Använd Python-tolkningspaketet för att förklara ML-modeller och förutsägelser (förhandsversion)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här instruktionsguiden lär du dig att använda tolkningspaketet i Azure Machine Learning Python SDK för att utföra följande uppgifter:
Förklara hela modellbeteendet eller enskilda förutsägelser på din personliga dator lokalt.
Aktivera tolkningstekniker för konstruerade funktioner.
Förklara beteendet för hela modellen och enskilda förutsägelser i Azure.
Ladda upp förklaringar till Körningshistorik för Azure Machine Learning.
Använd en instrumentpanel för visualisering för att interagera med dina modellförklaringar, både i en Jupyter Notebook och i Azure Machine Learning-studio.
Distribuera en bedömningsförklaring tillsammans med din modell för att observera förklaringar under inferensen.
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Mer information om de tolkningstekniker och maskininlärningsmodeller som stöds finns i Modelltolkning i Azure Machine Learning och exempelanteckningsböcker.
Vägledning om hur du aktiverar tolkning för modeller som tränats med automatiserad maskininlärning finns i Tolka: modellförklaringar för automatiserade maskininlärningsmodeller (förhandsversion).
Generera värde för funktionsprimitet på din personliga dator
I följande exempel visas hur du använder tolkningspaketet på din personliga dator utan att kontakta Azure-tjänster.
Installera paketet
azureml-interpret.pip install azureml-interpretTräna en exempelmodell i en lokal Jupyter Notebook.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Anropa förklaringen lokalt.
- Om du vill initiera ett förklarande objekt skickar du din modell och några träningsdata till förklaringskonstruktorn.
- Om du vill göra dina förklaringar och visualiseringar mer informativa kan du välja att skicka in funktionsnamn och utdataklassnamn om du gör klassificering.
Följande kodblock visar hur du instansierar ett förklaringsobjekt med
TabularExplainer,MimicExplainerochPFIExplainerlokalt.TabularExplaineranropar en av de tre SHAP-förklaringarna under (TreeExplainer,DeepExplainer, ellerKernelExplainer).TabularExplainerväljer automatiskt den lämpligaste för ditt användningsfall, men du kan anropa var och en av dess tre underliggande förklaringar direkt.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)eller
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)eller
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
Förklara hela modellbeteendet (global förklaring)
I följande exempel får du hjälp med att hämta de aggregerade (globala) funktionsvärdevärdena.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Förklara en enskild förutsägelse (lokal förklaring)
Hämta de enskilda funktionsvärdevärdena för olika datapunkter genom att anropa förklaringar för en enskild instans eller en grupp med instanser.
Kommentar
PFIExplainer stöder inte lokala förklaringar.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Råa funktionstransformeringar
Du kan välja att få förklaringar när det gäller råa, otransformerade funktioner i stället för konstruerade funktioner. För det här alternativet skickar du din pipeline för funktionstransformering till förklaringen i train_explain.py. I annat fall ger förklaringen förklaringar när det gäller konstruerade funktioner.
Formatet för omvandlingar som stöds är detsamma som beskrivs i sklearn-pandas. I allmänhet stöds alla transformeringar så länge de fungerar på en enda kolumn så att det är tydligt att de är en-till-många.
Få en förklaring av råa funktioner med hjälp av en sklearn.compose.ColumnTransformer eller med en lista över anpassade transformatortupplar. I följande exempel används sklearn.compose.ColumnTransformer.
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Om du vill köra exemplet med listan över anpassade transformatortupplar använder du följande kod:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Generera värden för funktionsvikt via fjärrkörningar
I följande exempel visas hur du kan använda ExplanationClient klassen för att aktivera modelltolkning för fjärrkörningar. Det är konceptuellt likt den lokala processen, förutom att du:
ExplanationClientAnvänd i fjärrkörningen för att ladda upp tolkningskontexten.- Ladda ned kontexten senare i en lokal miljö.
Installera paketet
azureml-interpret.pip install azureml-interpretSkapa ett träningsskript i en lokal Jupyter Notebook. Exempel:
train_explain.pyfrom azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Konfigurera en Azure Machine Learning Compute som beräkningsmål och skicka träningskörningen. Anvisningar finns i Skapa och hantera Azure Machine Learning-beräkningskluster . Du kanske också tycker att det är användbart med exempelanteckningsböcker .
Ladda ned förklaringen i din lokala Jupyter Notebook.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Visualiseringar
När du har laddat ned förklaringarna i din lokala Jupyter Notebook kan du använda visualiseringarna på instrumentpanelen för förklaringar för att förstå och tolka din modell. Om du vill läsa in instrumentpanelswidgeten för förklaringar i din Jupyter Notebook använder du följande kod:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
Visualiseringarna stöder förklaringar av både konstruerade och råa funktioner. Rådataförklaringar baseras på funktionerna från den ursprungliga datamängden och de konstruerade förklaringarna baseras på funktionerna från datauppsättningen med funktionstekniker tillämpade.
När du försöker tolka en modell med avseende på den ursprungliga datamängden rekommenderar vi att du använder rådataförklaringar eftersom varje funktionsvikt motsvarar en kolumn från den ursprungliga datauppsättningen. Ett scenario där konstruerade förklaringar kan vara användbara är när du undersöker effekten av enskilda kategorier från en kategorisk funktion. Om en kodning med en frekvent kodning tillämpas på en kategorisk funktion, kommer de resulterande kompilerade förklaringarna att innehålla ett annat prioritetsvärde per kategori, en per en frekvent och utvecklad funktion. Den här kodningen kan vara användbar när du begränsar vilken del av datamängden som är mest informativ för modellen.
Kommentar
Konstruerade och råa förklaringar beräknas sekventiellt. Först skapas en konstruerad förklaring baserat på modell- och funktionaliseringspipelinen. Sedan skapas den råa förklaringen baserat på den skapade förklaringen genom att aggregera vikten av konstruerade funktioner som kom från samma råfunktion.
Skapa, redigera och visa datamängdskohorter
Det övre menyfliksområdet visar den övergripande statistiken för din modell och dina data. Du kan dela upp och tärna dina data i datamängdskohorter, eller undergrupper, för att undersöka eller jämföra modellens prestanda och förklaringar mellan dessa definierade undergrupper. Genom att jämföra datamängdsstatistiken och förklaringarna i dessa undergrupper kan du få en uppfattning om varför möjliga fel inträffar i en grupp jämfört med en annan.

Förstå hela modellbeteendet (global förklaring)
De första tre flikarna på förklaringsinstrumentpanelen ger en övergripande analys av den tränade modellen tillsammans med dess förutsägelser och förklaringar.
Modellprestanda
Utvärdera modellens prestanda genom att utforska fördelningen av dina förutsägelsevärden och värdena för dina modellprestandamått. Du kan undersöka din modell ytterligare genom att titta på en jämförande analys av dess prestanda i olika kohorter eller undergrupper av datamängden. Välj filter längs y-value och x-value för att skära över olika dimensioner. Visa mått som noggrannhet, precision, återkallande, falsk positiv frekvens (FPR) och falsk negativ frekvens (FNR).

Datauppsättningsutforskaren
Utforska datamängdsstatistiken genom att välja olika filter längs X-, Y- och färgaxlarna för att segmentera dina data längs olika dimensioner. Skapa datamängdskohorter ovan för att analysera datamängdsstatistik med filter som förutsagt resultat, datamängdsfunktioner och felgrupper. Använd kugghjulsikonen i det övre högra hörnet av grafen för att ändra diagramtyper.

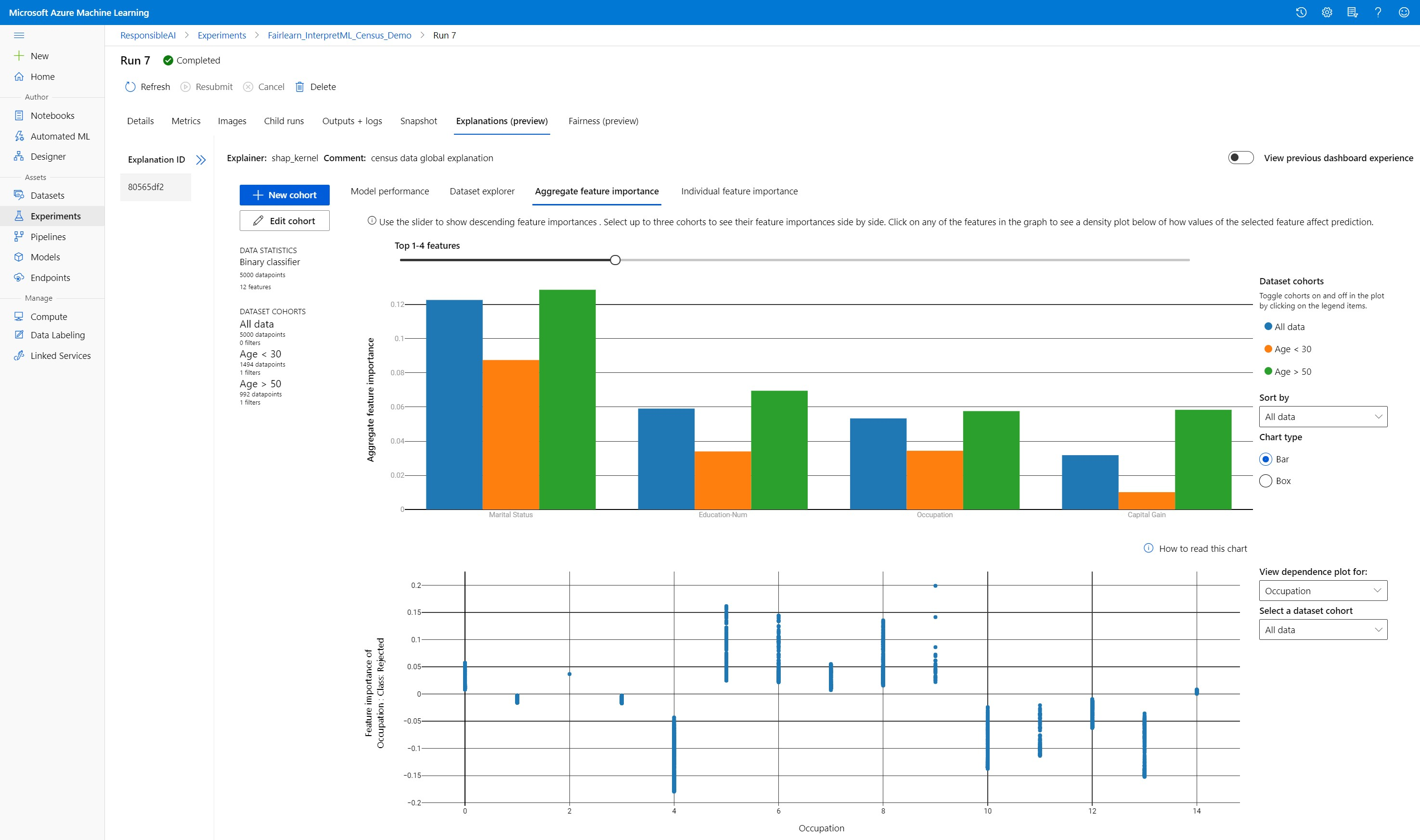
Aggregerad funktionsvikt
Utforska de viktigaste funktionerna som påverkar dina övergripande modellförutsägelser (kallas även global förklaring). Använd skjutreglaget för att visa värden för fallande funktionsvikt. Välj upp till tre kohorter för att se deras funktionsvärde sida vid sida. Välj någon av funktionsstaplarna i diagrammet för att se hur värden för den valda funktionen påverkar modellförutsägelse i beroendediagrammet nedan.

Förstå enskilda förutsägelser (lokal förklaring)
På den fjärde fliken på förklaringsfliken kan du öka detaljnivån för en enskild datapunkt och deras enskilda funktionsvikter. Du kan läsa in det enskilda funktionsviktsdiagrammet för valfri datapunkt genom att klicka på någon av de enskilda datapunkterna i huvuddiagrammet eller välja en specifik datapunkt i panelguiden till höger.
| Diagram | beskrivning |
|---|---|
| Individuell funktionsvikt | Visar de viktigaste funktionerna för en enskild förutsägelse. Hjälper till att illustrera det lokala beteendet för den underliggande modellen på en specifik datapunkt. |
| Konsekvensanalys | Tillåter ändringar av funktionsvärden för den valda verkliga datapunkten och observerar resulterande ändringar i förutsägelsevärdet genom att generera en hypotetisk datapunkt med de nya funktionsvärdena. |
| Individuell villkorsförväntning (ICE) | Tillåter funktionsvärdeändringar från ett minimivärde till ett högsta värde. Hjälper till att illustrera hur datapunktens förutsägelse ändras när en funktion ändras. |

Kommentar
Det här är förklaringar baserade på många uppskattningar och är inte "orsaken" till förutsägelser. Utan strikt matematisk robusthet av kausal slutsatsdragning rekommenderar vi inte användare att fatta verkliga beslut baserat på funktionsavvikelserna i What-If-verktyget. Det här verktyget är främst till för att förstå din modell och felsökning.
Visualisering i Azure Machine Learning-studio
Om du slutför stegen för fjärrtolkning (ladda upp genererade förklaringar till Azure Machine Learning Run History) kan du visa visualiseringarna på instrumentpanelen för förklaringar i Azure Machine Learning-studio. Den här instrumentpanelen är en enklare version av instrumentpanelswidgeten som genereras i din Jupyter Notebook. What-If-datapointgenerering och ICE-diagram inaktiveras eftersom det inte finns någon aktiv beräkning i Azure Machine Learning-studio som kan utföra sina realtidsberäkningar.
Om datauppsättningen, globala och lokala förklaringar är tillgängliga fylls alla flikar i. Men om det bara finns en global förklaring inaktiveras fliken Individuell funktionsvikt.
Följ någon av dessa sökvägar för att komma åt instrumentpanelen för förklaringar i Azure Machine Learning-studio:
Fönstret Experiment (förhandsversion)
- Välj Experiment i den vänstra rutan för att se en lista över experiment som du har kört i Azure Machine Learning.
- Välj ett visst experiment för att visa alla körningar i experimentet.
- Välj en körning och sedan fliken Förklaringar till instrumentpanelen för förklaringsvisualisering.
Fönstret Modeller
- Om du har registrerat din ursprungliga modell genom att följa stegen i Distribuera modeller med Azure Machine Learning kan du välja Modeller i den vänstra rutan för att visa den.
- Välj en modell och sedan fliken Förklaringar för att visa instrumentpanelen för förklaringar.

Tolkningsbarhet vid slutsatsdragningstid
Du kan distribuera förklaringen tillsammans med den ursprungliga modellen och använda den vid slutsatsdragningstidpunkten för att ange de enskilda funktionsvärdevärdena (lokal förklaring) för alla nya datapunkter. Vi erbjuder även förklarande poängsättning med lägre vikt för att förbättra tolkningsprestanda vid slutsatsdragning, som för närvarande endast stöds i Azure Machine Learning SDK. Processen med att distribuera en poängförklaring med lägre vikt liknar distributionen av en modell och innehåller följande steg:
Skapa ett förklaringsobjekt. Du kan till exempel använda
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Skapa en bedömningsförklaring med förklaringsobjektet.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)Konfigurera och registrera en avbildning som använder bedömningsförklaringsmodellen.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Som ett valfritt steg kan du hämta bedömningsförklaringen från molnet och testa förklaringarna.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Distribuera avbildningen till ett beräkningsmål genom att följa dessa steg:
Om det behövs registrerar du din ursprungliga förutsägelsemodell genom att följa stegen i Distribuera modeller med Azure Machine Learning.
Skapa en bedömningsfil.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Definiera distributionskonfigurationen.
Den här konfigurationen beror på kraven för din modell. I följande exempel definieras en konfiguration som använder en processorkärna och en GB minne.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Skapa en fil med miljöberoenden.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Skapa en anpassad dockerfile med g++ installerat.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Distribuera den skapade avbildningen.
Den här processen tar ungefär fem minuter.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Testa distributionen.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Städa upp.
Om du vill ta bort en distribuerad webbtjänst använder du
service.delete().
Felsökning
Glesa data stöds inte: Instrumentpanelen för modellförklaringen bryter/saktar ned avsevärt med ett stort antal funktioner, därför stöder vi för närvarande inte glesa dataformat. Dessutom uppstår allmänna minnesproblem med stora datamängder och ett stort antal funktioner.
Funktionsmatris för förklaringar som stöds
| Förklaringsflik som stöds | Raw-funktioner (tät) | Raw-funktioner (gles) | Konstruerade funktioner (kompakta) | Konstruerade funktioner (glesa) |
|---|---|---|---|---|
| Modellprestanda | Stöds (inte prognostisering) | Stöds (inte prognostisering) | Stöds | Stöds |
| Datauppsättningsutforskaren | Stöds (inte prognostisering) | Stöds ej. Eftersom glesa data inte laddas upp och användargränssnittet har problem med att återge glesa data. | Stöds | Stöds ej. Eftersom glesa data inte laddas upp och användargränssnittet har problem med att återge glesa data. |
| Aggregerad funktionsvikt | Stöds | Stöds | Stöds | Stöds |
| Individuell funktionsvikt | Stöds (inte prognostisering) | Stöds ej. Eftersom glesa data inte laddas upp och användargränssnittet har problem med att återge glesa data. | Stöds | Stöds ej. Eftersom glesa data inte laddas upp och användargränssnittet har problem med att återge glesa data. |
Prognosmodeller stöds inte med modellförklaringar: Tolkning, bästa modellförklaring, är inte tillgängligt för AutoML-prognosexperiment som rekommenderar följande algoritmer som den bästa modellen: TCNForecaster, AutoArima, Prophet, ExponentialSmoothing, Average, Naive, Seasonal Average och Seasonal Naive. Regressionsmodeller för AutoML-prognostisering stöder förklaringar. I förklaringsinstrumentpanelen stöds dock inte fliken "Individuell funktionsvikt" för prognostisering på grund av komplexiteten i deras datapipelines.
Lokal förklaring för dataindex: Förklaringsinstrumentpanelen stöder inte relaterade lokala prioritetsvärden till en radidentifierare från den ursprungliga valideringsdatauppsättningen om datamängden är större än 5 000 datapunkter eftersom instrumentpanelen slumpmässigt minskar datamängden. Instrumentpanelen visar dock funktionsvärden för rådatauppsättningar för varje datapunkt som skickas till instrumentpanelen under fliken Individuell funktionsvikt. Användare kan mappa lokala betydelser tillbaka till den ursprungliga datamängden genom att matcha funktionsvärdena för rådatauppsättningen. Om storleken på valideringsdatauppsättningen är mindre än 5 000 exempel
indexmotsvarar funktionen i Azure Machine Learning-studio indexet i valideringsdatauppsättningen.Konsekvensdiagram/ICE-diagram stöds inte i studiodiagram: Ice-diagram (What-If och Individual Conditional Expectation) stöds inte i Azure Machine Learning-studio under fliken Förklaringar eftersom den uppladdade förklaringen behöver en aktiv beräkning för att beräkna om förutsägelser och sannolikheter för störda funktioner. Det stöds för närvarande i Jupyter Notebooks när det körs som en widget med hjälp av SDK.
Nästa steg
Tekniker för modelltolkning i Azure Machine Learning
Kolla in exempel på notebook-filer för Azure Machine Learning-tolkning