SKAPA TABELL SOM SELECT (CTAS)
I den här artikeln beskrivs T-SQL-instruktionen CREATE TABLE AS SELECT (CTAS) i en dedikerad SQL-pool (tidigare SQL DW) för utveckling av lösningar. Artikeln innehåller också kodexempel.
CREATE TABLE AS SELECT
Instruktionen CREATE TABLE AS SELECT (CTAS) är en av de viktigaste T-SQL-funktionerna som är tillgängliga. CTAS är en parallell åtgärd som skapar en ny tabell baserat på utdata från en SELECT-instruktion. CTAS är det enklaste och snabbaste sättet att skapa och infoga data i en tabell med ett enda kommando.
UTVALD... INTO jämfört med CTAS
CTAS är en mer anpassningsbar version av SELECT... INTO-instruktion .
Följande är ett exempel på en enkel SELECT... IN:
SELECT *
INTO [dbo].[FactInternetSales_new]
FROM [dbo].[FactInternetSales]
UTVALD... INTO tillåter inte att du ändrar distributionsmetoden eller indextypen som en del av åtgärden. Du skapar [dbo].[FactInternetSales_new] med standarddistributionstypen ROUND_ROBIN och standardtabellstrukturen för CLUSTERED COLUMNSTORE INDEX.
Med CTAS kan du å andra sidan ange både fördelningen av tabelldata och tabellstrukturtypen. Så här konverterar du föregående exempel till CTAS:
CREATE TABLE [dbo].[FactInternetSales_new]
WITH
(
DISTRIBUTION = ROUND_ROBIN
,CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT *
FROM [dbo].[FactInternetSales];
Kommentar
Om du bara försöker ändra indexet i CTAS-åtgärden och källtabellen är hash-distribuerad behåller du samma distributionskolumn och datatyp. Detta förhindrar korsdistribution av dataförflyttningar under åtgärden, vilket är mer effektivt.
Använda CTAS för att kopiera en tabell
En av de vanligaste användningsområdena för CTAS är kanske att skapa en kopia av en tabell för att ändra DDL. Anta att du ursprungligen skapade tabellen som ROUND_ROBINoch nu vill ändra den till en tabell som distribueras i en kolumn. CTAS är hur du ändrar distributionskolumnen. Du kan också använda CTAS för att ändra partitionering, indexering eller kolumntyper.
Anta att du skapade den här tabellen genom att ange HEAP och använda standarddistributionstypen ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey int NOT NULL,
OrderDateKey int NOT NULL,
DueDateKey int NOT NULL,
ShipDateKey int NOT NULL,
CustomerKey int NOT NULL,
PromotionKey int NOT NULL,
CurrencyKey int NOT NULL,
SalesTerritoryKey int NOT NULL,
SalesOrderNumber nvarchar(20) NOT NULL,
SalesOrderLineNumber tinyint NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderQuantity smallint NOT NULL,
UnitPrice money NOT NULL,
ExtendedAmount money NOT NULL,
UnitPriceDiscountPct float NOT NULL,
DiscountAmount float NOT NULL,
ProductStandardCost money NOT NULL,
TotalProductCost money NOT NULL,
SalesAmount money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
CarrierTrackingNumber nvarchar(25),
CustomerPONumber nvarchar(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Nu vill du skapa en ny kopia av den här tabellen med en Clustered Columnstore Index, så att du kan dra nytta av prestanda för grupperade Columnstore-tabeller. Du vill också distribuera den här tabellen på ProductKey, eftersom du förväntar dig kopplingar i den här kolumnen och vill undvika dataflytt under kopplingar på ProductKey. Slutligen vill du också lägga till partitionering på OrderDateKey, så att du snabbt kan ta bort gamla data genom att släppa gamla partitioner. Här är CTAS-instruktionen som kopierar din gamla tabell till en ny tabell.
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Slutligen kan du byta namn på dina tabeller, växla i den nya tabellen och sedan släppa den gamla tabellen.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Uttryckligen tillståndsdatatyp och nullabilitet för utdata
När du migrerar kod kanske du stöter på den här typen av kodningsmönster:
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f;
Du kanske tycker att du bör migrera den här koden till CTAS, och du skulle ha rätt. Det finns dock ett dolt problem här.
Följande kod ger inte samma resultat:
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result;
Observera att kolumnen "result" vidarebefordrar datatypen och nullability-värdena för uttrycket. Att föra datatypen framåt kan leda till subtila variationer i värden om du inte är försiktig.
Prova det här exemplet:
SELECT result,result*@d
from result;
SELECT result,result*@d
from ctas_r;
Värdet som lagras för resultatet är annorlunda. Eftersom det beständiga värdet i resultatkolumnen används i andra uttryck blir felet ännu viktigare.
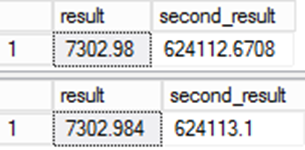
Detta är viktigt för datamigreringar. Även om den andra frågan förmodligen är mer exakt finns det ett problem. Data skulle skilja sig från källsystemet och det leder till integritetsfrågor i migreringen. Detta är ett av de sällsynta fall där det "fel" svaret faktiskt är rätt!
Anledningen till att vi ser en skillnad mellan de två resultaten beror på implicit typgjutning. I det första exemplet definierar tabellen kolumndefinitionen. När raden infogas sker en implicit typkonvertering. I det andra exemplet finns det ingen implicit typkonvertering eftersom uttrycket definierar kolumnens datatyp.
Observera också att kolumnen i det andra exemplet har definierats som en NULLable-kolumn, medan den i det första exemplet inte har det. När tabellen skapades i det första exemplet definierades kolumnens nullabilitet explicit. I det andra exemplet lämnades det till uttrycket och skulle som standard resultera i en NULL-definition.
För att lösa dessa problem måste du uttryckligen ange typkonvertering och nullbarhet i SELECT-delen av CTAS-instruktionen. Du kan inte ange de här egenskaperna i SKAPA TABELL. I följande exempel visas hur du åtgärdar koden:
DECLARE @d decimal(7,2) = 85.455
, @f float(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Notera följande:
- Du kan använda CAST eller CONVERT.
- Använd ISNULL, inte COALESCE, för att tvinga NULLability. Se följande anteckning.
- ISULL är den yttersta funktionen.
- Den andra delen av ISULL är en konstant, 0.
Kommentar
För att nullbarheten ska vara korrekt inställd är det viktigt att använda ISNULL och inte COALESCE. COALESCE är inte en deterministisk funktion, så resultatet av uttrycket kommer alltid att vara NULLable. ISULL är annorlunda. Det är deterministiskt. När den andra delen av ISNULL-funktionen därför är en konstant eller en literal blir det resulterande värdet INTE NULL.
Att säkerställa integriteten för dina beräkningar är också viktigt för växling av tabellpartition. Anta att du har den här tabellen definierad som en faktatabell:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
);
Beloppsfältet är dock ett beräknat uttryck. Det är inte en del av källdata.
Om du vill skapa en partitionerad datauppsättning kanske du vill använda följande kod:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Frågan skulle köras perfekt. Problemet uppstår när du försöker utföra partitionsväxlingen. Tabelldefinitionerna matchar inte. Om du vill att tabelldefinitionerna ska matcha ändrar du CTAS för att lägga till en ISNULL funktion för att bevara kolumnens nullatribut.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Du kan se att typkonsekvens och upprätthållande av nullabilitetsegenskaper på en CTAS är en metod för tekniktips. Det hjälper till att upprätthålla integriteten i dina beräkningar och säkerställer även att partitionsväxling är möjlig.
CTAS är en av de viktigaste instruktionerna i Synapse SQL. Se till att du verkligen förstår det. Se CTAS-dokumentationen.