Apache Spark i Azure Synapse Analytics
Apache Spark är ett ramverk för parallellbearbetning som stöder minnesintern bearbetning för att öka prestanda i program för stordataanalys. Apache Spark i Azure Synapse Analytics är en av Microsofts implementeringar av Apache Spark i molnet. Med Azure Synapse kan du enkelt skapa och konfigurera en serverlös Apache Spark-pool i Azure. Spark-pooler i Azure Synapse är kompatibla med Azure Storage och Azure Data Lake Generation 2-lagring. Så du kan använda Spark-pooler för att bearbeta dina data som lagras i Azure.
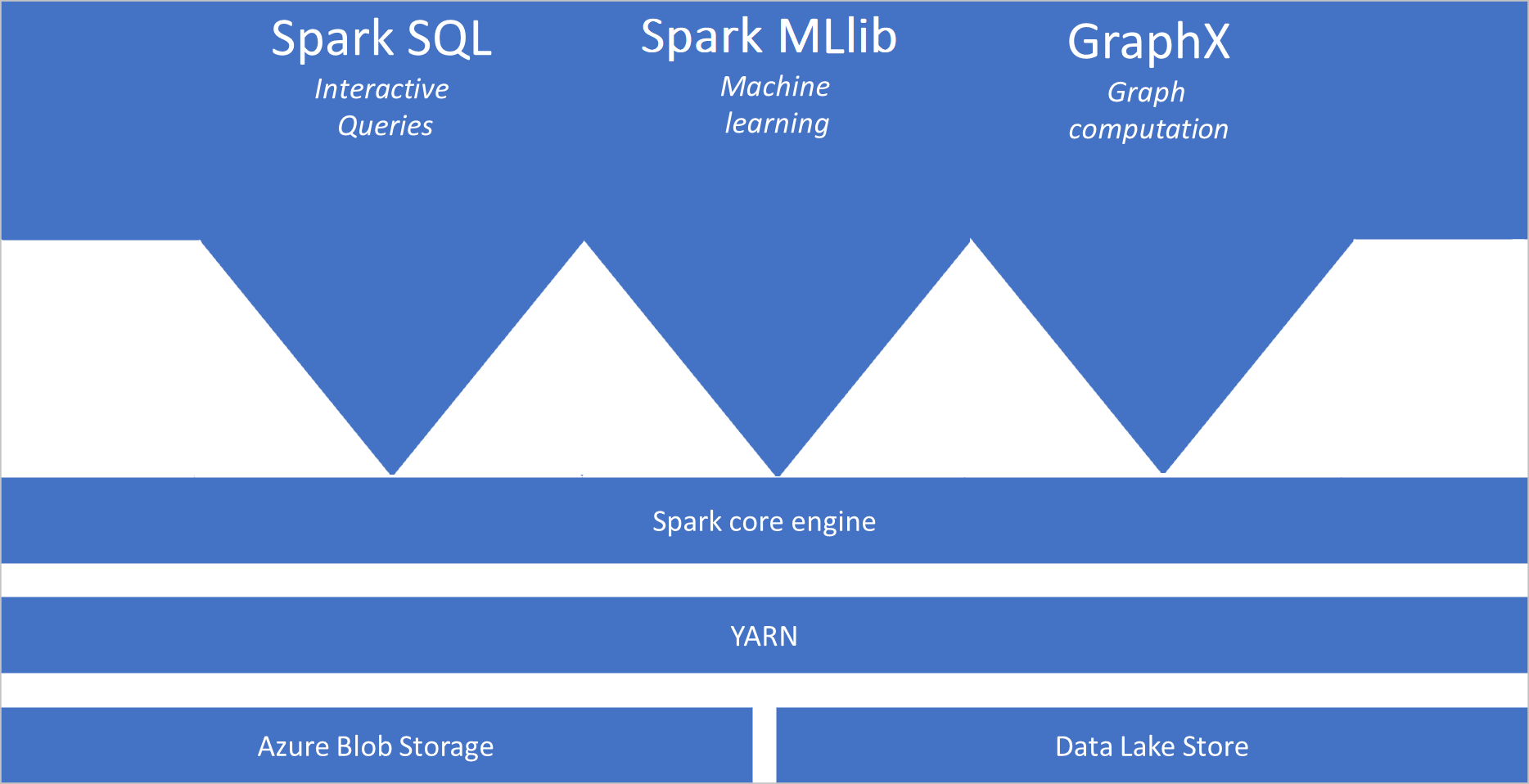
Vad är Apache Spark?
Apache Spark tillhandahåller primitiver för klusterbearbetning i minnet. Ett Spark-jobb kan läsa in och cachelagra data i minnet och köra frågor mot det upprepade gånger. Minnesintern databearbetning är mycket snabbare än diskbaserade program. Apache Spark är även integrerat med flera programmeringsspråk. På så sätt kan du bearbeta distribuerade datauppsättningar på samma sätt som lokala samlingar. Det finns inget behov av att strukturera det hela i mappnings- och reduceringsåtgärder. Du kan lära dig mer från Apache Spark för Synapse-videon.
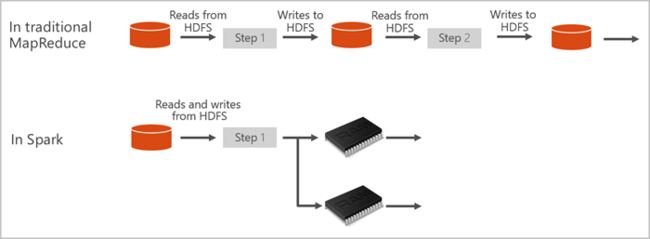
Spark-pooler i Azure Synapse erbjuder en fullständigt hanterad Spark-tjänst. Fördelarna med att skapa en Spark-pool i Azure Synapse Analytics visas här.
| Funktion | beskrivning |
|---|---|
| Hastighet och effektivitet | Spark-instanser startar på cirka 2 minuter för färre än 60 noder och cirka 5 minuter för fler än 60 noder. Instansen stängs som standard av 5 minuter efter att det senaste jobbet körs om den inte hålls vid liv av en notebook-anslutning. |
| Enkelt att skapa | Du kan skapa en ny Spark-pool i Azure Synapse på några minuter med hjälp av Azure-portalen, Azure PowerShell eller Synapse Analytics .NET SDK. Se Komma igång med Spark-pooler i Azure Synapse Analytics. |
| Användarvänlighet | Synapse Analytics innehåller en anpassad notebook-fil som härletts från nteract. Du kan de här anteckningsböckerna för interaktiv databehandling och visualisering. |
| REST API:er | Spark i Azure Synapse Analytics innehåller Apache Livy, en REST API-baserad Spark-jobbserver för fjärrsändning och övervakning av jobb. |
| Stöd för Azure Data Lake Storage Generation 2 | Spark-pooler i Azure Synapse kan använda Azure Data Lake Storage Generation 2 och BLOB Storage. Mer information om Data Lake Storage finns i Översikt över Azure Data Lake Storage. |
| Integrering med tredje parts IDEs | Azure Synapse tillhandahåller ett IDE-plugin-program för JetBrains IntelliJ IDEA som är användbart för att skapa och skicka program till en Spark-pool. |
| Förinstallerade Anaconda-bibliotek | Spark-pooler i Azure Synapse levereras med Anaconda-bibliotek förinstallerade. Anaconda tillhandahåller nära 200 bibliotek för maskininlärning, dataanalys, visualisering och andra tekniker. |
| Skalbarhet | Apache Spark i Azure Synapse-pooler kan ha automatisk skalning aktiverat, så att pooler skalas genom att lägga till eller ta bort noder efter behov. Dessutom kan Spark-pooler avslutas utan dataförlust eftersom alla data lagras i Azure Storage eller Data Lake Storage. |
Spark-pooler i Azure Synapse innehåller följande komponenter som är tillgängliga i poolerna som standard:
- Spark Core. Omfattar Spark Core, Spark SQL, GraphX och MLlib.
- Anaconda
- Apache Livy
- nteract notebook
Arkitektur för Spark-pool
Spark-program körs som oberoende uppsättningar processer i en pool, koordinerade av SparkContext objektet i huvudprogrammet, som kallas drivrutinsprogrammet.
SparkContext Kan ansluta till klusterhanteraren, som allokerar resurser mellan program. Klusterhanteraren är Apache Hadoop YARN. När spark har anslutits hämtas köre på noder i poolen, vilket är processer som kör beräkningar och lagrar data för ditt program. Därefter skickar den programkoden, som definieras av JAR- eller Python-filer som skickas till SparkContext, till körarna. Slutligen SparkContext skickar du uppgifter till de utförare som ska köras.
Kör SparkContext användarens huvudfunktion och kör de olika parallella åtgärderna på noderna. SparkContext Sedan samlar in resultatet av åtgärderna. Noderna läser och skriver data från och till filsystemet. Noderna cachelagrar även transformerade data i minnet som Resilient Distributed Datasets (RDD).
Ansluter SparkContext till Spark-poolen och ansvarar för att konvertera ett program till en riktad acyklisk graf (DAG). Diagrammet består av enskilda uppgifter som körs inom en körprocess på noderna. Varje program får sina egna körprocesser, som håller sig uppe under hela programmet och kör uppgifter i flera trådar.
Användningsfall för Apache Spark i Azure Synapse Analytics
Spark-pooler i Azure Synapse Analytics aktiverar följande viktiga scenarier:
- Datateknik/Förberedelse av data
Apache Spark innehåller många språkfunktioner som stöder förberedelse och bearbetning av stora mängder data så att de kan göras mer värdefulla och sedan användas av andra tjänster i Azure Synapse Analytics. Detta aktiveras via flera språk (C#, Scala, PySpark, Spark SQL) och tillhandahållna bibliotek för bearbetning och anslutning.
- Machine Learning
Apache Spark levereras med MLlib, ett maskininlärningsbibliotek som bygger på Spark som du kan använda från en Spark-pool i Azure Synapse Analytics. Spark-pooler i Azure Synapse Analytics innehåller även Anaconda, en Python-distribution med en mängd olika paket för datavetenskap, inklusive maskininlärning. När detta kombineras med inbyggt stöd för notebook-filer har du en miljö där du kan skapa maskininlärningsprogram.
- Strömmande data
Synapse Spark har stöd för Spark-strukturerad strömning så länge du kör versionen av Azure Synapse Spark-körningsversionen som stöds. Alla jobb stöds för att leva i sju dagar. Detta gäller både batch- och strömningsjobb, och i allmänhet automatiserar kunderna omstartsprocessen med hjälp av Azure Functions.
Var börjar jag?
Använd följande artiklar för att lära dig mer om Apache Spark i Azure Synapse Analytics:
- Snabbstart: Skapa en Spark-pool i Azure Synapse
- Snabbstart: Skapa en Apache Spark-notebook-fil
- Självstudie: Maskininlärning med Apache Spark
Kommentar
En del av den officiella Apache Spark-dokumentationen förlitar sig på att använda Spark-konsolen, som inte är tillgänglig i Azure Synapse Spark. Använd notebook- eller IntelliJ-miljöerna i stället.
Nästa steg
Den här översikten gav en grundläggande förståelse för Apache Spark i Azure Synapse Analytics. Gå vidare till nästa artikel för att lära dig hur du skapar en Spark-pool i Azure Synapse Analytics: