Mata in exporterade Dataverse-data med Azure Data Factory
När du har exporterat data från Microsoft Dataverse till Azure Data Lake Storage Gen2 med Azure Synapse Link for Dataverse kan du använda Azure Data Factory för att skapa dataflöden, omvandla dina data och köra analysen.
Anteckning
Azure Synapse Link for Dataverse hette tidigare Exportera till datasjö. Tjänsten ändrades till i maj 2021 och kommer även i fortsättningen att exportera data till Azure Data Lake och Azure Synapse Analytics.
Den här artikeln visar hur man utför följande uppgifter:
Ange lagringskontot Data Lake Storage Gen2 med Dataverse-data som en källa i ett Data Factory-dataflöde.
Omvandla Dataverse data i Data Factory med ett dataflöde.
Ange lagringskontot Data Lake Storage Gen2 med Dataverse-data som en mottagare i ett Data Factory-dataflöde.
Kör dataflödet genom att skapa en pipeline.
Förutsättningar
I det här avsnittet beskrivs förutsättningarna som krävs för intag av exporterade Dataverse-data med Data Factory.
Azure-roller. Det användarkonto som används för att logga in på Azure måste vara medlem i rollen deltagare eller ägare, eller en administratör av Azure-prenumerationen. Du kan visa de behörigheter du har i prenumerationen genom att gå till Azure Portal, välja ditt användarnamn i det övre högra hörnet, välja ... och sedan välja Mina behörigheter. Om du har tillgång till flera prenumerationer väljer du den aktuella prenumerationen. Om du vill skapa och hantera underordnade resurser för Data Factory i Azure-portalen—inklusive datauppsättningar, länkade tjänster, pipelines, utlösare och integreringskörningar—måste du tillhöra rollen Data Factory-deltagare i resursgruppsnivån eller högre.
Azure Synapse Link for Dataverse. I den här guiden förutsätts det att du redan har exporterat Dataverse-data via Azure Synapse Link for Dataverse. I det här exemplet exporteras data i kontotabellen till datasjön.
Azure Data Factory. I den här guiden förutsätts det att du redan har skapat en Data Factory under samma prenumeration och resursgrupp som det lagringskonto som innehåller exporterade Dataverse data.
Ange lagringskonto för Data Lake Storage Gen2 som källa
Öppna Azure Data Factory och välj den Data Factory som finns i samma prenumerations- och resursgrupp som lagringskontot som innehåller din exporterade Dataverse data. Välj sedan Skapa dataflöde från startsidan.
Aktivera felsökningsläget för dataflöden och välj önskad tid till publicering. Det kan ta upp till 10 minuter, men du kan fortsätta med följande steg.

Välj Lägg till källa.

Du kan göra följande under Källinställningar:
- Namn på utdataström: Ange det namn du vill ha.
- Källtyp: Välj Infoga.
- Infogad datauppsättning: Välj Common Data Model.
- Länkad tjänst: Välj lagringskontot på listrutan och länka sedan en ny tjänst genom att ange din prenumerationsinformation och lämna alla standardkonfigurationer.
- Provtagning: Om du vill använda alla data väljer du Inaktivera.
Du kan göra följande under Källalternativ:
Metadataformat: Välj Model.json.
Rotplats: Ange behållarnamnet i den första rutan (Behållare) eller Bläddra för behållarnamnet och välj OK.
Entitet: Ange tabellnamnet eller Bläddra efter tabellen.

Kontrollera fliken Projektion för att säkerställa att ditt schema har importerats korrekt. Om inga kolumner visas väljer du Schemaalternativ och kontrollerar alternativet Härled drivna kolumntyper. Konfigurera formateringsalternativen så att de matchar datauppsättningen och välj sedan Tillämpa.
Du kan visa dina data på fliken Förhandsgranskning av data om du vill vara säker på att källgenereringen är fullständig och korrekt.
Omvandla din Dataverse data
När du har angett exporterad Dataverse-data på Azure Data Lake Storage Gen2-kontot som en källa i dataflödet för Data Factory finns det många alternativ för att omforma dina data. Mer information: Azure Data Factory
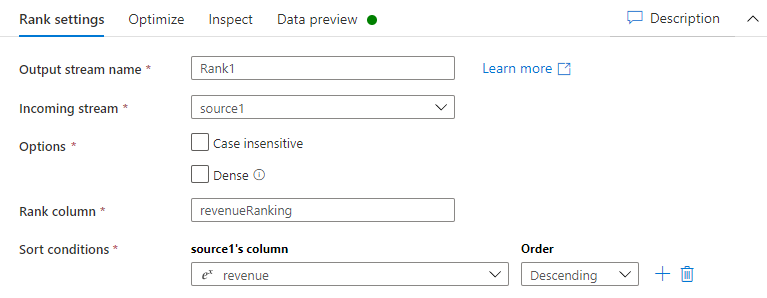
Följ dessa anvisningar om du vill skapa en rankning för respektive rad efter fältet intäkt i kontotabellen.
Välj + i det nedre högra hörnet av den föregående omvandlingen och sök sedan efter och välj Rangordna.
Gör följande på fliken Rangordningsinställningar:
Namn på utdataflöden: Ange det namn du vill använda, till exempel Rangordning1.
Inkommande ström: Välj det källnamn du vill använda. I det här fallet källnamnet från föregående steg.
Alternativ: Lämna alternativen avmarkerade.
Rangordningskolumn: Ange namnet på den genererade rangordningskolumnen
Sorteringsvillkor: Välj kolumnen intäkt och sortera i Fallande ordning.
Du kan visa dina data på fliken förhandsgranskning av data där den nya kolumnen revenueRank finns längst till höger.
Ange lagringskontot Data Lake Storage Gen2 som en mottagare
I slutändan måste du ange en mottagare för ditt dataflöde. Följ anvisningarna nedan om du vill placera dina omvandlade data som en avgränsad textfil i datasjön.
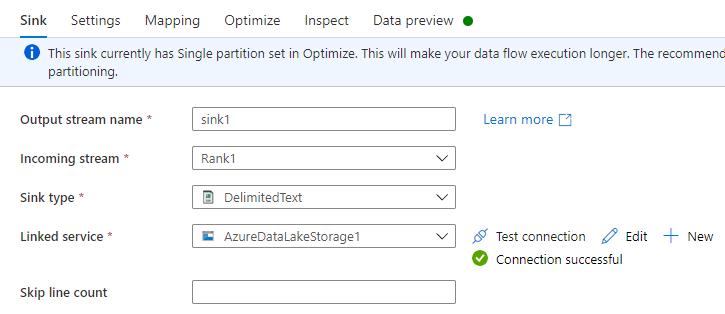
Välj + i det nedre högra hörnet av den föregående omvandlingen och sök sedan efter och välj Mottagare.
Gör något av följande på fliken Mottagare:
Namn på utdataström: Ange det namn du vill ha, t.ex. Mottagare1.
Inkommande ström: Välj det källnamn du vill använda. I det här fallet källnamnet från föregående steg.
Mottagartyp: Välj DelimitedText.
Länkad tjänst: Använd tjänsten Azure Synapse Link for Dataverse för att välja en lagringsbehållare för Data Lake Storage Gen2 som innehåller de data du exporterar.
På fliken Inställningar kan du göra följande:
Mappsökväg: Ange behållarnamnet i den första rutan (Filsystem) eller Bläddra för behållarnamnet och välj OK.
Filnamnsalternativ: Välj utdata till en fil.
Utdata till en fil: Ange ett filnamn, till exempel ADFOutput
Lämna alla andra standardinställningar.
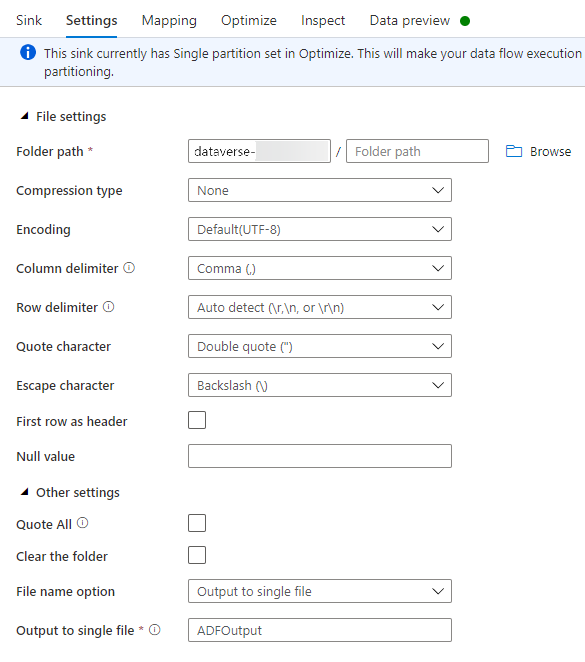
På fliken Optimera anger du alternativet Partitionsalternativ till Enkel partition.
Du kan visa dina data på fliken Förhandsgranskning av data.
Kör dataflöde
I vänster fönster, under Fabriksresurser, väljer du + och sedan Pipeline.

Under Aktiviteter väljer du Flytta och omvandla. Dra sedan Dataflöde till arbetsytan.
Välj Använd befintligt dataflöde och välj sedan det dataflöde du skapade i föregående steg.
Välj Felsök från kommandofältet.
Låt dataflödet köra tills den nedersta vyn visar att det har slutförts. Det kan ta några minuter.
Gå till den slutliga mållagringsbehållaren och leta upp den transformerade tabell datafilen.
Se även
Konfigurera Azure Synapse Link for Dataverse med Azure Data
Analysera Dataverse-data i Azure Data Lake Storage Gen2 med Power BI
Anteckning
Kan du berätta om dina inställningar för dokumentationsspråk? Svara i en kort undersökning. (observera att undersökningen är på engelska)
Undersökningen tar ungefär sju minuter. Inga personuppgifter samlas in (sekretesspolicy).