Konfigurationsalternativ för att minimera nätverksfördröjning med SAP-program
Viktigt!
I november 2021 gjorde vi betydande ändringar i hur närhetsplaceringsgrupper ska användas med SAP-arbetsbelastning i zonindelade distributioner.
SAP-program baserade på SAP NetWeaver- eller SAP S/4HANA-arkitekturen är känsliga för nätverksfördröjning mellan SAP-programnivån och SAP-databasnivån. Den här känsligheten är resultatet av det mesta av affärslogik som körs i programskiktet. Eftersom SAP-programlagret kör affärslogik utfärdar det frågor till databasnivån med hög frekvens, med en hastighet av tusentals eller tiotusentals per sekund. I de flesta fall är typen av frågor enkel. De kan ofta köras på databasnivån på 500 mikrosekunder eller mindre.
Den tid som läggs på nätverket för att skicka en sådan fråga från programnivån till databasnivån och ta emot resultatet som skickas tillbaka har stor inverkan på den tid det tar att köra affärsprocesser. Den här känsligheten för nätverksfördröjning är anledningen till att du kanske vill uppnå viss minsta nätverksfördröjning i SAP-distributionsprojekt. Se SAP Note #1100926 – Vanliga frågor och svar: Nätverksprestanda för riktlinjer för hur du klassificerar nätverksfördröjningen.
I många Azure-regioner har antalet datacenter ökat. Samtidigt använder kunder, särskilt för avancerade SAP-system, mer speciella VM-familjer som Mv2- eller Mv3-familj och nyare. Dessa typer av virtuella Azure-datorer är inte alltid tillgängliga i vart och ett av de datacenter som samlas in i en Azure-region. Dessa fakta kan skapa möjligheter att optimera nätverksfördröjningen mellan SAP-programlagret och SAP DBMS-lagret.
Azure tillhandahåller olika distributionsalternativ för SAP-arbetsbelastningar. För den valda distributionstypen har du alternativ för att optimera nätverksfördröjningen om det behövs. Detaljerad information om varje alternativ beskrivs noggrant i följande avsnitt i den här artikeln:
Närhetsplaceringsgrupper
Närhetsplaceringsgrupper möjliggör gruppering av olika typer av virtuella datorer under en enda nätverksrygg, vilket säkerställer optimal låg nätverksfördröjning mellan dem. När den första virtuella datorn distribueras i närhetsplaceringsgruppen blir den virtuella datorn bunden till en specifik nätverksrygg. Eftersom alla andra virtuella datorer som ska distribueras till samma närhetsplaceringsgrupp grupperas de virtuella datorerna under samma nätverksrygg. Hur tilltalande denna möjlighet än låter, introducerar användningen av konstruktionen vissa begränsningar och fallgropar också:
- Du kan inte anta att alla typer av virtuella Azure-datorer är tillgängliga i alla Azure-datacenter eller under varje nätverksrygg. Därför kan kombinationen av olika typer av virtuella datorer inom en närhetsplaceringsgrupp begränsas kraftigt. Dessa begränsningar beror på att värdmaskinvaran som behövs för att köra en viss typ av virtuell dator kanske inte finns i datacentret eller under nätverksryggen som närhetsplaceringsgruppen tilldelades till
- När du ändrar storlek på delar av de virtuella datorer som finns inom en närhetsplaceringsgrupp kan du inte automatiskt anta att den nya vm-typen i alla fall är tillgänglig i samma datacenter eller under nätverksryggen som närhetsplaceringsgruppen tilldelades till
- När Azure inaktiverar maskinvara kan det tvinga vissa virtuella datorer i en närhetsplaceringsgrupp till ett annat Azure-datacenter eller en annan nätverksrygg. Mer information om det här fallet finns i dokumentet Närhetsplaceringsgrupper
Viktigt!
Som ett resultat av de potentiella begränsningarna bör närhetsplaceringsgrupper endast användas:
- Vid behov i vissa scenarier (se senare)
- När nätverksfördröjningen mellan programskiktet och DBMS-lagret är för hög och påverkar arbetsbelastningen
- Endast på kornighet för ett enda SAP-system och inte för ett helt systemlandskap eller ett fullständigt SAP-landskap
- På ett sätt som gör det möjligt att hålla de olika typerna av virtuella datorer och antalet virtuella datorer inom en närhetsplaceringsgrupp till ett minimum
Scenarier där närhetsplaceringsgrupper kan användas för att optimera nätverksfördröjning:
- Du vill distribuera de kritiska resurserna för din SAP-arbetsbelastning över olika tillgänglighetszoner och å andra sidan behöver virtuella datorer på programnivån spridas över olika feldomäner med hjälp av tillgänglighetsuppsättningar i var och en av zonerna. I det här fallet, som beskrivs senare i dokumentet, är närhetsplaceringsgrupper det lim som behövs.
- Du distribuerar SAP-arbetsbelastningen med tillgänglighetsuppsättningar. Där SAP-databasnivån, SAP-programnivån och virtuella ASCS/SCS-datorer grupperas i tre olika tillgänglighetsuppsättningar. I så fall vill du se till att tillgänglighetsuppsättningarna inte är spridda över hela Azure-regionen eftersom detta kan, beroende på Azure-regionen, leda till nätverksfördröjning som kan påverka SAP-arbetsbelastningen negativt.
- Du använder närhetsplaceringsgrupper för att gruppera virtuella datorer för att uppnå lägsta möjliga nätverksfördröjning mellan de tjänster som finns på de virtuella datorerna. Svarstiden i en tillgänglighetszon uppfyller till exempel inte programkraven.
När det gäller distributionsscenario nr 2 i många regioner, särskilt regioner utan tillgänglighetszoner och de flesta regioner med tillgänglighetszoner, är nätverksfördröjningen oberoende av var de virtuella datorerna landar. Även om det finns vissa regioner i Azure som inte kan ge en tillräckligt bra upplevelse utan att samordna de tre olika tillgänglighetsuppsättningarna utan användning av närhetsplaceringsgrupper.
Vad är närhetsplaceringsgrupper?
En Närhetsplaceringsgrupp i Azure är en logisk konstruktion. När en närhetsplaceringsgrupp definieras är den bunden till en Azure-region och en Azure-resursgrupp. När virtuella datorer distribueras refereras en närhetsplaceringsgrupp av:
- Den första virtuella Azure-datorn som distribuerades under en nätverksrygg med många Azure-beräkningsenheter och låg nätverksfördröjning. En sådan nätverksrygg matchar ofta ett enda Azure-datacenter. Du kan se den första virtuella datorn som en "virtuell omfångsdator" som distribueras till en beräkningsskalningsenhet baserat på Azure-allokeringsalgoritmer som slutligen kombineras med distributionsparametrar.
- Alla efterföljande virtuella datorer som distribueras som refererar till närhetsplaceringsgruppen kommer att distribueras under samma nätverksrygg som den första virtuella datorn.
Kommentar
Om det inte finns någon distribuerad värdmaskinvara som kan köra en viss typ av virtuell dator under nätverksryggen där den första virtuella datorn placerades, kommer distributionen av den begärda vm-typen inte att lyckas. Du får ett meddelande om allokeringsfel som anger att den virtuella datorn inte kan stödjas inom närhetsplaceringsgruppens perimeter.
För att minska risken för ovanstående rekommenderar vi att du använder avsiktsalternativet när du skapar närhetsplaceringsgruppen. Med avsiktsalternativet kan du lista de VM-typer som du tänker ta med i närhetsplaceringsgruppen. Den här listan över typer av virtuella datorer används för att hitta det bästa datacentret som är värd för dessa typer av virtuella datorer. Om ett sådant datacenter hittas kommer PPG att skapas och omfångsbegränsas för det datacenter som uppfyller kraven för VM SKU. Om det inte finns något sådant datacenter kommer skapandet av närhetsplaceringsgruppen att misslyckas. Mer information finns i dokumentationen PPG – Använd avsikten för att ange VM-storlekar. Tänk på att faktiska kapacitetssituationer inte beaktas i kontrollerna som utlöses av avsiktsalternativet. Därför kan det fortfarande finnas allokeringsfel rotade i otillräcklig kapacitet.
En enskild Azure-resursgrupp kan ha flera närhetsplaceringsgrupper tilldelade till sig. Men en närhetsplaceringsgrupp kan bara tilldelas till en Azure-resursgrupp.
Mer information och distributionsexempel på närhetsplaceringsgrupper finns i den tillgängliga dokumentationen.
Närhetsplaceringsgrupper med zonindelade distributioner
Det är viktigt att tillhandahålla en ganska låg nätverksfördröjning mellan SAP-programnivån och DBMS-nivån. I de flesta fall uppfyller en zonindelad distribution det här kravet. För en begränsad uppsättning scenarier kanske en zonindelad distribution inte uppfyller kraven på programfördröjning. Sådana situationer kräver vm-placering så nära som möjligt och möjliggör någorlunda låg nätverksfördröjning. En Azure-närhetsplaceringsgrupp kan definieras för ett sådant SAP-system.
Undvik att paketera flera SAP-produktions- eller icke-produktionssystem i en enda närhetsplaceringsgrupp. Undvik paket med SAP-system eftersom ju fler system du grupperar i en närhetsplaceringsgrupp, desto högre är chanserna:
- Att du behöver en vm-typ som inte är tillgänglig under nätverksryggen som närhetsplaceringsgruppen tilldelades till.
- Resurserna för icke-överordnade virtuella datorer, till exempel virtuella datorer i M-serien, kan så småningom bli ouppfyllda när du behöver utöka antalet virtuella datorer till en närhetsplaceringsgrupp över tid.
Baserat på många förbättringar som Distribuerats av Microsoft till Azure-regionerna för att minska nätverksfördröjningen i en Azure-tillgänglighetszon, ser distributionsvägledningen ut så här när du använder närhetsplaceringsgrupper för zonindelade distributioner:
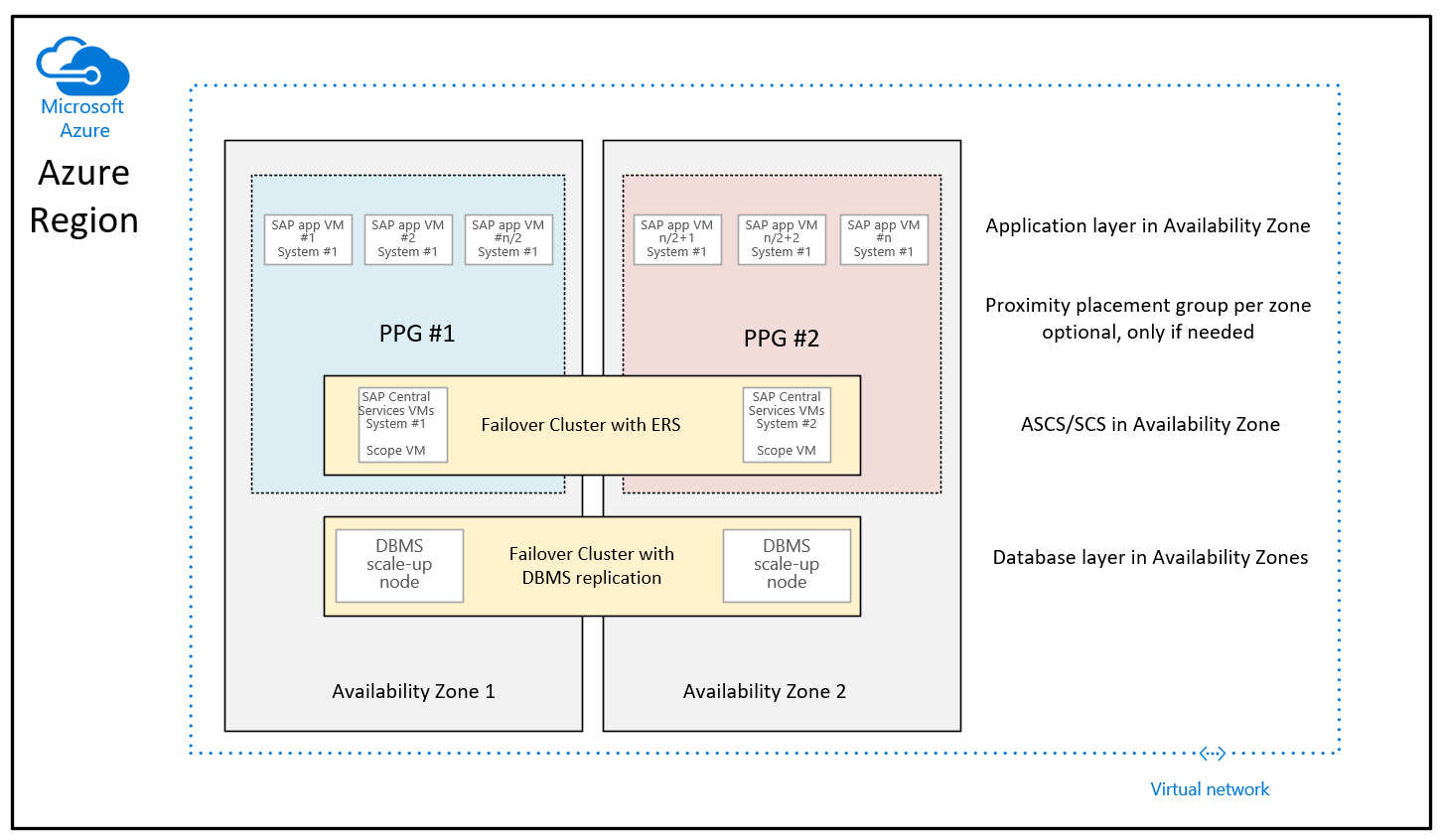
Skillnaden mot den rekommendation som har angetts hittills är att de virtuella databasdatorerna i de två zonerna inte längre är en del av närhetsplaceringsgrupperna. Närhetsplaceringsgrupperna per zon är nu begränsade med distributionen av den virtuella datorn som kör SAP ASCS/SCS-instanserna. Det innebär också att för de regioner där tillgänglighetszoner samlas in av flera datacenter kan ASCS/SCS-instansen och programnivån köras under en nätverksrygg och de virtuella databasdatorerna kan köras under en annan nätverksrygg. Men med de nätverksförbättringar som gjorts bör nätverksfördröjningen mellan SAP-programnivån och DBMS-nivån fortfarande vara tillräcklig för tillräckligt bra prestanda och dataflöde. Fördelen med den här nya konfigurationen är att du har större flexibilitet när det gäller att ändra storlek på virtuella datorer eller flytta till nya typer av virtuella datorer med antingen DBMS-lagret eller/och programskiktet i SAP-systemet.
Om du vill använda Azure NetApp Files för DBMS-miljön och azure NetApp Files-relaterade funktioner i Azure NetApp Files-programvolymgruppen för SAP HANA och dess nödvändighet för närhetsplaceringsgrupper, kontrollerar du dokumentet NFS v4.1-volymer på Azure NetApp Files för SAP HANA.
Närhetsplaceringsgrupper med distributioner av tillgänglighetsuppsättningar
I det här fallet är syftet att använda närhetsplaceringsgrupper för att samordna de virtuella datorer som distribueras via olika tillgänglighetsuppsättningar. I det här användningsscenariot använder du inte en kontrollerad distribution över olika tillgänglighetszoner i en region. I stället vill du distribuera SAP-systemet med hjälp av tillgänglighetsuppsättningar. Därför har du minst en tillgänglighetsuppsättning för de virtuella DBMS-datorerna, de virtuella ASCS-/SCS-datorerna och de virtuella datorerna på programnivå. Eftersom du inte kan ange en tillgänglighetsuppsättning och en tillgänglighetszon vid distributionstiden för en virtuell dator kan du inte styra var de virtuella datorerna i de olika tillgänglighetsuppsättningarna ska allokeras. Detta kan resultera i vissa Azure-regioner att nätverksfördröjningen mellan olika virtuella datorer fortfarande kan vara för hög för att ge en tillräckligt bra prestandaupplevelse. Den resulterande arkitekturen skulle därför se ut så här:
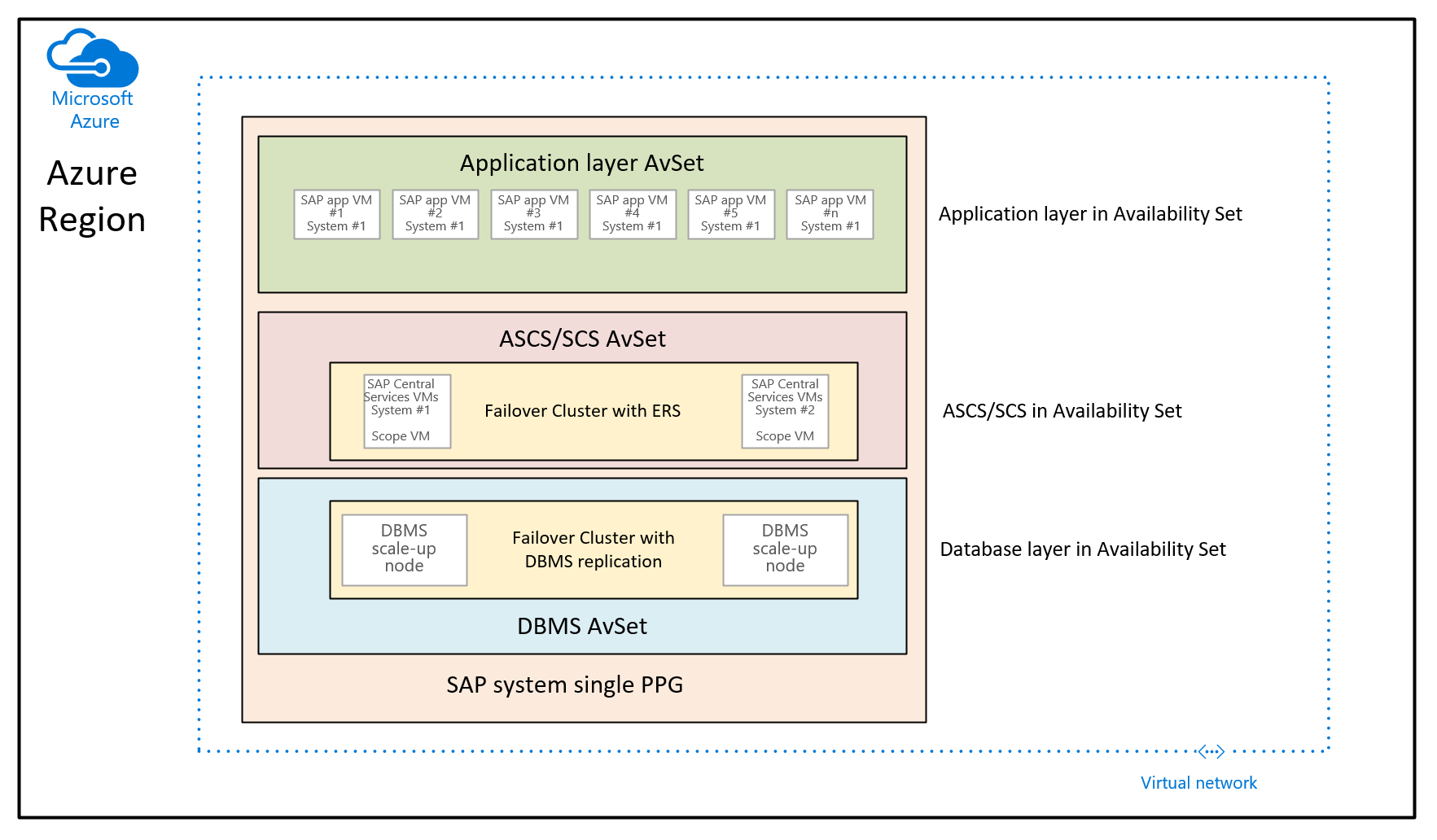
I den här bilden tilldelas en enda närhetsplaceringsgrupp till ett enda SAP-system. Denna PPG tilldelas till de tre tillgänglighetsuppsättningarna. Närhetsplaceringsgruppen begränsas sedan genom att distribuera de virtuella datorerna på den första databasnivån till DBMS-tillgänglighetsuppsättningen. Den här arkitekturrekommenderingen samlar alla virtuella datorer under samma nätverksrygg. Den introducerar de begränsningar som nämns tidigare i den här artikeln. Därför bör närhetsplaceringsgruppens arkitektur användas sparsamt.
Kombinera tillgänglighetsuppsättningar och tillgänglighetszoner med närhetsplaceringsgrupper
Ett av problemen med att använda tillgänglighetszoner för SAP-systemdistributioner är att du inte kan distribuera SAP-programnivån med hjälp av tillgänglighetsuppsättningar i den specifika tillgänglighetszonen. Du vill att SAP-programnivån ska distribueras i samma zoner som de virtuella SAP ASCS-/SCS-datorerna. Det är inte möjligt att referera till en tillgänglighetszon och en tillgänglighetsuppsättning när du distribuerar en enskild virtuell dator än så länge. Men när du bara distribuerar en virtuell dator som instruerar en tillgänglighetszon förlorar du möjligheten att se till att de virtuella datorerna på programnivå är spridda över olika uppdaterings- och feldomäner.
Genom att använda närhetsplaceringsgrupper kan du kringgå den här begränsningen. Här är distributionssekvensen:
- Skapa en närhetsplaceringsgrupp.
- Distribuera den virtuella ankardatorn, som rekommenderas som den virtuella ASCS-/SCS-datorn, genom att referera till en tillgänglighetszon.
- Skapa en tillgänglighetsuppsättning som refererar till närhetsplaceringsgruppen i Azure. (Se kommandot senare i den här artikeln.)
- Distribuera de virtuella datorerna på programnivå genom att referera till tillgänglighetsuppsättningen och närhetsplaceringsgruppen.
Viktigt!
Det är viktigt att förstå att diskar på de virtuella datorerna på programnivå inte garanteras allokeras i samma tillgänglighetszon som de virtuella datorerna dirigeras till med närhetsplaceringsgruppen. Resultatet av distributionen som visas i nästa steg kan vara att de virtuella datorerna allokeras i samma nätverksrygg och med samma tillgänglighetszon som den virtuella ankardatorn. Men de respctive diskarna (bas-VHD och monterade Azure-blocklagringsdiskar) kanske inte allokeras under samma nätverksrygg eller ens samma tillgänglighetszon. I stället kan diskarna för dessa virtuella datorer allokeras i något av datacenteren i den specifika regionen. Även om diskarna på den virtuella ankardatorn som distribuerades genom att definiera en zon kommer att distribueras i samma zon som den virtuella datorn distribuerades.
I stället för att distribuera den första virtuella datorn enligt föregående avsnitt refererar du till en tillgänglighetszon och närhetsplaceringsgruppen när du distribuerar den virtuella datorn:
New-AzVm -ResourceGroupName "ppgexercise" -Name "centralserviceszone1" -Location "westus2" -OpenPorts 80,3389 -Zone "1" -ProximityPlacementGroup "collocate" -Size "Standard_E8s_v4"
En lyckad distribution av den här virtuella datorn skulle vara värd för ASCS/SCS-instansen av SAP-systemet i en tillgänglighetszon. I det här fallet allokeras den virtuella datorn och den virtuella datorns bas-VHD och potentiellt monterade Azure-blocklagringsdiskar inom samma tillgänglighetszon. Omfånget för närhetsplaceringsgruppen är fast i en av nätverksryggarna i den tillgänglighetszon som du definierade.
I nästa steg måste du skapa de tillgänglighetsuppsättningar som du vill använda för programskiktet i DITT SAP-system.
Definiera och skapa närhetsplaceringsgruppen. Kommandot för att skapa tillgänglighetsuppsättningen kräver ytterligare en referens till närhetsplaceringsgruppens ID (inte namnet). Du kan hämta ID:t för närhetsplaceringsgruppen med hjälp av det här kommandot:
Get-AzProximityPlacementGroup -ResourceGroupName "ppgexercise" -Name "collocate"
När du skapar tillgänglighetsuppsättningen måste du överväga ytterligare parametrar när du använder hanterade diskar (standard om inget annat anges) och närhetsplaceringsgrupper:
New-AzAvailabilitySet -ResourceGroupName "ppgexercise" -Name "ppgavset" -Location "westus2" -ProximityPlacementGroupId "/subscriptions/my very long ppg id string" -sku "aligned" -PlatformUpdateDomainCount 3 -PlatformFaultDomainCount 2
Helst bör du använda tre feldomäner. Men antalet feldomäner som stöds kan variera från region till region. I det här fallet är det maximala antalet feldomäner som är möjliga för de specifika regionerna två. Om du vill distribuera dina virtuella datorer på programnivå måste du lägga till en referens till namnet på tillgänglighetsuppsättningen och namnet på närhetsplaceringsgruppen, som du ser här:
New-AzVm -ResourceGroupName "ppgexercise" -Name "appinstance1" -Location "westus2" -OpenPorts 80,3389 -AvailabilitySetName "myppgavset" -ProximityPlacementGroup "collocate" -Size "Standard_E16s_v4"
Kommentar
Diskarna för de virtuella datorer som distribueras till tillgänglighetsuppsättningen ovan tvingas inte allokeras i samma tillgänglighetszon som den virtuella datorn är. Även om du har uppnått att de virtuella datorerna på programnivå är spridda över olika feldomäner under samma nätverksrygg som den ankar-VM:n allokeras, kan diskarna, även om de allokeras i olika feldomäner, allokeras på olika platser i en regionomfattande omfattning.
Resultatet av den här distributionen är:
- En central tjänst för ditt SAP-system som finns i en specifik tillgänglighetszon(er).
- Ett SAP-programlager som finns via tillgänglighetsuppsättningar i samma nätverksrygg som den virtuella datorn eller de virtuella datorerna för SAP Central-tjänster (ASCS/SCS).
Kommentar
Eftersom du distribuerar en DBMS- och ASCS/SCS-vm till en zon och den andra virtuella DBMS- och ASCS/SCS-datorn till en annan zon för att skapa en konfiguration med hög tillgänglighet, behöver du en annan närhetsplaceringsgrupp för var och en av zonerna. Detsamma gäller för alla tillgänglighetsuppsättningar som du använder.
Ändra närhetsplaceringsgruppkonfigurationer för ett befintligt system
Om du har implementerat närhetsplaceringsgrupper enligt de rekommendationer som har getts hittills och vill anpassa dig till den nya konfigurationen kan du göra det med de metoder som beskrivs i dessa artiklar:
- Distribuera virtuella datorer till närhetsplaceringsgrupper med hjälp av Azure CLI.
- Distribuera virtuella datorer till närhetsplaceringsgrupper med hjälp av PowerShell.
Du kan också använda dessa kommandon för fall där du får allokeringsfel i fall där du inte kan flytta till en ny typ av virtuell dator med en befintlig virtuell dator i närhetsplaceringsgruppen.
Vm-skalningsuppsättning med flexibel orkestrering
För att undvika de begränsningar som är associerade med närhetsplaceringsgruppen rekommenderar vi att du distribuerar SAP-arbetsbelastningar mellan tillgänglighetszoner med hjälp av flexibel skalningsuppsättning med FD=1. Den här distributionsstrategin säkerställer att virtuella datorer som distribueras i varje zon inte är begränsade till ett enda datacenter eller nätverksrygg, och alla SAP-systemkomponenter, till exempel databaser, ASCS/ERS och programnivå, är begränsade inom en zon. Eftersom alla SAP-systemkomponenter är begränsade på zonnivå måste nätverksfördröjningen mellan olika komponenter i ett enda SAP-system vara tillräcklig för att säkerställa tillfredsställande prestanda och dataflöde. Den viktigaste fördelen med det här nya distributionsalternativet med flexibel skalningsuppsättning med FD=1 är att det ger större flexibilitet när det gäller att ändra storlek på virtuella datorer eller växla till nya vm-typer för alla lager i SAP-systemet. Skalningsuppsättningen allokerar även virtuella datorer över flera feldomäner i en enda zon, vilket är idealiskt för att köra flera virtuella datorer på programnivån i varje zon. Mer information finns i dokumentet vm-skalningsuppsättning för SAP-arbetsbelastning .
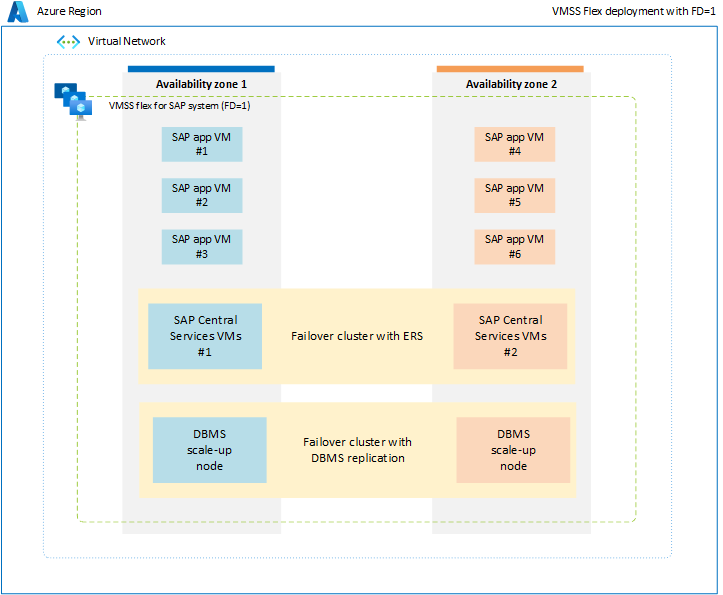
I en icke-produktions- eller icke-HA-miljö är det möjligt att distribuera alla SAP-systemkomponenter, inklusive databasen, ASCS och programnivån, inom en enda zon med hjälp av en flexibel skalningsuppsättning med FD=1.
Tidigare rekommenderade distributionsalternativ
Det här avsnittet innehåller information om tidigare rekommenderade distributionsalternativ för att optimera nätverksfördröjningen för SAP. Med nya funktioner och Azure-tillväxt över tid bör information i det här avsnittet endast användas i sällsynta fall.
Närhetsplaceringsgrupper för hela SAP-systemet med zonindelade distributioner
Den användning av närhetsplaceringsgrupp som vi har rekommenderat hittills ser ut som i den här bilden.

Du skapar en närhetsplaceringsgrupp (PPG) i var och en av de två tillgänglighetszoner som du distribuerade DITT SAP-system till. Alla virtuella datorer i en viss zon är en del av den enskilda närhetsplaceringsgruppen för den specifika zonen. Du börjar i varje zon med att distribuera den virtuella DBMS-datorn för att begränsa PPG:n och sedan distribuera den virtuella ASCS-datorn till samma zon och PPG. I ett tredje steg skapar du en Azure-tillgänglighetsuppsättning, tilldelar tillgänglighetsuppsättningen till den begränsade PPG:en och distribuerar SAP-programskiktet till den. Fördelen med den här konfigurationen var att alla komponenter är snyggt justerade under samma nätverksrygg. Den stora nackdelen är att din flexibilitet när det gäller att ändra storlek på virtuella datorer kan begränsas.
Baserat på många förbättringar som Microsoft har distribuerat till Azure-regionerna för att minska nätverksfördröjningen i en Azure-tillgänglighetszon finns den aktuella distributionsvägledningen för zonindelade distributioner i den här artikeln.
Närhetsplaceringsgrupper och STORA HANA-instanser
Om vissa av dina SAP-system förlitar sig på HANA-stora instanser för databasskiktet kan du uppleva betydande förbättringar av nätverksfördröjningen mellan enheten HANA Large Instances och virtuella Azure-datorer när du använder HANA Large Instances-enheter som distribueras i revision 4 rader eller stämplar. En förbättring är att HANA Large Instances-enheter, när de distribueras, distribueras med en närhetsplaceringsgrupp. Du kan använda närhetsplaceringsgruppen för att distribuera dina virtuella datorer på programnivå. Därför distribueras dessa virtuella datorer i samma datacenter som är värd för din HANA-enhet för stora instanser.
Om du vill ta reda på om enheten för stora HANA-instanser distribueras i en revision 4-stämpel eller rad kan du läsa artikeln om azure HANA-kontrollen för stora instanser via Azure-portalen. I attributöversikten för enheten HANA Large Instances kan du också fastställa namnet på närhetsplaceringsgruppen eftersom den skapades när enheten HANA Large Instances distribuerades. Namnet som visas i attributöversikten är namnet på närhetsplaceringsgruppen som du bör distribuera dina virtuella datorer på programnivå till.
Jämfört med SAP-system som endast använder virtuella Azure-datorer har du mindre flexibilitet när du använder HANA Stora instanser när du bestämmer hur många Azure-resursgrupper som ska användas. Alla HANA Large Instances-enheter för en hana-klientorganisation för stora instanser grupperas i en enda resursgrupp enligt beskrivningen i den här artikeln. Såvida du inte distribuerar till olika klienter för att separera till exempel produktions- och icke-produktionssystem eller andra system, distribueras alla dina HANA Large Instances-enheter i en HANA Large Instances-klientorganisation. Den här klientorganisationen har en en-till-en-relation med en resursgrupp. Men en separat närhetsplaceringsgrupp definieras för var och en av de enskilda enheterna.
Det innebär att relationerna mellan Azure-resursgrupper och närhetsplaceringsgrupper för en enskild klientorganisation visas här:

Nästa steg
Kolla in dokumentationen:
- SAP-arbetsbelastningar i Azure: Checklista för planering och distribution
- Distribuera virtuella datorer till närhetsplaceringsgrupper med Azure CLI
- Distribuera virtuella datorer till närhetsplaceringsgrupper med Hjälp av PowerShell
- Överväganden för AZURE Virtual Machines DBMS-distribution för SAP-arbetsbelastningar