsningsruta.
Objektidentifiering används redan i branscher som spel, detaljhandel, turism och självkörande bilar.
Bildtextgenerering
Liksom bildigenkänning, i bildtexter, för en viss bild, måste systemet generera en bildtext som beskriver innehållet i bilden. När du kan identifiera och märka objekt i fotografier är nästa steg att omvandla etiketterna till beskrivande meningar.
I program för bildtexter används vanligtvis konvolutionala neurala nätverk för att identifiera objekt i en bild och sedan använda ett återkommande neuralt nätverk för att omvandla etiketterna till konsekventa meningar.
Maskinöversättning
Maskinöversättning tar ord eller meningar från ett språk och översätter dem automatiskt till ett annat språk. Maskinöversättning har funnits länge, men djupinlärning ger imponerande resultat inom två specifika områden: automatisk översättning av text (och översättning av tal till text) och automatisk översättning av bilder.
Med lämplig datatransformering kan ett neuralt nätverk förstå text-, ljud- och visuella signaler. Maskinöversättning kan användas för att identifiera ljudfragment i större ljudfiler och transkribera det talade ordet eller bilden som text.
Textanalys
Textanalys baserad på djupinlärningsmetoder innebär att analysera stora mängder textdata (till exempel medicinska dokument eller utgiftskvitton), identifiera mönster och skapa organiserad och kortfattad information ur den.
Företag använder djupinlärning för att utföra textanalys för att upptäcka insiderhandel och efterlevnad av myndighetsregler. Ett annat vanligt exempel är försäkringsbedrägerier: textanalys har ofta använts för att analysera stora mängder dokument för att identifiera risken för att ett försäkringsanspråk är bedrägeri.
Artificiella neurala nätverk
Artificiella neurala nätverk bildas av lager av anslutna noder. Djupinlärningsmodeller använder neurala nätverk som har ett stort antal lager.
Följande avsnitt utforskar de mest populära topologierna för artificiella neurala nätverk.
Feedforward neuralt nätverk
Feedforward neurala nätverk är den enklaste typen av artificiella neurala nätverk. I ett feedforward-nätverk flyttas informationen bara i en riktning från indataskiktet till utdataskiktet. Feedforward neurala nätverk omvandlar en indata genom att placera den genom en serie dolda lager. Varje lager består av en uppsättning neuroner, och varje lager är helt anslutet till alla neuroner i lagret tidigare. Det senaste helt anslutna lagret (utdataskiktet) representerar de genererade förutsägelserna.
RNN (Recurrent Neural Network)
Återkommande neurala nätverk är ett allmänt använt artificiellt neuralt nätverk. Dessa nätverk sparar utdata från ett lager och matar tillbaka det till indataskiktet för att förutsäga lagrets resultat. Återkommande neurala nätverk har bra inlärningsförmåga. De används ofta för komplexa uppgifter som prognostisering av tidsserier, inlärning av handskrift och språkidentisering.
CNN (Convolutional Neural Network – faltningsnätverk)
Ett convolutional neuralt nätverk är ett särskilt effektivt artificiellt neuralt nätverk, och det presenterar en unik arkitektur. Lagren är ordnade i tre dimensioner: bredd, höjd och djup. Neuronerna i ett lager ansluter inte till alla neuroner i nästa lager, utan bara till en liten region av lagrets neuroner. De slutliga utdata minskas till en enda vektor med sannolikhetspoäng, ordnade längs djupdimensionen.
Convolutional neurala nätverk har använts inom områden som videoigenkänning, bildigenkänning och rekommenderande system.
GAN (Generative Adversarial Network)
Generativa kontradiktoriska nätverk är generativa modeller som tränats att skapa realistiskt innehåll, till exempel bilder. Det består av två nätverk som kallas generator och diskriminerande. Båda nätverken tränas samtidigt. Under träningen använder generatorn slumpmässigt brus för att skapa nya syntetiska data som liknar verkliga data. Diskrimineringen tar utdata från generatorn som indata och använder verkliga data för att avgöra om det genererade innehållet är verkligt eller syntetiskt. Varje nätverk konkurrerar med varandra. Generatorn försöker generera syntetiskt innehåll som inte kan skiljas från verkligt innehåll och diskrimineringen försöker korrekt klassificera indata som verkliga eller syntetiska. Utdata används sedan för att uppdatera vikten för båda nätverken för att hjälpa dem att bättre uppnå sina respektive mål.
Generativa kontradiktoriska nätverk används för att lösa problem som bild-till-bildöversättning och åldersprogression.
Omvandlare
Transformatorer är en modellarkitektur som lämpar sig för att lösa problem som innehåller sekvenser som text- eller tidsseriedata. De består av kodar- och avkodarlager. Kodaren tar en indata och mappar den till en numerisk representation som innehåller information, till exempel kontext. Avkodaren använder information från kodaren för att skapa utdata, till exempel översatt text. Det som skiljer transformatorer från andra arkitekturer som innehåller kodare och avkodare är underskikten för uppmärksamhet. Uppmärksamhet är tanken på att fokusera på specifika delar av en indata baserat på vikten av deras kontext i förhållande till andra indata i en sekvens. När du till exempel sammanfattar en nyhetsartikel är inte alla meningar relevanta för att beskriva huvudidén. Genom att fokusera på nyckelord i hela artikeln kan sammanfattning göras i en enda mening, rubriken.
Transformatorer har använts för att lösa problem med bearbetning av naturligt språk, till exempel översättning, textgenerering, frågesvar och textsammanfattning.
Några välkända implementeringar av transformatorer är:
- Dubbelriktad kodare representationer från transformatorer (BERT)
- Generativ förtränad Transformer 2 (GPT-2)
- Generativ förtränad transformerare 3 (GPT-3)
Nästa steg
Följande artiklar visar fler alternativ för att använda djupinlärningsmodeller med öppen källkod i Azure Mašinsko učenje: