Självstudie: Träna en klassificeringsmodell utan kod för AutoML i Azure Machine Learning-studio
I den här självstudien får du lära dig hur du tränar en klassificeringsmodell med automatisk maskininlärning utan kod (AutoML) med Hjälp av Azure Machine Learning i Azure Machine Learning-studio. Den här klassificeringsmodellen förutsäger om en kund prenumererar på en fast deposition hos ett finansinstitut.
Med automatiserad ML kan du automatisera tidsintensiva uppgifter. Automatiserad maskininlärning itererar snabbt över många kombinationer av algoritmer och hyperparametrar som hjälper dig att hitta den bästa modellen baserat på ett lyckat mått som du väljer.
Du skriver ingen kod i den här självstudien. Du använder studiogränssnittet för att träna. Du lär dig hur du utför följande uppgifter:
- Skapa en Azure Machine Learning-arbetsyta
- Köra ett automatiserat maskininlärningsexperiment
- Utforska modellinformation
- Distribuera den rekommenderade modellen
Förutsättningar
En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto.
Ladda ned bankmarketing_train.csv datafilen. Kolumnen y anger om en kund prenumererar på en fast deposition, som senare identifieras som målkolumnen för förutsägelser i den här självstudien.
Kommentar
Den här bankmarknadsföringsdatauppsättningen görs tillgänglig under creative commons-licensen (CCO: Public Domain). Alla rättigheter i det enskilda innehållet i databasen licensieras under licensen för databasinnehåll och är tillgängliga på Kaggle. Den här datamängden var ursprungligen tillgänglig i UCI Machine Learning Database.
[Moro et al., 2014] S. Moro, P. Cortez och P. Rita. En datadriven metod för att förutsäga hur framgångsrik banktelemarketing är. Beslutsstödsystem, Elsevier, 62:22-31, juni 2014.
Skapa en arbetsyta
En Azure Machine Learning-arbetsyta är en grundläggande resurs i molnet som du använder för att experimentera, träna och distribuera maskininlärningsmodeller. Den kopplar din Azure-prenumeration och resursgrupp till ett objekt som är enkelt att använda i tjänsten.
Slutför följande steg för att skapa en arbetsyta och fortsätt självstudien.
Logga in på Azure Machine Learning-studio.
Välj Skapa arbetsyta.
Ange följande information för att konfigurera den nya arbetsytan:
Fält beskrivning Namn på arbetsyta Ange ett unikt namn som identifierar din arbetsyta. Namn måste vara unika i resursgruppen. Använd ett namn som är enkelt att återkalla och skilja från arbetsytor som skapats av andra. Arbetsytans namn är skiftlägeskänsligt. Prenumeration Välj den Azure-prenumeration som du vill använda. Resursgrupp Använd en befintlig resursgrupp i din prenumeration eller ange ett namn för att skapa en ny resursgrupp. En resursgrupp innehåller relaterade resurser för en Azure-lösning. Du behöver rollen deltagare eller ägare för att kunna använda en befintlig resursgrupp. Mer information finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta. Region Välj den Azure-region som är närmast dina användare och dataresurserna för att skapa din arbetsyta. Välj Skapa för att skapa arbetsytan.
Mer information om Azure-resurser finns i Skapa arbetsytan.
För andra sätt att skapa en arbetsyta i Azure, hantera Azure Machine Learning-arbetsytor i portalen eller med Python SDK (v2).
Skapa ett automatiserat maskininlärningsjobb
Slutför följande experimentuppsättning och kör steg med hjälp av Azure Machine Learning-studio på https://ml.azure.com. Machine Learning Studio är ett konsoliderat webbgränssnitt som innehåller maskininlärningsverktyg för att utföra datavetenskapsscenarier för datavetenskapsutövare på alla kunskapsnivåer. Studio stöds inte i Internet Explorer-webbläsare.
Välj din prenumeration och den arbetsyta som du skapade.
I navigeringsfönstret väljer du Redigera automatiserad>ML.
Eftersom den här självstudien är ditt första automatiserade ML-experiment visas en tom lista och länkar till dokumentationen.
Välj Nytt automatiserat ML-jobb.
I Träningsmetod väljer du Träna automatiskt och väljer sedan Börja konfigurera jobb.
I Grundläggande inställningar väljer du Skapa ny och anger sedan my-1st-automl-experiment för Experimentnamn.
Välj Nästa för att läsa in datauppsättningen.

Skapa och läsa in en datauppsättning som en datatillgång
Innan du konfigurerar experimentet laddar du upp datafilen till din arbetsyta i form av en Azure Machine Learning-datatillgång. I den här självstudien kan du se en datatillgång som din datauppsättning för det automatiserade ML-jobbet. På så sätt kan du se till att dina data är korrekt formaterade för experimentet.
I Aktivitetstyp och data väljer du Klassificering för Välj aktivitetstyp.
Under Välj data väljer du Skapa.
I formuläret Datatyp ger du datatillgången ett namn och anger en valfri beskrivning.
För Typ väljer du Tabell. Det automatiserade ML-gränssnittet stöder för närvarande endast TabularDatasets.
Välj Nästa.
I formuläret Datakälla väljer du Från lokala filer. Välj Nästa.
I Mållagringstyp väljer du det standarddatalager som konfigurerades automatiskt när du skapade arbetsytan: workspaceblobstore. Du laddar upp datafilen till den här platsen för att göra den tillgänglig för din arbetsyta.
Välj Nästa.
I Val av fil eller mapp väljer du Ladda upp filer eller mapp>Ladda upp filer.
Välj filen bankmarketing_train.csv på den lokala datorn. Du laddade ned den här filen som en förutsättning.
Välj Nästa.
När uppladdningen är klar fylls dataförhandsgranskningsområdet i baserat på filtypen.
Granska värdena för dina data i formuläret Inställningar. Välj sedan Nästa.
Fält beskrivning Värde för självstudie File format Definierar layouten och typen av data som lagras i en fil. Avgränsad Delimiter Ett eller flera tecken för att ange gränsen mellan separata, oberoende regioner i oformaterad text eller andra dataströmmar. Comma Encoding Identifierar vilken bit till teckenschematabell som ska användas för att läsa datauppsättningen. UTF-8 Kolumnrubriker Anger hur sidhuvudena i datauppsättningen, om några, behandlas. Alla filer har samma rubriker Hoppa över rader Anger hur många, om några, rader som hoppas över i datauppsättningen. Ingen Schemaformuläret möjliggör ytterligare konfiguration av dina data för det här experimentet. I det här exemplet väljer du växlaren för day_of_week för att inte inkludera den. Välj Nästa.
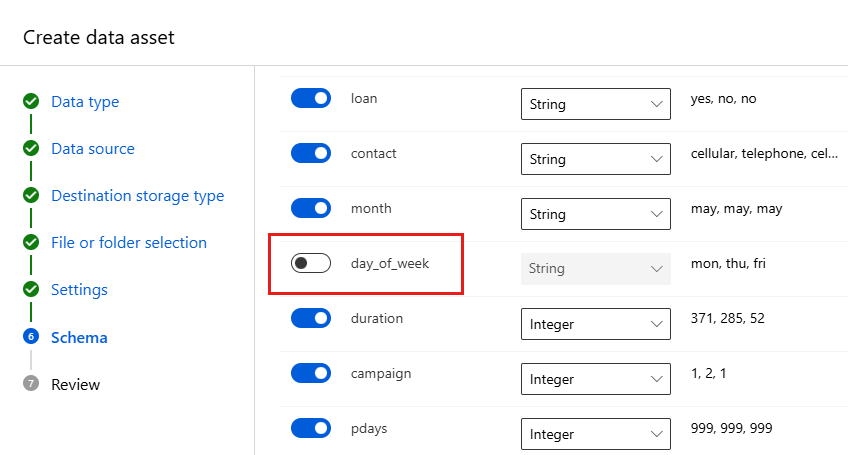
I formuläret Granska verifierar du informationen och väljer sedan Skapa.
Välj din datauppsättning i listan.
Granska data genom att välja datatillgången och titta på förhandsgranskningsfliken. Kontrollera att den inte innehåller day_of_week och välj Stäng.
Välj Nästa för att fortsätta till aktivitetsinställningarna.
Konfigurera jobb
När du har läst in och konfigurerat dina data kan du konfigurera experimentet. Den här konfigurationen innehåller experimentdesignuppgifter som att välja storleken på beräkningsmiljön och ange vilken kolumn du vill förutsäga.
Fyll i formuläret Aktivitetsinställningar på följande sätt:
Välj y (Sträng) som målkolumn, vilket är vad du vill förutsäga. Den här kolumnen anger om klienten prenumererar på en terminsättning eller inte.
Välj Visa ytterligare konfigurationsinställningar och fyll i fälten enligt följande. De här inställningarna är till för att bättre kontrollera träningsjobbet. Annars tillämpas standardvärden baserat på experimentval och data.
Ytterligare konfigurationer beskrivning Värde för självstudie Primärt mått Utvärderingsmått som används för att mäta maskininlärningsalgoritmen. AUCWeighted Förklara bästa modell Visar automatiskt förklaring på den bästa modellen som skapats av automatiserad ML. Aktivera Blockerade modeller Algoritmer som du vill undanta från träningsjobbet Ingen Välj Spara.
Under Verifiera och testa:
- Som Valideringstyp väljer du k-fold korsvalidering.
- För Antal korsvalideringar väljer du 2.
Välj Nästa.
Välj beräkningskluster som beräkningstyp.
Ett beräkningsmål är en lokal eller molnbaserad resursmiljö som används för att köra träningsskriptet eller vara värd för tjänstdistributionen. I det här experimentet kan du antingen prova en molnbaserad serverlös beräkning (förhandsversion) eller skapa en egen molnbaserad beräkning.
Kommentar
Om du vill använda serverlös beräkning aktiverar du förhandsgranskningsfunktionen, väljer Serverlös och hoppar över den här proceduren.
Om du vill skapa ett eget beräkningsmål går du till Välj beräkningstyp och väljer Beräkningskluster för att konfigurera beräkningsmålet.
Fyll i formuläret Virtuell dator för att konfigurera din beräkning. Välj Ny.
Fält beskrivning Värde för självstudie Plats Din region som du vill köra datorn från Västra USA 2 Nivå för virtuell dator Välj vilken prioritet experimentet ska ha Dedikerad Typ av virtuell dator Välj den virtuella datortypen för din beräkning. CPU (central bearbetningsenhet) Storlek för virtuell dator Välj storleken på den virtuella datorn för din beräkning. En lista över rekommenderade storlekar tillhandahålls baserat på dina data och experimenttyp. Standard_DS12_V2 Välj Nästa för att gå till formuläret Avancerade inställningar .
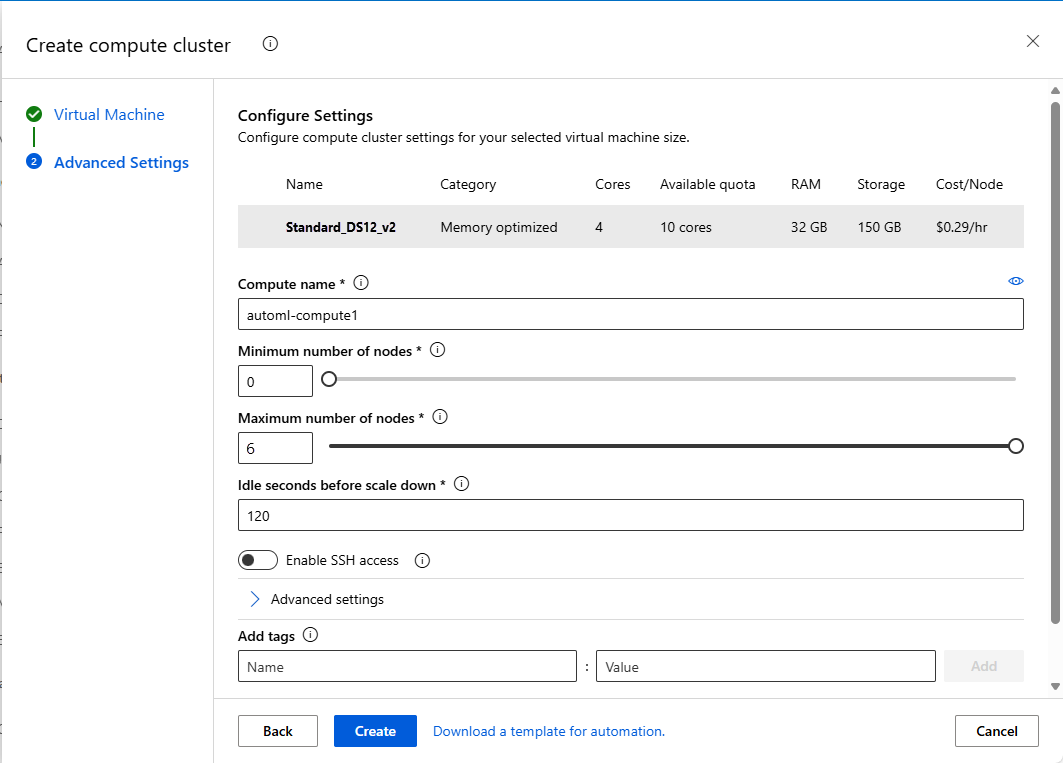
Fält beskrivning Värde för självstudie Namn på beräkning Ett unikt namn som identifierar din beräkningskontext. automl-compute Min/Max-noder Om du vill profilera data måste du ange 1 eller flera noder. Minsta noder: 1
Maximalt antal noder: 6Inaktiva sekunder innan nedskalning Inaktiv tid innan klustret skalas ned automatiskt till minsta antal noder. 120 (standard) Avancerade inställningar Inställningar för att konfigurera och auktorisera ett virtuellt nätverk för experimentet. Ingen Välj Skapa.
Det kan ta några minuter att skapa en beräkning.
När du har skapat väljer du ditt nya beräkningsmål i listan. Välj Nästa.
Välj Skicka träningsjobb för att köra experimentet. Skärmen Översikt öppnas med Status överst när experimentförberedelsen börjar. Den här statusen uppdateras när experimentet fortskrider. Meddelanden visas också i studion för att informera dig om statusen för experimentet.

Viktigt!
Det tar 10–15 minuter att förbereda experimentkörningen. När du har kört tar det 2–3 minuter till för varje iteration.
I produktion skulle du förmodligen gå iväg en stund. Men i den här självstudien kan du börja utforska de testade algoritmerna på fliken Modeller när de slutförs medan de andra fortsätter att köras.
Utforska modeller
Gå till fliken Modeller + underordnade jobb för att se vilka algoritmer (modeller) som testas. Som standard beställer jobbet modellerna efter måttpoäng när de slutförs. I den här självstudien finns den modell som får högst poäng baserat på det valda måttet AUCWeighted överst i listan.
Medan du väntar på att alla experimentmodeller ska slutföras väljer du algoritmnamnet för en slutförd modell för att utforska dess prestandainformation. Välj flikarna Översikt och Mått för information om jobbet.
Följande animering visar den valda modellens egenskaper, mått och prestandadiagram.

Visa modellförklaringar
Medan du väntar på att modellerna ska slutföras kan du också ta en titt på modellförklaringar och se vilka datafunktioner (råa eller konstruerade) som påverkade en viss modells förutsägelser.
Dessa modellförklaringar kan genereras på begäran. Instrumentpanelen för modellförklaringar som är en del av fliken Förklaringar (förhandsversion) sammanfattar dessa förklaringar.
Så här genererar du modellförklaringar:
I navigeringslänkarna överst på sidan väljer du jobbnamnet för att gå tillbaka till skärmen Modeller .
Välj fliken Modeller + underordnade jobb .
I den här självstudien väljer du den första MaxAbsScaler, LightGBM-modellen .
Välj Förklara modell. Till höger visas fönstret Förklara modell .
Välj din beräkningstyp och välj sedan den instans eller det kluster: automl-compute som du skapade tidigare. Den här beräkningen startar ett underordnat jobb för att generera modellförklaringarna.
Välj Skapa. Ett grönt meddelande visas.
Kommentar
Det tar cirka 2–5 minuter att slutföra förklaringsjobbet.
Välj Förklaringar (förhandsversion). Den här fliken fylls i när förklaringskörningen har slutförts.
Expandera fönstret till vänster. Under Funktioner väljer du raden som säger rå.
Välj fliken Mängdfunktionsvikt . Det här diagrammet visar vilka datafunktioner som påverkade förutsägelserna för den valda modellen.
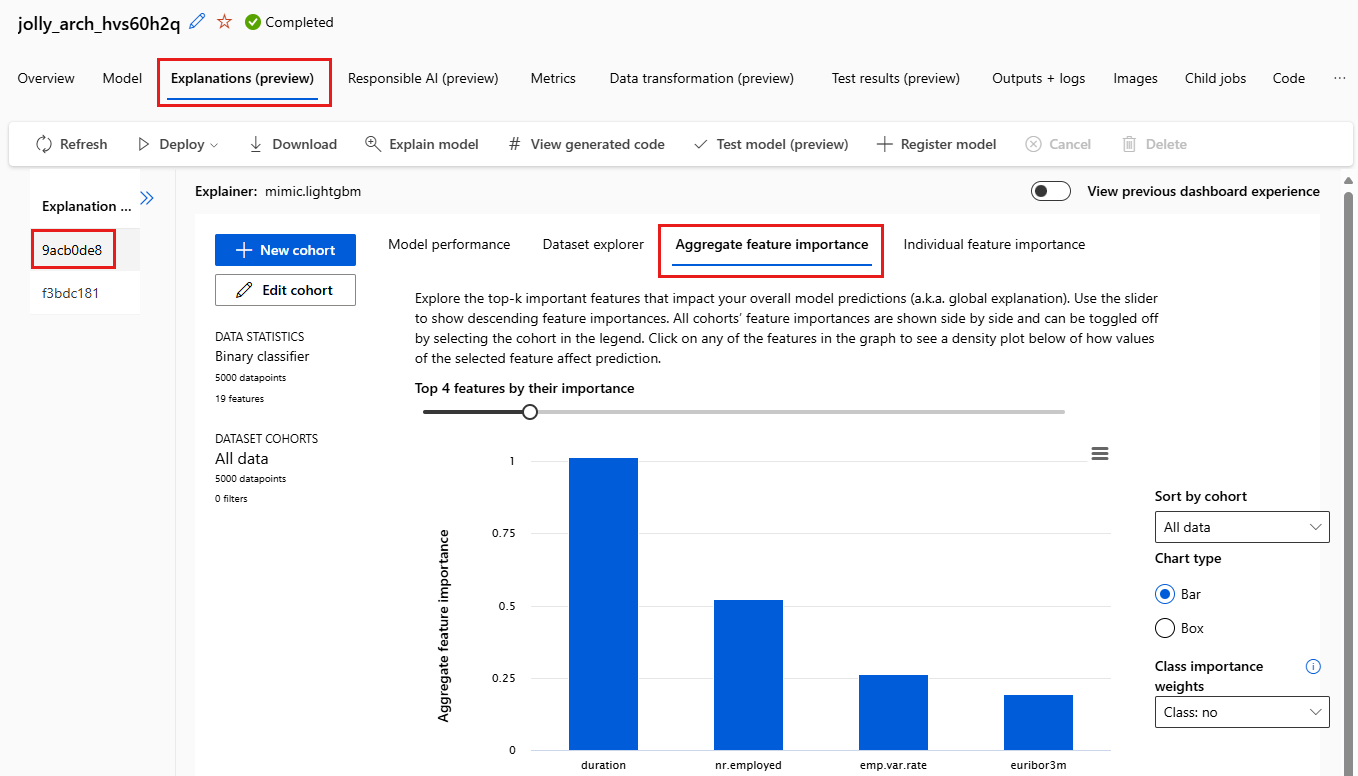
I det här exemplet verkar varaktigheten ha störst inverkan på förutsägelserna för den här modellen.

Distribuera den bästa modellen
Med det automatiserade maskininlärningsgränssnittet kan du distribuera den bästa modellen som en webbtjänst. Distribution är integreringen av modellen så att den kan förutsäga nya data och identifiera potentiella affärsmöjligheter. I det här experimentet innebär distributionen till en webbtjänst att finansinstitutet nu har en iterativ och skalbar webblösning för att identifiera potentiella kunder med fast tidsinsättning.
Kontrollera om experimentkörningen är klar. Det gör du genom att gå tillbaka till den överordnade jobbsidan genom att välja jobbnamnet överst på skärmen. Statusen Slutförd visas längst upp till vänster på skärmen.
När experimentkörningen är klar fylls sidan Information i med avsnittet Bästa modellsammanfattning . I det här experimentsammanhanget anses VotingEnsemble vara den bästa modellen, baserat på måttet AUCWeighted .
Distribuera den här modellen. Distributionen tar cirka 20 minuter att slutföra. Distributionsprocessen innebär flera steg, inklusive registrering av modellen, generering av resurser och konfiguration av dem för webbtjänsten.
Välj VotingEnsemble för att öppna den modellspecifika sidan.
Välj Distribuera>webbtjänst.
Fyll i fönstret Distribuera en modell på följande sätt:
Fält Värde Name my-automl-deploy beskrivning Min första automatiserade distribution av maskininlärningsexperiment Typ av beräkning Välj Azure Container Instance Aktivera autentisering Inaktivera. Använda anpassade distributionstillgångar Inaktivera. Tillåter att standarddrivrutinsfilen (bedömningsskriptet) och miljöfilen genereras automatiskt. I det här exemplet använder du standardvärdena i menyn Avancerat .
Välj distribuera.
Ett grönt meddelande visas överst på skärmen Jobb . I fönstret Modellsammanfattning visas ett statusmeddelande under Distribuera status. Välj Uppdatera regelbundet för att kontrollera distributionsstatusen.
Du har en fungerande webbtjänst som genererar förutsägelser.
Gå vidare till relaterat innehåll för att lära dig mer om hur du använder din nya webbtjänst och testa dina förutsägelser med hjälp av Power BI som är inbyggt i Azure Machine Learning-stöd.
Rensa resurser
Distributionsfiler är större än data- och experimentfiler, så de kostar mer att lagra. Om du vill behålla arbetsytan och experimentfilerna tar du bara bort distributionsfilerna för att minimera kostnaderna för ditt konto. Om du inte planerar att använda någon av filerna tar du bort hela resursgruppen.
Ta bort distributionsinstansen
Ta bort bara distributionsinstansen från Azure Machine Learning på https://ml.azure.com/.
Gå till Azure Machine Learning. Gå till din arbetsyta och under fönstret Tillgångar väljer du Slutpunkter.
Välj den distribution som du vill ta bort och välj Ta bort.
Välj Fortsätt.
Ta bort resursgruppen
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
Ange resursgruppsnamnet. Välj sedan ta bort.
Relaterat innehåll
I den här självstudien om automatiserad maskininlärning använde du Azure Machine Learnings automatiserade ML-gränssnitt för att skapa och distribuera en klassificeringsmodell. Mer information och nästa steg finns i följande resurser:
- Läs mer om automatiserad maskininlärning.
- Läs mer om klassificeringsmått och diagram: Artikeln Utvärdera automatiserade maskininlärningsexperimentresultat .
- Läs mer om hur du konfigurerar AutoML för NLP.
Prova även automatiserad maskininlärning för dessa andra modelltyper:
- Ett exempel på prognostisering utan kod finns i Självstudie: Prognostisera efterfrågan utan kod automatiserad maskininlärning i Azure Machine Learning-studio.
- Ett kodexempel på en objektidentifieringsmodell finns i Självstudie: Träna en objektidentifieringsmodell med AutoML och Python.