Hantera Apache Spark-bibliotek i Microsoft Fabric
Ett bibliotek är en samling förskriven kod som utvecklare kan importera för att tillhandahålla funktioner. Genom att använda bibliotek kan du spara tid och arbete genom att inte behöva skriva kod från grunden för att utföra vanliga uppgifter. Importera i stället biblioteket och använd dess funktioner och klasser för att uppnå önskad funktionalitet. Microsoft Fabric innehåller flera mekanismer som hjälper dig att hantera och använda bibliotek.
- Inbyggda bibliotek: Varje Fabric Spark-körning ger en omfattande uppsättning populära förinstallerade bibliotek. Du hittar den fullständiga inbyggda bibliotekslistan i Fabric Spark Runtime.
- Offentliga bibliotek: Offentliga bibliotek kommer från lagringsplatser som PyPI och Conda, som för närvarande stöds.
- Anpassade bibliotek: Anpassade bibliotek refererar till kod som du eller din organisation skapar. Fabric stöder dem i formaten .whl, .jar och .tar.gz . Infrastrukturresurser stöder endast .tar.gz för R-språket. För anpassade Python-bibliotek använder du formatet .whl .
Sammanfattning av metodtips för bibliotekshantering
I följande scenarier beskrivs metodtips när du använder bibliotek i Microsoft Fabric.
Scenario 1: Administratör anger standardbibliotek för arbetsytan
Om du vill ange standardbibliotek måste du vara administratör för arbetsytan. Som administratör kan du utföra följande uppgifter:
- Skapa en ny miljö
- Installera de bibliotek som krävs i miljön
- Bifoga den här miljön som standard för arbetsytan
När dina notebook-filer och Spark-jobbdefinitioner är kopplade till arbetsyteinställningarna startar de sessioner med biblioteken installerade i arbetsytans standardmiljö.
Scenario 2: Spara biblioteksspecifikationer för ett eller flera kodobjekt
Om du har vanliga bibliotek för olika kodobjekt och inte kräver frekvent uppdatering, är det ett bra val att installera biblioteken i en miljö och koppla det till kodobjekten .
Det tar lite tid att få biblioteken i miljöer att bli effektiva vid publicering. Det tar normalt 5–15 minuter, beroende på bibliotekens komplexitet. Under den här processen hjälper systemet till att lösa potentiella konflikter och ladda ned nödvändiga beroenden.
En fördel med den här metoden är att de bibliotek som har installerats garanterat är tillgängliga när Spark-sessionen startas med en bifogad miljö. Det sparar arbete med att underhålla vanliga bibliotek för dina projekt.
Det rekommenderas starkt för pipelinescenarier med dess stabilitet.
Scenario 3: Infogad installation i interaktiv körning
Om du använder notebook-filerna för att skriva kod interaktivt är det bästa sättet att använda infogad installation för att lägga till extra nya PyPI/conda-bibliotek eller verifiera dina anpassade bibliotek för engångsanvändning. Med infogade kommandon i Infrastruktur kan du ha biblioteket effektivt i den aktuella Spark-sessionen för notebook-filer. Det tillåter snabb installation, men det installerade biblioteket bevaras inte mellan olika sessioner.
Eftersom %pip install du genererar olika beroendeträd då och då, vilket kan leda till bibliotekskonflikter, inaktiveras infogade kommandon som standard i pipelinekörningarna och rekommenderas INTE att användas i dina pipelines.
Sammanfattning av bibliotekstyper som stöds
| Bibliotekstyp | Hantering av miljöbibliotek | Infogad installation |
|---|---|---|
| Python Public (PyPI & Conda) | Stöds | Stöds |
| Anpassad Python (.whl) | Stöds | Stöds |
| R Public (CRAN) | Stöds inte | Stöds |
| Anpassad R (.tar.gz) | Stöds som anpassat bibliotek | Stöds |
| Burk | Stöds som anpassat bibliotek | Stöds |
Infogad installation
Infogade kommandon stöder hantering av bibliotek i varje notebook-sessioner.
Infogad Python-installation
Systemet startar om Python-tolken för att tillämpa biblioteksändringen. Alla variabler som definierats innan du kör kommandocellen går förlorade. Vi rekommenderar starkt att du lägger till alla kommandon för att lägga till, ta bort eller uppdatera Python-paket i början av notebook-filen.
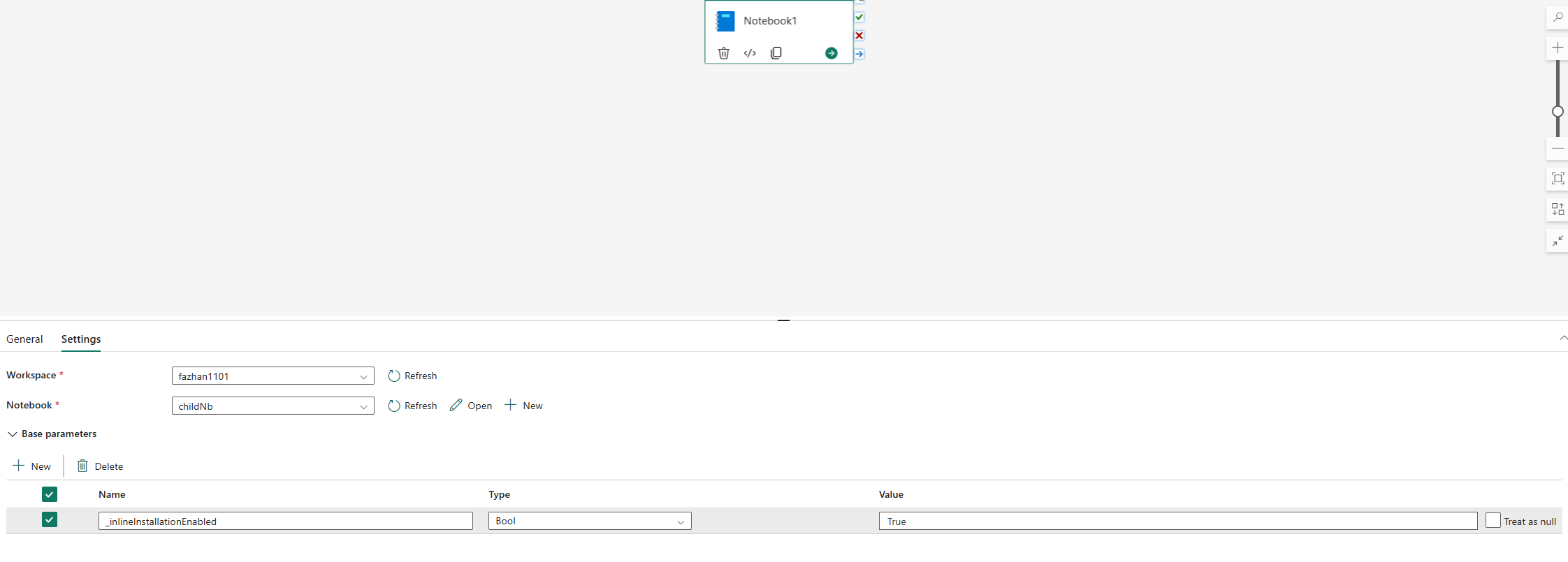
De infogade kommandona för att hantera Python-bibliotek är inaktiverade i notebook-pipeline som körs som standard. Om du vill aktivera %pip install för pipeline lägger du till "_inlineInstallationEnabled" som boolparameter lika med Sant i notebook-aktivitetsparametrarna.
Kommentar
%pip install Kan leda till inkonsekventa resultat då och då. Vi rekommenderar att du installerar biblioteket i en miljö och använder det i pipelinen.
I notebook-referenskörningar stöds inte infogade kommandon för att hantera Python-bibliotek. För att säkerställa att körningen är korrekt rekommenderar vi att du tar bort dessa infogade kommandon från den refererade notebook-filen.
Vi rekommenderar %pip i stället för !pip.
!pip är ett inbyggt IPython-kommando som har följande begränsningar:
-
!pipinstallerar endast ett paket på drivrutinsnoden, inte körnoder. - Paket som installeras via
!pippåverkar inte konflikter med inbyggda paket eller om paket redan har importerats i en notebook-fil.
Hanterar dock %pip dessa scenarier. Bibliotek som installeras via %pip är tillgängliga på både drivrutins- och körnoder och är fortfarande effektiva även om biblioteket redan har importerats.
Dricks
Kommandot %conda install tar vanligtvis längre tid än %pip install kommandot för att installera nya Python-bibliotek. Den kontrollerar de fullständiga beroendena och löser konflikter.
Du kanske vill använda %conda install för mer tillförlitlighet och stabilitet. Du kan använda %pip install om du är säker på att det bibliotek som du vill installera inte står i konflikt med de förinstallerade biblioteken i körningsmiljön.
Alla tillgängliga kommandon och förtydliganden i Python finns i %pip-kommandon och %conda-kommandon.
Hantera offentliga Python-bibliotek via infogad installation
I det här exemplet kan du se hur du använder infogade kommandon för att hantera bibliotek. Anta att du vill använda altair, ett kraftfullt visualiseringsbibliotek för Python, för en engångsdatautforskning. Anta att biblioteket inte är installerat på din arbetsyta. I följande exempel används conda-kommandon för att illustrera stegen.
Du kan använda infogade kommandon för att aktivera altair i notebook-sessionen utan att påverka andra sessioner i notebook-filen eller andra objekt.
Kör följande kommandon i en notebook-kodcell. Det första kommandot installerar altair-biblioteket . Installera även vega_datasets, som innehåller en semantisk modell som du kan använda för att visualisera.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandCellens utdata anger resultatet av installationen.
Importera paketet och semantikmodellen genom att köra följande kod i en annan notebook-cell.
import altair as alt from vega_datasets import dataNu kan du leka med altair-biblioteket med sessionsomfattning.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Hantera anpassade Python-bibliotek via infogad installation
Du kan ladda upp dina anpassade Python-bibliotek till resursmappen i anteckningsboken eller den anslutna miljön. Resursmapparna är det inbyggda filsystemet som tillhandahålls av varje notebook-fil och miljöer. Mer information finns i Notebook-resurser . Efter uppladdningen kan du dra och släppa det anpassade biblioteket till en kodcell. Det infogade kommandot för att installera biblioteket genereras automatiskt. Du kan också använda följande kommando för att installera.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
Infogad R-installation
För att hantera R-bibliotek har Fabric stöd för kommandona install.packages(), remove.packages()och devtools:: . Alla tillgängliga R-infogade kommandon och förtydliganden finns i kommandot install.packages och kommandot remove.package.
Hantera offentliga R-bibliotek via infogad installation
Följ det här exemplet om du vill gå igenom stegen för att installera ett offentligt R-bibliotek.
Så här installerar du ett R-feedbibliotek:
Växla arbetsspråket till SparkR (R) i notebook-menyfliksområdet.
Installera Caesar-biblioteket genom att köra följande kommando i en notebook-cell.
install.packages("caesar")Nu kan du leka med caesarbiblioteket med sessionsomfattning med ett Spark-jobb.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Hantera Jar-bibliotek via infogad installation
De .jar filerna stöds vid notebook-sessioner med följande kommando.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
Kodcellen använder Lakehouses lagring som exempel. I notebook-utforskaren kan du kopiera den fullständiga ABFS-sökvägen och ersätta den i koden.
