Partitionera tillförlitliga Service Fabric-tjänster
Den här artikeln ger en introduktion till de grundläggande begreppen för partitionering av tillförlitliga Azure Service Fabric-tjänster. Partitionering möjliggör datalagring på de lokala datorerna så att data och beräkning kan skalas tillsammans.
Dricks
Ett fullständigt exempel på koden i den här artikeln finns på GitHub.
Partitionering
Partitionering är inte unikt för Service Fabric. I själva verket är det ett kärnmönster för att skapa skalbara tjänster. I vidare mening kan vi tänka på partitionering som ett begrepp för att dela upp tillstånd (data) och beräkning i mindre tillgängliga enheter för att förbättra skalbarhet och prestanda. En välkänd form av partitionering är datapartitionering, även kallat horisontell partitionering.
Tillståndslösa tjänster för Partition Service Fabric
För tillståndslösa tjänster kan du tänka på att en partition är en logisk enhet som innehåller en eller flera instanser av en tjänst. Bild 1 visar en tillståndslös tjänst med fem instanser fördelade över ett kluster med hjälp av en partition.
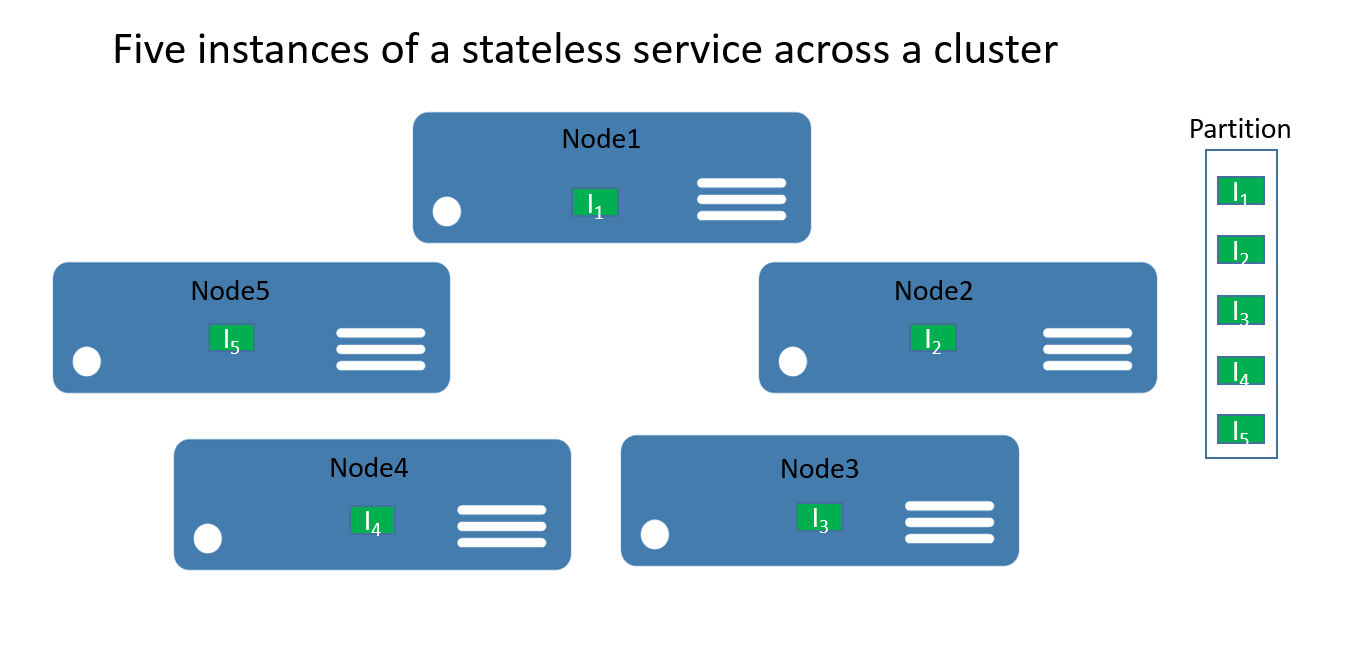
Det finns egentligen två typer av tillståndslösa tjänstlösningar. Den första är en tjänst som bevarar sitt tillstånd externt, till exempel i en databas i Azure SQL Database (till exempel en webbplats som lagrar sessionsinformation och data). Den andra är beräkningstjänster (t.ex. en kalkylator eller miniatyrbild) som inte hanterar något beständigt tillstånd.
I båda fallen är partitionering av en tillståndslös tjänst ett mycket sällsynt scenario – skalbarhet och tillgänglighet uppnås normalt genom att lägga till fler instanser. Den enda gången du vill överväga flera partitioner för tillståndslösa tjänstinstanser är när du behöver uppfylla särskilda routningsbegäranden.
Tänk dig till exempel ett fall där användare med ID:t i ett visst intervall endast ska hanteras av en viss tjänstinstans. Ett annat exempel på när du kan partitionera en tillståndslös tjänst är när du har en verkligt partitionerad serverdel (t.ex. en fragmenterad databas i SQL Database) och du vill styra vilken tjänstinstans som ska skriva till databasens shard – eller utföra annat förberedelsearbete inom den tillståndslösa tjänsten som kräver samma partitioneringsinformation som används i serverdelen. Dessa typer av scenarier kan också lösas på olika sätt och kräver inte nödvändigtvis tjänstpartitionering.
Resten av den här genomgången fokuserar på tillståndskänsliga tjänster.
Tillståndskänsliga tjänster för Partition Service Fabric
Service Fabric gör det enkelt att utveckla skalbara tillståndskänsliga tjänster genom att erbjuda ett förstklassigt sätt att partitionera tillstånd (data). Konceptuellt kan du tänka på en partition av en tillståndskänslig tjänst som en skalningsenhet som är mycket tillförlitlig via repliker som distribueras och balanseras över noderna i ett kluster.
Partitionering i samband med tillståndskänsliga Service Fabric-tjänster syftar på processen att fastställa att en viss tjänstpartition ansvarar för en del av tjänstens fullständiga tillstånd. (Som tidigare nämnts är en partition en uppsättning repliker). En bra sak med Service Fabric är att den placerar partitionerna på olika noder. På så sätt kan de växa till en nods resursgräns. När databehoven växer växer partitionerna och Service Fabric balanserar om partitioner mellan noder. Detta säkerställer fortsatt effektiv användning av maskinvaruresurser.
För att ge dig ett exempel, anta att du börjar med ett kluster med 5 noder och en tjänst som är konfigurerad för att ha 10 partitioner och ett mål på tre repliker. I det här fallet skulle Service Fabric balansera och distribuera replikerna över klustret – och du skulle få två primära repliker per nod. Om du nu behöver skala ut klustret till 10 noder skulle Service Fabric balansera om de primära replikerna över alla 10 noder. På samma sätt, om du skalade tillbaka till 5 noder, skulle Service Fabric balansera om alla repliker över de 5 noderna.
Bild 2 visar fördelningen av 10 partitioner före och efter skalning av klustret.
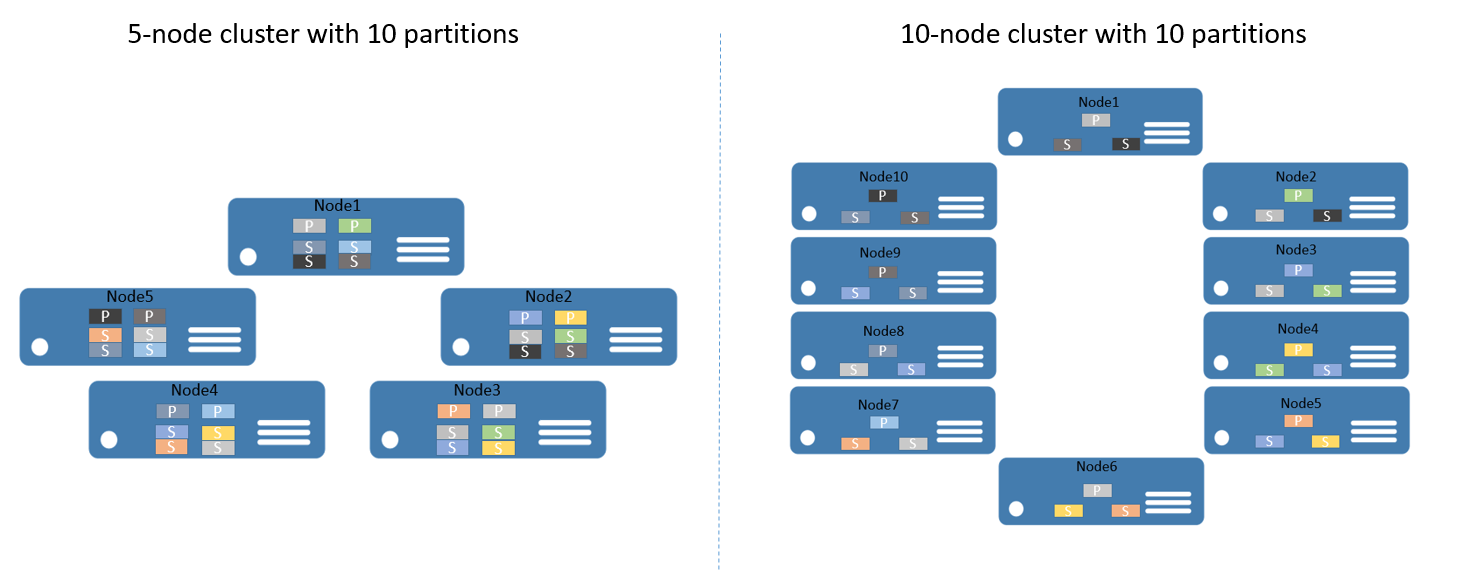
Därför uppnås utskalningen eftersom begäranden från klienter distribueras mellan datorer, programmets övergripande prestanda förbättras och konkurrensen om åtkomsten till datasegment minskar.
Planera för partitionering
Innan du implementerar en tjänst bör du alltid överväga den partitioneringsstrategi som krävs för att skala ut. Det finns olika sätt, men alla fokuserar på vad programmet behöver uppnå. I den här artikeln ska vi överväga några av de viktigaste aspekterna.
En bra metod är att tänka på strukturen för det tillstånd som måste partitioneras, som det första steget.
Låt oss ta ett enkelt exempel. Om du skulle skapa en tjänst för en landsomfattande undersökning kan du skapa en partition för varje stad i länet. Sedan kan du lagra rösterna för varje person i staden i partitionen som motsvarar den staden. Bild 3 illustrerar en uppsättning människor och den stad där de bor.
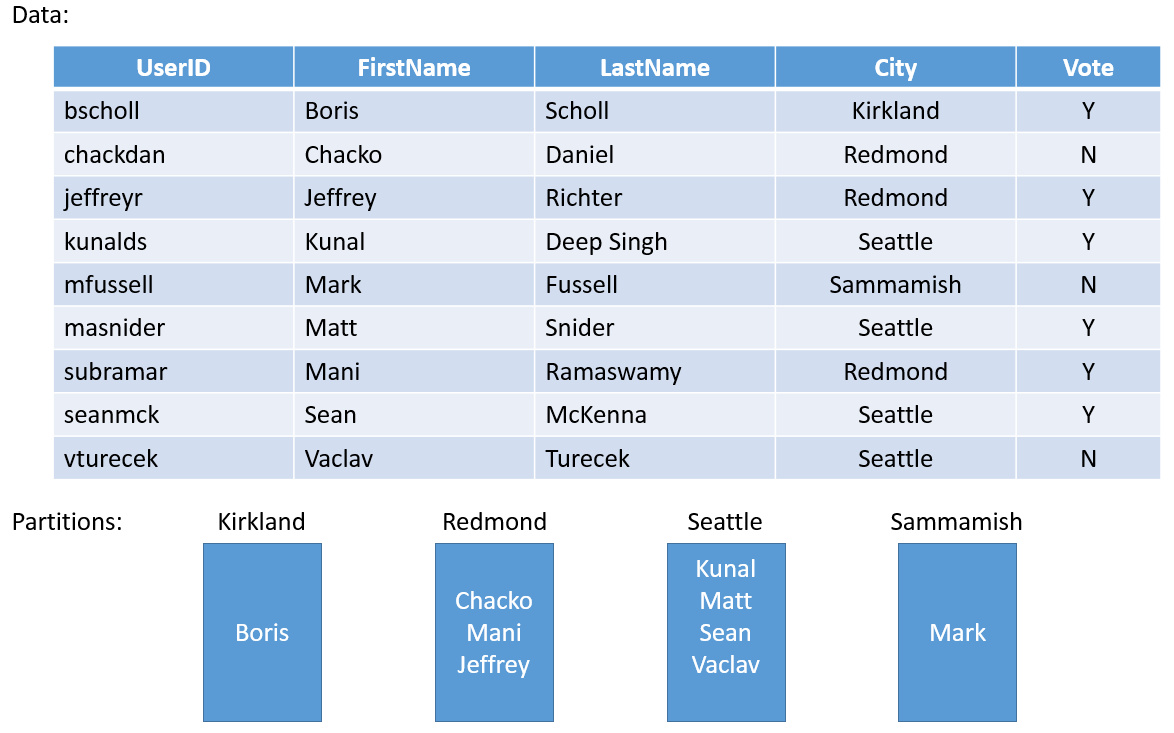
Eftersom städernas befolkning varierar kraftigt kan du få vissa partitioner som innehåller mycket data (t.ex. Seattle) och andra partitioner med mycket lite tillstånd (t.ex. Kirkland). Så vad är effekten av att ha partitioner med ojämna mängder tillstånd?
Om du tänker på exemplet igen kan du enkelt se att partitionen som innehåller rösterna för Seattle får mer trafik än Kirkland. Som standard ser Service Fabric till att det finns ungefär samma antal primära och sekundära repliker på varje nod. Så du kan få noder som innehåller repliker som hanterar mer trafik och andra som hanterar mindre trafik. Du vill helst undvika heta och kalla platser som detta i ett kluster.
För att undvika detta bör du göra två saker, från en partitioneringssynpunkt:
- Försök att partitionering tillståndet så att det är jämnt fördelat över alla partitioner.
- Rapportera inläsning från var och en av replikerna för tjänsten. (Mer information om hur du gör finns i den här artikeln om Mått och inläsning). Service Fabric ger möjlighet att rapportera belastning som förbrukas av tjänster, till exempel mängden minne eller antal poster. Baserat på de mått som rapporterats identifierar Service Fabric att vissa partitioner hanterar högre belastningar än andra och balanserar om klustret genom att flytta repliker till lämpligare noder, så att ingen nod överlag överbelastas.
Ibland kan du inte veta hur mycket data som kommer att finnas i en viss partition. Därför är en allmän rekommendation att göra båda – först genom att anta en partitioneringsstrategi som sprider data jämnt över partitionerna och sedan genom rapporteringsbelastning. Den första metoden förhindrar situationer som beskrivs i röstningsexemplet, medan den andra hjälper till att jämna ut tillfälliga skillnader i åtkomst eller belastning över tid.
En annan aspekt av partitionsplaneringen är att välja rätt antal partitioner till att börja med. Ur ett Service Fabric-perspektiv finns det inget som hindrar dig från att börja med ett högre antal partitioner än förväntat för ditt scenario. Faktum är att anta att det maximala antalet partitioner är en giltig metod.
I sällsynta fall kan det hända att du behöver fler partitioner än du ursprungligen har valt. Eftersom du inte kan ändra antalet partitioner i efterhand måste du tillämpa vissa avancerade partitionsmetoder, till exempel att skapa en ny tjänstinstans av samma tjänsttyp. Du skulle också behöva implementera viss logik på klientsidan som dirigerar begäranden till rätt tjänstinstans, baserat på kunskap på klientsidan som klientkoden måste underhålla.
Ett annat att tänka på vid partitioneringsplanering är de tillgängliga datorresurserna. Eftersom tillståndet måste nås och lagras måste du följa följande:
- Gränser för nätverksbandbredd
- Gränser för systemminne
- Gränser för disklagring
Vad händer om du stöter på resursbegränsningar i ett kluster som körs? Svaret är att du helt enkelt kan skala ut klustret för att uppfylla de nya kraven.
Guiden för kapacitetsplanering ger vägledning för hur du avgör hur många noder klustret behöver.
Kom igång med partitionering
I det här avsnittet beskrivs hur du kommer igång med att partitionera tjänsten.
Service Fabric erbjuder ett urval av tre partitionsscheman:
- Intervallpartitionering (även kallat UniformInt64Partition).
- Namngiven partitionering. Program som använder den här modellen har vanligtvis data som kan bucketas inom en begränsad uppsättning. Några vanliga exempel på datafält som används som namngivna partitionsnycklar är regioner, postnummer, kundgrupper eller andra affärsgränser.
- Singleton-partitionering. Singleton-partitioner används vanligtvis när tjänsten inte kräver någon ytterligare routning. Tillståndslösa tjänster använder till exempel det här partitioneringsschemat som standard.
Namngivna och Singleton-partitioneringsscheman är särskilda former av intervallpartitioner. Som standard använder Visual Studio-mallarna för Service Fabric intervallpartitionering, eftersom det är den vanligaste och mest användbara. Resten av den här artikeln fokuserar på det intervalldelade partitioneringsschemat.
Intervalldelade partitioneringsscheman
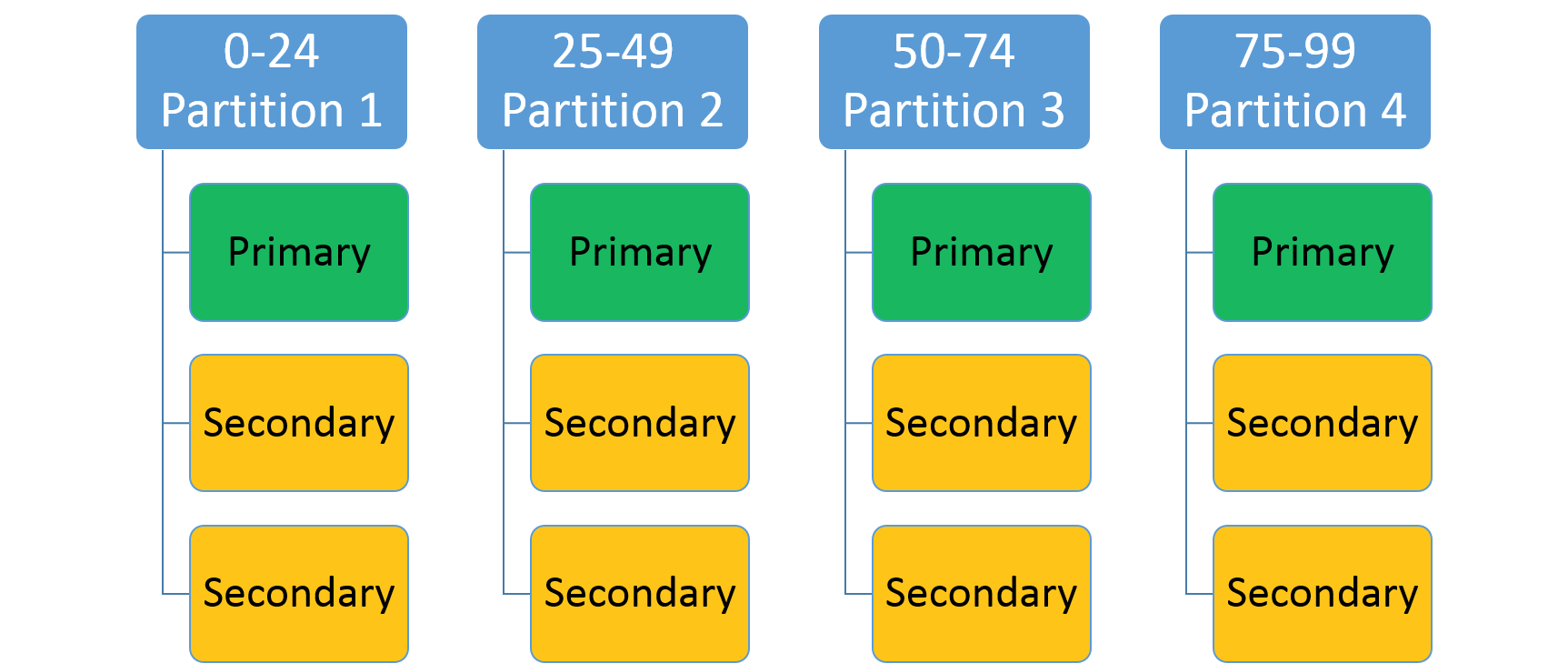
Detta används för att ange ett heltalsintervall (identifieras med låg nyckel och hög nyckel) och ett antal partitioner (n). Den skapar n-partitioner, som var och en ansvarar för ett icke-överlappande underordnat område för det övergripande partitionsnyckelintervallet. Till exempel skulle ett intervalldelade partitioneringsschema med en låg nyckel på 0, en högnyckel på 99 och antalet 4 skapa fyra partitioner, enligt nedan.
En vanlig metod är att skapa en hash baserat på en unik nyckel i datauppsättningen. Några vanliga exempel på nycklar är ett fordonsidentifieringsnummer (VIN), ett medarbetar-ID eller en unik sträng. Genom att använda den här unika nyckeln genererar du sedan en hash-kod, som modulerar nyckelintervallet, för att använda som din nyckel. Du kan ange de övre och nedre gränserna för det tillåtna nyckelintervallet.
Välj en hash-algoritm
En viktig del av hash-algoritmen är att välja din hash-algoritm. Ett övervägande är om målet är att gruppera liknande nycklar nära varandra (locality sensitive hashing)-- eller om aktiviteten ska distribueras brett över alla partitioner (distributionshashing), vilket är vanligare.
Egenskaperna hos en bra distributionshashalgoritm är att den är enkel att beräkna, att den har få kollisioner och att den distribuerar nycklarna jämnt. Ett bra exempel på en effektiv hashalgoritm är HASH-algoritmen FNV-1 .
En bra resurs för allmänna val av hashkodalgoritmer är Wikipedia-sidan på hash-funktioner.
Skapa en tillståndskänslig tjänst med flera partitioner
Nu ska vi skapa din första tillförlitliga tillståndskänsliga tjänst med flera partitioner. I det här exemplet skapar du ett mycket enkelt program där du vill lagra alla efternamn som börjar med samma bokstav i samma partition.
Innan du skriver någon kod måste du tänka på partitionerna och partitionsnycklarna. Du behöver 26 partitioner (en för varje bokstav i alfabetet), men hur är det med de låga och höga nycklarna? Eftersom vi bokstavligen vill ha en partition per bokstav kan vi använda 0 som lågnyckel och 25 som högnyckel, eftersom varje bokstav är sin egen nyckel.
Kommentar
Detta är ett förenklat scenario, eftersom fördelningen i själva verket skulle vara ojämn. Efternamn som börjar med bokstäverna "S" eller "M" är vanligare än de som börjar med "X" eller "Y".
Öppna Visual Studio>File>New>Project.
I dialogrutan Nytt projekt väljer du Service Fabric-programmet.
Anropa projektet "AlphabetPartitions".
I dialogrutan Skapa en tjänst väljer du Tillståndskänslig tjänst och kallar den "Alphabet.Processing".
Ange antalet partitioner. Öppna den ApplicationManifest.xml filen som finns i mappen ApplicationPackageRoot i alphabetpartitions-projektet och uppdatera parametern Processing_PartitionCount till 26 enligt nedan.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Du måste också uppdatera egenskaperna LowKey och HighKey för elementet StatefulService i ApplicationManifest.xml enligt nedan.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>För att tjänsten ska vara tillgänglig öppnar du en slutpunkt på en port genom att lägga till slutpunktselementet i ServiceManifest.xml (finns i mappen PackageRoot) för alphabet.processing-tjänsten enligt nedan:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Nu är tjänsten konfigurerad för att lyssna på en intern slutpunkt med 26 partitioner.
Därefter måste du åsidosätta metoden för
CreateServiceReplicaListeners()klassen Processing.Kommentar
I det här exemplet förutsätter vi att du använder en enkel HttpCommunicationListener. Mer information om tillförlitlig tjänstkommunikation finns i Modellen för tillförlitlig tjänstkommunikation.
Ett rekommenderat mönster för url:en som en replik lyssnar på är följande format:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Därför vill du konfigurera kommunikationslyssnaren så att den lyssnar på rätt slutpunkter och med det här mönstret.Flera repliker av den här tjänsten kan finnas på samma dator, så den här adressen måste vara unik för repliken. Det är därför partitions-ID + replik-ID finns i URL:en. HttpListener kan lyssna på flera adresser på samma port så länge URL-prefixet är unikt.
Det extra GUID:t finns där för ett avancerat fall där sekundära repliker också lyssnar efter skrivskyddade begäranden. När så är fallet vill du se till att en ny unik adress används när du övergår från primär till sekundär för att tvinga klienter att matcha adressen igen. '+' används som adress här så att repliken lyssnar på alla tillgängliga värdar (IP, FQDN, localhost osv.) Koden nedan visar ett exempel.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Det är också värt att notera att den publicerade URL:en skiljer sig något från prefixet för lyssnande URL. Lyssnar-URL:en ges till HttpListener. Den publicerade URL:en är den URL som publiceras till Service Fabric Naming Service, som används för tjänstidentifiering. Klienterna kommer att be om den här adressen via identifieringstjänsten. Adressen som klienterna får måste ha nodens faktiska IP- eller FQDN för att kunna ansluta. Därför måste du ersätta '+' med nodens IP- eller FQDN enligt ovan.
Det sista steget är att lägga till bearbetningslogik i tjänsten enligt nedan.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestläser värdena för frågesträngsparametern som används för att anropa partitionen och anroparAddUserAsyncför att lägga till efternamn i den tillförlitliga ordlistandictionary.Nu ska vi lägga till en tillståndslös tjänst i projektet för att se hur du kan anropa en viss partition.
Den här tjänsten fungerar som ett enkelt webbgränssnitt som accepterar efternamn som en frågesträngsparameter, bestämmer partitionsnyckeln och skickar den till alphabet.processing-tjänsten för bearbetning.
I dialogrutan Skapa en tjänst väljer du Tillståndslös tjänst och kallar den "Alphabet.Web" enligt nedan.
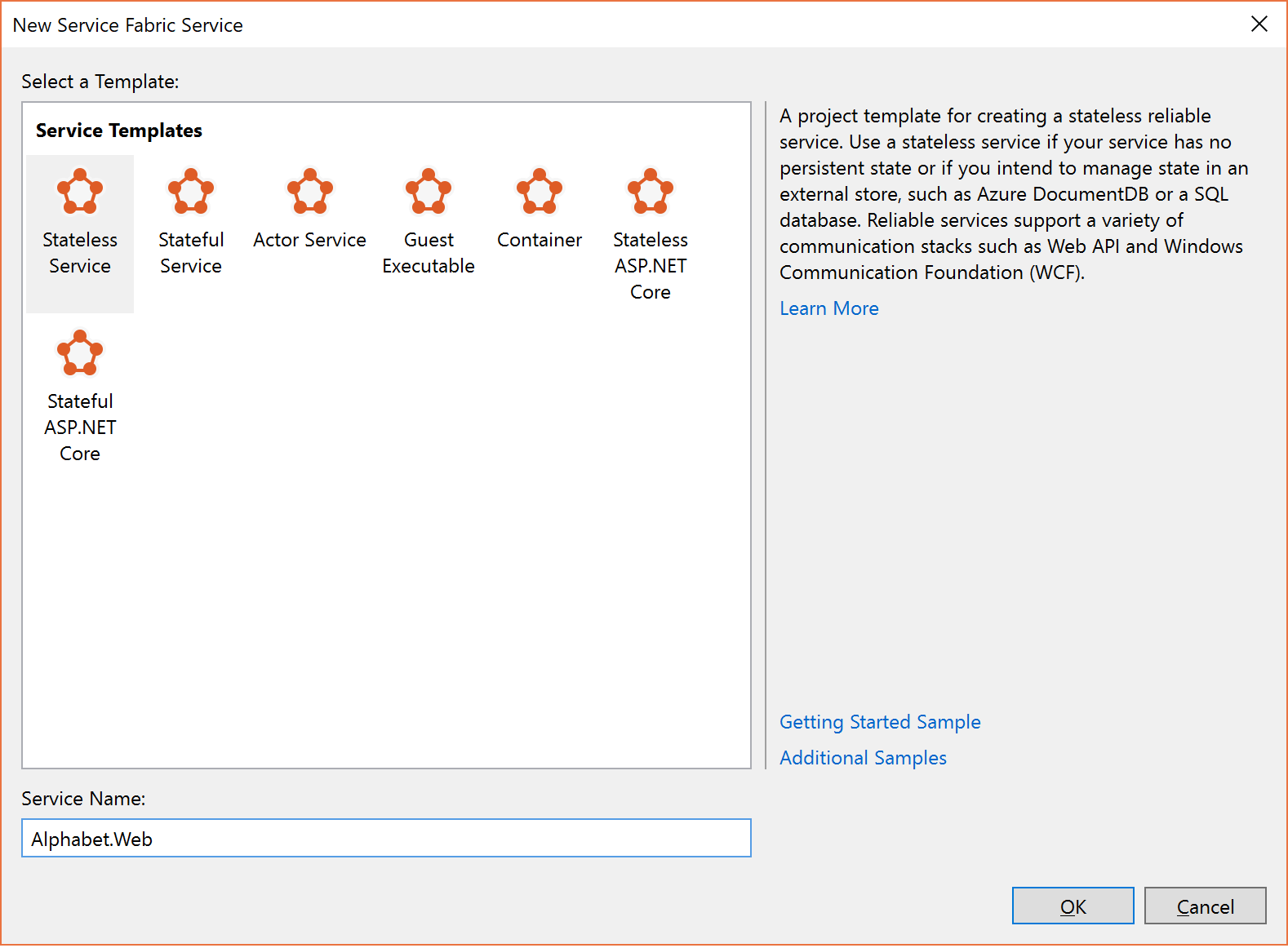 .
.Uppdatera slutpunktsinformationen i ServiceManifest.xml för tjänsten Alphabet.WebApi för att öppna en port enligt nedan.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Du måste returnera en samling ServiceInstanceListeners i klassen Web. Återigen kan du välja att implementera en enkel HttpCommunicationListener.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Nu måste du implementera bearbetningslogik. HttpCommunicationListener anropar
ProcessInputRequestnär en begäran kommer in. Så vi går vidare och lägger till koden nedan.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Vi går igenom det steg för steg. Koden läser in den första bokstaven i frågesträngsparametern
lastnamei ett tecken. Sedan avgör den partitionsnyckeln för den här bokstaven genom att subtrahera hexadecimalt värdeAfrån hexadecimalt värde för efternamnens första bokstav.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');I det här exemplet använder vi 26 partitioner med en partitionsnyckel per partition. Därefter hämtar vi tjänstpartitionen
partitionför den här nyckeln med hjälpResolveAsyncav -metoden förservicePartitionResolverobjektet.servicePartitionResolverdefinieras somprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();Metoden
ResolveAsynctar tjänstens URI, partitionsnyckeln och en annulleringstoken som parametrar. Tjänst-URI:n för bearbetningstjänsten ärfabric:/AlphabetPartitions/Processing. Därefter hämtar vi slutpunkten för partitionen.ResolvedServiceEndpoint ep = partition.GetEndpoint()Slutligen skapar vi slutpunkts-URL:en plus frågesträngen och anropar bearbetningstjänsten.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);När bearbetningen är klar skriver vi tillbaka utdata.
Det sista steget är att testa tjänsten. Visual Studio använder programparametrar för lokal distribution och molndistribution. Om du vill testa tjänsten med 26 partitioner lokalt måste du uppdatera
Local.xmlfilen i mappen ApplicationParameters i AlphabetPartitions-projektet enligt nedan:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>När du är klar med distributionen kan du kontrollera tjänsten och alla dess partitioner i Service Fabric Explorer.
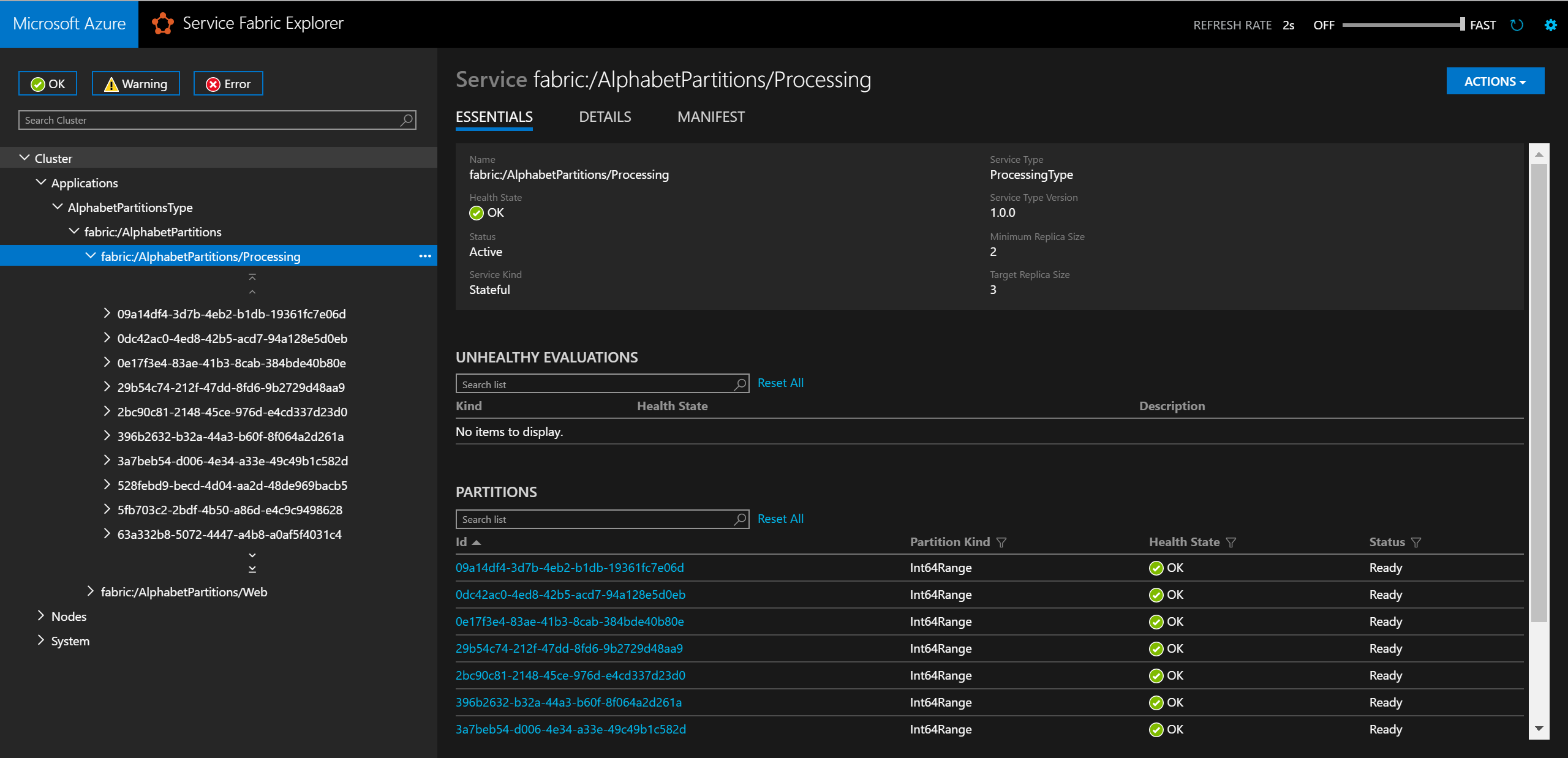
I en webbläsare kan du testa partitioneringslogik genom att ange
http://localhost:8081/?lastname=somename. Du ser att varje efternamn som börjar med samma bokstav lagras i samma partition.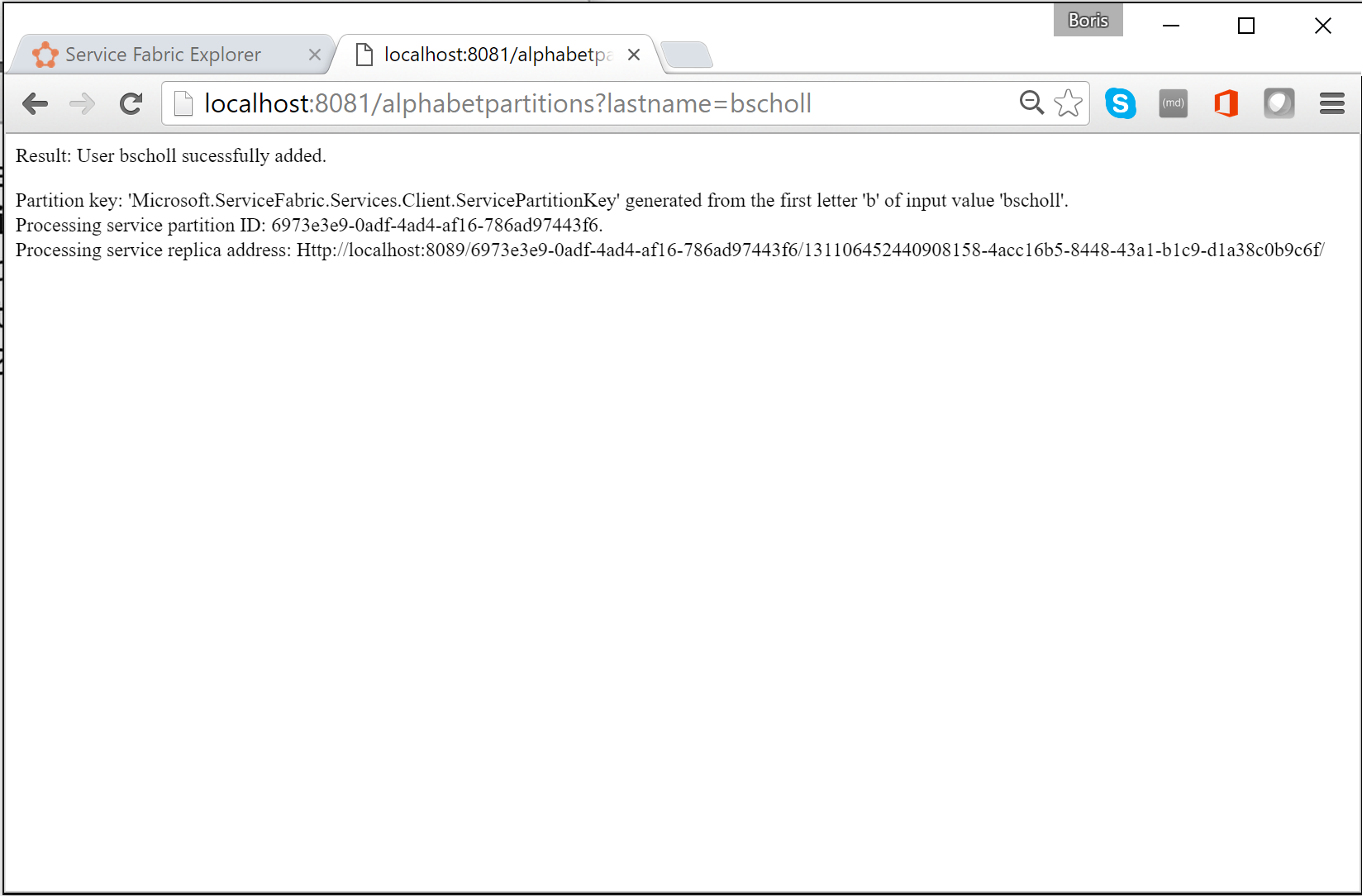
Den fullständiga lösningen för koden som används i den här artikeln finns här: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Nästa steg
Läs mer om Service Fabric-tjänster: