Förstå datavymappning i visuella Power BI-objekt
I den här artikeln beskrivs datavymappning och hur dataroller används för att skapa olika typer av visuella objekt. Den förklarar hur du anger villkorsstyrda krav för dataroller och de olika dataMappings typerna.
Varje giltig mappning skapar en datavy. Du kan ange flera datamappningar under vissa förhållanden. De mappningsalternativ som stöds är:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Power BI skapar en mappning till en datavy endast om den giltiga mappningen också definieras i dataViewMappings.
Med andra ord kan definieras i dataViewMappings men categorical andra mappningar, till exempel table eller single, kanske inte är det. I så fall skapar Power BI en datavy med en enda categorical mappning, medan table andra mappningar förblir odefinierade. Till exempel:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Villkor
Avsnittet conditions upprättar regler för en viss datamappning. Om data matchar en av de beskrivna uppsättningarna med villkor accepterar det visuella objektet data som giltiga.
För varje fält kan du ange ett lägsta och högsta värde. Värdet representerar antalet fält som kan bindas till den datarollen.
Kommentar
Om en dataroll utelämnas i villkoret kan den ha valfritt antal fält.
I följande exempel category är begränsad till ett datafält och measure är begränsad till två datafält.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Du kan också ange flera villkor för en dataroll. I så fall är data giltiga om något av villkoren uppfylls.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
I föregående exempel krävs något av följande två villkor:
- Exakt ett kategorifält och exakt två mått
- Exakt två kategorier och exakt ett mått
Enkel datamappning
Enkel datamappning är den enklaste formen av datamappning. Det accepterar ett enda måttfält och returnerar totalsumman. Om fältet är numeriskt returneras summan. Annars returneras antalet unika värden.
Om du vill använda enkel datamappning definierar du namnet på den dataroll som du vill mappa. Den här mappningen fungerar bara med ett enda måttfält. Om ett andra fält tilldelas genereras ingen datavy, så det är bra att inkludera ett villkor som begränsar data till ett enda fält.
Kommentar
Den här datamappningen kan inte användas tillsammans med någon annan datamappning. Det är avsett att minska data till ett enda numeriskt värde.
Till exempel:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
Den resulterande datavyn kan fortfarande innehålla andra typer av mappning, t.ex. tabell eller kategorisk, men varje mappning innehåller bara det enskilda värdet. Det bästa sättet är att endast komma åt värdet i enskild mappning.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
Följande kodexempel bearbetar enkel datavymappning:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
Det tidigare kodexemplet resulterar i visning av ett enda värde från Power BI:
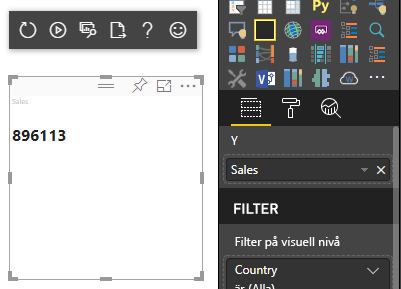
Kategorisk datamappning
Kategorisk datamappning används för att hämta oberoende grupper eller kategorier av data. Kategorierna kan också grupperas tillsammans med hjälp av "gruppera efter" i datamappningen.
Grundläggande kategorisk datamappning
Överväg följande dataroller och mappningar:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
I föregående exempel står det "Mappa min category dataroll så att dess data mappas till för varje fält jag drar till categorical.categoriescategory. Mappa även min measure dataroll till categorical.values.
- för... i: Innehåller alla objekt i den här datarollen i datafrågan.
- binda... till: Ger samma resultat som för... i men förväntar sig att datarollen har ett villkor som begränsar den till ett enda fält.
Gruppera kategoridata
I nästa exempel används samma två dataroller som i föregående exempel och ytterligare två dataroller med namnet grouping och measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
Skillnaden mellan den här mappningen och den grundläggande mappningen är hur categorical.values mappas. När du mappar datarollerna measure och measure2 till datarollen groupingkan x-axeln och y-axeln skalas på rätt sätt.
Gruppera hierarkiska data
I nästa exempel används kategoridata för att skapa en hierarki som kan användas för att stödja åtgärder för ökad detaljnivå .
I följande exempel visas dataroller och mappningar:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Tänk på följande kategoriska data:
| Land/region | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | x | x | 650 | 350 |
| Kanada | x | 630 | 490 | x |
| Mexico | 645 | x | x | x |
| Storbritannien | x | x | 831 | x |
Power BI skapar en kategorisk datavy med följande uppsättning kategorier.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Varje category mappas till en uppsättning med values. Var och en av dessa values grupperas efter series, vilket uttrycks som år.
Till exempel representerar varje values matris ett år.
Dessutom har varje values matris fyra värden: Kanada, USA, Storbritannien och Mexiko.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
Följande kodexempel är för bearbetning av kategorisk datavymappning. Det här exemplet skapar den hierarkiska strukturen Country/Region > Year > Value.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
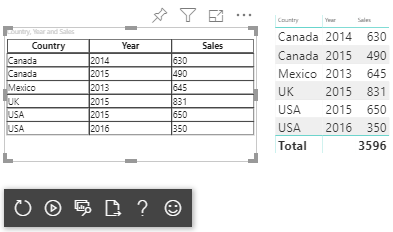
Här är det resulterande visuella objektet:
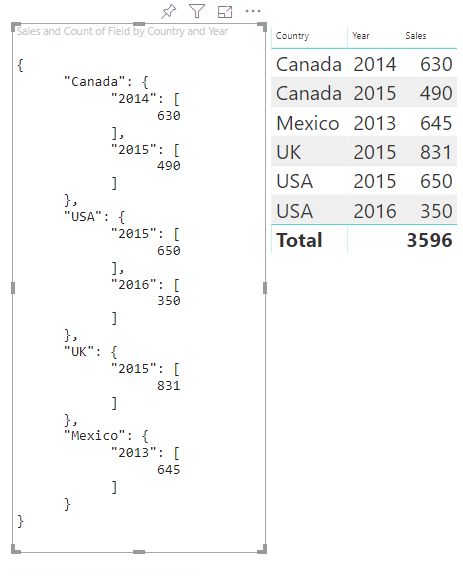
Mappa tabeller
Tabelldatavyn är i princip en lista över datapunkter där numeriska datapunkter kan aggregeras.
Använd till exempel samma data i föregående avsnitt, men med följande funktioner:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
Visualisera tabelldatavyn så här:
| Land/region | Year | Sales |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Kanada | 2015 | 200 |
| Kanada | 2015 | 50 |
| Mexico | 2013 | 300 |
| Storbritannien | 2014 | 150 |
| USA | 2015 | 75 |
Databindning:
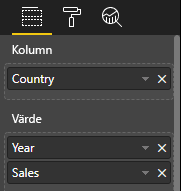
Power BI visar dina data som tabelldatavy. Anta inte att data är ordnade.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Om du vill aggregera data väljer du önskat fält och väljer sedan Summa.
Kodexempel för att bearbeta mappning av tabelldatavyer.
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Filen style/visual.less med visuella format innehåller layouten för tabellen:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Det resulterande visuella objektet ser ut så här:
Matrisdatamappning
Matrisdatamappning liknar tabelldatamappning, men raderna presenteras hierarkiskt. Alla datarollvärden kan användas som ett kolumnhuvudvärde.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
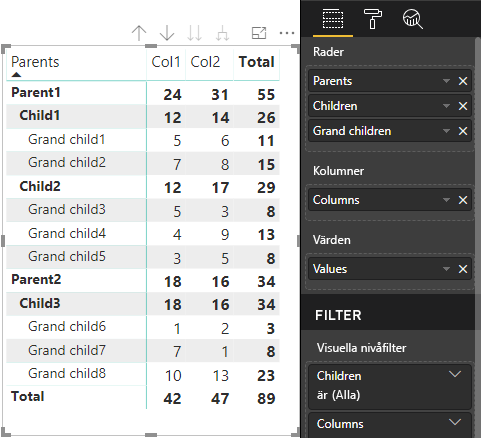
Hierarkisk struktur för matrisdata
Power BI skapar en hierarkisk datastruktur. Roten i trädhierarkin innehåller data från kolumnen Överordnade i datarollen Category med underordnade från kolumnen Underordnade i datarolltabellen.
Semantisk modell:
| Överordnade | Underordnade | Barnbarn | Kolumner | Värden |
|---|---|---|---|---|
| Överordnad 1 | Underordnad1 | Grand child1 | Col1 | 5 |
| Överordnad 1 | Underordnad1 | Grand child1 | Col2 | 6 |
| Överordnad 1 | Underordnad1 | Grand child2 | Col1 | 7 |
| Överordnad 1 | Underordnad1 | Grand child2 | Col2 | 8 |
| Överordnad 1 | Underordnad 2 | Grand child3 | Col1 | 5 |
| Överordnad 1 | Underordnad 2 | Grand child3 | Col2 | 3 |
| Överordnad 1 | Underordnad 2 | Grand child4 | Col1 | 4 |
| Överordnad 1 | Underordnad 2 | Grand child4 | Col2 | 9 |
| Överordnad 1 | Underordnad 2 | Grand child5 | Col1 | 3 |
| Överordnad 1 | Underordnad 2 | Grand child5 | Col2 | 5 |
| Överordnad 2 | Underordnad 3 | Grand child6 | Col1 | 1 |
| Överordnad 2 | Underordnad 3 | Grand child6 | Col2 | 2 |
| Överordnad 2 | Underordnad 3 | Grand child7 | Col1 | 7 |
| Överordnad 2 | Underordnad 3 | Grand child7 | Col2 | 1 |
| Överordnad 2 | Underordnad 3 | Grand child8 | Col1 | 10 |
| Överordnad 2 | Underordnad 3 | Grand child8 | Col2 | 13 |
Det visuella kärnmatrisobjektet i Power BI renderar data som en tabell.
Det visuella objektet hämtar sin datastruktur enligt beskrivningen i följande kod (endast de två första tabellraderna visas här):
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Expandera och dölj radrubriker
För API 4.1.0 eller senare har matrisdata stöd för att expandera och komprimera radrubriker. Från API 4.2 kan du expandera/komprimera hela nivån programmatiskt. Funktionen expandera och dölj optimerar hämtningen av data till dataView genom att tillåta att användaren expanderar eller döljer en rad utan att hämta alla data för nästa nivå. Den hämtar bara data för den valda raden. Radrubrikens expansionstillstånd förblir konsekvent mellan bokmärken och även över sparade rapporter. Det är inte specifikt för varje visuellt objekt.
Expandera och dölj kommandon kan läggas till i snabbmenyn genom att ange parametern dataRoles till showContextMenu metoden.
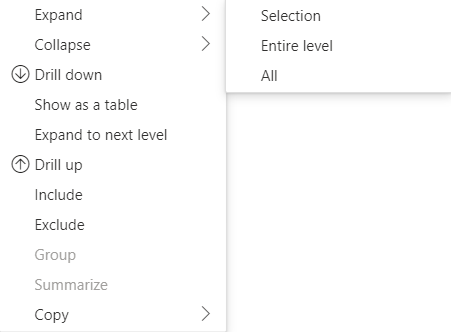
Om du vill expandera ett stort antal datapunkter använder du hämtningen av fler data-API :et med expand/collapse-API:et.
API-funktioner
Följande element har lagts till i API-version 4.1.0 för att aktivera expanderande och komprimerande radrubriker:
Flaggan
isCollapsediDataViewTreeNode:interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }Metoden
toggleExpandCollapseiISelectionMangergränssnittet:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }Flaggan
canBeExpandedi DataViewHierarchyLevel:interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Visuella krav
Så här aktiverar du funktionen dölj expandera i ett visuellt objekt med hjälp av matrisdatavyn:
Lägg till följande kod i filen capabilities.json:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Kontrollera att rollerna är visningsbara:
"drilldown": { "roles": ["Rows"] },För varje nod skapar du en instans av markeringsverktyget genom att anropa
withMatrixNodemetoden på den valda nodhierarkinivån och skapa enselectionId. Till exempel:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Skapa en instans av markeringshanteraren och använd
selectionManager.toggleExpandCollapse()metoden med parameternselectionId, som du skapade för den valda noden. Till exempel:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Kommentar
- Om den valda noden inte är en radnod ignorerar PowerBI expandera och dölj anrop och kommandona expandera och dölj tas bort från snabbmenyn.
- Parametern
dataRoleskrävs endast förshowContextMenumetoden om det visuella objektet stöderdrilldownellerexpandCollapsehar funktioner. Om det visuella objektet har stöd för dessa funktioner men dataRoles inte har angetts kommer ett fel att skickas till konsolen när du använder det visuella utvecklarobjektet eller om felsökning av ett offentligt visuellt objekt med felsökningsläget aktiverat.
Beaktanden och begränsningar
- När du har expanderat en nod tillämpas nya datagränser på DataView. Den nya DataView kanske inte innehåller några av noderna som presenterades i föregående DataView.
- När du använder expandera eller komprimera läggs summor till även om det visuella objektet inte begärde dem.
- Det går inte att expandera och komprimera kolumner.
Behåll alla metadatakolumner
För API 5.1.0 eller senare stöds alla metadatakolumner. Med den här funktionen kan det visuella objektet ta emot metadata för alla kolumner oavsett vilka deras aktiva projektioner är.
Lägg till följande rader i din capabilities.json-fil :
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Om du anger den här egenskapen till true får du alla metadata, inklusive från komprimerade kolumner. Om du ställer in den på false eller lämnar den odefinierad får du endast metadata för kolumner med aktiva projektioner (expanderade, till exempel).
Algoritm för dataminskning
Algoritmen för dataminskning styr vilka data och hur mycket data som tas emot i datavyn.
Antalet anges till det maximala antalet värden som datavyn kan acceptera. Om det finns fler än antal värden avgör algoritmen för dataminskning vilka värden som ska tas emot.
Typer av algoritmer för dataminskning
Det finns fyra typer av inställningar för algoritmer för dataminskning:
top: De första värdena för antal hämtas från den semantiska modellen.bottom: De sista värdena för antal hämtas från den semantiska modellen.sample: De första och sista objekten inkluderas och antalet objekt med samma intervall mellan dem. Om du till exempel har en semantisk modell [0, 1, 2, ... 100] och antalet 9 får du värdena [0, 10, 20 ... 100].window: Läser in ett fönster med datapunkter i taget som innehåller antal element.topFör närvarande ochwindowär likvärdiga. I framtiden kommer en fönsterinställning att stödjas fullt ut.
Som standard har alla visuella Power BI-objekt den främsta dataminskningsalgoritmen tillämpad med antalet inställt på 1 000 datapunkter. Den här standardinställningen motsvarar inställningen av följande egenskaper i filen capabilities.json :
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Du kan ändra antalsvärdet till valfritt heltalsvärde upp till 30000. R-baserade visuella Power BI-objekt kan ha stöd för upp till 15 000 rader.
Användning av algoritmer för dataminskning
Algoritmen för dataminskning kan användas i kategorisk datavymappning, tabell eller matrisvymappning.
I kategorisk datamappning kan du lägga till algoritmen i avsnittet values "kategorier" och/eller "grupp" för kategorisk datamappning.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
I mappning av tabelldatavy tillämpar du algoritmen för dataminskning på rows avsnittet i mappningstabellen för datavyn.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Du kan använda algoritmen för dataminskning på avsnitten rows och columns i datavyns mappningsmatris.