Exempel på pipelines och datamängder för Azure Machine Learning
Använd de inbyggda exemplen i Azure Machine Learning-designern för att snabbt komma igång med att skapa egna maskininlärningspipelines. GitHub-lagringsplatsen för Azure Machine Learning Designer innehåller detaljerad dokumentation som hjälper dig att förstå några vanliga maskininlärningsscenarier.
Förutsättningar
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto
- En Azure Machine Learning-arbetsyta
Viktigt!
Om du inte ser grafiska element som nämns i det här dokumentet, till exempel knappar i studio eller designer, kanske du inte har rätt behörighetsnivå för arbetsytan. Kontakta azure-prenumerationsadministratören för att kontrollera att du har beviljats rätt åtkomstnivå. Mer information finns i Hantera användare och roller.
Använda exempelpipelines
Designern sparar en kopia av exempelpipelines till din studioarbetsyta. Du kan redigera pipelinen för att anpassa den efter dina behov och spara den som din egen. Använd dem som utgångspunkt för att komma igång med dina projekt.
Så här använder du ett designerexempel:
Logga in på ml.azure.com och välj den arbetsyta som du vill arbeta med.
Välj Designer.
Välj en exempelpipeline under avsnittet Ny pipeline .
Välj Visa fler exempel för en fullständig lista över exempel.
Om du vill köra en pipeline måste du först ange standardberäkningsmålet för att köra pipelinen på.
I fönstret Inställningar till höger om arbetsytan väljer du Välj beräkningsmål.
I dialogrutan som visas väljer du ett befintligt beräkningsmål eller skapar ett nytt. Välj Spara.
Välj Skicka överst på arbetsytan för att skicka ett pipelinejobb.
Beroende på exempelinställningarna för pipeline och beräkning kan det ta lite tid att slutföra jobb. Standardinställningarna för beräkning har en minsta nodstorlek på 0, vilket innebär att designern måste allokera resurser när den är inaktiv. Upprepade pipelinejobb tar mindre tid eftersom beräkningsresurserna redan har allokerats. Dessutom använder designern cachelagrade resultat för varje komponent för att ytterligare förbättra effektiviteten.
När pipelinen har körts kan du granska pipelinen och visa utdata för varje komponent om du vill veta mer. Använd följande steg för att visa komponentutdata:
- Högerklicka på komponenten på arbetsytan vars utdata du vill se.
- Välj Visualisera.
Använd exemplen som utgångspunkt för några av de vanligaste maskininlärningsscenarierna.
Regression
Utforska dessa inbyggda regressionsexempel.
| Exempelrubrik | beskrivning |
|---|---|
| Regression – Förutsägelse av bilpriser (basic) | Förutsäga bilpriser med linjär regression. |
| Regression – Förutsägelse av bilpriser (avancerat) | Förutsäga bilpriser med beslutsskog och ökade regressorer för beslutsträd. Jämför modeller för att hitta den bästa algoritmen. |
Klassificering
Utforska dessa inbyggda klassificeringsexempel. Du kan lära dig mer om exemplen genom att öppna exemplen och visa komponentkommentarna i designern.
| Exempelrubrik | beskrivning |
|---|---|
| Binär klassificering med funktionsval – Inkomstförutsägelse | Förutse inkomster som höga eller låga, med hjälp av ett tvåklassat förbättrat beslutsträd. Använd Pearson-korrelation för att välja funktioner. |
| Binär klassificering med anpassat Python-skript – Kreditriskförutsägelse | Klassificera kreditansökningar som hög eller låg risk. Använd komponenten Kör Python-skript för att vikta dina data. |
| Binär klassificering – Förutsägelse av kundrelation | Förutsäga kundomsättning med hjälp av tvåklassade förstärkta beslutsträd. Använd SMOTE för att prova partiska data. |
| Textklassificering – Wikipedia SP 500-datauppsättning | Klassificera företagstyper från Wikipedia-artiklar med logistisk regression i flera klasser. |
| Klassificering av flera klasser – brevigenkänning | Skapa en ensemble med binära klassificerare för att klassificera skriftliga bokstäver. |
Visuellt innehåll
Utforska dessa inbyggda exempel på visuellt innehåll. Du kan lära dig mer om exemplen genom att öppna exemplen och visa komponentkommentarna i designern.
| Exempelrubrik | beskrivning |
|---|---|
| Bildklassificering med hjälp av DenseNet | Använd komponenter för visuellt innehåll för att skapa en bildklassificeringsmodell baserat på PyTorch DenseNet. |
Rekommenderare
Utforska de här inbyggda rekommendationsexemplen. Du kan lära dig mer om exemplen genom att öppna exemplen och visa komponentkommentarna i designern.
| Exempelrubrik | beskrivning |
|---|---|
| Bred och djupbaserad rekommendation – Förutsägelse av restaurangklassificering | Skapa en restaurangrekommendatormotor från restaurang-/användarfunktioner och betyg. |
| Rekommendation – Tweets för filmklassificering | Skapa en filmrekommendatormotor från film-/användarfunktioner och klassificeringar. |
Verktyg
Läs mer om de exempel som demonstrerar verktyg och funktioner för maskininlärning. Du kan lära dig mer om exemplen genom att öppna exemplen och visa komponentkommentarna i designern.
| Exempelrubrik | beskrivning |
|---|---|
| Binär klassificering med vowpal wabbit-modell – förutsägelse av vuxeninkomst | Vowpal Wabbit är ett maskininlärningssystem som driver gränsen för maskininlärning med tekniker som online, hashning, allreduce, reduces, learning2search, aktiv och interaktiv inlärning. Det här exemplet visar hur du använder Vowpal Wabbit-modellen för att skapa en binär klassificeringsmodell. |
| Använda anpassat R-skript – Förutsägelse av flygfördröjning | Använd anpassat R-skript för att förutsäga om en schemalagd passagerarflygning kommer att försenas med mer än 15 minuter. |
| Korsvalidering för binär klassificering – Förutsägelse av vuxeninkomst | Använd korsvalidering för att skapa en binär klassificerare för vuxeninkomst. |
| Permutationfunktionsprioritet | Använd funktionsvikt för permutation för att beräkna prioritetspoäng för testdatauppsättningen. |
| Justera parametrar för binär klassificering – Förutsägelse av vuxeninkomst | Använd Tune Model Hyperparameters för att hitta optimala hyperparametrar för att skapa en binär klassificerare. |
Datauppsättningar
När du skapar en ny pipeline i Azure Machine Learning Designer inkluderas ett antal exempeldatauppsättningar som standard. Dessa exempeldatauppsättningar används av exempelpipelines på designerns startsida.
Exempeldatauppsättningarna är tillgängliga under kategorin Datamängdsexempel-. Du hittar detta i komponentpaletten till vänster om arbetsytan i designern. Du kan använda någon av dessa datauppsättningar i din egen pipeline genom att dra den till arbetsytan.
| Namn på datauppsättning | Beskrivning av datauppsättning |
|---|---|
| Datauppsättning för binär klassificering av vuxnas censusinkomster | En delmängd av 1994 års folkräkningsdatabas med arbetande vuxna över 16 år med ett justerat inkomstindex på > 100. Användning: Klassificera personer som använder demografi för att förutsäga om en person tjänar över 50 000 om året. Relaterad forskning: Kohavi, R., Becker, B., (1996). UCI Machine Learning-lagringsplats. Irvine, CA: University of California, School of Information and Computer Science |
| Prisdata för bilar (rådata) | Information om bilar efter märke och modell, inklusive priset, funktioner som antalet cylindrar och MPG, samt en försäkringsriskpoäng. Riskpoängen är ursprungligen associerad med autopris. Den justeras sedan för faktisk risk i en process som kallas aktuarier som symbol. Värdet +3 anger att det automatiska värdet är riskabelt och värdet -3 att det förmodligen är säkert. Användning: Förutsäga riskpoängen efter funktioner med hjälp av regression eller multivariatklassificering. Relaterad forskning: Schlimmer, J.C. (1987). UCI Machine Learning-lagringsplats. Irvine, CA: University of California, School of Information and Computer Science. |
| DELADE CRM-appetencyetiketter | Etiketter från förutsägelseutmaningen för KDD Cup 2009-kundrelationer (orange_small_train_appetency.labels). |
| DELADE CRM-omsättningsetiketter | Etiketter från förutsägelseutmaningen för KDD Cup 2009-kundrelationer (orange_small_train_churn.labels). |
| DELAD CRM-datauppsättning | Dessa data kommer från förutsägelseutmaningen för KDD Cup 2009-kundrelationer (orange_small_train.data.zip). Datamängden innehåller 50 000 kunder från det franska telekomföretaget Orange. Varje kund har 230 anonymiserade funktioner, varav 190 är numeriska och 40 är kategoriska. Funktionerna är mycket glesa. |
| DELADE CRM-etiketter | Etiketter från förutsägelseutmaningen för KDD Cup 2009-kundrelationer (orange_large_train_upselling.labels |
| Data om flygförseningar | Prestandadata för passagerarflygning i tid som hämtats från TranStats-datainsamlingen från U.S. Department of Transportation (On-Time). Datamängden omfattar tidsperioden april-oktober 2013. Innan datauppsättningen laddades upp till designern bearbetades den på följande sätt: - Datamängden filtrerades för att endast täcka de 70 mest trafikerade flygplatserna i kontinentala USA - Inställda flyg har märkts som försenade med mer än 15 minuter - Omdirigerade flyg filtrerades bort - Följande kolumner har valts: År, Månad, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| UCI-datauppsättning för tyska kreditkort | Datamängden UCI Statlog (tyska kreditkort) (Statlog+German+Credit+Data) med hjälp av filen german.data. Datauppsättningen klassificerar personer, som beskrivs av en uppsättning attribut, som låg eller hög kreditrisk. Varje exempel representerar en person. Det finns 20 funktioner, både numeriska och kategoriska, och en binär etikett (kreditriskvärdet). Poster med hög kreditrisk har etiketten = 2, poster med låg kreditrisk har etiketten = 1. Kostnaden för att felklassificeras ett lågriskexempel som högt är 1, medan kostnaden för att felklassificeras ett exempel med hög risk som låg är 5. |
| IMDB-filmtitlar | Datamängden innehåller information om filmer som klassificerats i X-tweets: IMDB-film-ID, filmnamn, genre och produktionsår. Det finns 17 000 filmer i datamängden. Datamängden introducerades i tidningen "S. Dooms, T. De Pessemier och L. Martens. MovieTweetings: en filmklassificeringsdatauppsättning som samlats in från Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Filmklassificeringar | Datamängden är en utökad version av datauppsättningen Movie Tweetings. Datamängden har 170 000 betyg för filmer, extraherade från välstrukturerade tweets på X. Varje instans representerar en tweet och är en tupplar: användar-ID, IMDB-film-ID, omdöme, tidsstämpel, antal favoriter för den här tweeten och antalet retweets för den här tweeten. Datauppsättningen gjordes tillgänglig av A. Said, S. Dooms, B. Loni och D. Tikk för Recommender Systems Challenge 2014. |
| Väderdatauppsättning | Landbaserade väderobservationer varje timme från NOAA (sammanfogade data från 201304 till 201310). Väderdata omfattar observationer från flygplatsens väderstationer som täcker tidsperioden april-oktober 2013. Innan datauppsättningen laddades upp till designern bearbetades den på följande sätt: - Väderstations-ID:n mappades till motsvarande flygplats-ID:n - Väderstationer som inte är associerade med de 70 mest trafikerade flygplatserna filtrerades bort - Kolumnen Datum delades upp i separata kolumner för år, månad och dag - Följande kolumner har valts: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Synlighet, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500-datauppsättning | Data härleds från Wikipedia (https://www.wikipedia.org/) baserat på artiklar från varje S&P 500-företag som lagras som XML-data. Innan datauppsättningen laddades upp till designern bearbetades den på följande sätt: – Extrahera textinnehåll för varje specifikt företag – Ta bort wiki-formatering – Ta bort icke-alfanumeriska tecken – Konvertera all text till gemener – Kända företagskategorier har lagts till Observera att det inte gick att hitta en artikel för vissa företag, så antalet poster är mindre än 500. |
| Funktionsdata för restaurang | En uppsättning metadata om restauranger och deras funktioner, till exempel mattyp, matstil och plats. Användning: Använd den här datamängden, i kombination med de andra två restaurangdatauppsättningarna, för att träna och testa ett rekommenderande system. Relaterad forskning: Bache, K. och Lichman, M. (2013). UCI Machine Learning-lagringsplats. Irvine, CA: University of California, School of Information and Computer Science. |
| Restaurangklassificeringar | Innehåller omdömen från användare till restauranger i en skala från 0 till 2. Användning: Använd den här datamängden, i kombination med de andra två restaurangdatauppsättningarna, för att träna och testa ett rekommenderande system. Relaterad forskning: Bache, K. och Lichman, M. (2013). UCI Machine Learning-lagringsplats. Irvine, CA: University of California, School of Information and Computer Science. |
| Kunddata för restaurang | En uppsättning metadata om kunder, inklusive demografi och inställningar. Användning: Använd den här datamängden, i kombination med de andra två restaurangdatauppsättningarna, för att träna och testa ett rekommenderande system. Relaterad forskning: Bache, K. och Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Rensa resurser
Viktigt!
Du kan använda de resurser som du skapade som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Ta bort allt
Om du inte planerar att använda något som du har skapat tar du bort hela resursgruppen så att du inte debiteras några avgifter.
I Azure Portal väljer du Resursgrupper till vänster i fönstret.
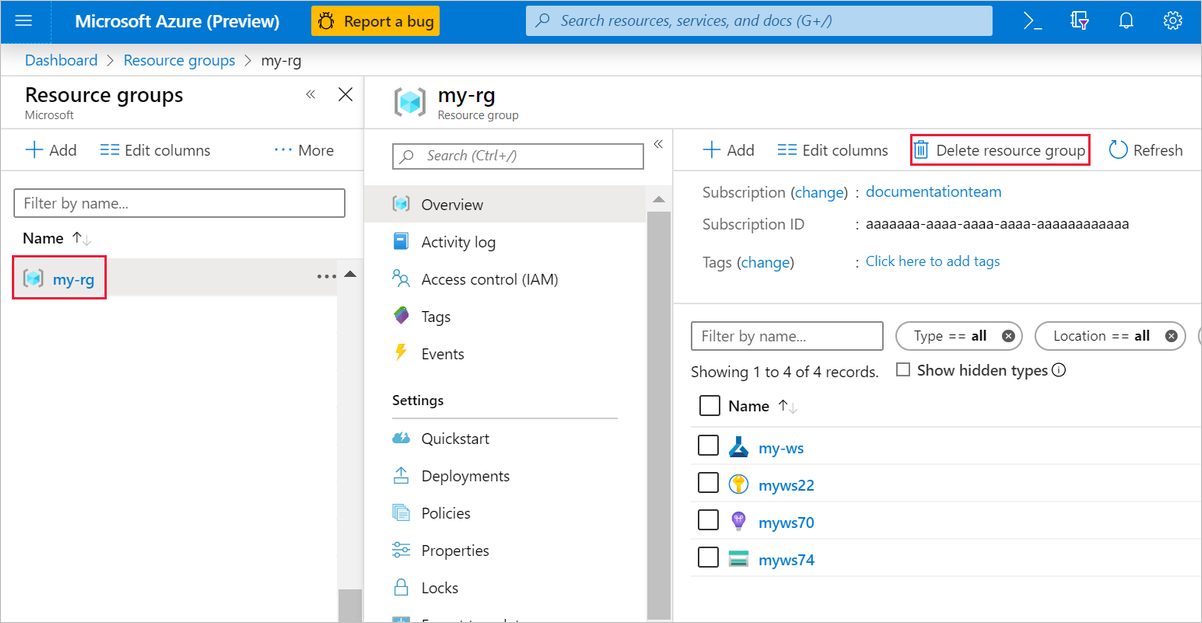
I listan väljer du den resursgrupp som du skapade.
Välj Ta bort resursgrupp.
Om du tar bort resursgruppen tas även alla resurser som du skapade i designern bort.
Ta bort enskilda tillgångar
I designern där du skapade experimentet tar du bort enskilda tillgångar genom att välja dem och sedan välja knappen Ta bort .
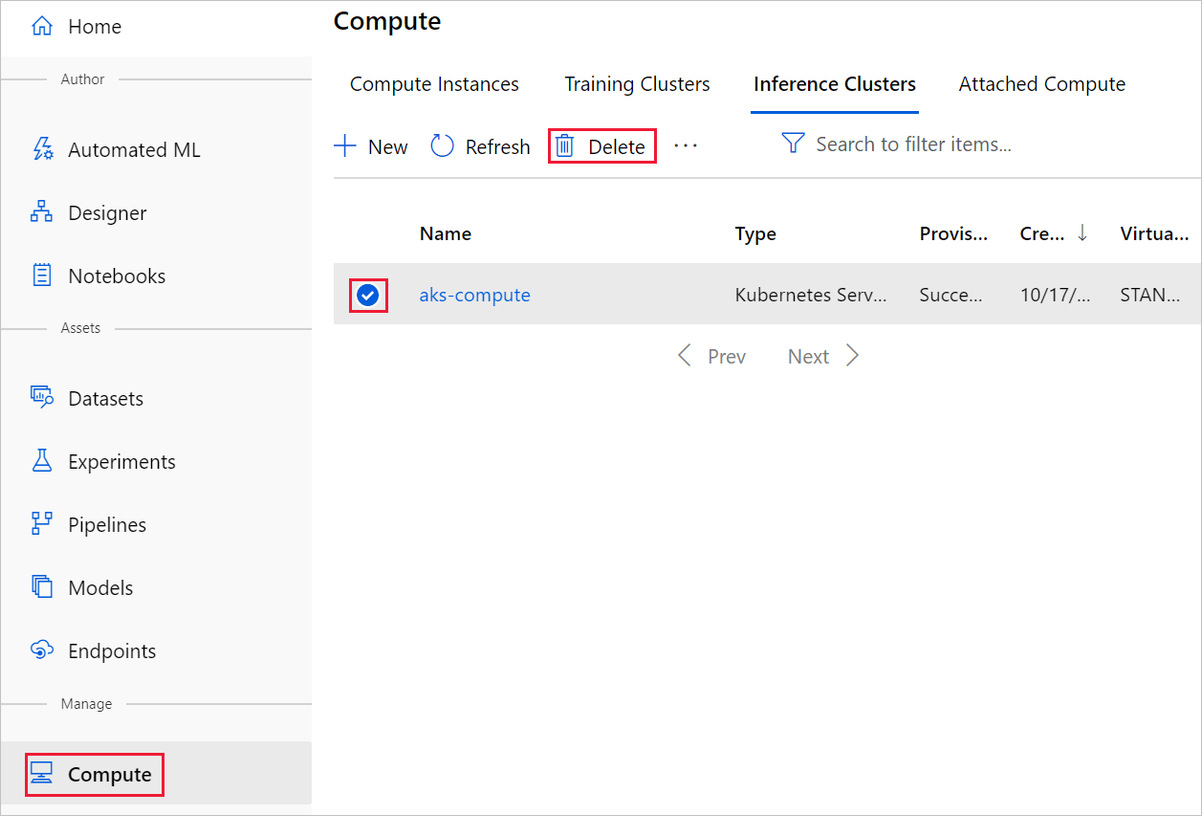
Beräkningsmålet som du skapade här skalar automatiskt till noll noder när det inte används. Den här åtgärden vidtas för att minimera avgifterna. Om du vill ta bort beräkningsmålet gör du följande:
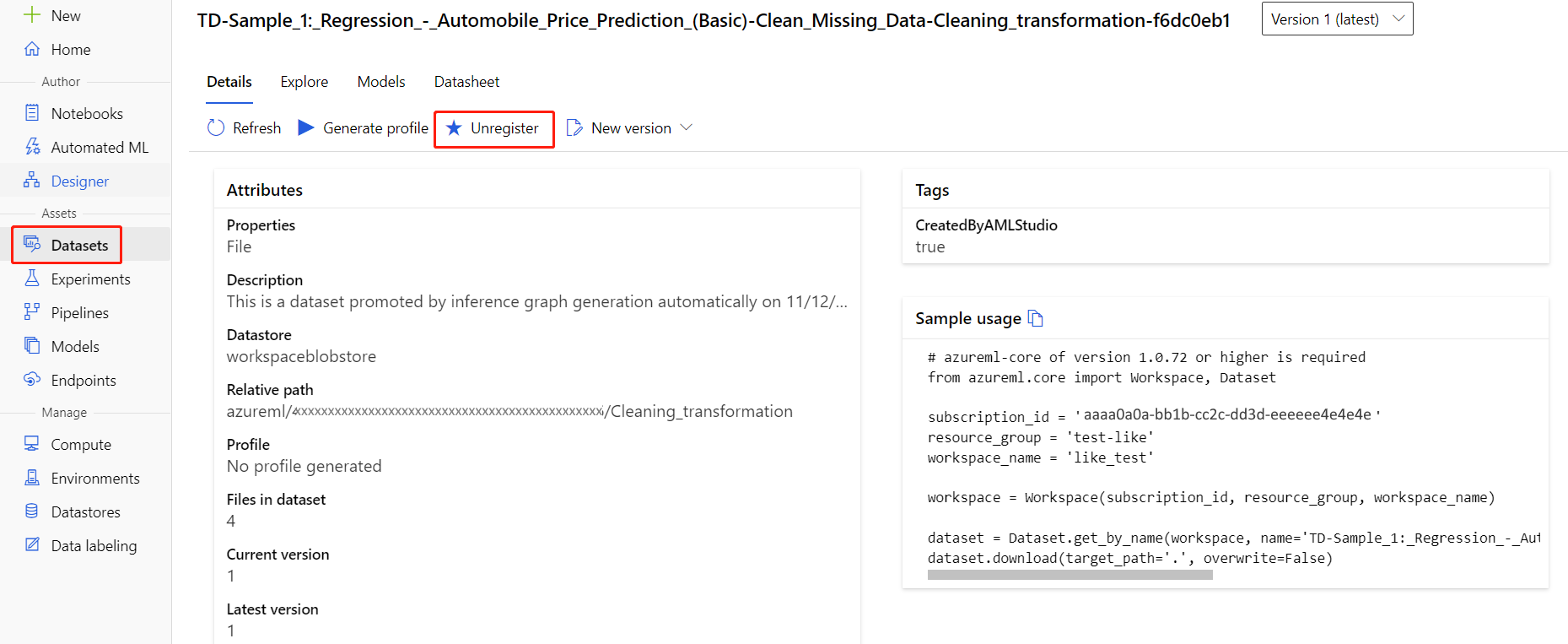
Du kan avregistrera datauppsättningar från din arbetsyta genom att välja varje datauppsättning och välja Avregistrera.
Om du vill ta bort en datauppsättning går du till lagringskontot med hjälp av Azure Portal eller Azure Storage Explorer och tar bort dessa tillgångar manuellt.
Nästa steg
Lär dig grunderna i förutsägelseanalys och maskininlärning med Självstudie: Förutsäga bilpriser med designern