Använda externa tabeller med Synapse SQL
En extern tabell pekar på data som finns i Hadoop, Azure Storage Blob eller Azure Data Lake Storage. Du kan använda externa tabeller för att läsa data från filer eller skriva data till filer i Azure Storage.
Med Synapse SQL kan du använda externa tabeller för att läsa externa data med hjälp av en dedikerad SQL-pool eller en serverlös SQL-pool.
Beroende på typen av extern datakälla kan du använda två typer av externa tabeller:
- Hadoop-externa tabeller som du kan använda för att läsa och exportera data i olika dataformat, till exempel CSV, Parquet och ORC. Hadoop-externa tabeller är tillgängliga i dedikerade SQL-pooler, men de är inte tillgängliga i serverlösa SQL-pooler.
- Interna externa tabeller som du kan använda för att läsa och exportera data i olika dataformat, till exempel CSV och Parquet. Interna externa tabeller är tillgängliga i serverlösa SQL-pooler och de är i offentlig förhandsversion i dedikerade SQL-pooler. Att skriva/exportera data med hjälp av CETAS och interna externa tabeller är endast tillgängligt i den serverlösa SQL-poolen, men inte i de dedikerade SQL-poolerna.
De viktigaste skillnaderna mellan Hadoop och interna externa tabeller:
| Extern tabelltyp | Hadoop | Inbyggd |
|---|---|---|
| Dedikerad SQL-pool | Tillgängligt | Endast Parquet-tabeller är tillgängliga i offentlig förhandsversion. |
| Serverlös SQL-pool | Inte tillgängliga | Tillgängligt |
| Format som stöds | Avgränsad/CSV, Parquet, ORC, Hive RC och RC | Serverlös SQL-pool: Avgränsad/CSV, Parquet och Delta Lake Dedikerad SQL-pool: Parquet (förhandsversion) |
| Eliminering av mapppartition | Inga | Partitionseliminering är endast tillgängligt i de partitionerade tabeller som skapats i Parquet- eller CSV-format som synkroniseras från Apache Spark-pooler. Du kan skapa externa tabeller i Parquet-partitionerade mappar, men partitioneringskolumnerna är otillgängliga och ignoreras, medan partitionseliminering inte tillämpas. Skapa inte externa tabeller i Delta Lake-mappar eftersom de inte stöds. Använd Delta-partitionerade vyer om du behöver fråga partitionerade Delta Lake-data. |
| Fileliminering (predikatnedtryckning) | Inga | Ja i serverlös SQL-pool. För strängnedtryckningen måste du använda Latin1_General_100_BIN2_UTF8 sortering på kolumnerna VARCHAR för att aktivera pushdown. Mer information om sortering finns i Sorteringstyper som stöds för Synapse SQL. |
| Anpassat format för plats | Inga | Ja, med jokertecken som /year=*/month=*/day=* för Parquet- eller CSV-format. Anpassade mappsökvägar är inte tillgängliga i Delta Lake. I den serverlösa SQL-poolen kan du också använda rekursiva jokertecken /logs/** för att referera till Parquet- eller CSV-filer i valfri undermapp under den refererade mappen. |
| Rekursiv mappsökning | Ja | Ja. I serverlösa SQL-pooler måste anges /** i slutet av platssökvägen. I dedikerad pool genomsöks mapparna alltid rekursivt. |
| Lagringsautentisering | Storage Access Key(SAK), Microsoft Entra-genomströmning, hanterad identitet, anpassad microsoft entra-identitet för program | Signatur för delad åtkomst(SAS), Microsoft Entra-genomströmning, hanterad identitet, anpassad microsoft entra-identitet för program. |
| Kolumnmappning | Ordning – kolumnerna i den externa tabelldefinitionen mappas till kolumnerna i de underliggande Parquet-filerna efter position. | Serverlös pool: efter namn. Kolumnerna i den externa tabelldefinitionen mappas till kolumnerna i de underliggande Parquet-filerna efter kolumnnamnmatchning. Dedikerad pool: ordningstalsmatchning. Kolumnerna i den externa tabelldefinitionen mappas till kolumnerna i de underliggande Parquet-filerna efter position. |
| CETAS (export/transformering) | Ja | CETAS med de interna tabellerna som mål fungerar bara i den serverlösa SQL-poolen. Du kan inte använda de dedikerade SQL-poolerna för att exportera data med hjälp av interna tabeller. |
Kommentar
De interna externa tabellerna är den rekommenderade lösningen i poolerna där de är allmänt tillgängliga. Om du behöver komma åt externa data använder du alltid de interna tabellerna i serverlösa pooler. I dedikerade pooler bör du växla till de interna tabellerna för att läsa Parquet-filer när de är i GA. Använd endast Hadoop-tabellerna om du behöver komma åt vissa typer som inte stöds i interna externa tabeller (till exempel ORC, RC) eller om den interna versionen inte är tillgänglig.
Externa tabeller i en dedikerad SQL-pool och en serverlös SQL-pool
Du kan använda externa tabeller för att:
- Fråga Azure Blob Storage och Azure Data Lake Gen2 med Transact-SQL-instruktioner.
- Lagra frågeresultat till filer i Azure Blob Storage eller Azure Data Lake Storage med CETAS.
- Importera data från Azure Blob Storage och Azure Data Lake Storage och lagra dem i en dedikerad SQL-pool (endast Hadoop-tabeller i en dedikerad pool).
Kommentar
När det används tillsammans med instruktionen CREATE TABLE AS SELECT importerar valet från en extern tabell data till en tabell i den dedikerade SQL-poolen.
Om prestanda för hadoop-externa tabeller i de dedikerade poolerna inte uppfyller dina prestandamål kan du läsa in externa data i Datawarehouse-tabellerna med copy-instruktionen.
En inläsningsguide finns i Använda PolyBase för att läsa in data från Azure Blob Storage.
Du kan skapa externa tabeller i Synapse SQL-pooler via följande steg:
- SKAPA EXTERN DATAKÄLLA för att referera till en extern Azure-lagring och ange de autentiseringsuppgifter som ska användas för att komma åt lagringen.
- SKAPA EXTERNT FILFORMAT för att beskriva formatet för CSV- eller Parquet-filer.
- SKAPA EXTERN TABELL ovanpå filerna som placeras på datakällan med samma filformat.
Eliminering av mapppartition
De interna externa tabellerna i Synapse-pooler kan ignorera de filer som placeras i mapparna som inte är relevanta för frågorna. Om dina filer lagras i en mapphierarki (till exempel - /year=2020/month=03/day=16) och värdena för year, monthoch day exponeras som kolumner, läser frågorna som innehåller filter som year=2020 filerna endast från undermapparna som placeras i year=2020 mappen. Filer och mappar som placeras i andra mappar (year=2021 eller year=2022) ignoreras i den här frågan. Den här elimineringen kallas partitionseliminering.
Elimineringen av mapppartitionen är tillgänglig i de interna externa tabeller som synkroniseras från Synapse Spark-poolerna. Om du har partitionerad datauppsättning och vill utnyttja partitionselimineringen med de externa tabeller som du skapar använder du de partitionerade vyerna i stället för de externa tabellerna.
Fileliminering
Vissa dataformat som Parquet och Delta innehåller filstatistik för varje kolumn (till exempel min/max-värden för varje kolumn). De frågor som filtrerar data läser inte filerna där de obligatoriska kolumnvärdena inte finns. Frågan utforskar först min/max-värden för kolumnerna som används i frågepredikatet för att hitta de filer som inte innehåller nödvändiga data. Dessa filer ignoreras och tas bort från frågeplanen.
Den här tekniken kallas även för push-nedtryckning av filterpredikat och kan förbättra prestandan för dina frågor. Filter-pushdown är tillgängligt i serverlösa SQL-pooler i Parquet- och Delta-format. Om du vill använda filter-pushdown för strängtyperna använder du VARCHAR-typen med Latin1_General_100_BIN2_UTF8 sortering. Mer information om sortering finns i Sorteringstyper som stöds för Synapse SQL.
Säkerhet
Användaren måste ha SELECT behörighet i en extern tabell för att kunna läsa data.
Externa tabeller får åtkomst till underliggande Azure Storage med hjälp av databasens begränsade autentiseringsuppgifter som definierats i datakällan med hjälp av följande regler:
- Datakälla utan autentiseringsuppgifter gör det möjligt för externa tabeller att komma åt offentligt tillgängliga filer i Azure Storage.
- Datakällan kan ha en autentiseringsuppgift som gör det möjligt för externa tabeller att endast komma åt filerna i Azure Storage med hjälp av SAS-token eller hanterad arbetsytasidentitet . Du kan till exempel läsa artikeln Utveckla lagringsfiler för lagringsåtkomstkontroll .
Exempel på SKAPA EXTERN DATAKÄLLA
I följande exempel skapas en extern Hadoop-datakälla i en dedikerad SQL-pool för Azure Data Lake Gen2 som pekar på New York-datauppsättningen:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
I följande exempel skapas en extern datakälla för Azure Data Lake Gen2 som pekar på den offentligt tillgängliga New York-datauppsättningen:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Exempel på SKAPA EXTERNT FILFORMAT
I följande exempel skapas ett externt filformat för census-filer:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Exempel PÅ SKAPA EXTERN TABELL
I följande exempel skapas en extern tabell. Den returnerar den första raden:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Skapa och fråga externa tabeller från en fil i Azure Data Lake
Med hjälp av Data Lake-utforskningsfunktionerna i Synapse Studio kan du nu skapa och köra frågor mot en extern tabell med hjälp av Synapse SQL-poolen med ett enkelt högerklicka på filen. Gesten med ett klick för att skapa externa tabeller från ADLS Gen2-lagringskontot stöds bara för Parquet-filer.
Förutsättningar
Du måste ha åtkomst till arbetsytan med minst åtkomstrollen
Storage Blob Data Contributortill ADLS Gen2-kontot eller åtkomstkontrollistor (ACL) som gör att du kan köra frågor mot filerna.Du måste ha minst behörighet att skapa en extern tabell och köra frågor mot externa tabeller i Synapse SQL-poolen (dedikerad eller serverlös).
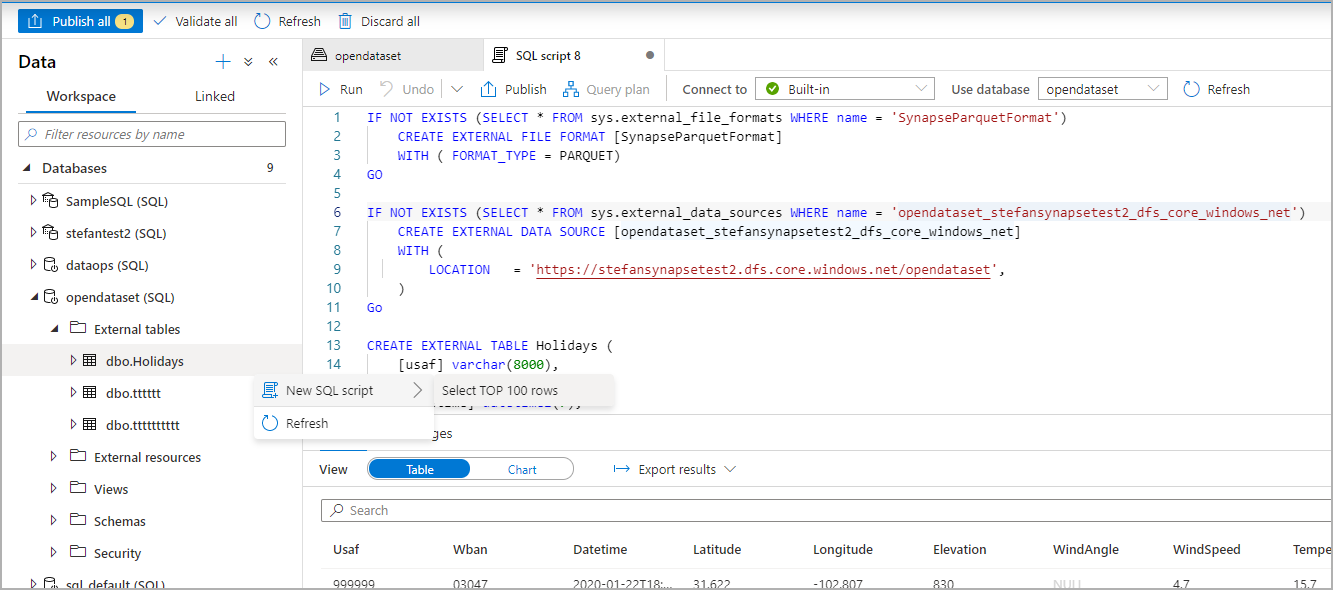
I panelen Data väljer du den fil som du vill skapa den externa tabellen från:
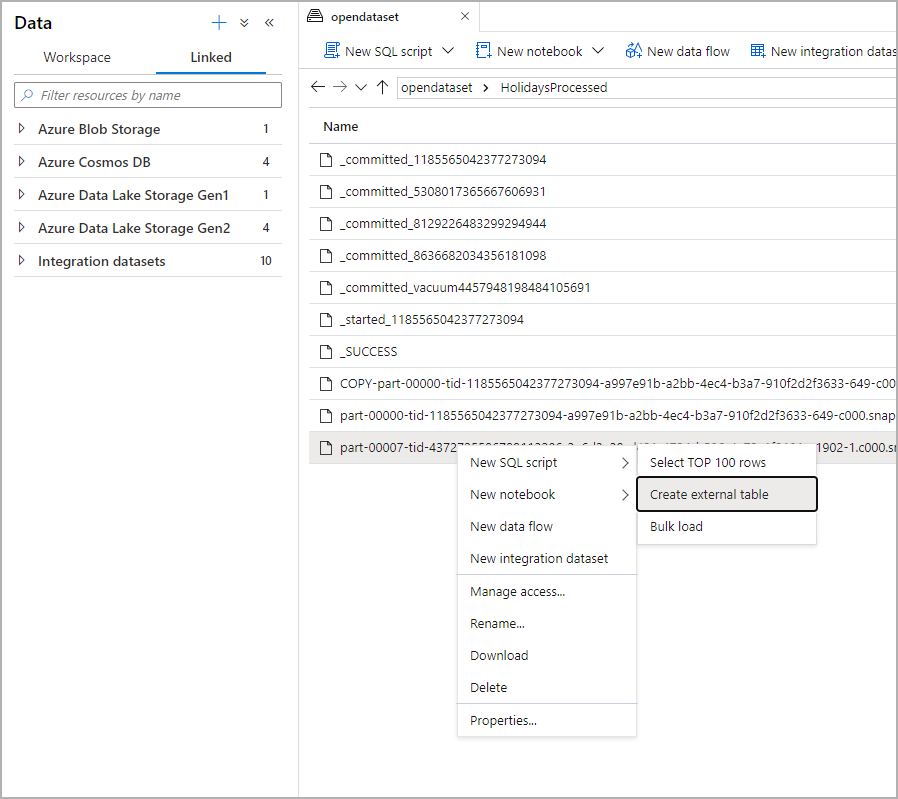
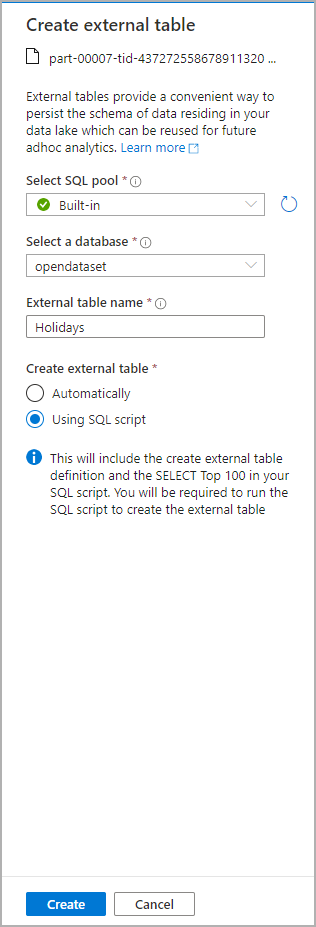
Ett dialogfönster öppnas. Välj dedikerad SQL-pool eller serverlös SQL-pool, ge tabellen ett namn och välj öppna skript:
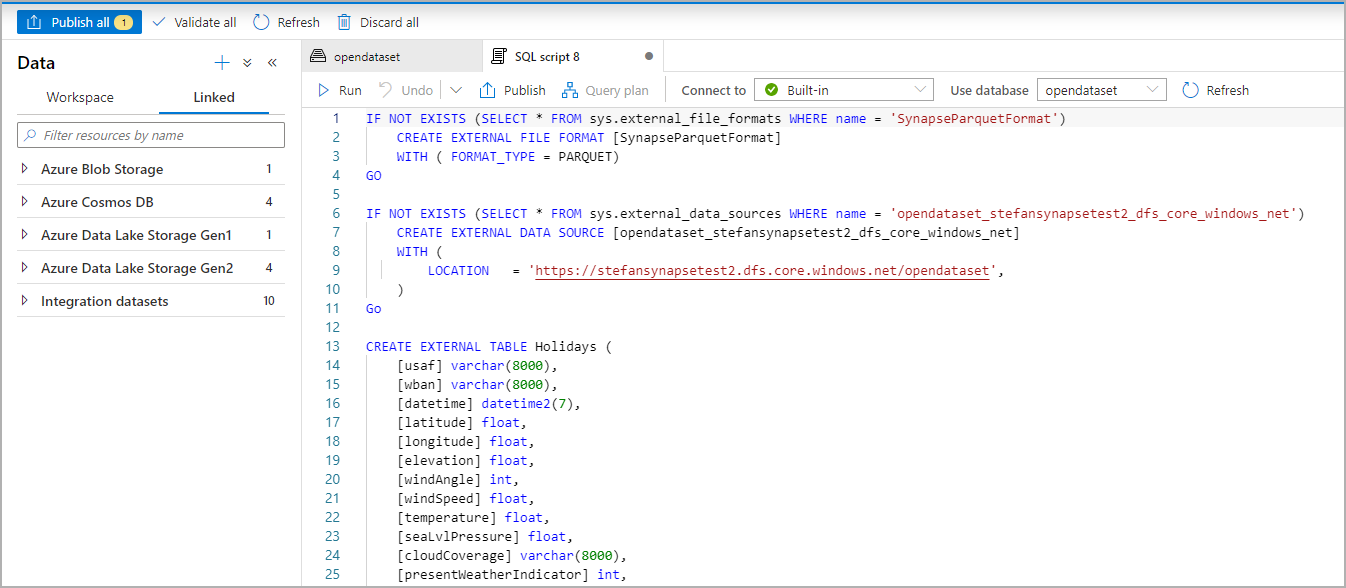
SQL-skriptet genereras automatiskt och härleder schemat från filen:
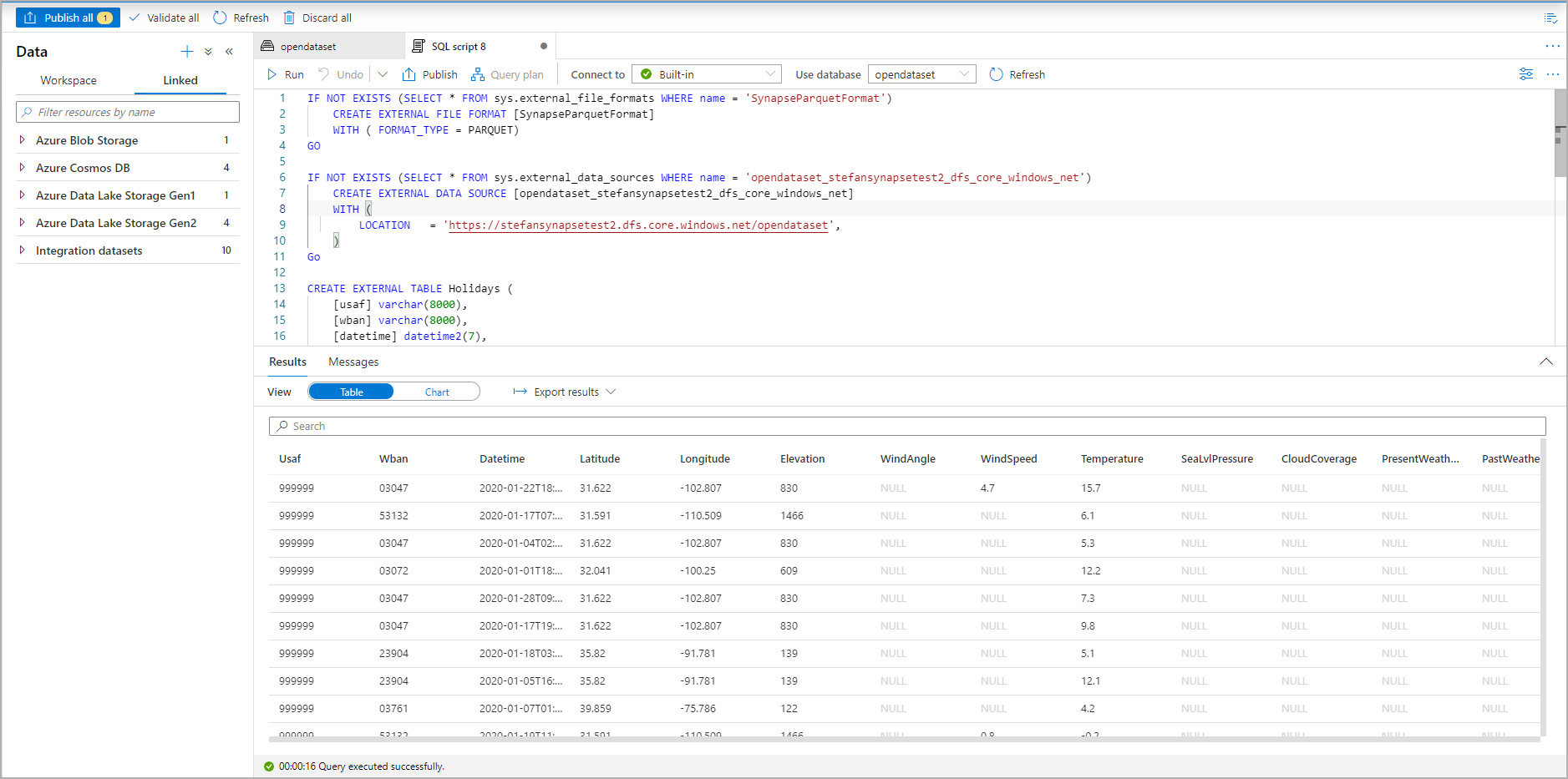
Kör skriptet. Skriptet kör automatiskt select top 100 *.:
Den externa tabellen har nu skapats, för framtida utforskning av innehållet i den här externa tabellen kan användaren fråga den direkt från fönstret Data:
Nästa steg
Se CETAS-artikeln om hur du sparar frågeresultat i en extern tabell i Azure Storage. Eller så kan du börja fråga Apache Spark om externa Azure Synapse-tabeller.