Beräkna och hantera kapaciteten för en söktjänst
I Azure AI Search baseras kapaciteten på repliker och partitioner som kan skalas till din arbetsbelastning. Repliker är kopior av sökmotorn. Partitioner är lagringsenheter. Varje ny söktjänst börjar med en var, men du kan lägga till eller ta bort repliker och partitioner oberoende av varandra för att hantera fluktuerande arbetsbelastningar. Om du lägger till kapacitet ökar kostnaden för att köra en söktjänst.
De fysiska egenskaperna för repliker och partitioner, till exempel bearbetningshastighet och disk-I/O, varierar beroende på tjänstnivå. I en standardsöktjänst är replikerna och partitionerna snabbare och större än för en grundläggande tjänst.
Att ändra kapacitet är inte omedelbart. Det kan ta upp till en timme att beställa eller inaktivera partitioner, särskilt för tjänster med stora mängder data.
När du skalar en söktjänst kan du välja mellan följande verktyg och metoder:
Kommentar
Partitioner med högre kapacitet är tillgängliga med samma faktureringshastighet för nyare tjänster som skapats efter april och maj 2024. Mer information finns i Tjänstbegränsningar för uppgraderingar av partitionsstorlek.
Begrepp: sökenheter, repliker, partitioner
Kapaciteten uttrycks i sökenheter som kan allokeras i kombinationer av partitioner och repliker.
| Begrepp | Definition |
|---|---|
| Sökenhet | En enda ökning av den totala tillgängliga kapaciteten (36 enheter). Minst en enhet krävs för att köra tjänsten. Det första replik- och partitionsparet är den första sökenheten. Varje extra instans av en replik eller partition förbrukar dock en extra sökenhet. Du börjar till exempel med en replik och partition (en sökenhet), lägger till en andra replik, du använder nu två sökenheter. En sökenhet är också faktureringsenheten för en Azure AI-tjänsten Search. |
| Replik | Instanser av söktjänsten, som främst används för att belastningsutjämning av frågeåtgärder. Varje replik är värd för en kopia av ett index. Om du allokerar tre repliker har du tre kopior av ett index som är tillgängligt för service av frågebegäranden. |
| Partition | Fysisk lagring och I/O för läs-/skrivåtgärder (till exempel vid återskapande eller uppdatering av ett index). Varje partition har en del av det totala indexet. Om du allokerar tre partitioner delas ditt index upp i tredjedelar. |
Granska tabellen partitioner och repliker för möjliga kombinationer som håller sig under gränsen på 36 enheter.
När kapacitet ska läggas till
Inledningsvis allokeras en tjänst en minimal resursnivå som består av en partition och en replik. Den nivå du väljer avgör partitionens storlek och hastighet, och varje nivå är optimerad kring en uppsättning egenskaper som passar olika scenarier. Om du väljer en högre nivå kan du behöva färre partitioner än om du använder S1. En av de frågor du behöver besvara via självstyrd testning är om en större och dyrare partition ger bättre prestanda än två billigare partitioner på en tjänst som etableras på en lägre nivå.
En enskild tjänst måste ha tillräckligt med resurser för att hantera alla arbetsbelastningar (indexering och frågor). Ingen av arbetsbelastningarna körs i bakgrunden. Du kan schemalägga indexering för tider då frågebegäranden är naturligt mindre frekventa, men tjänsten prioriterar annars inte en aktivitet framför en annan. Dessutom jämnar en viss mängd redundans ut frågeprestanda när tjänster eller noder uppdateras internt.
Några riktlinjer för att avgöra om kapacitet ska läggas till är:
- Uppfylla kriterierna för hög tillgänglighet för serviceavtal
- Frekvensen för HTTP 503-fel ökar
- Stora frågevolymer förväntas
Som en allmän regel tenderar sökprogram att behöva fler repliker än partitioner, särskilt när tjänståtgärderna är partiska mot frågearbetsbelastningar. Varje replik är en kopia av ditt index, vilket gör att tjänsten kan lastbalansera begäranden mot flera kopior. All belastningsutjämning och replikering av ett index hanteras av Azure AI Search och du kan ändra antalet repliker som allokerats för din tjänst när som helst. Du kan allokera upp till 12 repliker i en Standard-söktjänst och 3 repliker i en grundläggande söktjänst. Replikallokering kan göras antingen från Azure Portal eller något av de programmatiska alternativen.
Extra partitioner är användbara för intensiva indexeringsarbetsbelastningar. Extra partitioner sprider läs-/skrivåtgärder över ett större antal beräkningsresurser.
Slutligen tar det längre tid att köra frågor mot större index. Därför kan det hända att varje inkrementell ökning av partitioner kräver en mindre men proportionell ökning av repliker. Komplexiteten i dina frågor och frågevolymen tar hänsyn till hur snabbt frågekörningen vänds.
Kommentar
Om du lägger till fler repliker eller partitioner ökar kostnaden för att köra tjänsten och kan medföra små variationer i hur resultaten sorteras. Kontrollera priskalkylatorn för att förstå faktureringskonsekvenserna av att lägga till fler noder. Diagrammet nedan kan hjälpa dig att korsreferensa antalet sökenheter som krävs för en viss konfiguration. Mer information om hur ytterligare repliker påverkar frågebearbetning finns i Beställa resultat.
Så här ändrar du kapacitet
Om du vill öka eller minska söktjänstens kapacitet lägger du till eller tar bort partitioner och repliker.
Logga in på Azure Portal och välj söktjänsten.
Under Inställningar öppnar du sidan Skala för att ändra repliker och partitioner.
Följande skärmbild visar en Standard-tjänst som har etablerats med en replik och partition. Formeln längst ned anger hur många sökenheter som används (1). Om enhetspriset var 100 USD (inte ett verkligt pris) skulle den månatliga kostnaden för att köra den här tjänsten vara 100 USD i genomsnitt.
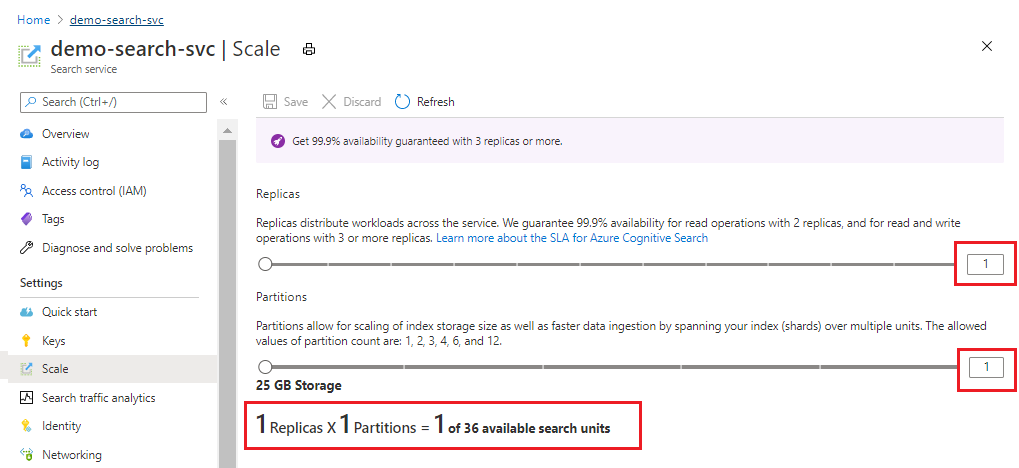
Använd skjutreglaget för att öka eller minska antalet partitioner. Välj Spara.
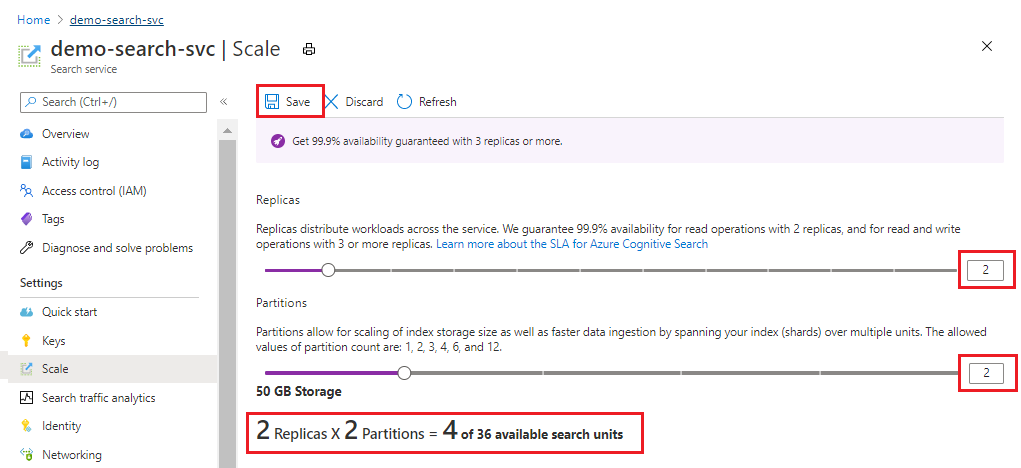
Det här exemplet lägger till en andra replik och partition. Observera antalet sökenheter. det är nu fyra eftersom faktureringsformeln är repliker multiplicerat med partitioner (2 x 2). En fördubbling av kapaciteten mer än fördubblar kostnaden för att köra tjänsten. Om kostnaden för sökenheten var 100 USD skulle den nya månadsfakturan nu vara 400 USD.
Information om aktuella enhetskostnader för varje nivå finns på sidan Prissättning.
När du har sparat kan du kontrollera aviseringar för att bekräfta att åtgärden har slutförts.
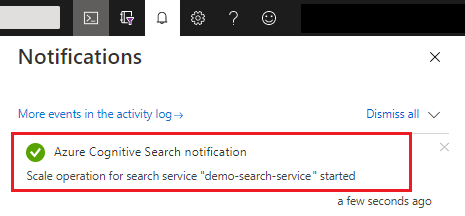
Det kan ta allt från 15 minuter upp till flera timmar att slutföra kapacitetsändringar. Du kan inte avbryta när processen har startats och det inte finns någon realtidsövervakning för replik- och partitionsjusteringar. Följande meddelande förblir dock synligt när ändringar pågår.

Kommentar
När en tjänst har etablerats kan den inte uppgraderas till en högre nivå. Du måste skapa en söktjänst på den nya nivån och läsa in indexen igen. Mer information om tjänstetablering finns i Skapa en Azure AI-tjänsten Search i portalen.
Så här hanteras skalningsbegäranden
När en skalningsbegäran har mottagits:
- Kontrollerar om begäran är giltig.
- Börjar säkerhetskopiera data och systeminformation.
- Kontrollerar om tjänsten redan är i etableringstillstånd (för närvarande lägger till eller eliminerar du antingen repliker eller partitioner).
- Startar etablering.
Det kan ta så lite som 15 minuter eller en bra bit över en timme att skala en tjänst, beroende på tjänstens storlek och begärans omfattning. Säkerhetskopieringen kan ta flera minuter, beroende på mängden data och antalet partitioner och repliker.
Stegen ovan är inte helt i följd. Systemet börjar till exempel etablera när det kan göra det på ett säkert sätt, vilket kan vara när säkerhetskopieringen avvecklas.
Fel vid skalning
Felmeddelandet "Tjänstuppdateringsåtgärder tillåts inte just nu eftersom vi bearbetar en tidigare begäran" orsakas av att en begäran om nedskalning eller uppskalning upprepas när tjänsten redan bearbetar en tidigare begäran.
Lös det här felet genom att kontrollera tjänstens status för att verifiera etableringsstatus:
- Använd REST API för hantering, Azure PowerShell eller Azure CLI för att hämta tjänststatus.
- Anropa Get Service (REST) eller motsvarande för PowerShell eller CLI.
- Kontrollera svaret för "provisioningState": "provisioning"
Om statusen är "Etablering" väntar du tills begäran har slutförts. Statusen ska vara antingen "Lyckades" eller "Misslyckades" innan en annan begäran görs. Det finns ingen status för säkerhetskopiering. Säkerhetskopiering är en intern åtgärd och det är osannolikt att det är en faktor i några avbrott i en skalningsövning.
Om söktjänsten verkar vara stoppad i etableringstillstånd kontrollerar du om det finns överblivna index som inte går att använda, utan frågevolymer och inga indexuppdateringar. Ett oanvändbart index kan blockera ändringar i tjänstkapaciteten. Leta särskilt efter index som är CMK-krypterade, vars nycklar inte längre är giltiga. Du bör antingen ta bort indexet eller återställa nycklarna så att indexet är online igen och avblockera skalningsåtgärden.
Kombinationer av partitioner och repliker
Följande diagram gäller för standardnivån och högre. Den visar alla möjliga kombinationer av partitioner och repliker, med högst 36 sökenheter per tjänst.
| 1 partition | 2 partitioner | 3 partitioner | 4 partitioner | 6 partitioner | 12 partitioner | |
|---|---|---|---|---|---|---|
| 1 replik | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 repliker | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 repliker | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 repliker | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | Ej tillämpligt |
| 5 repliker | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | Ej tillämpligt |
| 6 repliker | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | Ej tillämpligt |
| 12 repliker | 12 SU | 24 SU | 36 SU | Saknas | Saknas | Saknas |
Grundläggande söktjänster har lägre antal sökenheter.
På söktjänster som skapats före den 3 april 2024 kan en grundläggande söktjänst ha exakt en partition och upp till tre repliker, för en maximal gräns på tre SU:er. Den enda justerbara resursen är repliker.
På söktjänster som skapats efter den 3 april 2024 i regioner som stöds kan grundläggande tjänster ha upp till tre partitioner och tre repliker. Den maximala SU-gränsen är nio för att stödja ett fullständigt komplement av partitioner och repliker.
För söktjänster på valfri fakturerbar nivå, oavsett skapandedatum, behöver du minst två repliker för hög tillgänglighet i frågor.
För faktureringspriser per nivå och valuta, se prissättningssidan för Azure AI Search.
Beräkna kapacitet med hjälp av en fakturerbar nivå
Lagringsbehov bestäms av storleken på de index som du förväntar dig att skapa. Det finns inga solida heuristiker eller generaliteter som hjälper till med uppskattningar. Det enda sättet att fastställa storleken på ett index är att skapa ett. Storleken baseras på tokenisering och inbäddningar, och om du aktiverar förslagsgivare, filtrering och sortering, eller kan dra nytta av vektorkomprimering.
Vi rekommenderar att du beräknar på en fakturerbar nivå, Basic eller senare. Den kostnadsfria nivån körs på fysiska resurser som delas av flera kunder och omfattas av faktorer som ligger utanför din kontroll. Endast de dedikerade resurserna för en fakturerbar söktjänst kan hantera större samplings- och bearbetningstider för mer realistiska uppskattningar av indexkvantitet, storlek och frågevolymer under utvecklingen.
Granska tjänstbegränsningarna på varje nivå för att avgöra om lägre nivåer kan stödja det antal index du behöver. Fundera på om du behöver flera kopior av ett index för aktiv utveckling, testning och produktion.
En söktjänst omfattas av objektgränser (maximalt antal index, indexerare, kompetensuppsättningar osv.) och lagringsgränser. Den gräns som uppnås först är den effektiva gränsen.
Skapa en tjänst på en fakturerbar nivå. Nivåerna är optimerade för vissa arbetsbelastningar. Lagringsoptimerad nivå har till exempel en gräns på 10 index eftersom den är utformad för att stödja ett lågt antal mycket stora index.
Börja lågt, på Basic eller S1, om du inte är säker på den planerade belastningen.
Börja högt, på S2 eller till och med S3, om testningen omfattar storskalig indexering och frågebelastningar.
Börja med Lagringsoptimerad, vid L1 eller L2, om du indexerar en stor mängd data och frågebelastningen är relativt låg, som med ett internt affärsprogram.
Skapa ett första index för att avgöra hur källdata översätts till ett index. Det här är det enda sättet att beräkna indexstorleken. Attribut för fältdefinitionerna påverkar fysiska lagringskrav:
För nyckelordssökning ökar indexstorleken genom att markera fält som filterbara och sorterbara.
För vektorsökning kan du ange parametrar för att minska lagringen.
Övervaka lagring, tjänstbegränsningar, frågevolym och svarstid i portalen. Portalen visar frågor per sekund, begränsade frågor och svarstid för sökning. Alla dessa värden kan hjälpa dig att avgöra om du har valt rätt nivå.
Lägg till repliker för hög tillgänglighet eller för att minska långsamma frågeprestanda.
Det finns inga riktlinjer för hur många repliker som behövs för att hantera frågebelastningar. Frågeprestanda beror på frågans komplexitet och konkurrerande arbetsbelastningar. Även om du lägger till repliker ger det bättre prestanda, men resultatet är inte strikt linjärt: att lägga till tre repliker garanterar inte tre dataflöden. Information om hur du beräknar QPS för din lösning finns i Analysera prestandaoch Övervaka frågor.
För ett inverterat index bestäms storlek och komplexitet av innehåll, inte nödvändigtvis av mängden data som du matar in i det. En stor datakälla med hög redundans kan resultera i ett mindre index än en mindre datauppsättning som innehåller mycket variabelt innehåll. Därför är det sällan möjligt att härleda indexstorlek baserat på storleken på den ursprungliga datamängden.
Lagringskraven kan blåsas upp om du inkluderar data som aldrig kommer att sökas igenom. Helst innehåller dokument endast de data som du behöver för sökupplevelsen.
Överväganden för serviceavtal
Funktionerna på den kostnadsfria nivån och förhandsversionen omfattas inte av serviceavtal (SLA). För alla fakturerbara nivåer träder serviceavtal i kraft när du etablerar tillräcklig redundans för din tjänst.
Två eller flera repliker uppfyller serviceavtalen för frågor (läs).
Tre eller fler repliker uppfyller serviceavtalen för frågor och indexering (läs-och-skriv).
Antalet partitioner påverkar inte serviceavtal.