Inkrementell uppdatering och realtidsdata för semantiska modeller
Inkrementell uppdatering och realtidsdata för semantiska modeller i Power BI ger effektiva sätt att hantera dynamiska data och förbättra prestanda för modelluppdatering. Genom att automatisera skapande och hantering av partitioner minskar inkrementell uppdatering mängden data som behöver uppdateras och gör det möjligt att inkludera realtidsdata. Den här artikeln beskriver hur du konfigurerar och använder inkrementella uppdateringsfunktioner i Power BI för att samla in snabbrörliga data och förbättra prestanda.
Inkrementell uppdatering utökar schemalagda uppdateringsåtgärder genom att tillhandahålla automatisk skapande och hantering av partitioner för semantiska modelltabeller som ofta läser in nya och uppdaterade data. För de flesta modeller innehåller en eller flera tabeller transaktionsdata som ofta ändras och kan växa exponentiellt, till exempel en faktatabell i ett relations- eller stjärndatabasschema. En inkrementell uppdateringsprincip för att partitionera tabellen, uppdatera endast de senaste importpartitionerna och om du vill kan du använda en annan DirectQuery-partition för realtidsdata avsevärt minska mängden data som måste uppdateras. Samtidigt säkerställer den här principen att de senaste ändringarna i datakällan ingår i frågeresultatet.
Med inkrementell uppdatering och realtidsdata:
- Färre uppdateringscykler för snabbt föränderliga data behövs. DirectQuery-läget hämtar de senaste datauppdateringarna när frågor bearbetas, utan att kräva en hög uppdateringstakt.
- Uppdateringarna går snabbare. Endast de senaste data som har ändrats behöver uppdateras.
- Uppdateringar är mer tillförlitliga. Långvariga anslutningar till flyktiga datakällor är inte nödvändiga. Frågor till källdata körs snabbare, vilket minskar risken för att nätverksproblem stör.
- Resursförbrukningen minskas. Mindre data att uppdatera minskar den totala förbrukningen av minne och andra resurser i både Power BI och datakällasystem.
- Stora semantiska modeller är aktiverade. Semantiska modeller med potentiellt miljarder rader kan växa utan att helt behöva uppdatera hela modellen med varje uppdateringsåtgärd.
- Det är enkelt att konfigurera. Inkrementella uppdateringsprinciper definieras i Power BI Desktop med bara några få uppgifter. När Power BI Desktop publicerar rapporten tillämpar tjänsten automatiskt dessa principer för varje uppdatering.
När du publicerar en Power BI Desktop-modell till tjänsten har varje tabell i den nya modellen en enda partition. Den enskilda partitionen innehåller alla rader för tabellen. Om tabellen är stor, t.ex. med tiotals miljoner rader eller mer, kan en uppdatering för tabellen ta lång tid och förbruka en för stor mängd resurser.
Med inkrementell uppdatering partitioner och separerar tjänsten dynamiskt data som måste uppdateras ofta från data som kan uppdateras mindre ofta. Tabelldata filtreras med power query-datum-/tidsparametrar med reserverade, skiftlägeskänsliga namn RangeStart och RangeEnd. När du konfigurerar inkrementell uppdatering i Power BI Desktop används dessa parametrar för att filtrera endast en liten period med data som läses in i modellen. När Power BI Desktop publicerar rapporten till Power BI-tjänst, med den första uppdateringsåtgärden skapar tjänsten inkrementella uppdaterings- och historiska partitioner, och eventuellt en DirectQuery-partition i realtid baserat på inkrementella uppdateringsprincipinställningar. Tjänsten åsidosätter sedan parametervärdena för att filtrera och fråga efter data för varje partition baserat på datum-/tidsvärden för varje rad.
Vid varje efterföljande uppdatering returnerar frågefiltren endast de rader inom uppdateringsperioden som definieras dynamiskt av parametrarna. Dessa rader med ett datum/en tid inom uppdateringsperioden uppdateras. Rader med ett datum/en tid som inte längre ingår i uppdateringsperioden blir sedan en del av den historiska perioden, som inte uppdateras. Om en DirectQuery-partition i realtid ingår i principen för inkrementell uppdatering uppdateras även dess filter så att det hämtar eventuella ändringar som inträffar efter uppdateringsperioden. Både uppdateringsperioder och historiska perioder rullas framåt. När nya inkrementella uppdateringspartitioner skapas blir uppdateringspartitioner inte längre historiska partitioner under uppdateringsperioden. Med tiden blir historiska partitioner mindre detaljerade när de sammanfogas. När en historisk partition inte längre finns i den historiska period som definieras av principen tas den bort helt från modellen. Det här beteendet kallas för ett rullande fönstermönster.
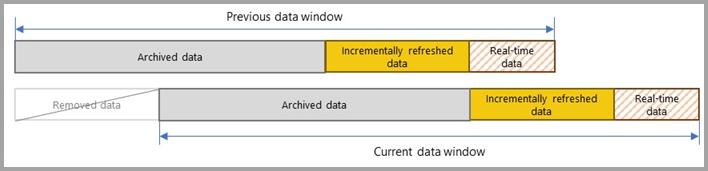
Det fina med inkrementell uppdatering är att tjänsten hanterar allt åt dig baserat på de inkrementella uppdateringsprinciper som du definierar. I själva verket syns inte processen och partitionerna som skapats från den i tjänsten. I de flesta fall är en väldefinierad inkrementell uppdateringsprincip allt som krävs för att avsevärt förbättra modellens uppdateringsprestanda. DirectQuery-partitionen i realtid stöds dock bara för modeller i Premium-kapaciteter. Power BI Premium möjliggör även mer avancerade partitions- och uppdateringsscenarier via XMLA-slutpunkten (XMLA).
Krav
I nästa avsnitt beskrivs de planer och datakällor som stöds.
Planer som stöds
Inkrementell uppdatering stöds för Power BI Premium-, Premium per användare-, Power BI Pro- och Power BI Embedded-modeller.
Att hämta de senaste data i realtid med DirectQuery stöds endast för Power BI Premium-, Premium per användare- och Power BI Embedded-modeller.
Datakällor som stöds
Inkrementell uppdatering och realtidsdata fungerar bäst för strukturerade relationsdatakällor som SQL Database och Azure Synapse, men kan också fungera för andra datakällor. I vilket fall som helst måste datakällan ha stöd för följande:
Datumfiltrering – Datakällan måste ha stöd för någon mekanism för att filtrera data efter datum. För en relationskälla är detta vanligtvis en datumkolumn med datatypen datum/tid eller heltal i måltabellen. Parametrarna RangeStart och RangeEnd, som måste vara datatypen datum/tid, filtrerar tabelldata baserat på datumkolumnen. För datumkolumner med heltals surrogatnycklar i form av yyyymmddkan du skapa en funktion som konverterar datum/tid-värdet i parametrarna RangeStart och RangeEnd så att de matchar heltals surrogatnycklarna i datumkolumnen. Mer information finns i Konfigurera inkrementell uppdatering och realtidsdata – Konvertera DateTime till heltal.
För andra datakällor måste parametrarna RangeStart och RangeEnd skickas till datakällan på något sätt som möjliggör filtrering. För filbaserade datakällor där filer och mappar ordnas efter datum kan parametrarna RangeStart och RangeEnd användas för att filtrera filerna och mapparna för att välja vilka filer som ska läsas in. För webbaserade datakällor kan parametrarna RangeStart och RangeEnd integreras i HTTP-begäran. Följande fråga kan till exempel användas för inkrementell uppdatering av spårningarna från en AppInsights-instans:
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
När inkrementell uppdatering har konfigurerats körs ett Power Query-uttryck som innehåller ett datum/tid-filter baserat på parametrarna RangeStart och RangeEnd mot datakällan. Om filtret anges i ett frågesteg efter den första källfrågan är det viktigt att frågedelegering kombinerar det första frågesteget med de steg som refererar till parametrarna RangeStart och RangeEnd. I följande frågeuttryck Table.SelectRows viks till exempel eftersom det omedelbart följer Sql.Database steget och SQL Server stöder vikning:
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
Det finns inget krav på att den slutgiltiga frågan ska ha stöd för vikning. I följande uttryck använder vi till exempel en icke-vikbar NativeQuery men integrerar parametrarna RangeStart och RangeEnd direkt i SQL:
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
Men om principen för inkrementell uppdatering inkluderar att hämta realtidsdata med DirectQuery kan icke-vikbara transformeringar inte användas. Om det är en ren princip för importläge utan realtidsdata kan frågekombinationsmotorn kompensera och tillämpa filtret lokalt, vilket kräver att alla rader för tabellen hämtas från datakällan. Detta kan göra att inkrementell uppdatering blir långsam, och processen kan ta slut på resurser antingen i Power BI-tjänst eller i en lokal datagateway – vilket effektivt motverkar syftet med inkrementell uppdatering.
Eftersom stödet för frågedelegering skiljer sig åt för olika typer av datakällor bör verifiering utföras för att säkerställa att filterlogiken ingår i de frågor som körs mot datakällan. I de flesta fall försöker Power BI Desktop utföra den här verifieringen åt dig när du definierar principen för inkrementell uppdatering. För SQL-baserade datakällor som SQL Database, Azure Synapse, Oracle och Teradata är den här verifieringen tillförlitlig. Andra datakällor kanske inte kan verifiera utan att spåra frågorna. Om Power BI Desktop inte kan bekräfta frågorna visas en varning i dialogrutan Konfiguration av inkrementell uppdateringsprincip.
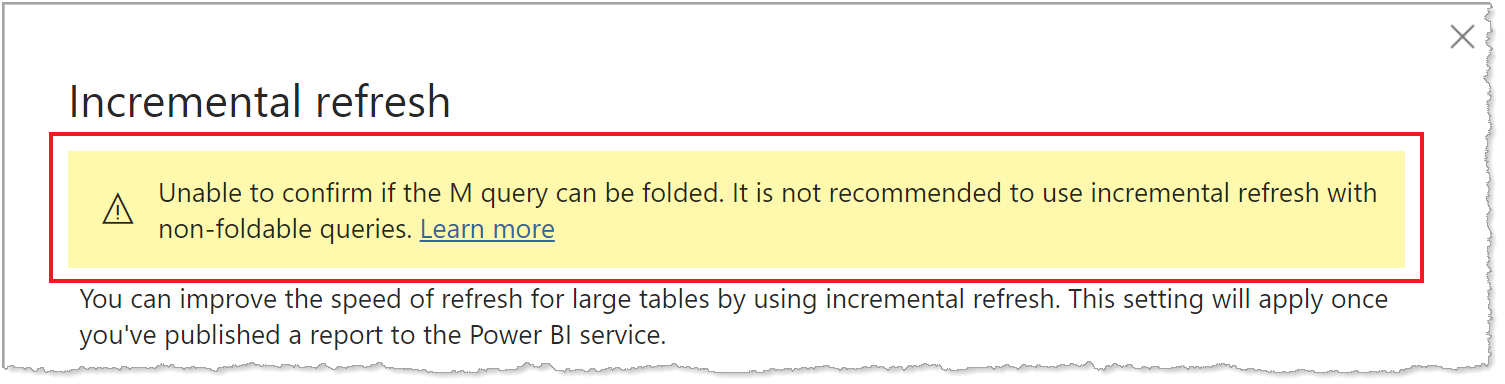
Om du ser den här varningen och vill verifiera att den nödvändiga frågedelegeringen sker använder du funktionen Power Query Diagnostics eller spårar frågor med hjälp av ett verktyg som stöds av datakällan, till exempel SQL Profiler. Om frågedelegering inte sker kontrollerar du att filterlogiken ingår i frågan som skickas till datakällan. Annars är det troligt att frågan innehåller en transformering som förhindrar vikning.
Innan du konfigurerar din inkrementella uppdateringslösning bör du noggrant läsa och förstå vägledningen för frågedelegering i Power BI Desktop och Power Query-frågedelegering. De här artiklarna kan hjälpa dig att avgöra om datakällan och frågorna stöder frågedelegering.
Enskild datakälla
När du konfigurerar inkrementell uppdatering och realtidsdata med hjälp av Power BI Desktop, eller konfigurerar en avancerad lösning med hjälp av TMSL (Tabular Model Scripting Language) eller Tabular Object Model (TOM) via XMLA-slutpunkten, måste alla partitioner, oavsett om de importeras eller DirectQuery, köra frågor mot data från en enda källa.
Andra typer av datakällor
Genom att använda fler anpassade frågefunktioner och frågelogik kan inkrementell uppdatering användas med andra typer av datakällor om filter baserade på RangeStart och RangeEnd kan skickas i en enda fråga, till exempel med datakällor som Excel-arbetsboksfiler som lagras i en mapp, filer i SharePoint och RSS-feeds. Tänk på att det här är avancerade scenarier som kräver ytterligare anpassning och testning utöver det som beskrivs här. Se avsnittet Community senare i den här artikeln för att få förslag på hur du hittar mer information om hur du använder inkrementell uppdatering för unika scenarier.
Tidsgränser
Oavsett inkrementell uppdatering har Power BI Pro modeller en tidsgräns på två timmar och har inte stöd för att hämta realtidsdata med DirectQuery. För modeller i en Premium-kapacitet är tidsgränsen fem timmar. Uppdateringsåtgärder är process- och minnesintensiva. En fullständig uppdateringsåtgärd kan använda så mycket som dubbelt så mycket minne som krävs enbart av modellen, eftersom tjänsten behåller en ögonblicksbild av modellen i minnet tills uppdateringsåtgärden är klar. Uppdateringsåtgärder kan också vara processintensiva och förbruka en betydande mängd tillgängliga CPU-resurser. Uppdateringsåtgärder måste också förlita sig på flyktiga anslutningar till datakällor och möjligheten för dessa datakällsystem att snabbt returnera frågeutdata. Tidsgränsen är ett skydd för att begränsa överförbrukningen av dina tillgängliga resurser.
Kommentar
Med Premium-kapaciteter har uppdateringsåtgärder som utförs via XMLA-slutpunkten ingen tidsgräns. Mer information finns i Avancerad inkrementell uppdatering med XMLA-slutpunkten.
Eftersom inkrementell uppdatering optimerar uppdateringsåtgärder på partitionsnivå i modellen kan resursförbrukningen minskas avsevärt. Samtidigt, även med inkrementell uppdatering, såvida de inte går igenom XMLA-slutpunkten, är uppdateringsåtgärder bundna av samma två- och femtimmarsgränser. En effektiv inkrementell uppdateringsprincip minskar inte bara mängden data som bearbetas med en uppdateringsåtgärd, utan minskar också mängden onödiga historiska data som lagras i din modell.
Frågor kan också begränsas av en standardtidsgräns för datakällan. De flesta relationsdatakällor tillåter tvingande tidsgränser i Power Query M-uttrycket. Följande uttryck använder till exempel funktionen SQL Server-dataåtkomst för att ange CommandTimeout till två timmar. Varje period som definieras av principintervallen skickar en fråga som observerar tidsgränsinställningen för kommandot:
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
För mycket stora modeller i Premium-kapaciteter som sannolikt innehåller miljarder rader kan den inledande uppdateringsåtgärden startas. Bootstrapping gör att tjänsten kan skapa tabell- och partitionsobjekt för modellen, men läser inte in och bearbetar data i någon av partitionerna. Genom att använda SQL Server Management Studio kan du ange att partitioner ska bearbetas individuellt, sekventiellt eller parallellt för att både minska mängden data som returneras i en enda fråga och även kringgå tidsgränsen på fem timmar. Mer information finns i Avancerad inkrementell uppdatering – Förhindra tidsgränser vid den första fullständiga uppdateringen.
Aktuellt datum och aktuell tid
Som standard bestäms aktuellt datum och tid baserat på UTC (Coordinated Universal Time) vid tidpunkten för uppdateringen. För uppdateringar på begäran, schemalagt och REST API kan du konfigurera en annan tidszon under "Uppdatera" som kommer att beaktas när du fastställer aktuellt datum och tid. En uppdatering som inträffar kl. 20:00 Stillahavstid (USA och Kanada) med en konfigurerad tidszon avgör till exempel aktuellt datum och tid baserat på Pacific Time, inte UTC, som skulle returneras nästa dag.
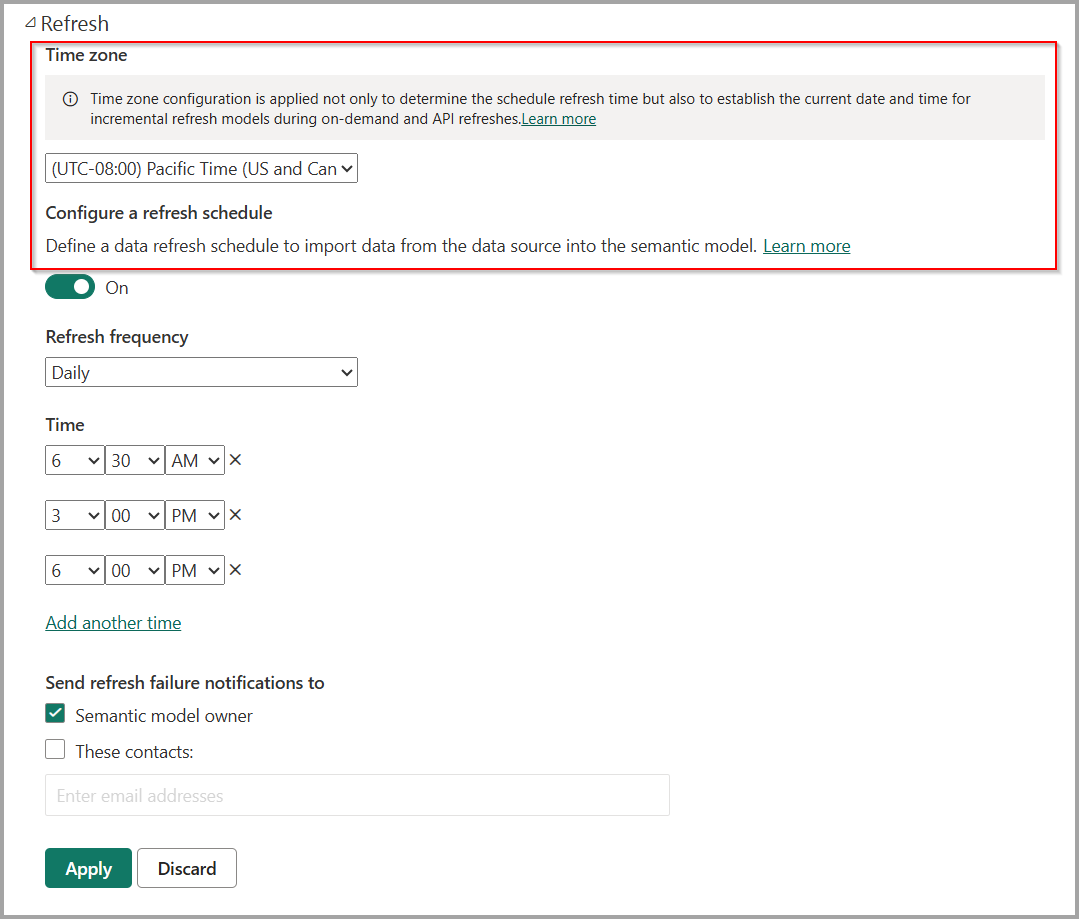
Uppdateringsåtgärder som inte anropas via Power BI-tjänsten, till exempel XMLA TMSL-uppdateringskommando, tar inte hänsyn till tidszonskonfigurationen och standardvärdet UTC.
Konfigurera inkrementell uppdatering och realtidsdata
I det här avsnittet beskrivs viktiga begrepp för att konfigurera inkrementell uppdatering och realtidsdata. När du är redo för mer detaljerade stegvisa instruktioner kan du läsa Konfigurera inkrementell uppdatering och realtidsdata.
Inkrementell uppdatering konfigureras i Power BI Desktop. För de flesta modeller krävs bara ett fåtal uppgifter. Tänk dock på följande:
- När du har publicerat till Power BI-tjänst kan du inte publicera samma modell igen från Power BI Desktop. Ompublicering tar bort alla befintliga partitioner och data som redan finns i modellen. Om du publicerar till en Premium-kapacitet kan efterföljande ändringar av metadatascheman göras med verktyg som ALM Toolkit med öppen källkod eller med hjälp av TMSL. Mer information finns i Avancerad inkrementell uppdatering – endast metadatadistribution.
- När du har publicerat till Power BI-tjänst kan du inte ladda ned modellen som en .pbix till Power BI Desktop. Eftersom modeller i tjänsten kan bli så stora är det opraktiskt att ladda ned och öppna dem på en typisk stationär dator.
- När du hämtar realtidsdata med DirectQuery kan du inte publicera modellen till en arbetsyta som inte är premium. Inkrementell uppdatering med realtidsdata stöds endast med Power BI Premium.
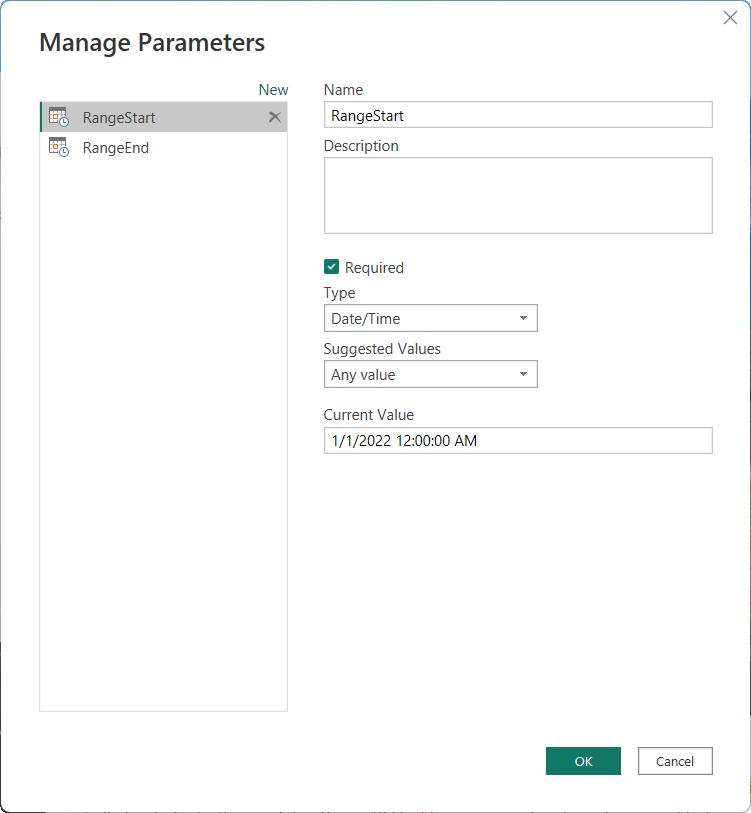
Skapa parametrar
Om du vill konfigurera inkrementell uppdatering i Power BI Desktop skapar du först två Power Query-datum-/tidsparametrar med de reserverade, skiftlägeskänsliga namnen RangeStart och RangeEnd. Dessa parametrar, som definieras i dialogrutan Hantera parametrar i Power Query-redigeraren, används ursprungligen för att filtrera de data som läses in i Power BI Desktop-modelltabellen för att endast inkludera de rader med datum/tid inom den perioden.
RangeStart representerar det äldsta eller tidigaste datumet/tiden och RangeEnd representerar det senaste eller senaste datumet/tiden. När modellen har publicerats till tjänsten RangeStart och RangeEnd åsidosättas automatiskt av tjänsten för att köra frågor mot data som definierats av uppdateringsperioden som anges i principinställningarna för inkrementell uppdatering.
Till exempel är datakälltabellen FactInternetSales i genomsnitt 10 000 nya rader per dag. Om du vill begränsa antalet rader som ursprungligen lästes in i modellen i Power BI Desktop anger du en period på två dagar mellan RangeStart och RangeEnd.
Filtrera data
Med parametrarna RangeStart och RangeEnd definierade tillämpar du anpassade datumfilter på tabellens datumkolumn. De filter du använder väljer en delmängd av data som läses in i modellen när du väljer Använd.
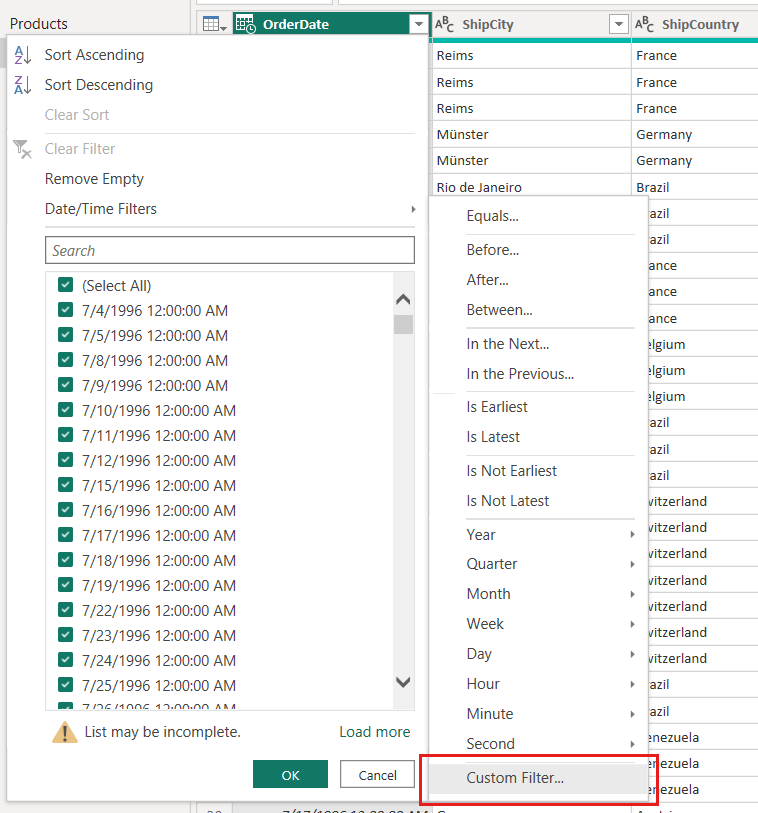
Med vårt FactInternetSales-exempel läses två dagars data (ungefär 20 000 rader) in i modellen när du har skapat filter baserat på parametrarna och tillämpat stegen.
Definiera princip
När filter har tillämpats och en delmängd data har lästs in i modellen definierar du en inkrementell uppdateringsprincip för tabellen. När modellen har publicerats till tjänsten används principen av tjänsten för att skapa och hantera tabellpartitioner och utföra uppdateringsåtgärder. Om du vill definiera principen använder du dialogrutan Inkrementell uppdatering och realtidsdata för att ange både obligatoriska och valfria inställningar.
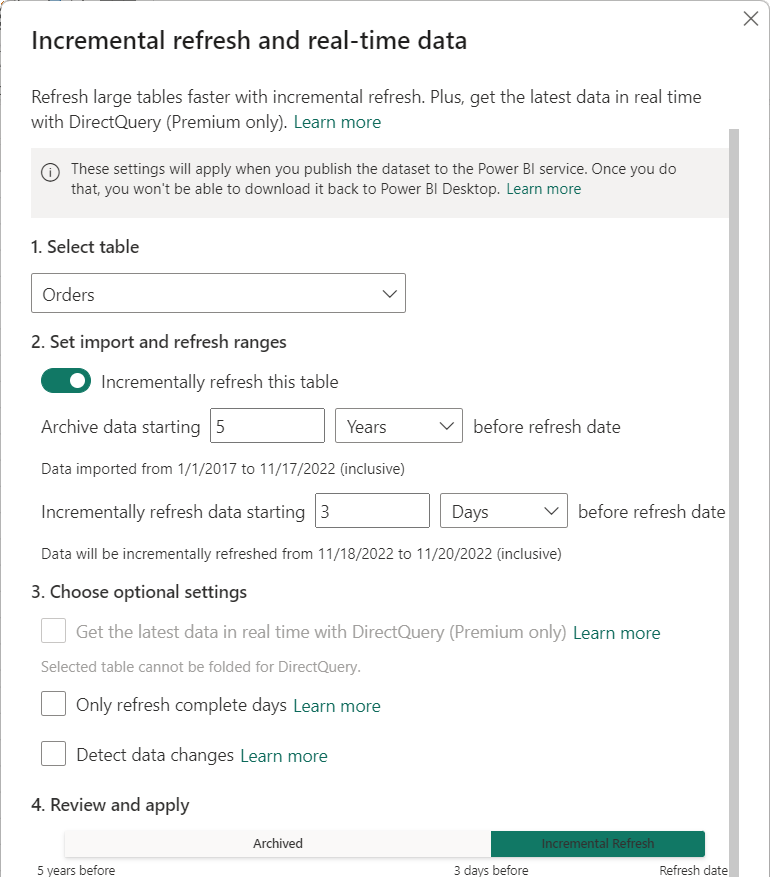
Register
Listrutan Välj tabell är som standard den tabell som du har valt i tabellvyn. Aktivera inkrementell uppdatering för tabellen med skjutreglaget. Om Power Query-uttrycket för tabellen inte innehåller ett filter baserat på parametrarna RangeStart och RangeEnd är växlingsknappen inte tillgänglig.
Nödvändiga inställningar
Inställningen Arkivdata som börjar före uppdateringsdatum avgör den historiska period där rader med ett datum/en tid under den perioden ingår i modellen, plus rader för den aktuella ofullständiga historiska perioden, plus rader i uppdateringsperioden fram till aktuellt datum och tid.
Om du till exempel anger fem år lagrar tabellen de senaste fem hela åren av historiska data i årspartitioner. Tabellen innehåller även rader för innevarande år i partitioner för kvartal, månad eller dag, upp till och med uppdateringsperioden.
För modeller i Premium-kapaciteter kan bakåtdaterade historiska partitioner uppdateras selektivt med en kornighet som bestäms av den här inställningen. Mer information finns i Avancerad inkrementell uppdatering – partitioner.
Inställningen Inkrementell uppdateringsdata som börjar före uppdateringsdatum avgör den inkrementella uppdateringsperiod där alla rader med datum/tid under den perioden ingår i uppdateringspartitionerna och uppdateras med varje uppdateringsåtgärd.
Om du till exempel anger en uppdateringsperiod på tre dagar, med varje uppdateringsåtgärd, åsidosätter RangeStart tjänsten parametrarna och RangeEnd för att skapa en fråga för rader med ett datum/en tid inom en tredagarsperiod, med början och slutet beroende på aktuellt datum och tid. Rader med datum/tid under de senaste tre dagarna fram till den aktuella uppdateringsåtgärdstiden uppdateras. Med den här typen av princip kan du förvänta dig att vår FactInternetSales-modelltabell i tjänsten, som i genomsnitt är 10 000 nya rader per dag, uppdaterar ungefär 30 000 rader med varje uppdateringsåtgärd.
Ange en period som endast innehåller det minsta antal rader som krävs för att säkerställa korrekt rapportering. När du definierar principer för mer än en tabell måste samma RangeStartRangeEnd och parametrar användas även om olika lagrings- och uppdateringsperioder definieras för varje tabell.
Valfria inställningar
Med inställningen Hämta de senaste data i realtid med DirectQuery (endast Premium) kan du hämta de senaste ändringarna från den valda tabellen i datakällan utöver den inkrementella uppdateringsperioden med hjälp av DirectQuery. Alla rader med ett datum/en tid senare än den inkrementella uppdateringsperioden ingår i en DirectQuery-partition och hämtas från datakällan med varje modellfråga.
Om den här inställningen till exempel är aktiverad, med varje uppdateringsåtgärd, åsidosätter RangeStart tjänsten fortfarande parametrarna och RangeEnd för att skapa en fråga för rader med ett datum/en tid efter uppdateringsperioden, med början beroende på aktuellt datum och tid. Rader med datum/tid efter den aktuella uppdateringsåtgärdstiden ingår också. Med den här typen av princip innehåller modeltabellen FactInternetSales i tjänsten de senaste datauppdateringarna.
Inställningen Endast fullständiga dagar säkerställer att alla rader för hela dagen ingår i uppdateringsåtgärden. Den här inställningen är valfri om du inte aktiverar inställningen Hämta de senaste data i realtid med DirectQuery (endast Premium). Anta till exempel att uppdateringen är schemalagd att köras 04:00 varje morgon. Om nya rader med data visas i datakällans tabell under dessa fyra timmar mellan midnatt och 04:00 vill du inte ta hänsyn till dem. Vissa affärsmått, som fat per dag i olje- och gasindustrin, är meningslösa med partiella dagar. Ett annat exempel är att uppdatera data från ett finansiellt system där data för föregående månad godkänns den tolfte kalenderdagen i månaden. Du kan ange uppdateringsperioden till en månad och schemalägga uppdateringen så att den körs den tolfte dagen i månaden. Med det här alternativet valt skulle det till exempel uppdatera januaridata den 12 februari.
Tänk på att om inte tidszonen under "Uppdatera" har konfigurerats för en icke-UTC en, körs uppdateringsåtgärder i tjänsten under UTC-tid, vilket kan fastställa giltighetsdatum och slutförandeperioder.
Inställningen Identifiera dataändringar möjliggör ännu mer selektiv uppdatering. Du kan välja en datum/tid-kolumn som bara används för att identifiera och uppdatera de dagar då data har ändrats. Den här inställningen förutsätter att en sådan kolumn finns i datakällan, vilket vanligtvis är i granskningssyfte. Den här kolumnen ska inte vara samma kolumn som används för att partitionera data med parametrarna RangeStart och RangeEnd . Det maximala värdet för den här kolumnen utvärderas för var och en av perioderna i det inkrementella intervallet. Om den inte har ändrats sedan den senaste uppdateringen behöver du inte uppdatera perioden, vilket potentiellt ytterligare kan minska de dagar som uppdateras stegvis från tre till en.
Den aktuella designen kräver att kolumnen för att identifiera dataändringar sparas och cachelagras i minnet. Följande tekniker kan användas för att minska kardinaliteten och minnesförbrukningen:
- Spara bara det maximala värdet för kolumnen vid tidpunkten för uppdateringen, kanske med hjälp av en Power Query-funktion.
- Minska precisionen till en acceptabel nivå med tanke på dina krav på uppdateringsfrekvens.
- Definiera en anpassad fråga för att identifiera dataändringar med hjälp av XMLA-slutpunkten och undvik att bevara kolumnvärdet helt och hållet.
I vissa fall kan alternativet Identifiera dataändringar förbättras ytterligare. Du kanske till exempel vill undvika att bevara en kolumn för senaste uppdatering i minnesintern cache, eller aktivera scenarier där en konfigurations-/instruktionstabell förbereds genom ETL-processer (extract-transform-load) för att endast flagga de partitioner som behöver uppdateras. I sådana fall, för Premium-kapaciteter, använder du TMSL och/eller TOM för att åsidosätta beteendet för att identifiera dataändringar. Mer information finns i Avancerad inkrementell uppdatering – Anpassade frågor för att identifiera dataändringar.
Publicera
När du har konfigurerat principen för inkrementell uppdatering publicerar du modellen till tjänsten. När publiceringen är klar kan du utföra den första uppdateringsåtgärden för modellen.
Kommentar
Semantiska modeller med en inkrementell uppdateringsprincip för att hämta de senaste data i realtid med DirectQuery kan bara publiceras till en Premium-arbetsyta.
Om du tror att modellen kommer att växa över 1 GB för modeller som publicerats till arbetsytor som tilldelats Premium-kapaciteter kan du förbättra uppdateringsåtgärdens prestanda och se till att modellen inte maxar storleksgränserna genom att aktivera inställningen Lagringsformat för stor semantisk modell innan du utför den första uppdateringsåtgärden i tjänsten. Mer information finns i Stora modeller i Power BI Premium.
Viktigt!
När Power BI Desktop har publicerat modellen till tjänsten kan du inte ladda ned .pbix-tillbaka .
Uppdatera
När du har publicerat till tjänsten utför du en inledande uppdateringsåtgärd för modellen. Den här uppdateringen bör vara en enskild (manuell) uppdatering så att du kan övervaka förloppet. Den inledande uppdateringsåtgärden kan ta ett tag att slutföra. Partitioner måste skapas, historiska data läses in, objekt som relationer och hierarkier skapas eller återskapas och beräknade objekt beräknas om.
Efterföljande uppdateringsåtgärder, antingen enskilda eller schemalagda, går mycket snabbare eftersom endast inkrementella uppdateringspartitioner uppdateras. Andra bearbetningsåtgärder måste fortfarande utföras, till exempel sammanslagning av partitioner och omberäkning, men det tar vanligtvis mycket mindre tid än den första uppdateringen.
Automatisk rapportuppdatering
För rapporter som använder en modell med en inkrementell uppdateringsprincip för att hämta de senaste data i realtid med DirectQuery är det en bra idé att aktivera automatisk siduppdatering med ett fast intervall eller baserat på ändringsidentifiering så att rapporterna innehåller de senaste data utan fördröjning. Mer information finns i Automatisk siduppdatering i Power BI.
Avancerad inkrementell uppdatering
Om din modell är på en Premium-kapacitet med en XMLA-slutpunkt aktiverad kan inkrementell uppdatering utökas ytterligare för avancerade scenarier. Du kan till exempel använda SQL Server Management Studio för att visa och hantera partitioner, starta den inledande uppdateringsåtgärden eller uppdatera bakåtdaterade historiska partitioner. Mer information finns i Avancerad inkrementell uppdatering med XMLA-slutpunkten.
Community
Power BI har en livlig community där MVP:er, BI-proffs och kollegor delar expertis i diskussionsgrupper, videor, bloggar med mera. När du lär dig mer om inkrementell uppdatering kan du läsa följande resurser:
- Power BI Community
- Sök efter "Inkrementell uppdatering i Power BI" i Bing
- Sök efter "Inkrementell uppdatering för filer" i Bing
- Sök "Behåll befintliga data med inkrementell uppdatering" på Bing