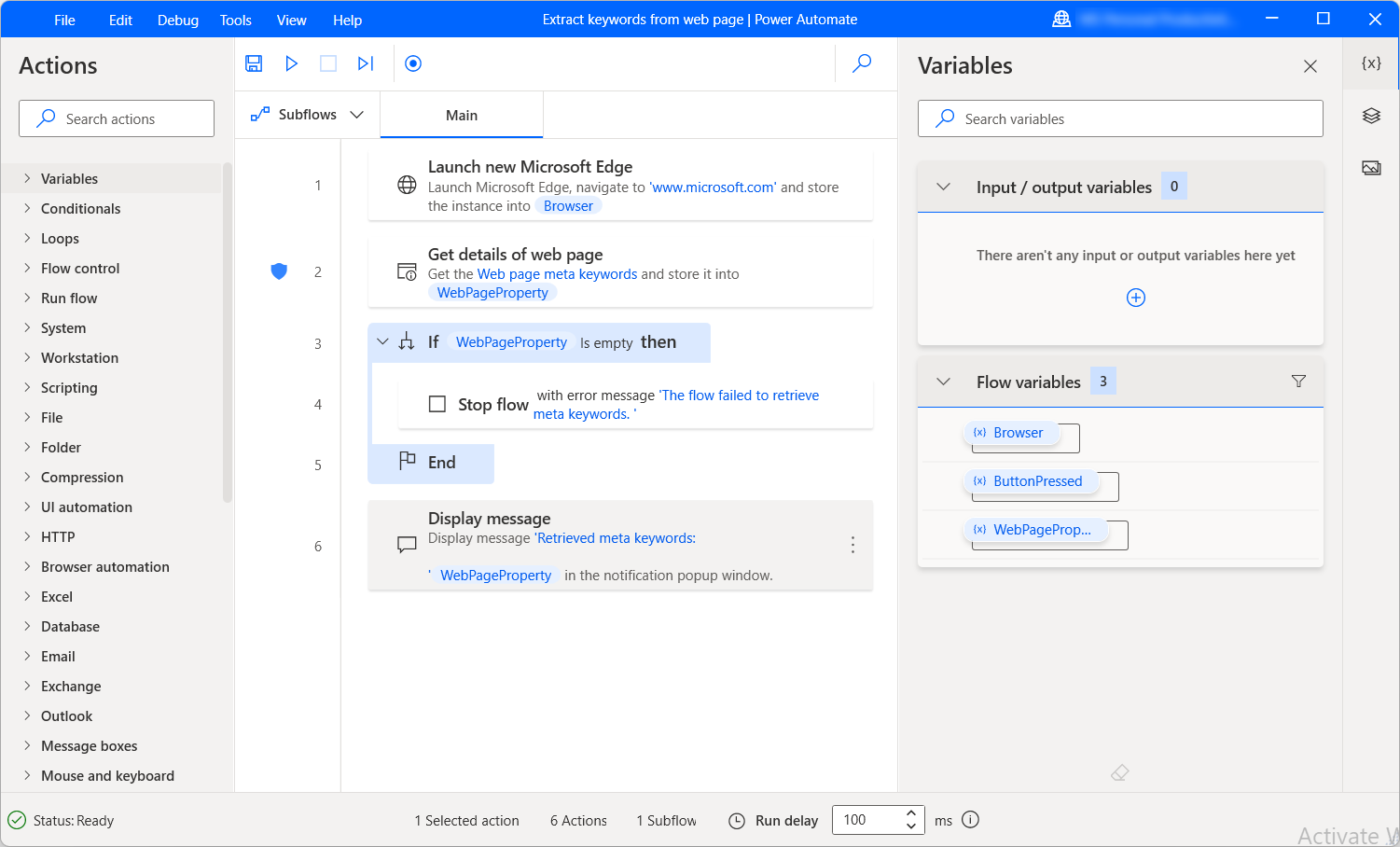
Hämta detaljer från en webbsida
Att extrahera information om webbsidor är en viktig funktion i de flesta webbrelaterade flöden. Åtgärden Hämta information om webbsidan låter dig hämta olika detaljer från webbsidor och hantera dem i dina datorflöden.
För att kunna använda åtgärden måste du ha en redan skapad webbläsarinstans som anger den webbsida du vill extrahera information från. En webbläsarinstans kan skapas med valfri webbläsarstartsåtgärd.
När du har valt rätt webbläsarinstans väljer du den information du vill extrahera från webbsidan. Åtgärden Hämta information om webbsida innehåller sex olika alternativ:
- Beskrivningen av webbsidan
- Metanyckelord för webbsidan
- Webbsidans titel
- Webbsidans text
- Webbsidans källkod
- Webbsidans URL
Den hämtade informationen sparas för senare användning i en textvariabel med namnet WebPageProperty.
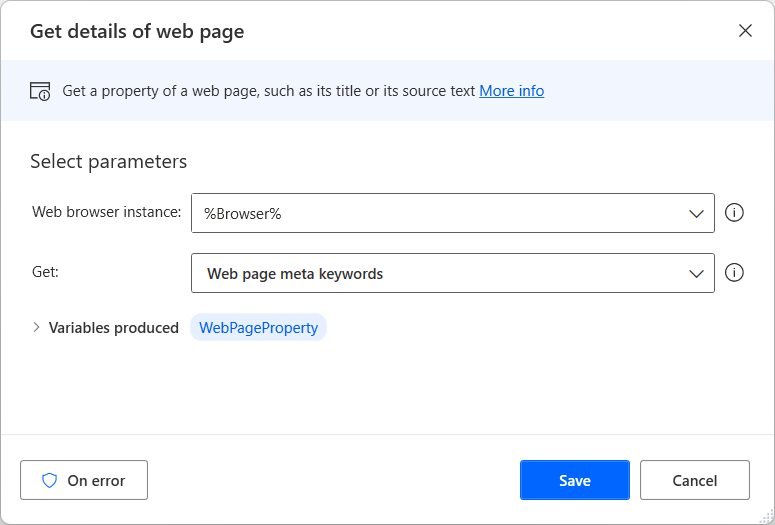
Förhindra fel vid hämtning av information
De flesta egenskaper finns praktiskt taget på alla webbsidor, men det kan finnas situationer då åtgärden Hämta information om webbsidor inte kan hämta den valda informationen. Webbsidor utan metanyckel används till exempel ofta.
Om du är osäker på om det finns ett attribut på en webbsida konfigurerar du alternativen För fel i åtgärden Hämta information om webbsidor för att fortsätta köra flödet efter att det uppstått fel. För mer information om åtgärds felhantering, se Hantera fel i datorflöden.
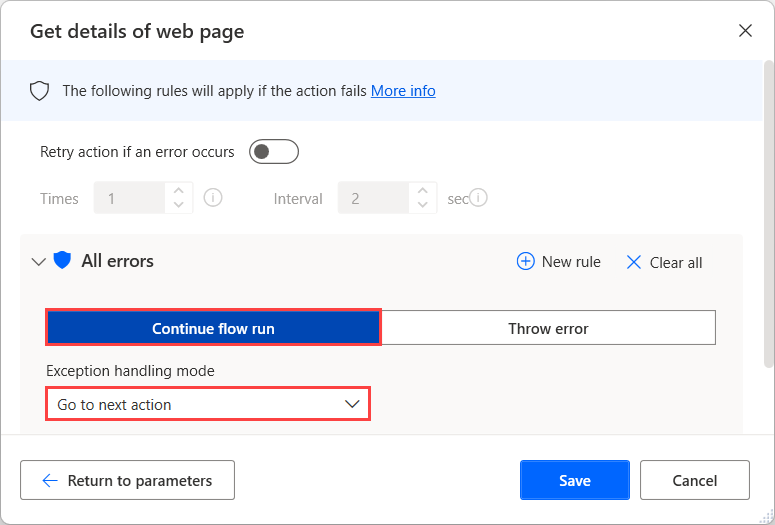
Avgör om extraheringen av data har lyckats genom att använda ett If-villkor för att kontrollera om variabeln WebPageProperty är tom eller inte.
Med villkorsfunktionerna kan du implementera olika funktioner för att extrahera lyckade och misslyckade data. Du kan hitta mer information om villkorliga villkor i Använda villkor.
I följande exempel hämtas de tillgängliga metanyckelorden från en webbsida och visas i en meddelanderuta. Om extraheringen misslyckas stoppas flödet och ett felmeddelande returneras.