Snabbstart: Skapa en kompetensuppsättning i Azure Portal
I den här snabbstarten får du lära dig hur en kompetensuppsättning i Azure AI Search lägger till optisk teckenigenkänning (OCR), bildanalys, språkidentifiering, textöversättning och entitetsigenkänning för att generera textsökningsbart innehåll i ett sökindex.
Du kan köra guiden Importera data i Azure Portal för att tillämpa kunskaper som skapar och transformerar textinnehåll under indexeringen. Indata är dina rådata, vanligtvis blobar i Azure Storage. Utdata är ett sökbart index som innehåller AI-genererad bildtext, bildtexter och entiteter. Genererat innehåll kan efterfrågas i Azure Portal med hjälp av Sökutforskaren.
För att förbereda skapar du några resurser och laddar upp exempelfiler innan du kör guiden.
Förutsättningar
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
Skapa en Azure AI-tjänsten Search eller hitta en befintlig tjänst. Du kan använda en kostnadsfri tjänst för den här snabbstarten.
Ett Azure Storage-konto med Azure Blob Storage.
Kommentar
Den här snabbstarten använder Azure AI-tjänster för AI-transformeringar. Eftersom arbetsbelastningen är så liten används Azure AI-tjänster i bakgrunden för kostnadsfri bearbetning för upp till 20 transaktioner. Du kan slutföra den här övningen utan att behöva skapa en Azure AI-resurs med flera tjänster.
Konfigurera dina data
I följande steg konfigurerar du en blobcontainer i Azure Storage för att lagra heterogena innehållsfiler.
Ladda ned exempeldata som består av en liten filuppsättning med olika typer av data.
Logga in på Azure Portal med ditt Azure-konto.
Skapa ett Azure Storage-konto eller hitta ett befintligt konto.
Välj samma region som Azure AI Search för att undvika bandbreddsavgifter.
Välj StorageV2 (generell användning V2).
Öppna din Azure Storage-sida i Azure Portal och skapa en container. Du kan använda standardåtkomstnivån.
I Container väljer du Ladda upp för att ladda upp exempelfilerna. Observera att du har en mängd olika innehållstyper, inklusive bilder och programfiler som inte kan sökas i fulltext i sina interna format.

Nu är du redo att gå vidare med guiden Importera data.
Kör guiden Importera data
Logga in på Azure Portal med ditt Azure-konto.
Hitta söktjänsten. På sidan Översikt väljer du Importera data i kommandofältet för att skapa sökbart innehåll i fyra steg.
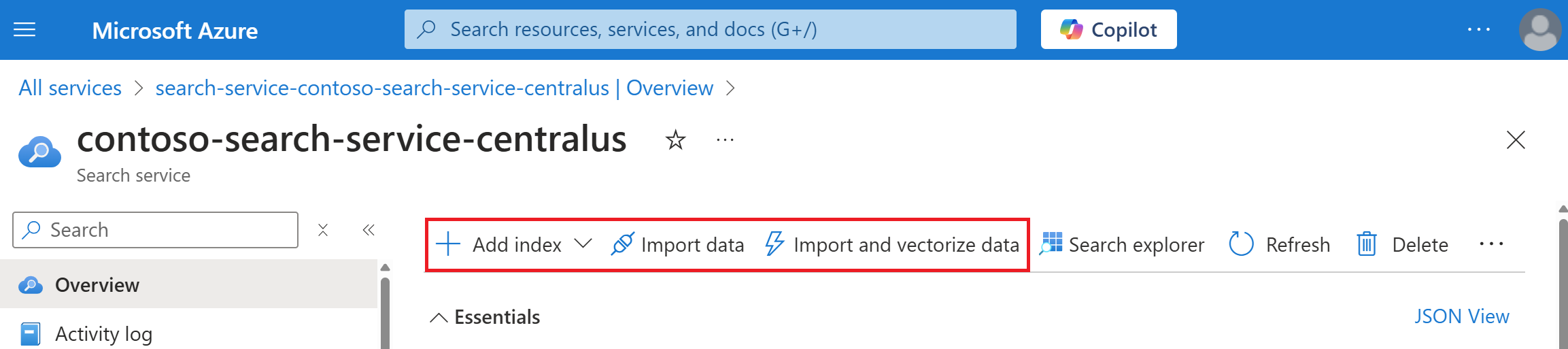
Steg 1: Skapa en datakälla
I Anslut till dina data väljer du Azure Blob Storage.
Välj en befintlig anslutning till lagringskontot och välj den container som du skapade. Namnge datakällan och lämna standardvärdena för resten av inställningarna.

Fortsätt till nästa sida.
Om du får Fel vid identifiering av indexschema från datakälla kan indexeraren som driver guiden inte ansluta till datakällan. Datakällan har förmodligen säkerhetsskydd. Prova följande lösningar och kör sedan guiden igen.
| Säkerhetsfunktion | Lösning |
|---|---|
| Resursen kräver Azure-roller eller dess åtkomstnycklar är inaktiverade | Ansluta som en betrodd tjänst eller ansluta med hjälp av en hanterad identitet |
| Resursen finns bakom en IP-brandvägg | Skapa en inkommande regel för Sök och för Azure Portal |
| Resursen kräver en privat slutpunktsanslutning | Ansluta via en privat slutpunkt |
Steg 2: Lägga till kognitiva kunskaper
Konfigurera sedan AI-berikning för att anropa OCR, bildanalys och bearbetning av naturligt språk.
OCR och bildanalys är tillgängliga för blobar i Azure Blob Storage och Azure Data Lake Storage (ADLS) Gen2 och för bildinnehåll i OneLake. Bilder kan vara fristående filer eller inbäddade bilder i en PDF eller andra filer.
I den här snabbstarten använder vi resursen Kostnadsfria Azure AI-tjänster. Exempeldata består av 14 filer, så den kostnadsfria tilldelningen av 20 transaktioner på Azure AI-tjänster räcker för den här snabbstarten.

Expandera Lägg till berikanden och gör sex val.
Aktivera OCR för att lägga till kunskaper om bildanalys på guidesidan.
Välj entitetsigenkänning (personer, organisationer, platser) och kunskaper om bildanalys (taggar, undertexter).

Fortsätt till nästa sida.
Steg 3: Konfigurera indexet
Ett index innehåller ditt sökbara innehåll och guiden Importera data kan vanligtvis skapa schemat genom att sampling av datakällan. I det här steget granskar du det genererade schemat och kan eventuellt ändra eventuella inställningar.
I den här snabbstarten passar guidens standardinställningar bra:
Standardfält baseras på metadataegenskaper för befintliga blobar, plus de nya fälten för berikningsutdata (till exempel
people,organizations,locations). Datatyper härleds från metadata och genom datasampling.Standarddokumentnyckeln är metadata_storage_path (markerad eftersom fältet innehåller unika värden).
Standardattribut är Hämtningsbara och sökbara. Sökbart tillåter fulltextsökning i ett fält. Hämtningsbar innebär att fältvärden kan returneras i resultat. Guiden förutsätter att du vill att dessa fält ska vara hämtningsbara och sökbara, eftersom du har skapat dem via en kompetensuppsättning. Välj Filterbar om du vill använda fält i ett filteruttryck.

Att markera ett fält som Hämtningsbart betyder inte att fältet måste finnas i sökresultaten. Du kan styra sökresultatets sammansättning med hjälp av frågeparametern select för att ange vilka fält som ska inkluderas.
Fortsätt till nästa sida.
Steg 4: Konfigurera indexeraren
Indexeraren styr indexeringsprocessen. Indexeraren definierar datakällans namn, ett målindex och körningsfrekvensen. Guiden Importera data skapar flera objekt, inklusive en indexerare som du kan återställa och köra upprepade gånger.
På sidan Indexer accepterar du standardnamnet och väljer En gång.

Välj Skicka för att skapa och kör indexeraren samtidigt.
Övervaka status
Välj Indexerare i det vänstra navigeringsfönstret för att övervaka status och välj sedan indexeraren. Kompetensbaserad indexering tar längre tid än textbaserad indexering, särskilt OCR och bildanalys.
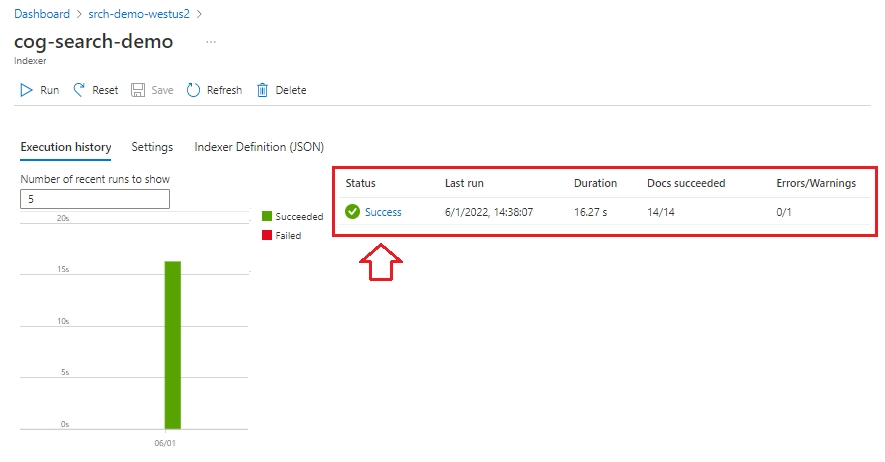
Om du vill visa information om körningsstatus väljer du Lyckades (eller Misslyckades) för att visa körningsinformation.
I den här demonstrationen finns det några varningar: "Det gick inte att köra färdigheter eftersom en eller flera kunskapsindata var ogiltiga." Den anger att en PNG-fil i datakällan inte ger någon textinmatning till Entitetsigenkänning. Den här varningen beror på att den överordnade OCR-färdigheten inte kände igen någon text i bilden och därför inte kunde ange någon textinmatning till den underordnade entitetsigenkänningsfärdigheten.
Varningar är vanliga vid körning av kompetensuppsättningar. När du bekantar dig med hur kunskaper itererar över dina data kan du börja märka mönster och lära dig vilka varningar som är säkra att ignorera.
Fråga i Sökutforskaren
När ett index har skapats använder du Sökutforskaren för att returnera resultat.
Till vänster väljer du Index och sedan indexet. Sökutforskaren finns på den första fliken.
Ange en söksträng för att fråga indexet, till exempel
satya nadella. Sökfältet accepterar nyckelord, citattecken och operatorer:"Satya Nadella" +"Bill Gates" +"Steve Ballmer"
Resultaten returneras som utförlig JSON, vilket kan vara svårt att läsa, särskilt i stora dokument. Några tips för att söka i det här verktyget innehåller följande tekniker:
Växla till JSON-vyn för att ange parametrar som formar resultatet.
Lägg till
selectför att begränsa fälten i resultat.Lägg till
countför att visa antalet matchningar.Använd CTRL-F för att söka i JSON efter specifika egenskaper eller termer.

Här är några JSON som du kan klistra in i vyn:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Dricks
Frågesträngar är skiftlägeskänsliga, så om du får ett meddelande om "okänt fält" markerar du Fält eller Indexdefinition (JSON) för att verifiera namn och skiftläge.
Lärdomar
Nu har du skapat din första kompetensuppsättning och lärt dig de grundläggande stegen i kunskapsbaserad indexering.
Några viktiga begrepp som vi hoppas att du har lärt dig är beroenden. En kompetensuppsättning är bunden till en indexerare och indexerare är Azure och källspecifika. Även om den här snabbstarten använder Azure Blob Storage är andra Azure-datakällor möjliga. Mer information finns i Indexerare i Azure AI Search.
Ett annat viktigt begrepp är att färdigheter fungerar över innehållstyper, och när du arbetar med heterogent innehåll hoppas vissa indata över. Dessutom kan stora filer eller fält överskrida indexeringsgränserna för din tjänstnivå. Det är normalt att se varningar när dessa händelser inträffar.
Utdata dirigeras till ett sökindex och det finns en mappning mellan namn/värde-par som skapats under indexering och enskilda fält i ditt index. Internt konfigurerar guiden ett berikningsträd och definierar en kompetensuppsättning som etablerar ordningen för åtgärder och det allmänna flödet. De här stegen är dolda i guiden, men när du börjar skriva kod blir dessa begrepp viktiga.
Slutligen har du lärt dig att du kan verifiera innehållet genom att fråga indexet. Det som Azure AI Search tillhandahåller är till slut ett sökbart index som du kan köra frågor mot med hjälp av antingen den enkla eller fullständigt utökade frågesyntaxen. Ett index som innehåller berikade fält är precis som andra fält. Du kan använda standardanalysverktyg eller anpassade analysverktyg, bedömningsprofiler, synonymer, fasetterad navigering, geo-sökning eller någon annan Azure AI Search-funktion.
Rensa resurser
När du arbetar i din egen prenumeration kan det dock vara klokt att i slutet av ett projekt kontrollera om du fortfarande behöver de resurser som du skapade. Resurser som fortsätter att köras kostar pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i Azure Portal med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Om du använde en kostnadsfri tjänst bör du komma ihåg att du är begränsad till tre index, indexerare och datakällor. Du kan ta bort enskilda objekt i Azure Portal för att hålla dig under gränsen.
Gå vidare
Du kan skapa kunskapsuppsättningar med hjälp av Azure Portal, .NET SDK eller REST API. Om du vill veta mer kan du prova REST-API:et med hjälp av en REST-klient och fler exempeldata.