Anslut till Common Data Model-tabeller i Azure Data Lake Storage
Kommentar
Azure Active Directory har bytt namn till Microsoft Entra ID. Läs mer
Mata in data till Dynamics 365 Customer Insights - Data med ditt konto Azure Data Lake Storage med Common Data Model-tabellerna. Datainmatning kan göras fullständig eller vara inkrementell.
Förutsättningar
Azure Data Lake Storage-konton måste ha hierarkiskt namnutrymme aktiverat. Data måste lagras i ett hierarkiskt mappformat som definierar rotmappen och som har undermappar för varje tabell. Undermapparna kan ha fullständiga data eller mappar med indata.
Om du vill autentisera med Microsoft Entra-tjänstens huvudkonto, se till att det är konfigurerat i din klientorganisation. Mer information finns i Ansluta till ett Azure Data Lake Storage-konto med ett Microsoft Entra tjänsthuvudkonto.
Så här ansluter du till lagring som skyddas av brandväggar, Konfigurera Azure Private Link.
Om datasjön för närvarande har privata länkanslutningar till den måste Customer Insights - Data även ansluta med en privat länk, oavsett inställningen för nätverksåtkomst.
Den Azure Data Lake Storage som du vill ansluta och hämta data från måste finnas i samma Azure-region som Dynamics 365 Customer Insights-miljön. Anslutningar till en Common Data Model-mapp från en datasjö i en annan Azure-region stöds inte. För att känna till Azure-regionen i miljön, gå till Inställningar>System>Om i Customer Insights - Data.
Data som lagras i onlinetjänster kan lagras på en annan plats än där data behandlas eller lagras. Genom att importera eller ansluta till data som lagras på en onlinetjänst, t.ex. godkänner du att data kan överföras. Läs mer i Microsoft Trust Center.
Tjänstens huvudkonto för Customer Insights - Data måste finnas i en av följande roller för att få åtkomst till lagringskontot. Mer information finns i Bevilja behörigheter till tjänstens huvudnamn för åtkomst till lagringskontot.
- Storage Blob-dataläsare
- Storage Blob-dataägare
- Storage Blob-datadeltagare
När du ansluter till din Azure-lagring med alternativet Azure-prenumeration behöver användaren som konfigurerar datakällans anslutning åtminstone Storage Blob Data deltagarbehörigheterna på lagringskontot.
När du ansluter till din Azure-lagring med alternativet Azure-resurs behöver användaren som konfigurerar datakällans anslutning åtminstone behörighet för åtgärden Microsoft.Storage/storageAccounts/read på lagringskontot. En Azure inbyggd roll som inkluderar den här åtgärden är rollen Läsare. För att begränsa åtkomsten till bara den nödvändiga åtgärden skapa en anpassad Azure-roll som endast inkluderar denna åtgärd.
För optimala prestanda bör storleken på en partition vara 1 GB eller mindre och antalet partitionsfiler i en mapp får inte överskrida 1000.
Data i Data Lake Storage bör följa standarden för Common Data Model för lagring av dina data och ha en Common Data Model som representerar schemat för datafilerna (*.csv eller *.parquet). Manifestet måste innehålla information om tabellerna, t.ex. tabellkolumner och datatyper, samt datafilsplatsen och filtypen. Mer information om finns i Common Data Model manifest. Om manifestet inte finns kan administratörsanvändare med åtkomst till Storage Blob-dataägare eller Storage Blob-datadeltagare deltagare definiera schemat när de öppnar data.
Kommentar
Om något av fälten i .parquet-filerna har datatypen Int96 visas eventuellt inte data på sidan tabeller. Vi rekommenderar att du använder standarddatatyper, som Unix-tidsstämpelformatet (som representerar tiden som antalet sekunder sedan 1 januari 1970, vid midnatt UTC).
Begränsningar
- Customer Insights - Data stöder inte kolumner av decimaltyp med mer precision än 16.
Ansluta till Azure Data Lake Storage
Namn på dataanslutningar, datasökvägar, till exempel mappar i en container, och tabellnamn måste använda namn som börjar med en bokstav. Namnet får bara innehålla bokstäver, siffror och understreck (_). Specialtecken tillåts inte.
Gå till Data>Datakällor.
Välj Lägg till en datakälla.
Välj Common Data Model-tabeller för Azure Data Lake.

Ange ett Datakällans namn och en valfri Beskrivning. Namnet refereras till i nedströmsprocesser och det är inte möjligt att ändra det efter att ha skapat datakällan.
Välj ett av följande alternativ för Anslut lagringsutrymmet med. Mer information finns i Ansluta till ett Azure Data Lake Storage-konto med ett Microsoft Entra tjänsthuvudkonto.
- Azure-resurs: Ange Resurs-ID.
- Azure-prenumeration: Välj prenumeration och sedan resursgruppen och lagringskontot.
Kommentar
Du behöver en av följande roller till behållaren för att skapa datakällan:
- Storage Blob Data-läsare räcker för att läsa från ett lagringskonto och mata in datan i Customer Insights - Data.
- Deltagare i eller ägare av Storage Blob Data krävs om du vill redigera manifestfilerna direkt i Customer Insights - Data.
Att ha rollen på lagringskontot ger samma roll på alla dess behållare.
Välj namnet på den behållare som innehåller data och schema (filen model.json eller manifest.json) om du vill importera data från.
Obs
Inga model.json- eller manifest.json-filer som är associerade med en annan datakälla i miljön visas. Samma model.json- eller manifest.json-fil kan dock användas för datakällor i flera miljöer.
Om du vill hämta data från ett lagringskonto via en Azure Private Link väljer du Aktivera Private Link. Mer information finns i den här Private Link.
Om du vill skapa ett nytt schema går du till Skapa en ny schemafil.
Om du vill använda ett befintligt schema navigerar du till mappen som innehåller filen model.json eller manifest.cdm.json. Du kan söka i en katalog för att hitta filen.
Välj json-fil och välj Nästa. En lista över tillgängliga tabeller visas.
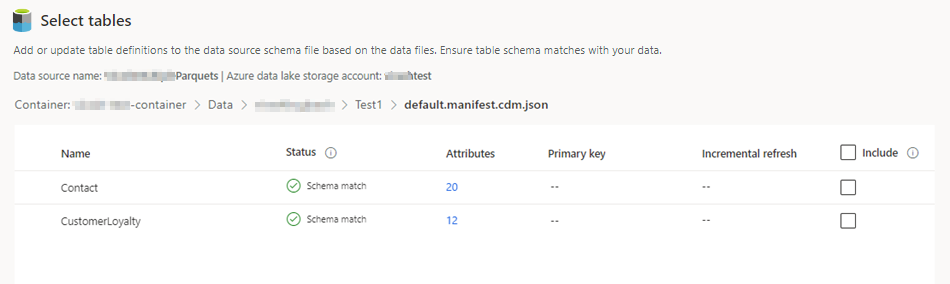
Välj vilka tabeller du vill inkludera.
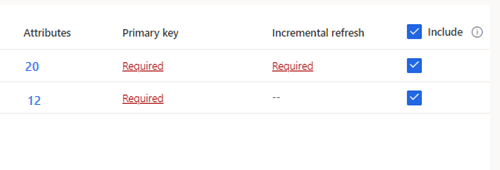
Dricks
Om du vill redigera en tabell i ett JSON-redigeringsgränssnitt väljer tabellen och sedan Redigera schemafil. Gör ändringar och välj Spara.
För valda tabeller där en primärnyckel inte har definierats visas Obligatoriska under Primärnyckel. För var och en av dessa tabeller:
- Välj Obligatorisk. Panelen Redigera tabell visas.
- Välj primärnyckel. Den primära nyckeln är ett attribut som är unikt för tabellen. För att ett attribut ska vara en giltig primär nyckel bör det inte innehålla dubblettvärden, saknade värden och null-värden. Sträng-, heltals- och GUID-datatypattribut stöds som primärnycklar.
- Alternativt kan du ändra partitionsmönstret.
- Välj Stäng när du vill spara och stänga panelen.
Välj antalet kolumner för varje inkluderad tabell. Sidan Hantera attribut visas.
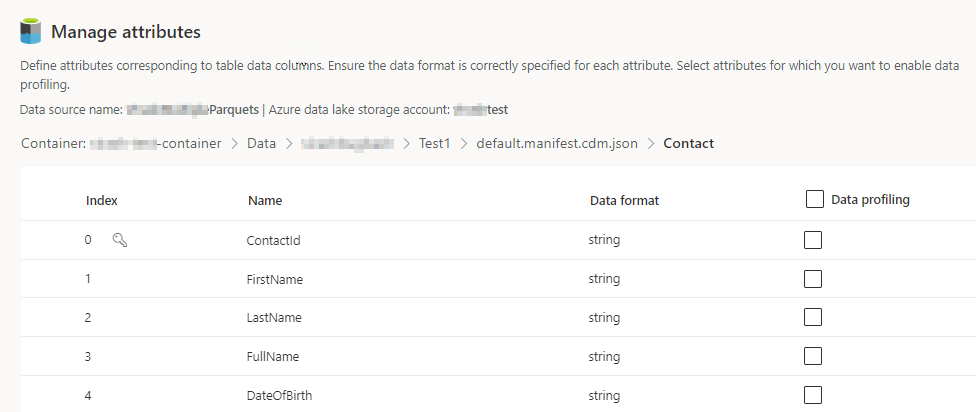
- Skapa nya kolumner, redigera eller ta bort befintliga kolumner. Du kan ändra namn, dataformat eller lägga till en semantiktyp.
- Om du vill aktivera analyser och andra funktioner väljer du Dataprofilering för hela tabellen eller för specifika kolumner. Som standard är ingen tabell aktiverad för dataprofilering.
- Välj Klart.
Välj Spara. Sidan Datakällor öppnas där den nya datakälla visas i status uppdateras.
Dricks
Det finns statusar för uppgifter och processer. De flesta processer är beroende av andra processförlopp, t.ex. datakällor och uppdateringar av dataprofiler.
Välj status för att öppna rutan Förloppsinformation och se framstegen för uppgifter. Om du vill avbryta jobbet väljer du Avbryt jobbet längst ned i fönstret.
Under varje uppgift kan du välja Visa information om du vill ha mer förloppsinformation, till exempel bearbetningstid, senaste bearbetningsdatum och eventuella tillämpliga fel och varningar för uppgiften eller processen. Välj Visa systemstatus längst ned i panelen om du vill se andra processer i systemet.

Det kan ta lång tid att läsa in data. Efter en lyckad uppdatering kan hämtade data granskas från sidan tabeller.
Skapa en ny schemafil
Välj Skapa schemafil.
Ange ett namn för filen och välj Spara.
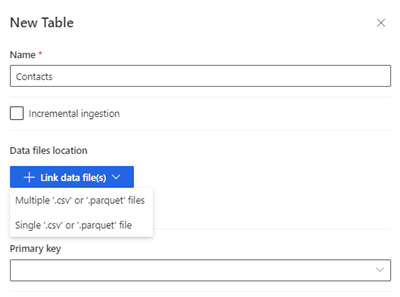
Välj Ny tabell. Panelen Ny tabell visas.
Ange tabellens namn och välj Datafilers sökväg.
- Flera .csv eller .parquet filer: Bläddra till rotmappen, välj mönstertyp och ange uttrycket.
- Enskilda .csv eller .parquet filer: Bläddra till .csv- eller .parquet-filen och välj den.
Välj Spara.
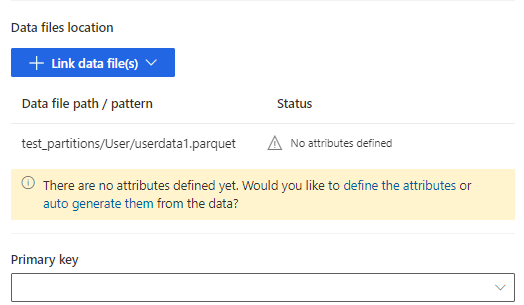
Välj definiera attributen och lägg till attributen manuellt, eller välj generera dem automatiskt. Ange ett namn, välj dataformat och valfri typ av attribut om du vill definiera attributen. För automatiskt genererade attribut:
När attributen har skapats automatiskt väljer du Granska attribut. Sidan Hantera attribut visas.
Kontrollera att dataformatet är korrekt för varje attribut.
Om du vill aktivera analyser och andra funktioner väljer du Dataprofilering för hela tabellen eller för specifika kolumner. Som standard är ingen tabell aktiverad för dataprofilering.
Välj Klart. Sidan Välj tabeller visas.
Fortsätt att lägga till tabeller och kolumner om tillämpligt.
När alla tabeller har lagts till väljer du Inkludera och ta med tabellerna i datakällsinsamlingen.
För valda tabeller där en primärnyckel inte har definierats visas Obligatoriska under Primärnyckel. För var och en av dessa tabeller:
- Välj Obligatorisk. Panelen Redigera tabell visas.
- Välj primärnyckel. Den primära nyckeln är ett attribut som är unikt för tabellen. För att ett attribut ska vara en giltig primär nyckel bör det inte innehålla dubblettvärden, saknade värden och null-värden. Sträng-, heltals- och GUID-datatypattribut stöds som primärnycklar.
- Alternativt kan du ändra partitionsmönstret.
- Välj Stäng när du vill spara och stänga panelen.
Välj Spara. Sidan Datakällor öppnas där den nya datakälla visas i status uppdateras.
Dricks
Det finns statusar för uppgifter och processer. De flesta processer är beroende av andra processförlopp, t.ex. datakällor och uppdateringar av dataprofiler.
Välj status för att öppna rutan Förloppsinformation och se framstegen för uppgifter. Om du vill avbryta jobbet väljer du Avbryt jobbet längst ned i fönstret.
Under varje uppgift kan du välja Visa information om du vill ha mer förloppsinformation, till exempel bearbetningstid, senaste bearbetningsdatum och eventuella tillämpliga fel och varningar för uppgiften eller processen. Välj Visa systemstatus längst ned i panelen om du vill se andra processer i systemet.
Det kan ta lång tid att läsa in data. Efter en lyckad uppdatering kan hämtade data granskas från sidan Data>Tabeller.
Redigera en Azure Data Lake Storage datakälla
Du kan uppdatera alternativet Anslut till ett lagringskonto med. Mer information finns i Ansluta till ett Azure Data Lake Storage-konto med ett Microsoft Entra tjänsthuvudkonto. Om du vill ansluta till en annan behållare från lagringskontot eller ändra kontonamnet måste du skapa en ny datakällaanslutning.
Gå till Data>Datakällor. Välj bredvid datakällan du vill uppdatera Redigera.
Ändra någon av följande information:
Description
Anslut ditt lagringsutrymme med och information om anslutningen. Du kan inte ändra informationen Behållare när anslutningen uppdateras.
Kommentar
En av följande roller måste tilldelas till lagringskontot eller -behållare:
- Storage Blob-dataläsare
- Storage Blob-dataägare
- Storage Blob-datadeltagare
Aktivera Private Link Om du vill hämta data från ett lagringskonto via en Azure Private Link. Mer information finns i den här Private Link.
Klicka på Nästa.
Ändra någon av följande:
Navigera till en annan model.json- eller manifest.json-fil med en annan uppsättning tabeller från behållare.
Om du vill lägga till ytterligare tabeller att mata in markerar du Ny tabell.
Om du vill ta bort alla markerade tabeller som redan finns utan beroende markerar du tabellen och Ta bort.
Viktigt!
Om det finns beroenden på den befintliga filen model.json eller manifest.json och tabelluppsättningen visas ett felmeddelande och det går inte att välja en annan model.json- eller manifest.json-fil. Ta bort dessa beroenden innan du ändrar filen model.json eller manifest.json, eller skapa en ny datakälla med den model.json- eller manifest.json-fil som du vill använda för att undvika att ta bort beroendena.
Om du vill ändra platsen för datafilen eller den primära nyckeln väljer du Redigera.
Ändra endast tabellnamnet så att det matchar tabellnamnet i .json-filen.
Kommentar
Behåll alltid tabellnamnet på samma sätt som tabellnamnet i filen model.json eller manifest.json efter inmatning. Customer Insights - Data verifierar alla tabellnamn med model.json eller manifest.json vid varje systemuppdatering. Om ett tabellnamn ändras uppstår ett fel eftersom Customer Insights - Data inte kan hitta det nya tabellnamnet i .json-filen. Om ett inmatat tabellnamn ändrades av misstag, redigera tabellnamnet så att det matchar namnet i .json-filen.
Välj kolumner om du vill lägga till eller ändra dem eller för att aktivera dataprofilering. Markera sedan Klar.
Klicka på Spara om du vill tillämpa ändringarna och återgå till sidan Datakällor.
Dricks
Det finns statusar för uppgifter och processer. De flesta processer är beroende av andra processförlopp, t.ex. datakällor och uppdateringar av dataprofiler.
Välj status för att öppna rutan Förloppsinformation och se framstegen för uppgifter. Om du vill avbryta jobbet väljer du Avbryt jobbet längst ned i fönstret.
Under varje uppgift kan du välja Visa information om du vill ha mer förloppsinformation, till exempel bearbetningstid, senaste bearbetningsdatum och eventuella tillämpliga fel och varningar för uppgiften eller processen. Välj Visa systemstatus längst ned i panelen om du vill se andra processer i systemet.