Dataingenjör inställningar för arbetsyteadministration i Microsoft Fabric
Gäller för:✅ Dataingenjör ing och Datavetenskap i Microsoft Fabric
När du skapar en arbetsyta i Microsoft Fabric skapas automatiskt en startpool som är associerad med arbetsytan. Med den förenklade installationen i Microsoft Fabric behöver du inte välja nod- eller datorstorlekar eftersom de här alternativen hanteras för dig i bakgrunden. Den här konfigurationen ger en snabbare (5–10 sekunder) Startupplevelse för Apache Spark-sessioner så att användarna kan komma igång och köra dina Apache Spark-jobb i många vanliga scenarier utan att behöva oroa sig för att konfigurera beräkningen. För avancerade scenarier med specifika beräkningskrav kan användarna skapa en anpassad Apache Spark-pool och storleksanpassa noderna baserat på deras prestandabehov.
Om du vill göra ändringar i Apache Spark-inställningarna på en arbetsyta bör du ha administratörsrollen för den arbetsytan. Mer information finns i Roller på arbetsytor.
Så här hanterar du Spark-inställningarna för poolen som är associerad med din arbetsyta:
Gå till inställningarna för arbetsytan på arbetsytan och välj alternativet Dataingenjör ing/Vetenskap för att expandera menyn:
Du ser alternativet Spark Compute i den vänstra menyn:
Kommentar
Om du ändrar standardpoolen från startpoolen till en anpassad Spark-pool kan du se längre sessionsstart (~3 minuter).

Pool
Standardpool för arbetsytan
Du kan använda den automatiskt skapade startpoolen eller skapa anpassade pooler för arbetsytan.
Startpool: Förhydrerade livepooler skapas automatiskt för din snabbare upplevelse. Dessa kluster är medelstora. Startpoolen är inställd på en standardkonfiguration baserat på den SKU för infrastrukturkapacitet som köpts. Administratörer kan anpassa maximalt antal noder och utförare baserat på deras krav på Spark-arbetsbelastningsskalning. Mer information finns i Konfigurera startpooler
Anpassad Spark-pool: Du kan storleksanpassa noderna, autoskalning och dynamiskt allokera exekutorer baserat på dina Krav för Spark-jobb. Om du vill skapa en anpassad Spark-pool bör kapacitetsadministratören aktivera alternativet Anpassade arbetsytepooler i avsnittet Spark Compute i Inställningar för kapacitetsadministratör.
Kommentar
Kapacitetsnivåkontrollen för anpassade arbetsytepooler är aktiverad som standard. Mer information finns i Konfigurera och hantera datateknik och datavetenskapsinställningar för Infrastrukturkapaciteter.
Administratörer kan skapa anpassade Spark-pooler baserat på deras beräkningskrav genom att välja alternativet Ny pool .

Apache Spark för Microsoft Fabric stöder kluster med en nod, vilket gör att användare kan välja en minsta nodkonfiguration på 1, i vilket fall drivrutinen och kören körs i en enda nod. Dessa kluster med en nod erbjuder återställningsbar hög tillgänglighet vid nodfel och bättre tillförlitlighet för arbetsbelastningar med mindre beräkningskrav. Du kan också aktivera eller inaktivera alternativet automatisk skalning för dina anpassade Spark-pooler. När den är aktiverad med autoskalning hämtar poolen nya noder inom den maximala nodgräns som angetts av användaren och drar tillbaka dem efter jobbkörningen för bättre prestanda.
Du kan också välja alternativet att dynamiskt allokera köre till poolen automatiskt optimalt antal utförare inom den maximala gränsen som anges baserat på datavolymen för bättre prestanda.

Läs mer om Apache Spark-beräkning för Fabric.
- Anpassa beräkningskonfigurationen för objekt: Som arbetsyteadministratör kan du tillåta användare att justera beräkningskonfigurationer (egenskaper på sessionsnivå som omfattar Driver/Executor Core, Driver/Executor Memory) för enskilda objekt, till exempel notebook-filer, Spark-jobbdefinitioner med hjälp av miljö.
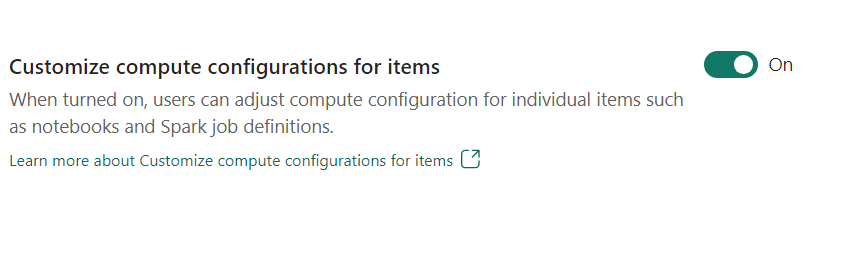
Om inställningen inaktiveras av arbetsyteadministratören används standardpoolen och dess beräkningskonfigurationer för alla miljöer på arbetsytan.
Environment
Miljön innehåller flexibla konfigurationer för att köra dina Spark-jobb (notebook-filer, Spark-jobbdefinitioner). I en miljö kan du konfigurera beräkningsegenskaper, välja olika körningsfunktioner och konfigurera beroenden för bibliotekspaket baserat på dina arbetsbelastningskrav.
På fliken Miljö har du möjlighet att ange standardmiljön. Du kan välja vilken version av Spark du vill använda för arbetsytan.
Som administratör för infrastrukturarbetsytan kan du välja en miljö som standardmiljö för arbetsytan.
Du kan också skapa en ny via listrutan Miljö .

Om du inaktiverar alternativet för att ha en standardmiljö kan du välja körningsversionen för infrastrukturresurser från de tillgängliga körningsversioner som anges i listrutan.

Läs mer om Apache Spark-körningar.
Projekt
Med jobbinställningar kan administratörer styra jobbantagningslogik för alla Spark-jobb på arbetsytan.

Som standard är alla arbetsytor aktiverade med optimistisk jobbinträde. Läs mer om jobbantagning för Spark i Microsoft Fabric.
Du kan aktivera reservens maximala kärnor för aktiva Spark-jobb för att omvandla optimistisk jobbantagningsbaserad metod och reservera maximalt antal kärnor för sina Spark-jobb.
Du kan också ange tidsgränsen för Spark-sessionen för att anpassa sessionens förfallodatum för alla interaktiva sessioner i notebook-filen.
Kommentar
Standardsessionens förfallodatum är inställt på 20 minuter för interaktiva Spark-sessioner.
Hög samtidighet
Med hög samtidighetsläge kan användare dela samma Spark-sessioner i Apache Spark för datateknik och datavetenskapsarbetsbelastningar i Apache Spark. Ett objekt som en notebook-fil använder en Spark-session för körningen och när det är aktiverat kan användare dela en enda Spark-session över flera notebook-filer.

Läs mer om hög samtidighet i Apache Spark för Fabric.
Automatisk loggning för Machine Learning-modeller och experiment
Administratörer kan nu aktivera automatisk loggning för sina maskininlärningsmodeller och experiment. Det här alternativet samlar automatiskt in värdena för indataparametrar, utdatamått och utdataobjekt i en maskininlärningsmodell när den tränas. Läs mer om automatisk loggning.

Relaterat innehåll
- Läs mer om Apache Spark Runtimes i Infrastrukturresurser – Översikt, Versionshantering, Stöd för flera körningar och uppgradering av Delta Lake Protocol.
- Läs mer i den offentliga Dokumentationen om Apache Spark.
- Hitta svar på vanliga frågor och svar: Vanliga frågor och svar om administration av Apache Spark-arbetsyteinställningar.