Batch-slutpunkter
Med Azure Mašinsko učenje kan du implementera batchslutpunkter och distributioner för att utföra långvariga, asynkrona inferenser med maskininlärningsmodeller och pipelines. När du tränar en maskininlärningsmodell eller pipeline måste du distribuera den så att andra kan använda den med nya indata för att generera förutsägelser. Den här processen för att generera förutsägelser med modellen eller pipelinen kallas inferens.
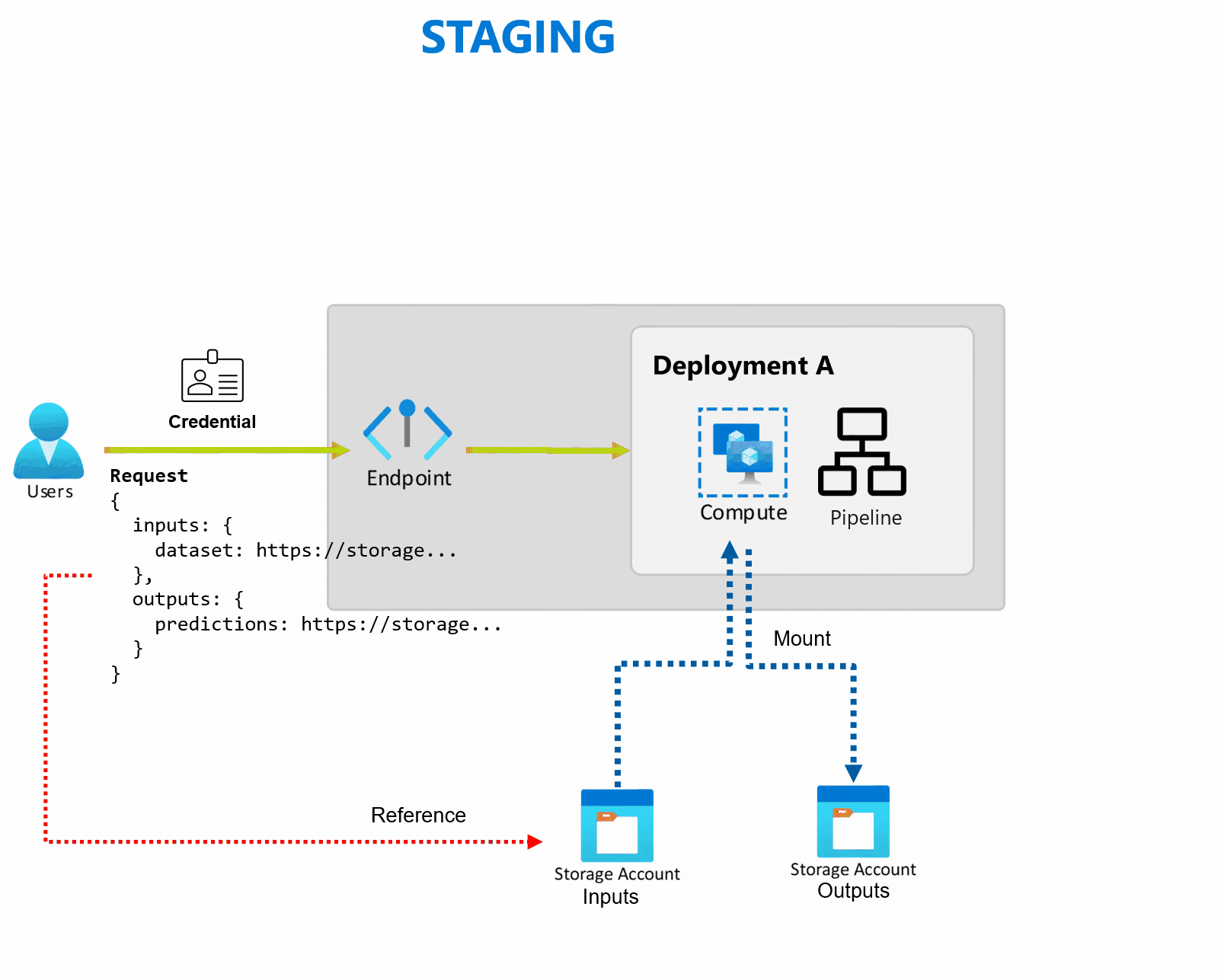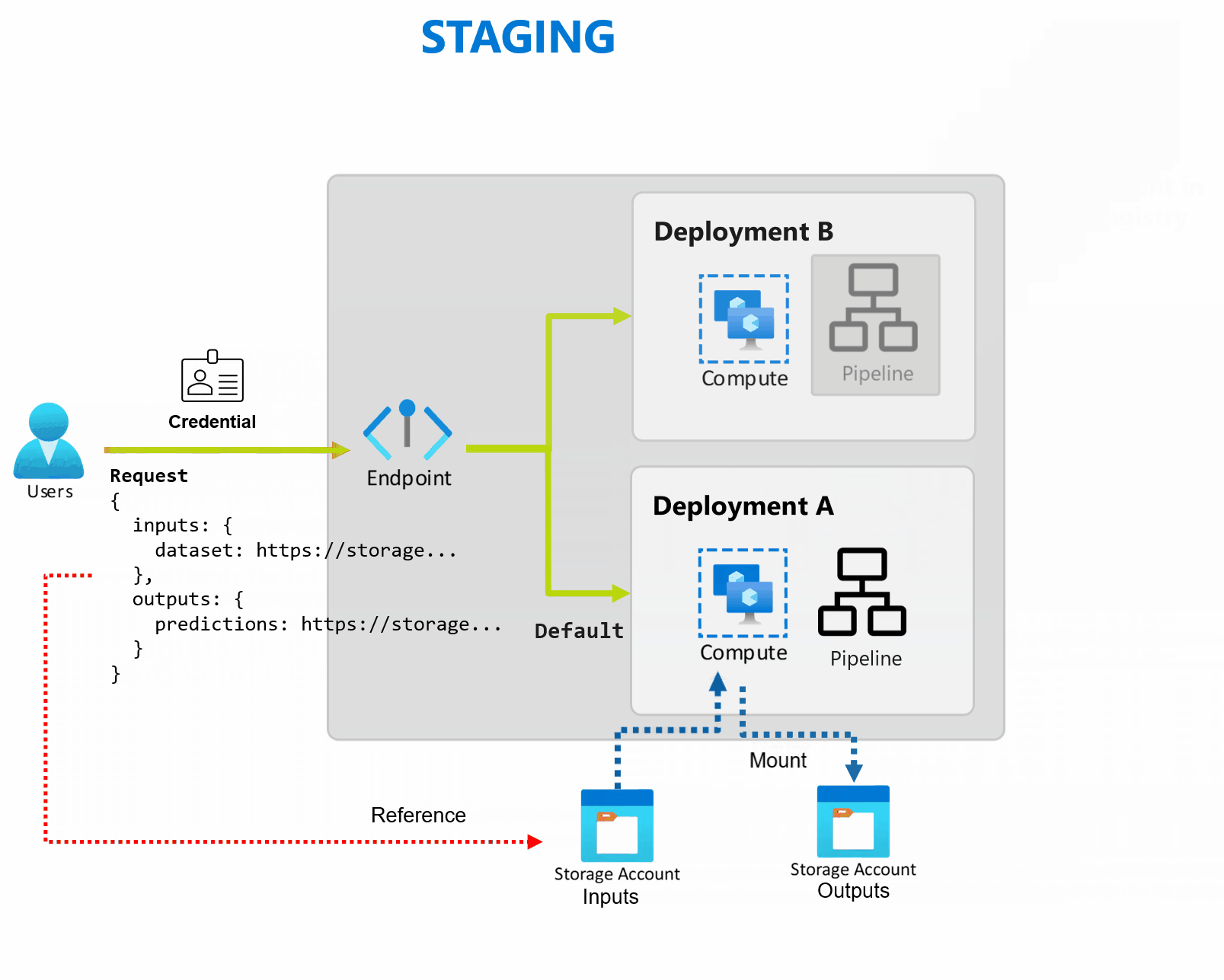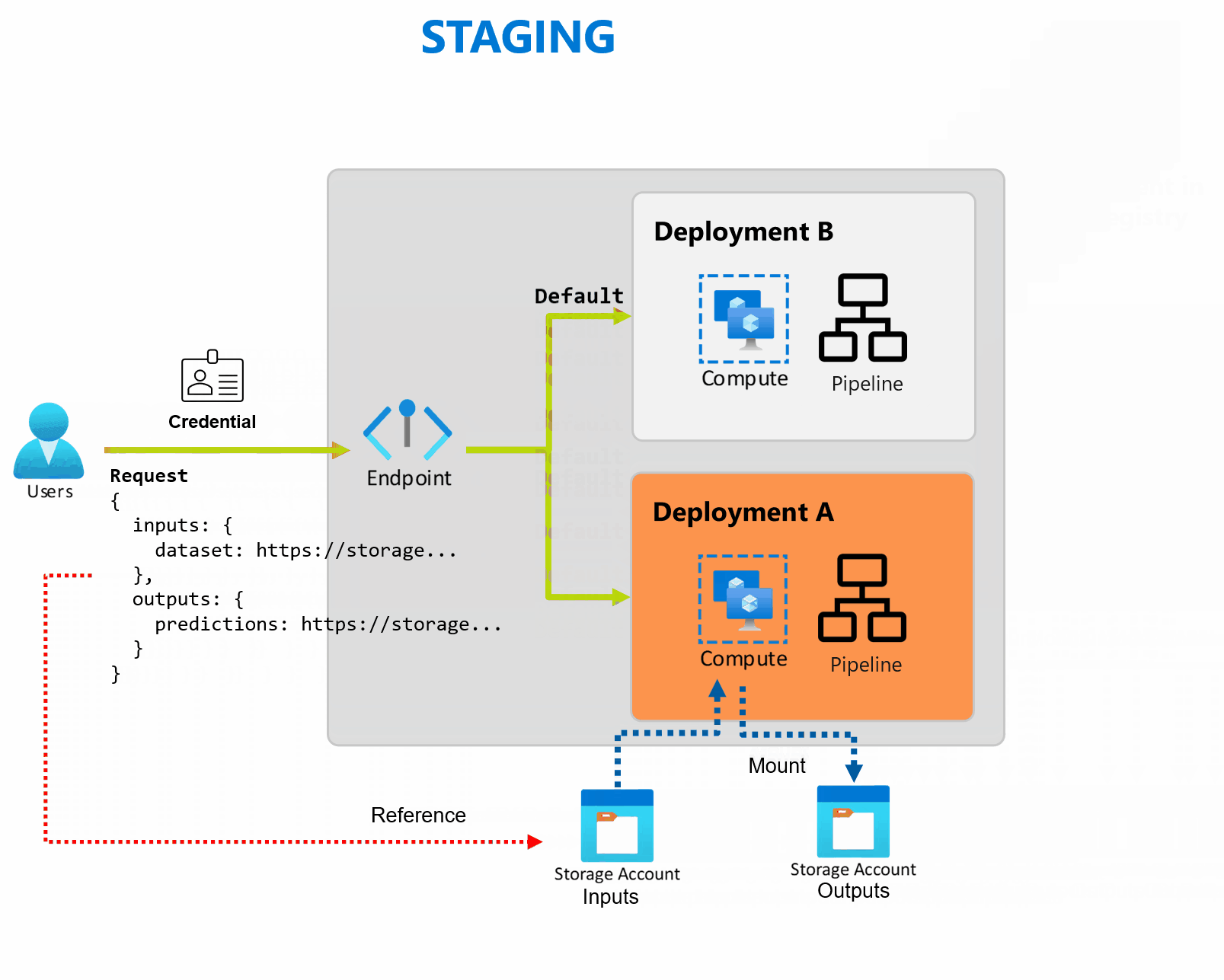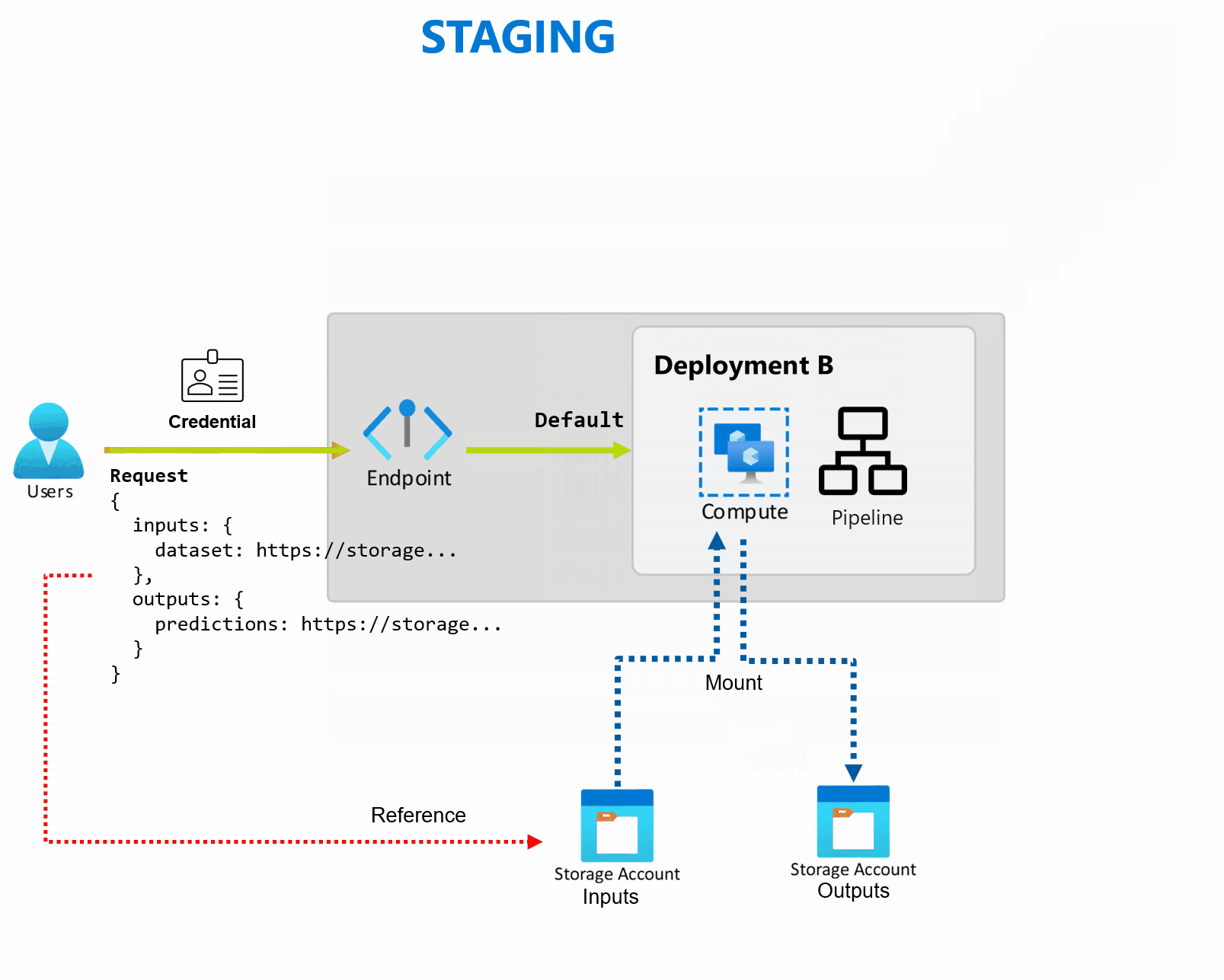
Batch-slutpunkter tar emot pekare till data och kör jobb asynkront för att bearbeta data parallellt i beräkningskluster. Batch-slutpunkter lagrar utdata till ett datalager för ytterligare analys. Använd batchslutpunkter när:
- Du har dyra modeller eller pipelines som kräver längre tid att köra.
- Du vill operationalisera maskininlärningspipelines och återanvända komponenter.
- Du måste utföra slutsatsdragning över stora mängder data som distribueras i flera filer.
- Du har inte krav på låg svarstid.
- Modellens indata lagras i ett lagringskonto eller i en Azure Machine Learning-datatillgång.
- Du kan dra nytta av parallellisering.
Batch-distributioner
En distribution är en uppsättning resurser och beräkningar som krävs för att implementera de funktioner som slutpunkten tillhandahåller. Varje slutpunkt kan vara värd för flera distributioner med olika konfigurationer, och den här funktionen hjälper till att frikoppla slutpunktens gränssnitt från implementeringsinformationen som definieras av distributionen. När en batchslutpunkt anropas dirigeras klienten automatiskt till standarddistributionen. Den här standarddistributionen kan konfigureras och ändras när som helst.

Två typer av distributioner är möjliga i Azure Mašinsko učenje batchslutpunkter:
Modelldistribution
Modelldistribution möjliggör driftsättning av modellinferenser i stor skala, så att du kan bearbeta stora mängder data på ett kort svarstids- och asynkront sätt. Azure Mašinsko učenje instrumenterar automatiskt skalbarhet genom att tillhandahålla parallellisering av inferensprocesserna mellan flera noder i ett beräkningskluster.
Använd modelldistribution när:
- Du har dyra modeller som kräver längre tid för att köra slutsatsdragning.
- Du måste utföra slutsatsdragning över stora mängder data som distribueras i flera filer.
- Du har inte krav på låg svarstid.
- Du kan dra nytta av parallellisering.
Den största fördelen med modelldistributioner är att du kan använda samma tillgångar som distribueras för realtidsinferens till onlineslutpunkter, men nu får du köra dem i stor skala i batch. Om din modell kräver enkel förbearbetning eller efterbearbetning kan du skapa ett bedömningsskript som utför de datatransformeringar som krävs.
Om du vill skapa en modelldistribution i en batchslutpunkt måste du ange följande element:
- Modell
- Beräkningskluster
- Bedömningsskript (valfritt för MLflow-modeller)
- Miljö (valfritt för MLflow-modeller)
Distribution av pipelinekomponenter
Distribution av pipelinekomponenter gör det möjligt att operationalisera hela bearbetningsdiagram (eller pipelines) för att utföra batchinferens på ett kort svarstids- och asynkront sätt.
Använd pipelinekomponentdistribution när:
- Du måste operationalisera fullständiga beräkningsdiagram som kan delas upp i flera steg.
- Du måste återanvända komponenter från träningspipelines i din slutsatsdragningspipeline.
- Du har inte krav på låg svarstid.
Den största fördelen med distributioner av pipelinekomponenter är återanvändning av komponenter som redan finns i din plattform och möjligheten att operationalisera komplexa slutsatsdragningsrutiner.
Om du vill skapa en pipelinekomponentdistribution i en batchslutpunkt måste du ange följande element:
- Pipelinekomponent
- Konfiguration av beräkningskluster
Med Batch-slutpunkter kan du också skapa pipelinekomponentdistributioner från ett befintligt pipelinejobb. När du gör det skapar Azure Mašinsko učenje automatiskt en pipelinekomponent från jobbet. Detta förenklar användningen av den här typen av distributioner. Det är dock bästa praxis att alltid skapa pipelinekomponenter explicit för att effektivisera MLOps-metoden.
Kostnadshantering
Om du anropar en batchslutpunkt utlöses ett asynkront batchinferensjobb. Azure Mašinsko učenje etablerar automatiskt beräkningsresurser när jobbet startar och frigör dem automatiskt när jobbet slutförs. På så sätt betalar du bara för beräkning när du använder den.
Dricks
När du distribuerar modeller kan du åsidosätta beräkningsresursinställningar (t.ex. antal instanser) och avancerade inställningar (t.ex. mini batchstorlek, feltröskel och så vidare) för varje enskilt batchinferensjobb. Genom att dra nytta av dessa specifika konfigurationer kanske du kan påskynda körningen och minska kostnaderna.
Batchslutpunkter kan också köras på virtuella datorer med låg prioritet. Batch-slutpunkter kan automatiskt återställas från frigjorda virtuella datorer och återuppta arbetet där det lämnades när modeller distribuerades för slutsatsdragning. Mer information om hur du använder virtuella datorer med låg prioritet för att minska kostnaden för batchinferensarbetsbelastningar finns i Använda virtuella datorer med låg prioritet i batchslutpunkter.
Slutligen debiterar Inte Azure Mašinsko učenje dig för själva batchslutpunkter eller batchdistributioner, så du kan ordna dina slutpunkter och distributioner så att de passar bäst för ditt scenario. Slutpunkter och distributioner kan använda oberoende eller delade kluster, så att du kan få detaljerad kontroll över vilken beräkning jobben använder. Använd skala till noll i kluster för att säkerställa att inga resurser förbrukas när de är inaktiva.
Effektivisera MLOps-metoden
Batch-slutpunkter kan hantera flera distributioner under samma slutpunkt, så att du kan ändra implementeringen av slutpunkten utan att ändra den URL som dina konsumenter använder för att anropa den.
Du kan lägga till, ta bort och uppdatera distributioner utan att påverka själva slutpunkten.
Flexibla datakällor och lagring
Batchslutpunkter läser och skriver data direkt från lagring. Du kan ange Azure Mašinsko učenje datalager, Azure Mašinsko učenje datatillgångar eller Lagringskonton som indata. Mer information om de indataalternativ som stöds och hur du anger dem finns i Skapa jobb och mata in data till batchslutpunkter.
Säkerhet
Batch-slutpunkter tillhandahåller alla funktioner som krävs för att köra arbetsbelastningar på produktionsnivå i en företagsinställning. De stöder privata nätverk på skyddade arbetsytor och Microsoft Entra-autentisering, antingen med ett användarhuvudnamn (till exempel ett användarkonto) eller ett huvudnamn för tjänsten (till exempel en hanterad eller ohanterad identitet). Jobb som genereras av en batchslutpunkt körs under anroparens identitet, vilket ger dig flexibiliteten att implementera alla scenarier. Mer information om auktorisering när du använder batchslutpunkter finns i Autentisera på batchslutpunkter.