Konfiguration av hög tillgänglighet i SUSE med hjälp av fäktningsenheten
I den här artikeln går vi igenom stegen för att konfigurera hög tillgänglighet (HA) i STORA HANA-instanser på SUSE-operativsystemet med hjälp av fäktningsenheten.
Anteckning
Den här guiden härleds från att ha testat konfigurationen i miljön stora Microsoft HANA-instanser. Microsoft Service Management-teamet för stora HANA-instanser stöder inte operativsystemet. Om du vill felsöka eller förtydliga operativsystemets lager kontaktar du SUSE.
Microsoft Service Management-teamet har konfigurerat och har fullt stöd för fäktningsenheten. Det kan hjälpa dig att felsöka problem med stängselenheter.
Förutsättningar
Om du vill konfigurera hög tillgänglighet med hjälp av SUSE-klustring måste du:
- Etablera stora HANA-instanser.
- Installera och registrera operativsystemet med de senaste korrigeringarna.
- Anslut HANA Large Instance-servrar till SMT-servern för att hämta korrigeringar och paket.
- Konfigurera NTP-tidsserver (Network Time Protocol).
- Läs och förstå den senaste SUSE-dokumentationen om konfiguration av hög tillgänglighet.
Konfigurationsinformation
I den här guiden används följande konfiguration:
- Operativsystem: SLES 12 SP1 för SAP
- STORA HANA-instanser: 2xS192 (fyra sockets, 2 TB)
- HANA-version: HANA 2.0 SP1
- Servernamn: sapprdhdb95 (node1) och sapprdhdb96 (node2)
- Fäktningsenhet: iSCSI-baserad
- NTP på en av noderna för stora HANA-instanser
När du konfigurerar STORA HANA-instanser med HANA-systemreplikering kan du begära att Microsoft Service Management-teamet konfigurerar fäktningsenheten. Gör detta vid tidpunkten för etableringen.
Om du är en befintlig kund med STORA HANA-instanser som redan har etablerats kan du fortfarande konfigurera fäktningsenheten. Ange följande information till Microsoft Service Management-teamet i tjänstbegäransformuläret (SRF). Du kan hämta SRF via den tekniska kontohanteraren eller din Microsoft-kontakt för registrering av stora HANA-instanser.
- Servernamn och serverns IP-adress (till exempel myhanaserver1 och 10.35.0.1)
- Plats (till exempel USA, östra)
- Kundnamn (till exempel Microsoft)
- HANA-systemidentifierare (SID) (till exempel H11)
När fäktningsenheten har konfigurerats ger Microsoft Service Management-teamet dig SBD-namnet och IP-adressen för iSCSI-lagringen. Du kan använda den här informationen för att konfigurera fäktningskonfigurationen.
Följ stegen i följande avsnitt för att konfigurera HA med hjälp av fäktningsenheten.
Identifiera SBD-enheten
Anteckning
Det här avsnittet gäller endast för befintliga kunder. Om du är en ny kund ger Microsoft Service Management-teamet dig SBD-enhetsnamnet, så hoppa över det här avsnittet.
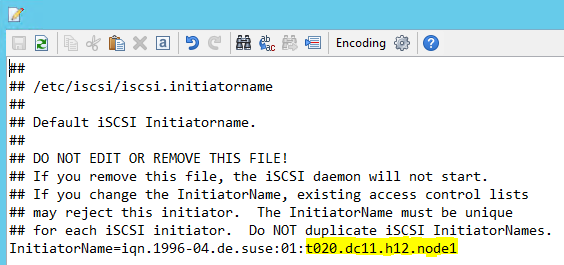
Ändra /etc/iscsi/initiatorname.isci till:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft Service Management tillhandahåller den här strängen. Ändra filen på båda noderna. Nodnumret är dock olika på varje nod.
Ändra /etc/iscsi/iscsid.conf genom att ange
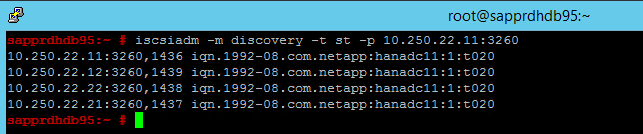
node.session.timeo.replacement_timeout=5ochnode.startup = automatic. Ändra filen på båda noderna.Kör följande identifieringskommando på båda noderna.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Resultaten visar fyra sessioner.
Kör följande kommando på båda noderna för att logga in på iSCSI-enheten.
iscsiadm -m node -lResultaten visar fyra sessioner.

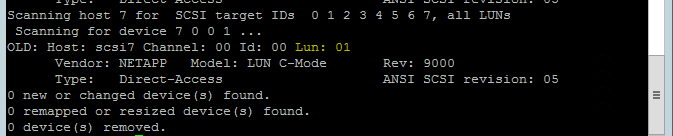
Använd följande kommando för att köra rescan-scsi-bus.sh genomsöka skriptet igen. Det här skriptet visar de nya diskar som skapats åt dig. Kör den på båda noderna.
rescan-scsi-bus.shResultatet bör visa ett LUN-tal som är större än noll (till exempel: 1, 2 och så vidare).
Hämta enhetsnamnet genom att köra följande kommando på båda noderna.
fdisk –lI resultatet väljer du enheten med storleken 178 MiB.

Initiera SBD-enheten
Använd följande kommando för att initiera SBD-enheten på båda noderna.
sbd -d <SBD Device Name> create
Använd följande kommando på båda noderna för att kontrollera vad som har skrivits till enheten.
sbd -d <SBD Device Name> dump
Konfigurera SUSE HA-klustret
Använd följande kommando för att kontrollera om ha_sles- och SAPHanaSR-doc-mönster är installerade på båda noderna. Installera dem om de inte är installerade.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Konfigurera klustret med hjälp av kommandot
ha-cluster-initeller yast2-guiden. I det här exemplet använder vi yast2-guiden. Gör det här steget endast på den primära noden.Gå till yast2-kluster>med hög tillgänglighet>.
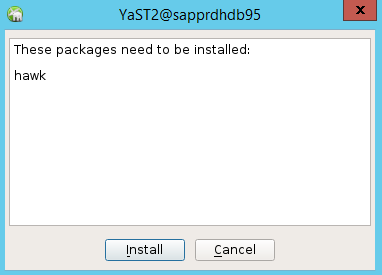
I dialogrutan som visas om hawk-paketinstallationen väljer du Avbryt eftersom halk2-paketet redan är installerat.
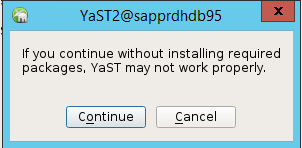
I dialogrutan som visas om att fortsätta väljer du Fortsätt.
Det förväntade värdet är antalet distribuerade noder (i det här fallet 2). Välj Nästa.
Lägg till nodnamn och välj sedan Lägg till föreslagna filer.
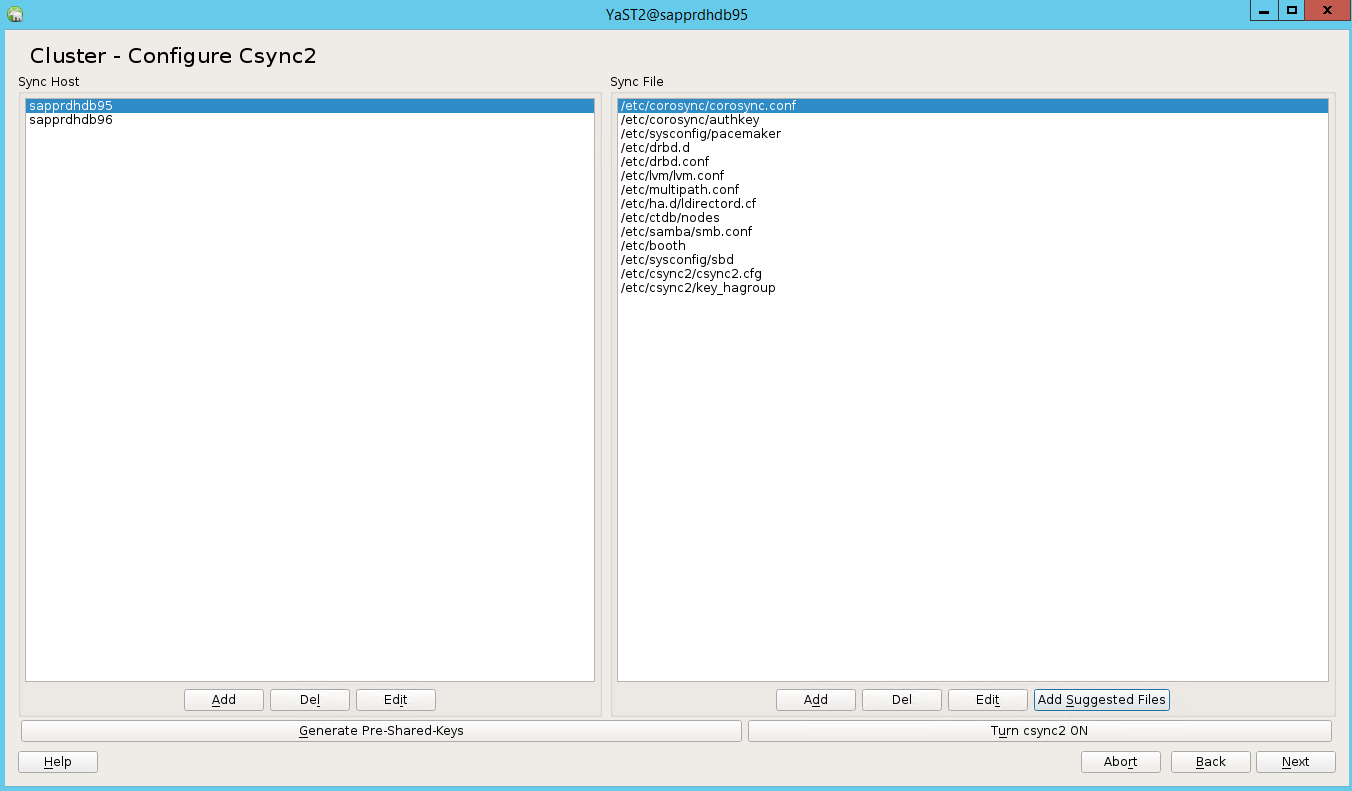
Välj Aktivera csync2.
Välj Generera i förväg delade nycklar.
I popup-meddelandet som visas väljer du OK.
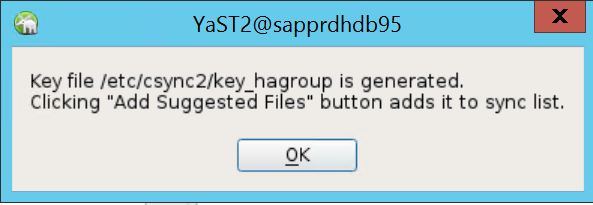
Autentiseringen utförs med hjälp av IP-adresser och i förväg delade nycklar i Csync2. Nyckelfilen genereras med
csync2 -k /etc/csync2/key_hagroup.Kopiera filen key_hagroup till alla medlemmar i klustret manuellt när den har skapats. Se till att kopiera filen från node1 till node2. Välj sedan Nästa.
I standardalternativet var startav. Ändra den till På så att pacemakertjänsten startas vid start. Du kan göra valet baserat på dina konfigurationskrav.
Välj Nästa så är klusterkonfigurationen klar.
Konfigurera softdog-vakthunden
Lägg till följande rad i /etc/init.d/boot.local på båda noderna.
modprobe softdog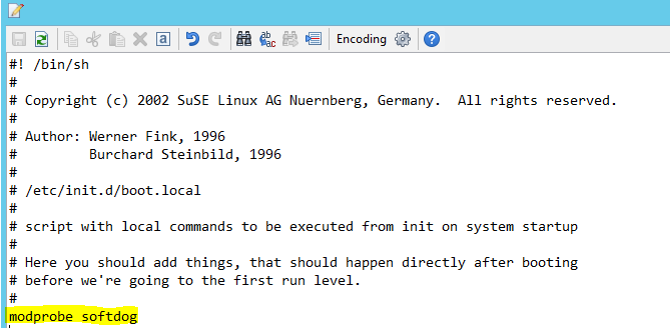
Använd följande kommando för att uppdatera filen /etc/sysconfig/sbd på båda noderna.
SBD_DEVICE="<SBD Device Name>"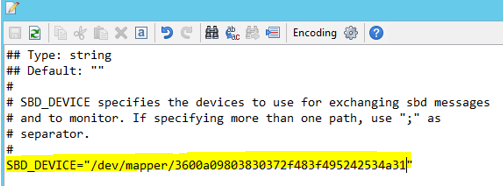
Läs in kernelmodulen på båda noderna genom att köra följande kommando.
modprobe softdog
Använd följande kommando för att säkerställa att softdog körs på båda noderna.
lsmod | grep dog
Använd följande kommando för att starta SBD-enheten på båda noderna.
/usr/share/sbd/sbd.sh start
Använd följande kommando för att testa SBD-daemonen på båda noderna.
sbd -d <SBD Device Name> listResultatet visar två poster efter konfigurationen på båda noderna.

Skicka följande testmeddelande till en av dina noder.
sbd -d <SBD Device Name> message <node2> <message>På den andra noden (node2) använder du följande kommando för att kontrollera meddelandestatusen.
sbd -d <SBD Device Name> list
Om du vill implementera SBD-konfigurationen uppdaterar du filen /etc/sysconfig/sbd på följande sätt på båda noderna.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Använd följande kommando för att starta pacemakertjänsten på den primära noden (node1).
systemctl start pacemaker
Om pacemakertjänsten misslyckas kan du läsa avsnittet Scenario 5: Pacemakertjänsten misslyckas senare i den här artikeln.
Anslut noden till klustret
Kör följande kommando på node2 för att låta noden ansluta till klustret.
ha-cluster-join
Om du får ett fel när du ansluter till klustret kan du läsa avsnittet Scenario 6: Node2 kan inte ansluta till klustret senare i den här artikeln.
Verifiera klustret
Använd följande kommandon för att kontrollera och starta klustret för första gången på båda noderna.
systemctl status pacemaker systemctl start pacemaker
Kör följande kommando för att se till att båda noderna är online. Du kan köra den på någon av noderna i klustret.
crm_mon
Du kan också logga in på hawk för att kontrollera klusterstatusen:
https://\<node IP>:7630. Standardanvändaren är hacluster och lösenordet är linux. Om det behövs kan du ändra lösenordet med hjälppasswdav kommandot .
Konfigurera klusteregenskaper och resurser
I det här avsnittet beskrivs stegen för att konfigurera klusterresurserna. I det här exemplet konfigurerar du följande resurser. Du kan konfigurera resten (om det behövs) genom att referera till SUSE HA-guiden.
- Bootstrap för kluster
- Fäktningsenhet
- Virtuell IP-adress
Utför endast konfigurationen på den primära noden .
Skapa bootstrap-filen för klustret och konfigurera den genom att lägga till följande text.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Använd följande kommando för att lägga till konfigurationen i klustret.
crm configure load update crm-bs.txt
Konfigurera stängselenheten genom att lägga till resursen, skapa filen och lägga till text på följande sätt.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Använd följande kommando för att lägga till konfigurationen i klustret.
crm configure load update crm-sbd.txtLägg till den virtuella IP-adressen för resursen genom att skapa filen och lägga till följande text.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Använd följande kommando för att lägga till konfigurationen i klustret.
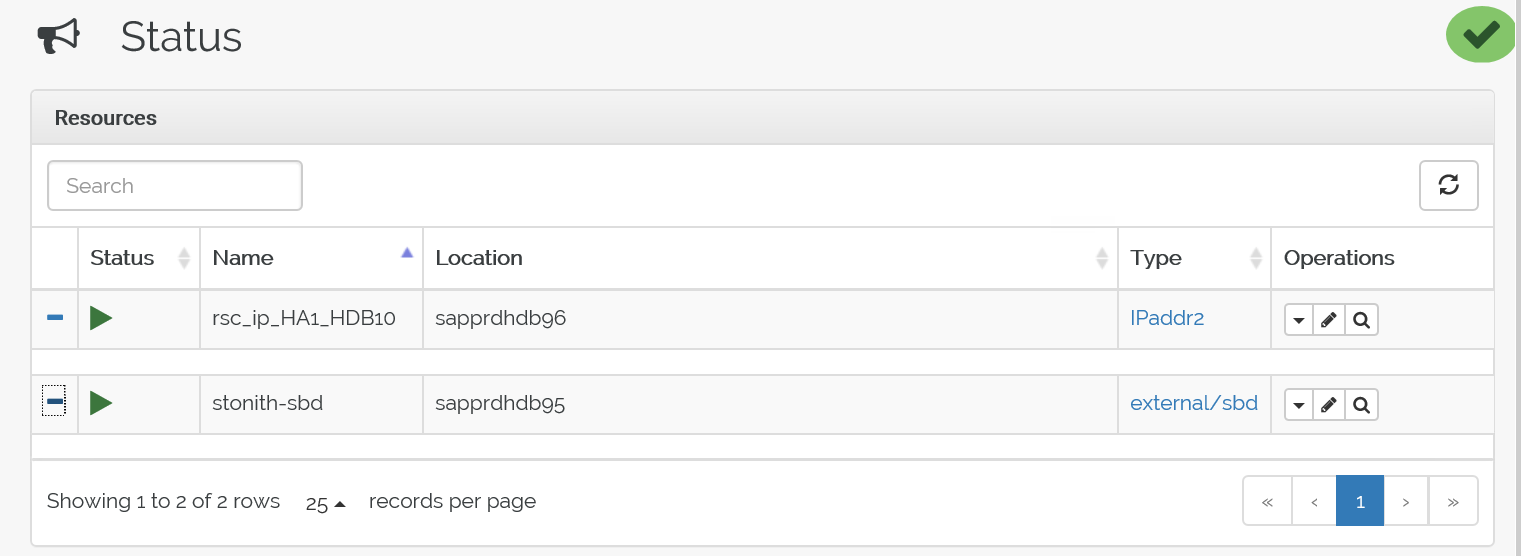
crm configure load update crm-vip.txtcrm_monAnvänd kommandot för att verifiera resurserna.Resultaten visar de två resurserna.

Du kan också kontrollera statusen på https://< nodens IP-adress>:7630/cib/live/state.
Testa redundansväxlingsprocessen
Om du vill testa redundansväxlingen använder du följande kommando för att stoppa pacemakertjänsten på node1.
Service pacemaker stopResurserna redundansväxlar till node2.
Stoppa pacemakertjänsten på node2 och resurser redundansväxlar till node1.
Här är statusen före redundansväxlingen:
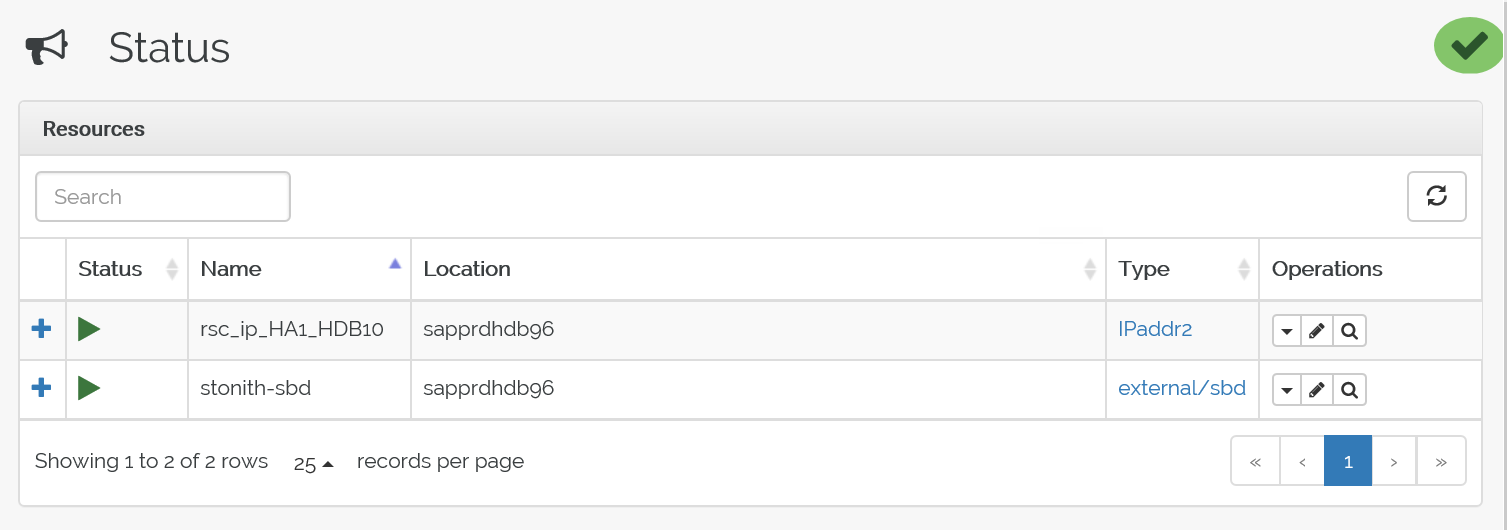
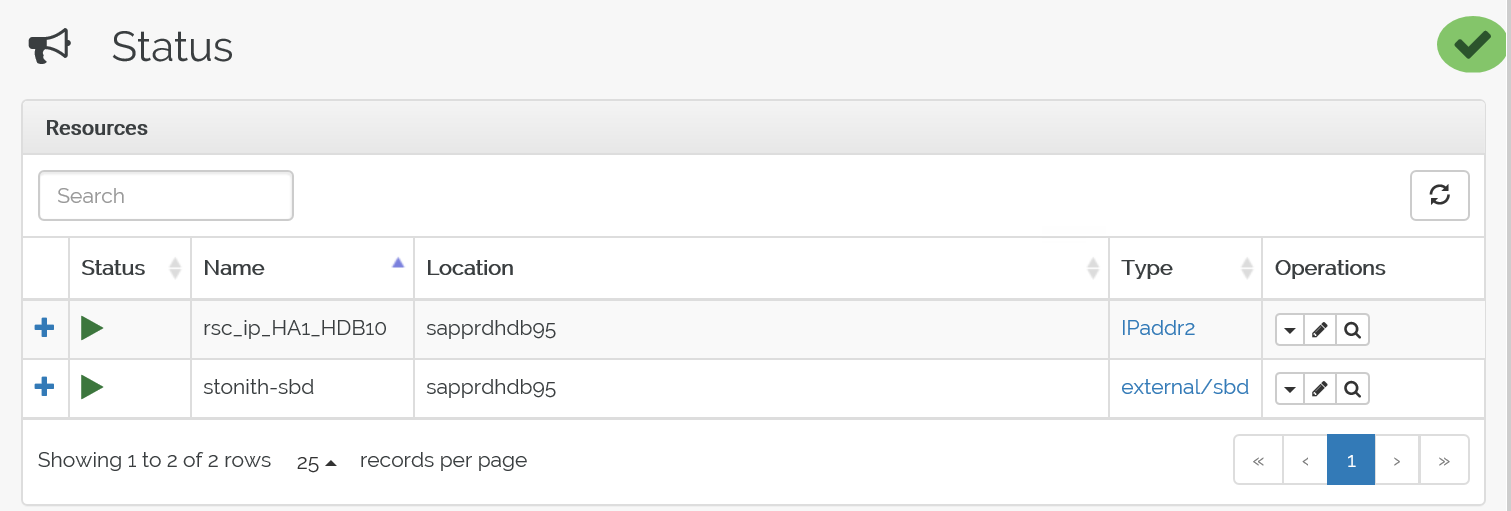
Här är statusen efter redundansväxlingen:

Felsökning
I det här avsnittet beskrivs felscenarier som du kan stöta på under installationen.
Scenario 1: Klusternoden är inte online
Om någon av noderna inte visas online i Klusterhanteraren kan du prova den här proceduren för att ta den online.
Använd följande kommando för att starta iSCSI-tjänsten.
service iscsid startAnvänd följande kommando för att logga in på den iSCSI-noden.
iscsiadm -m node -lFörväntade utdata ser ut så här:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scenario 2: Yast2 visar inte grafisk vy
Den grafiska skärmen yast2 används för att konfigurera klustret med hög tillgänglighet i den här artikeln. Om yast2 inte öppnas med det grafiska fönstret som det visas, och det utlöser ett Qt-fel, utför du följande steg för att installera de nödvändiga paketen. Om den öppnas med det grafiska fönstret kan du hoppa över stegen.
Här är ett exempel på Qt-felet:

Här är ett exempel på förväntade utdata:
Kontrollera att du är inloggad som användarens "rot" och att SMT har konfigurerats för att ladda ned och installera paketen.
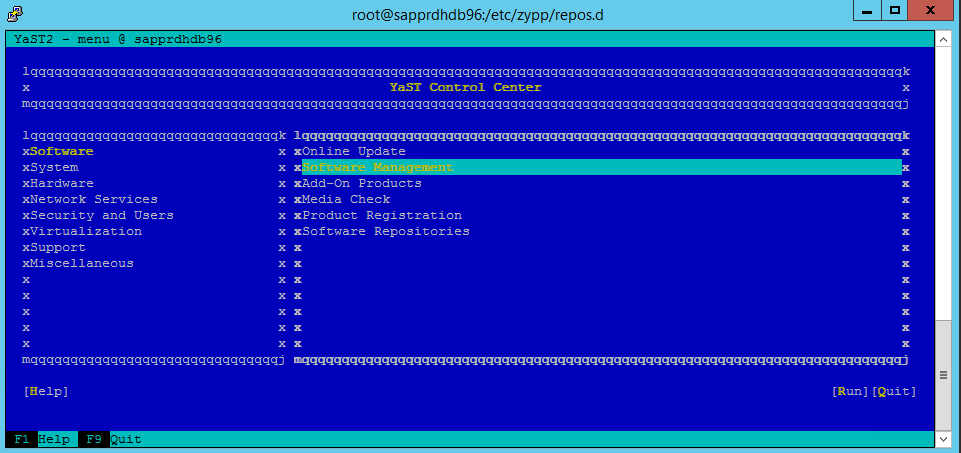
Gå till yast>Software>Software Management>Dependencies och välj sedan Installera rekommenderade paket.
Anteckning
Utför stegen på båda noderna så att du kan komma åt den grafiska vyn yast2 från båda noderna.
Följande skärmbild visar den förväntade skärmen.
Under Beroenden väljer du Installera rekommenderade paket.
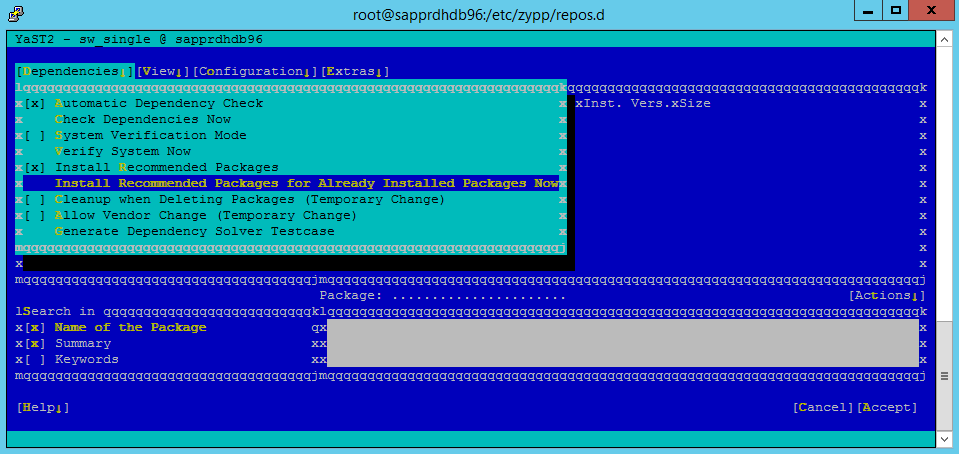
Granska ändringarna och välj OK.
Paketinstallationen fortsätter.
Välj Nästa.
När skärmen Installationen är klar visas väljer du Slutför.
Använd följande kommandon för att installera paketen libqt4 och libyui-qt.
zypper -n install libqt4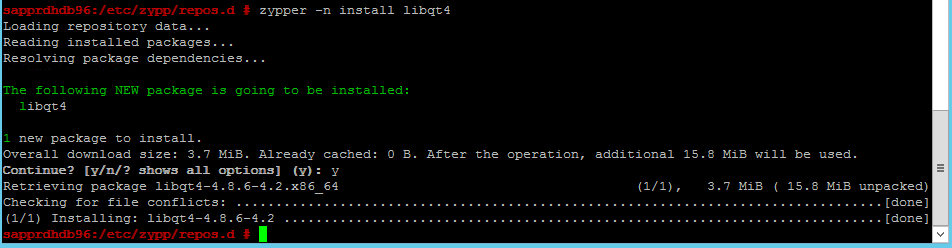
zypper -n install libyui-qt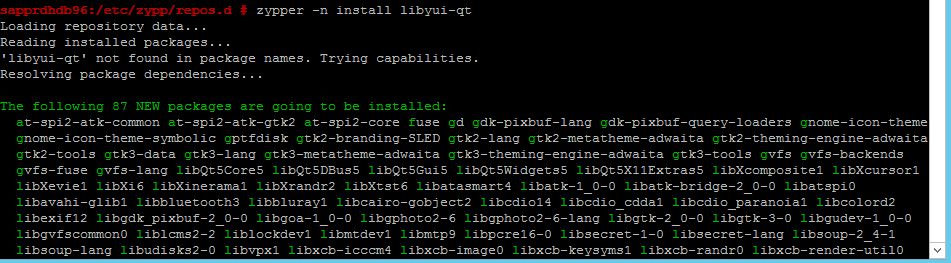

Yast2 kan nu öppna den grafiska vyn.
Scenario 3: Yast2 visar inte alternativet för hög tillgänglighet
För att alternativet med hög tillgänglighet ska vara synligt i yast2-kontrollcentret måste du installera de andra paketen.
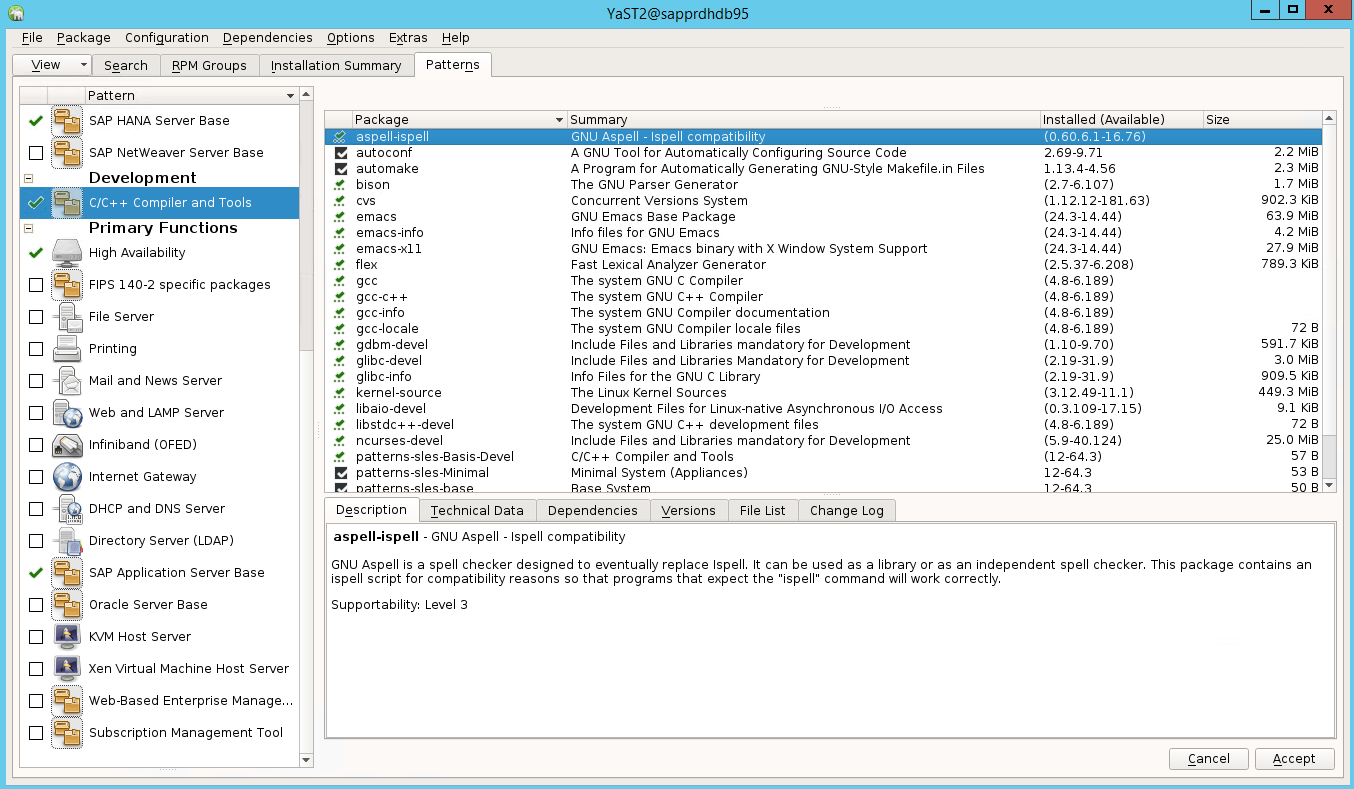
Gå till Yast2>Software>Software Management. Välj sedan Programuppdatering>online.
Välj mönster för följande objekt. Välj sedan Acceptera.
- SAP HANA-serverbas
- C/C++-kompilator och verktyg
- Hög tillgänglighet
- SAP-programserverbas
I listan över paket som har ändrats för att lösa beroenden väljer du Fortsätt.

På sidan Installationsstatus väljer du Nästa.
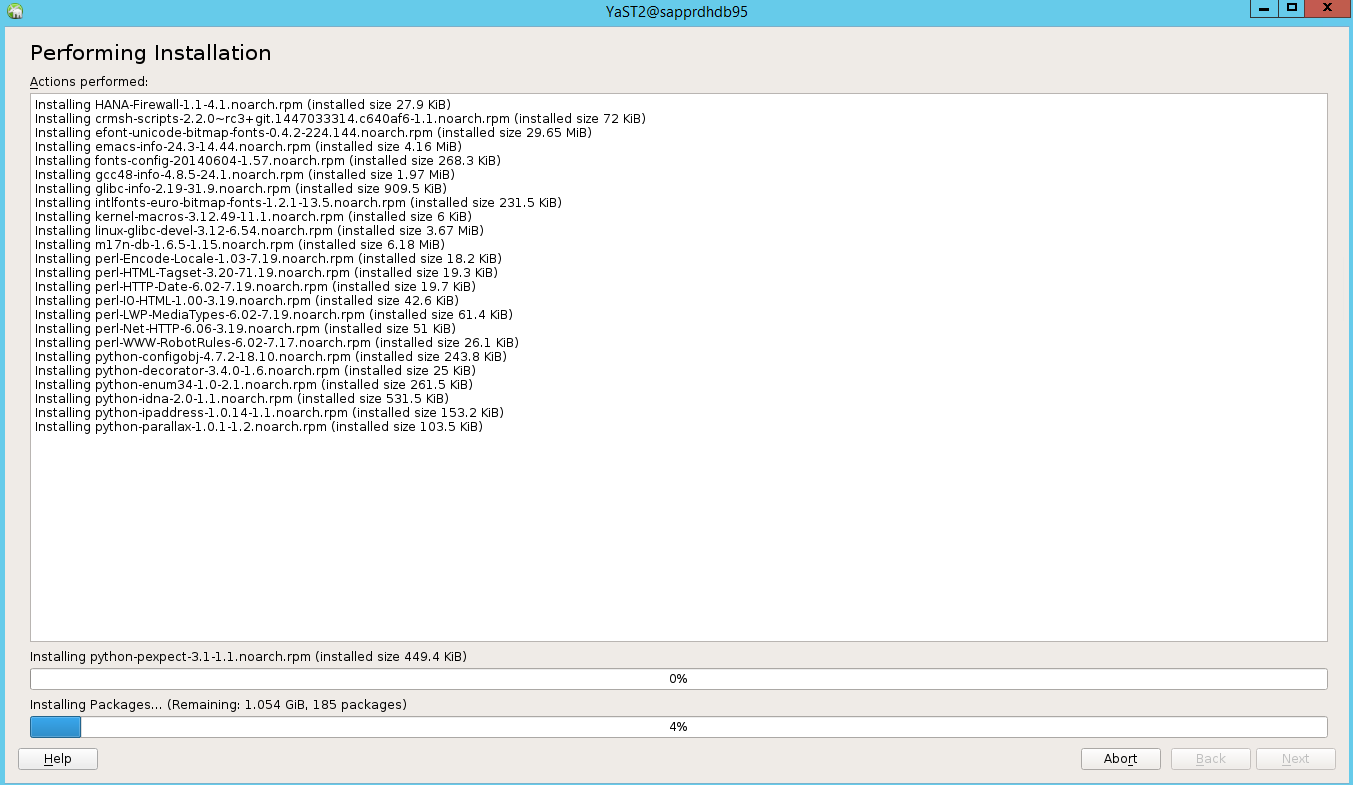
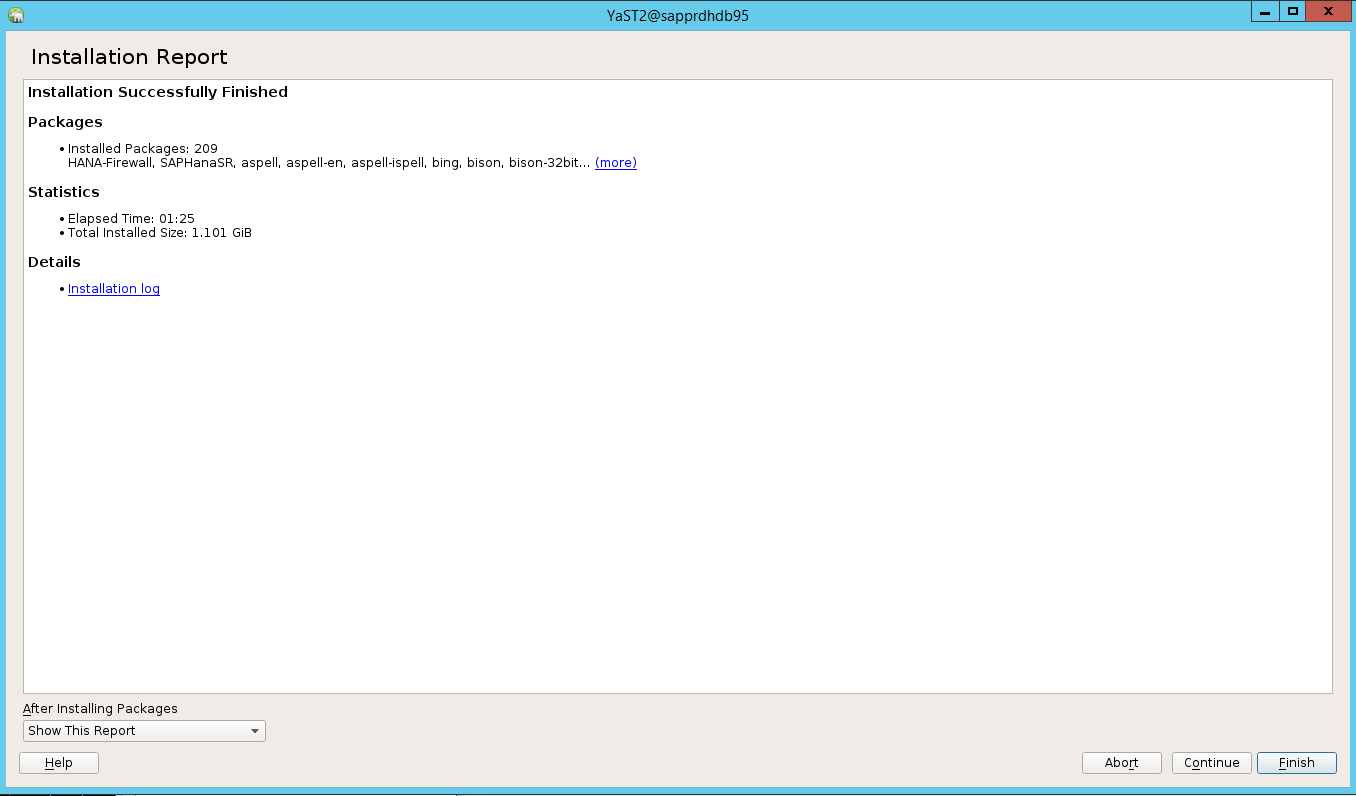
När installationen är klar visas en installationsrapport. Välj Slutför.
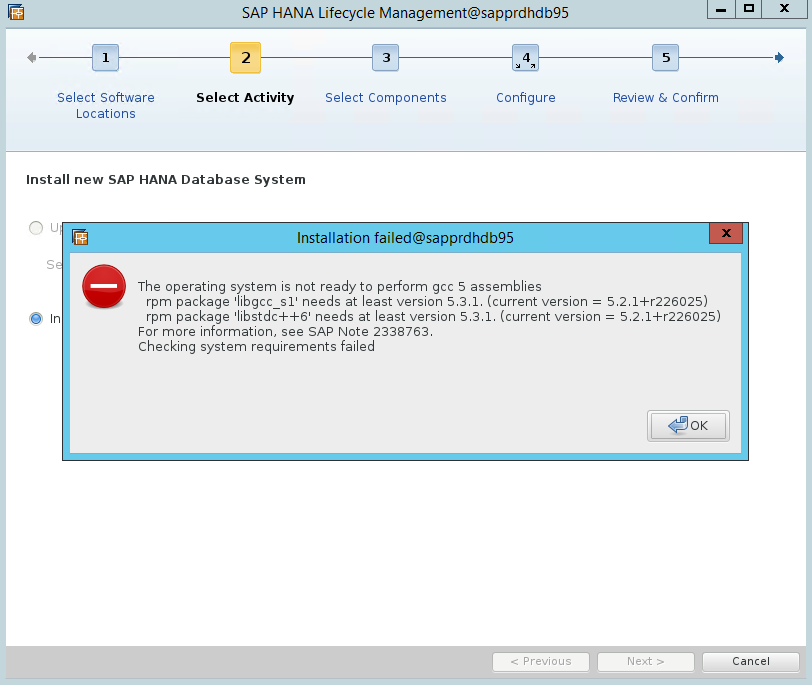
Scenario 4: HANA-installationen misslyckas med gcc-sammansättningar
Om HANA-installationen misslyckas kan du få följande fel.
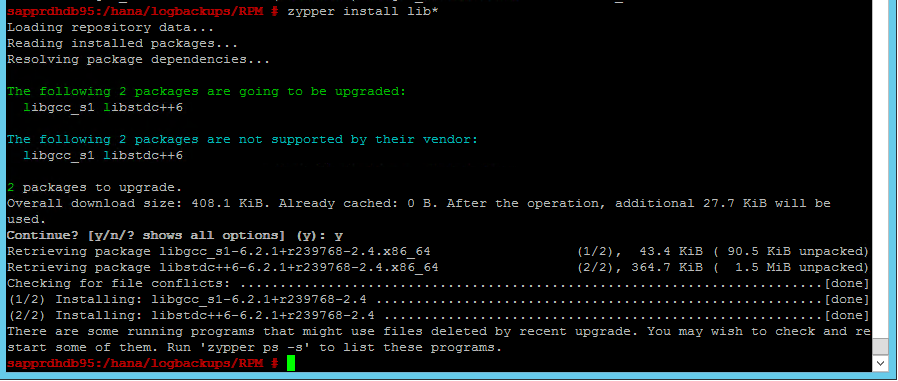
Åtgärda problemet genom att installera biblioteken libgcc_sl och libstdc++6 enligt följande skärmbild.
Scenario 5: Pacemakertjänsten misslyckas
Följande information visas om pacemakertjänsten inte kan starta.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
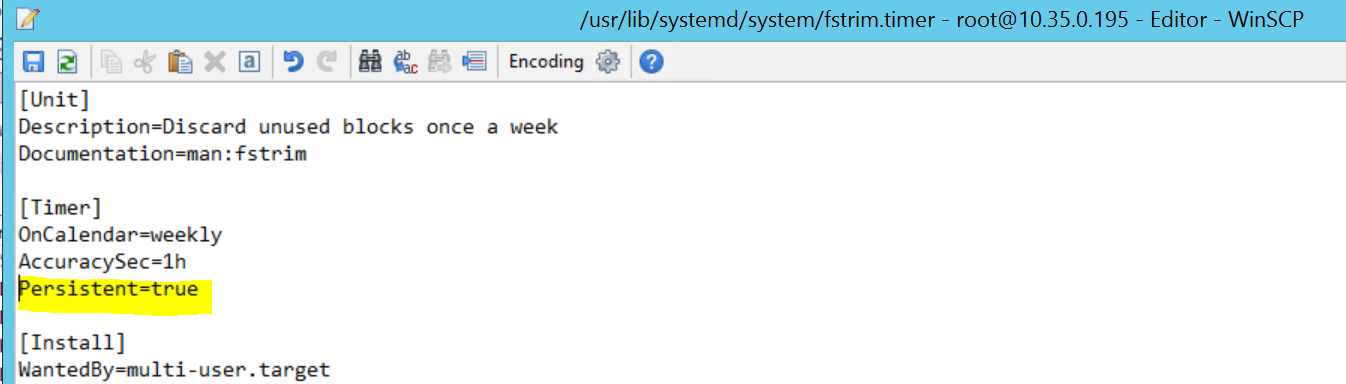
Åtgärda problemet genom att ta bort följande rad från filen /usr/lib/systemd/system/fstrim.timer:
Persistent=true
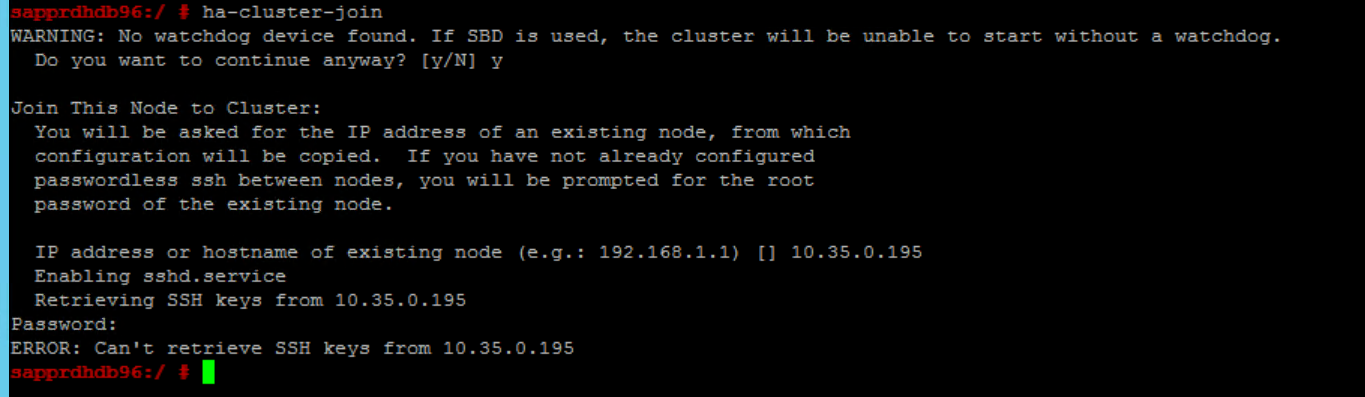
Scenario 6: Node2 kan inte ansluta till klustret
Följande fel visas om det finns ett problem med att ansluta node2 till det befintliga klustret via kommandot ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>
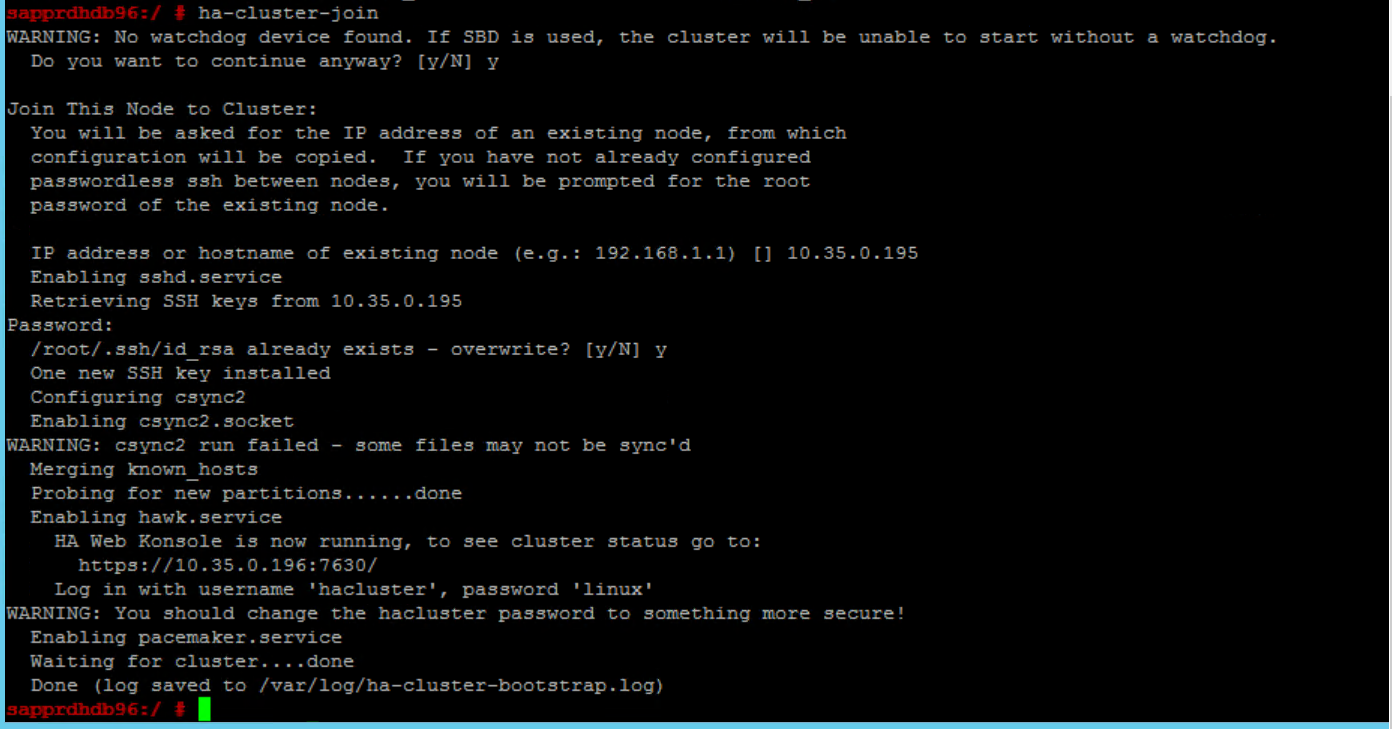
Så här åtgärdar du det:
Kör följande kommandon på båda noderna.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Bekräfta att node2 har lagts till i klustret.
Nästa steg
Mer information om konfiguration av SUSE HA finns i följande artiklar:
- SAP HANA SR-prestandaoptimerad scenario (SUSE-webbplats)
- Fäktnings- och fäktningsenheter (SUSE-webbplats)
- Var beredd på att använda pacemakerkluster för SAP HANA – del 1: Grunder (SAP-blogg)
- Var beredd på att använda pacemakerkluster för SAP HANA – del 2: Fel i båda noderna (SAP-blogg)
- Säkerhetskopiering och återställning av operativsystem