Skapa viktiga visualiseringar för påverkare
GÄLLER FÖR:![]() Power BI Desktop-Power BI-tjänst
Power BI Desktop-Power BI-tjänst ![]()
Det visuella objektet för viktiga påverkare hjälper dig att förstå de faktorer som driver ett mått som du är intresserad av. Den analyserar dina data, rangordnar de faktorer som är viktiga och visar dem som viktiga påverkare. Anta till exempel att du vill ta reda på vad som påverkar medarbetarnas omsättning, vilket även kallas omsättning. En faktor kan vara anställningsavtalens längd, och en annan faktor kan vara pendlingstiden.
När du ska använda viktiga påverkare
Det visuella objektet för viktiga påverkare är ett bra val om du vill:
- Se vilka faktorer som påverkar måttet som analyseras.
- Kontrastera de här faktorernas relativa betydelse. Påverkar till exempel kortsiktiga kontrakt omsättning mer än långsiktiga kontrakt?
Funktioner i det visuella objektet för viktiga påverkare
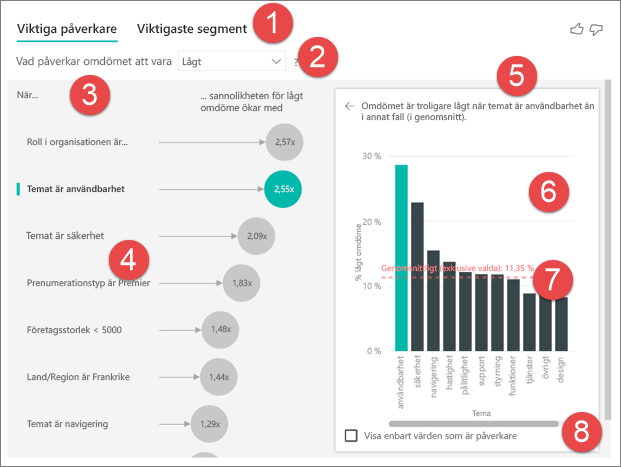
Flikar: Välj en flik för att växla mellan vyer. Viktiga påverkare visar de främsta bidragsgivarna till det valda måttvärdet. De översta segmenten visar de viktigaste segmenten som bidrar till det valda måttvärdet. Ett segment består av en kombination av värden. Ett segment kan till exempel vara konsumenter som har varit kunder i minst 20 år och bor i regionen västra.
Listruta: Värdet för måttet som undersöks. I det här exemplet tittar du på måttklassificeringen. Det valda värdet är Låg.
Omläggning: Det hjälper dig att tolka det visuella objektet i den vänstra rutan.
Vänster fönsterruta: Det vänstra fönstret innehåller ett visuellt objekt. I det här fallet visar det vänstra fönstret en lista över de viktigaste påverkarna.
Omläggning: Det hjälper dig att tolka det visuella objektet i den högra rutan.
Höger fönsterruta: Det högra fönstret innehåller ett visuellt objekt. I det här fallet visar kolumndiagrammet alla värden för nyckel påverkaren Tema som har valts i den vänstra rutan. Det specifika värdet för användbarhet från den vänstra rutan visas i grönt. Alla andra värden för Tema visas i svart.
Genomsnittlig rad: Medelvärdet beräknas för alla möjliga värden för Tema utom användbarhet (som är den valda påverkaren). Beräkningen gäller alltså för alla värden i svart. Den visar vilken procentandel av de andra temana som hade ett lågt omdöme. I det här fallet hade 11,35 % ett lågt omdöme (visas av den streckade linjen).
Kryssruta: Filtrerar ut det visuella objektet i den högra rutan för att endast visa värden som är påverkare för det fältet. I det här exemplet filtreras det visuella objektet för att visa användbarhet, säkerhet och navigering.
Analysera ett mått som är kategoriskt
Titta på den här videon om du vill lära dig hur du skapar ett visuellt objekt för viktiga påverkare med ett kategoriskt mått. Följ sedan stegen för att skapa en.
Kommentar
Den här videon kan använda tidigare versioner av Power BI Desktop eller Power BI-tjänst.
- Produktchefen vill att du ska ta reda på vilka faktorer som leder till att kunderna lämnar negativa recensioner om din molntjänst. Om du vill följa med i Power BI Desktop öppnar du PBIX-filen för kundfeedback.
Kommentar
Datauppsättningen Kundfeedback baseras på [Moro et al., 2014] S. Moro, P. Cortez och P. Rita. "En datadriven metod för att förutsäga framgången för banktelemarketing." Beslutsstödsystem, Elsevier, 62:22-31, juni 2014.
Under Skapa visuellt objekt i fönstret Visualiseringar väljer du ikonen Viktiga påverkare .
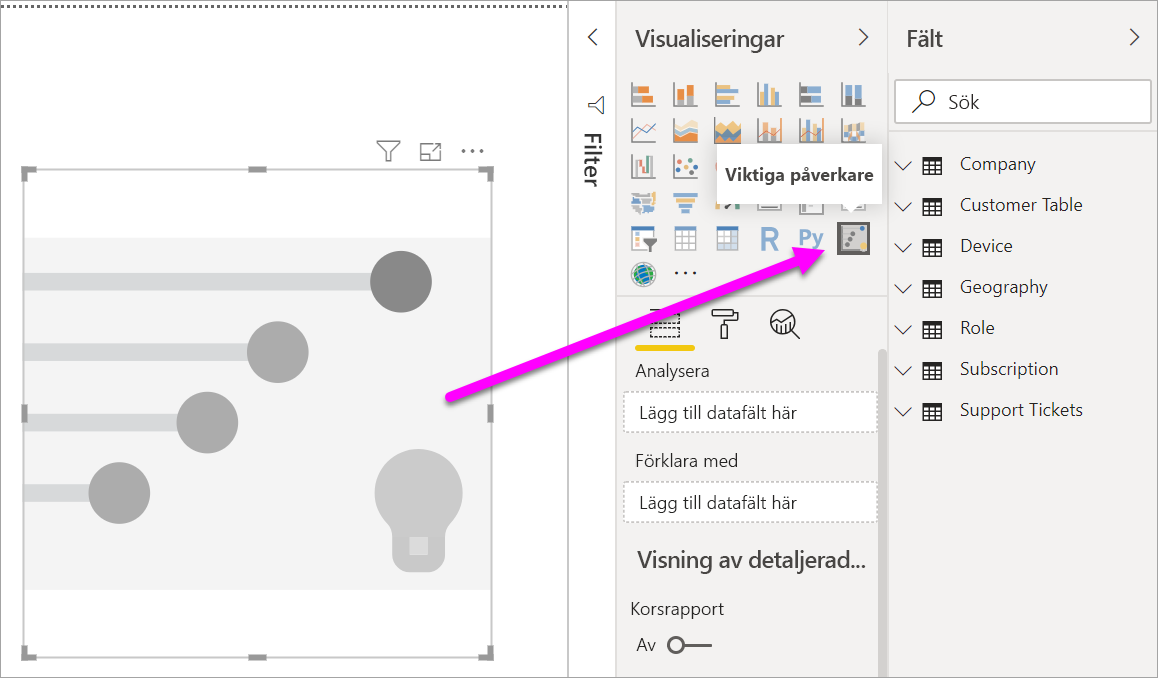
Flytta måttet som du vill undersöka till fältet Analysera . Om du vill se vad som driver en kundklassificering av tjänsten till låg väljer du Kundtabellklassificering>.
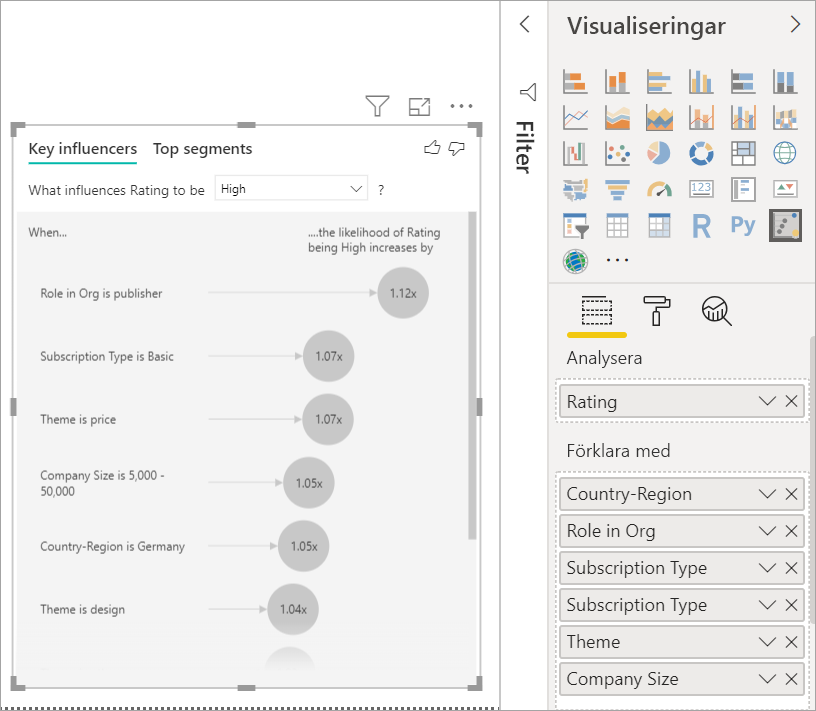
Flytta fält som du tror kan påverka Omdöme till fältet Förklara efter . Du kan flytta så många fält du vill. I det här fallet börjar du med:
- Country-Region
- Roll i organisationen
- Prenumerationstyp
- Företagets storlek
- Theme
Lämna fältet Expandera efter tomt. Det här fältet används bara när du analyserar ett mått eller ett sammanfattat fält.
Om du vill fokusera på de negativa omdömena väljer du Låg i listrutan Vad påverkar omdömet .
Analysen körs på tabellnivå för det fält som analyseras. I det här fallet är det måttet Omdöme . Det här måttet definieras på kundnivå. Varje kund har gett antingen en hög poäng eller en låg poäng. Alla förklarande faktorer måste definieras på kundnivå för att det visuella objektet ska kunna använda dem.
I föregående exempel har alla förklarande faktorer antingen en-till-en- eller många-till-en-relation med måttet. I det här fallet tilldelade varje kund ett enda tema till sitt omdöme. På samma sätt kommer kunderna från ett land eller en region, har en medlemskapstyp och har en roll i organisationen. De förklarande faktorerna är redan attribut för en kund och inga transformeringar behövs. Det visuella objektet kan använda dem omedelbart.
Senare i självstudien tittar du på mer komplexa exempel som har en-till-många-relationer. I dessa fall måste kolumnerna först aggregeras ned till kundnivå innan du kan köra analysen.
Mått och aggregeringar som används som förklarande faktorer utvärderas också på tabellnivå för måttet Analysera . Några exempel visas senare i den här artikeln.
Tolka kategoriska viktiga påverkare
Låt oss ta en titt på de viktigaste påverkarna för låga omdömen.
Högsta enskilda faktor som påverkar sannolikheten för ett lågt omdöme
Kunden i det här exemplet kan ha tre roller: konsument, administratör och utgivare. Att vara konsument är den viktigaste faktorn som bidrar till ett lågt omdöme.
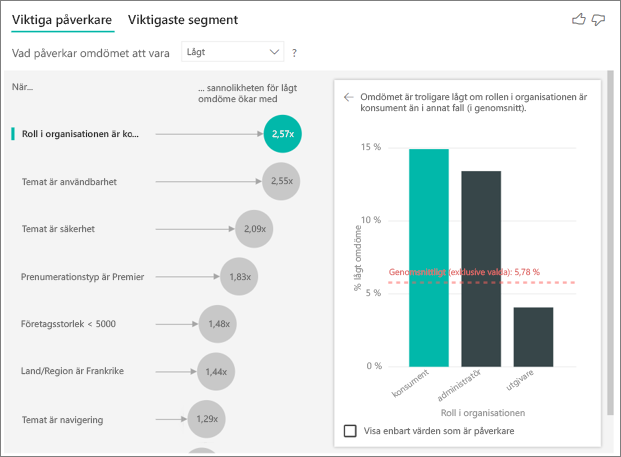
Mer exakt är dina konsumenter 2,57 gånger mer benägna att ge din tjänst en negativ poäng. Diagrammet viktiga påverkare listar Roll i organisationen är konsument först i listan till vänster. Genom att välja Roll i organisationen är konsument visar Power BI mer information i det högra fönstret. Den jämförande effekten av varje roll på sannolikheten för ett lågt omdöme visas.
- 14,93 % av konsumenterna ger en låg poäng.
- I genomsnitt ger alla andra roller en låg poäng 5,78 % av tiden.
- Konsumenter är 2,57 gånger mer benägna att ge en låg poäng jämfört med alla andra roller. Du kan fastställa den här poängen genom att dividera det gröna fältet med den röda streckade linjen.
Den andra enskilda faktorn som påverkar sannolikheten för ett lågt omdöme
Det visuella objektet för viktiga påverkare jämför och rangordnar faktorer från många olika variabler. Den andra påverkaren har inget att göra med roll i organisationen. Välj den andra påverkaren i listan, som är Tema är användbarhet.
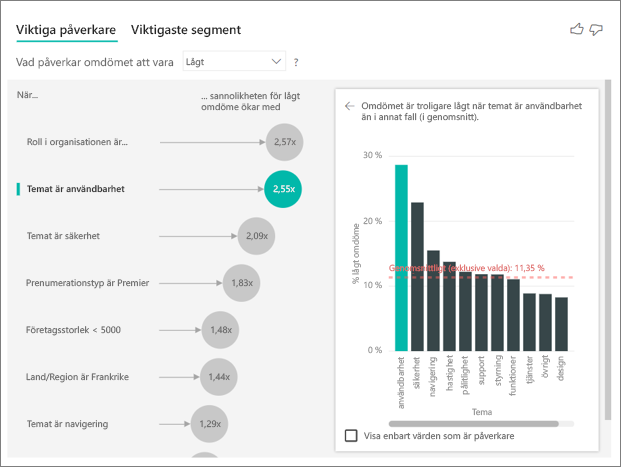
Den näst viktigaste faktorn är relaterad till temat för kundens granskning. Kunder som kommenterade produktens användbarhet var 2,55 gånger mer benägna att ge en låg poäng jämfört med kunder som kommenterade andra teman, till exempel tillförlitlighet, design eller hastighet.
Mellan de visuella objekten ändrades medelvärdet, som visas av den röda streckade linjen, från 5,78 % till 11,35 %. Genomsnittet är dynamiskt eftersom det baseras på medelvärdet av alla andra värden. För den första påverkaren exkluderade medelvärdet kundrollen. För den andra påverkaren exkluderades användbarhetstemat.
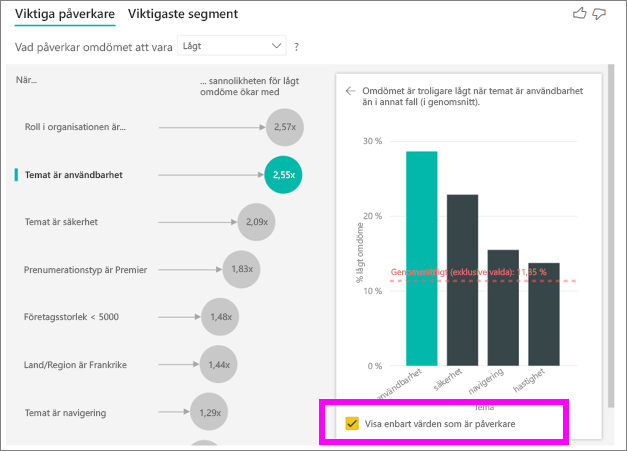
Markera kryssrutan Visa endast värden som är påverkare om du bara vill filtrera med hjälp av de inflytelserika värdena. I det här fallet är det de roller som ger låg poäng. 12 teman reduceras till de fyra som Power BI har identifierat som teman som ger låga omdömen.
Interagera med andra visuella objekt
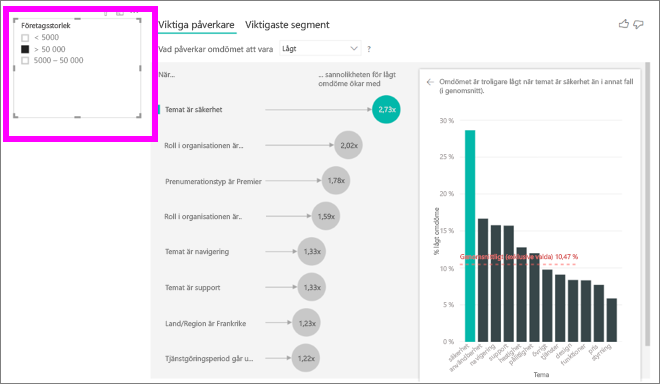
Varje gång du väljer ett utsnitt, filter eller annat visuellt objekt på arbetsytan kör det visuella objektet viktiga påverkare sin analys på den nya delen av data. Du kan till exempel flytta Företagsstorlek till rapporten och använda den som utsnitt. Använd den för att se om de viktigaste påverkarna för dina företagskunder skiljer sig från den allmänna populationen. Företagets storlek är större än 50 000 anställda.
Välj >50 000 för att köra analysen igen, så kan du se att påverkarna har ändrats. För stora företagskunder har den främsta påverkaren för låga omdömen ett tema som rör säkerhet. Du kanske vill undersöka ytterligare för att se om det finns specifika säkerhetsfunktioner som dina stora kunder är missnöjda med.
Tolka kontinuerliga viktiga påverkare
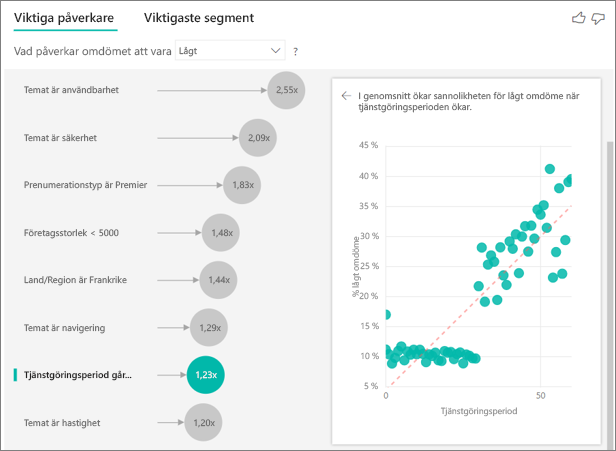
Hittills har du sett hur du använder det visuella objektet för att utforska hur olika kategoriska fält påverkar låga omdömen. Det går också att ha kontinuerliga faktorer som ålder, höjd och pris i fältet Förklara efter . Nu ska vi titta på vad som händer när Tenure flyttas från kundtabellen till Förklara med. Besittningsrätt visar hur länge en kund har använt tjänsten.
När besittningsrätten ökar ökar också sannolikheten för att få ett lägre betyg. Denna trend tyder på att de långsiktiga kunderna är mer benägna att ge en negativ poäng. Den här insikten är intressant och en som du kanske vill följa upp senare.
Visualiseringen visar att varje gång anställningen ökar med 13,44 månader ökar sannolikheten för ett lågt omdöme i genomsnitt med 1,23 gånger. I det här fallet visar 13,44 månader standardavvikelsen för besittningsrätt. Så insikten du får tittar på hur ökad anställning med ett standardbelopp, vilket är standardavvikelsen för besittningsrätten, påverkar sannolikheten för att få ett lågt omdöme.
Punktdiagrammet i den högra rutan ritar den genomsnittliga procentandelen låga omdömen för varje värde för period. Lutningen markeras med en trendlinje.
Influerare med kontinuerlig nyckel i binned
I vissa fall kan du upptäcka att dina kontinuerliga faktorer automatiskt omvandlades till kategoriska faktorer. Om relationen mellan variablerna inte är linjär kan vi inte beskriva relationen som att bara öka eller minska (som vi gjorde i exemplet ovan).
Vi kör korrelationstester för att avgöra hur linjär påverkaren är när det gäller målet. Om målet är kontinuerligt kör vi Pearson-korrelation och om målet är kategoriskt kör vi Point Biserial-korrelationstester. Om vi upptäcker att relationen inte är tillräckligt linjär utför vi övervakad binning och genererar högst fem lagerplatser. För att ta reda på vilka lagerplatser som är mest meningsfulla använder vi en övervakad binningsmetod som tittar på relationen mellan den förklarande faktorn och det mål som analyseras.
Tolka mått och aggregeringar som viktiga påverkare
Du kan använda mått och aggregeringar som förklarande faktorer i analysen. Du kanske till exempel vill se vilken effekt antalet kundsupportärenden eller den genomsnittliga varaktigheten för en öppen biljett har på poängen du får.
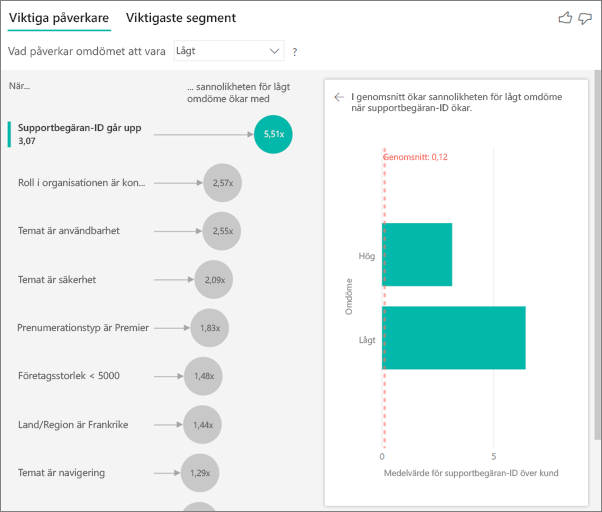
I det här fallet vill du se om antalet supportärenden som en kund har påverkar poängen de ger. Nu tar du in supportbiljett-ID från supportbiljetttabellen. Eftersom en kund kan ha flera supportärenden aggregerar du ID:t till kundnivå. Sammansättning är viktigt eftersom analysen körs på kundnivå, så alla drivrutiner måste definieras på den detaljnivån.
Nu ska vi titta på antalet ID:er. Varje kundrad har ett antal supportärenden som är associerade med den. I det här fallet ökar sannolikheten för att betyget är lågt 4,08 gånger när antalet supportärenden ökar. Det visuella objektet till höger visar det genomsnittliga antalet supportärenden efter olika omdömesvärden som utvärderas på kundnivå.
Tolka resultaten: De viktigaste segmenten
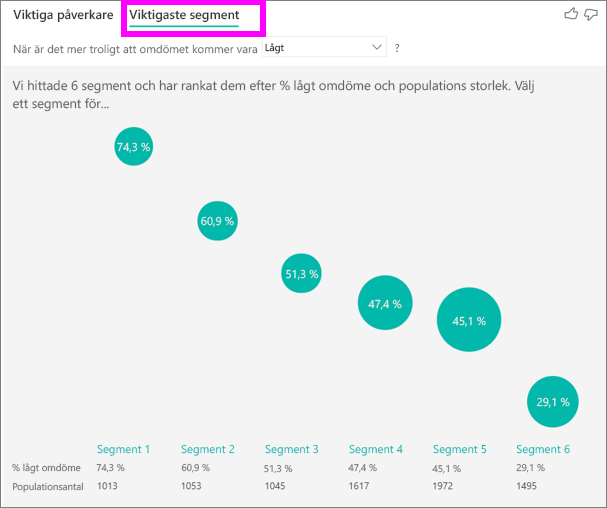
Du kan använda fliken Viktiga påverkare för att utvärdera varje faktor individuellt. Du kan också använda fliken Översta segment för att se hur en kombination av faktorer påverkar det mått som du analyserar.
De översta segmenten visar inledningsvis en översikt över alla segment som Power BI har identifierat. I följande exempel visas att sex segment hittades. Dessa segment rangordnas efter procentandelen låga omdömen inom segmentet. Segment 1 har till exempel 74,3 % kundklassificeringar som är låga. Desto högre bubbla, desto högre andel låga omdömen. Storleken på bubblan representerar hur många kunder som finns inom segmentet.
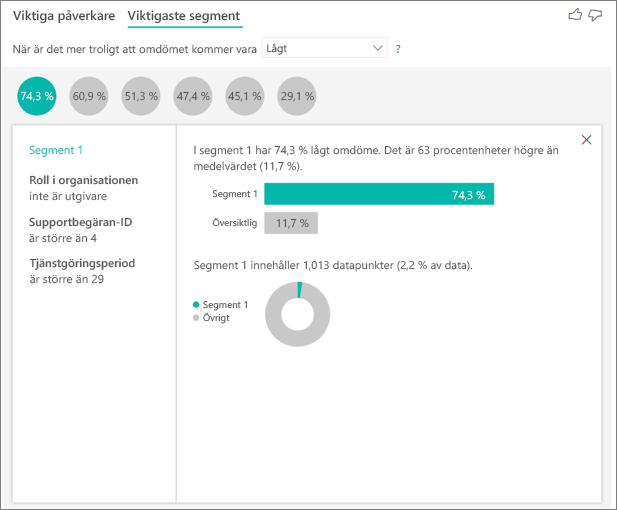
Om du väljer en bubbla visas information om segmentet. Om du till exempel väljer Segment 1 upptäcker du att det består av relativt etablerade kunder. De har varit kunder i över 29 månader och har mer än fyra supportärenden. Slutligen är de inte utgivare, så de är antingen konsumenter eller administratörer.
I den här gruppen gav 74,3 % av kunderna ett lågt omdöme. Den genomsnittliga kunden gav ett lågt omdöme 11,7 % av tiden, så det här segmentet har en större andel låga omdömen. Det är 63 procentenheter högre. Segment 1 innehåller också cirka 2,2 % av data, så det representerar en adresserbar del av populationen.
Lägga till antal
Ibland kan en påverkare ha en betydande effekt men representerar lite av data. Tema är till exempel användbarhet är den tredje största påverkaren för låga omdömen. Det kan dock bara ha funnits en handfull kunder som klagade över användbarhet. Counts kan hjälpa dig att prioritera vilka påverkare du vill fokusera på.
Du kan aktivera antal via analyskortet i formateringsfönstret.
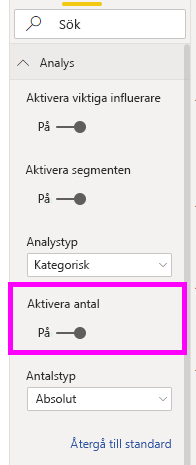
När antalet har aktiverats ser du en ring runt varje påverkarens bubbla, som representerar den ungefärliga procentandelen data som påverkaren innehåller. Ju mer av bubblan ringen cirklar, desto mer data innehåller den. Vi kan se att Tema är användbarhet innehåller en liten del av data.
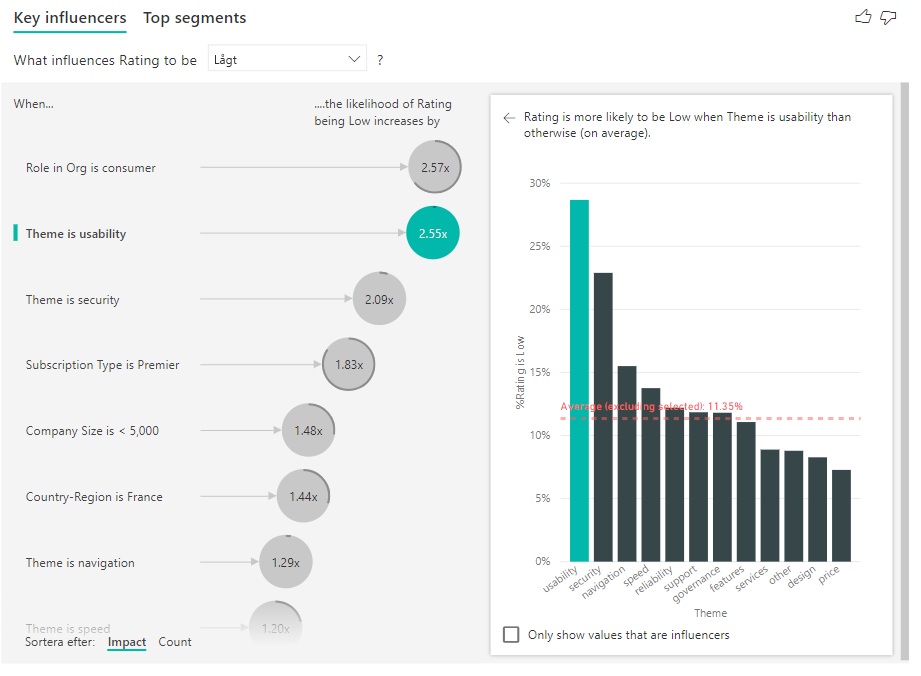
Du kan också använda växlingsknappen Sortera efter längst ned till vänster i det visuella objektet för att sortera bubblorna efter antal först i stället för påverkan. Prenumerationstyp är Premier är den främsta påverkaren baserat på antal.
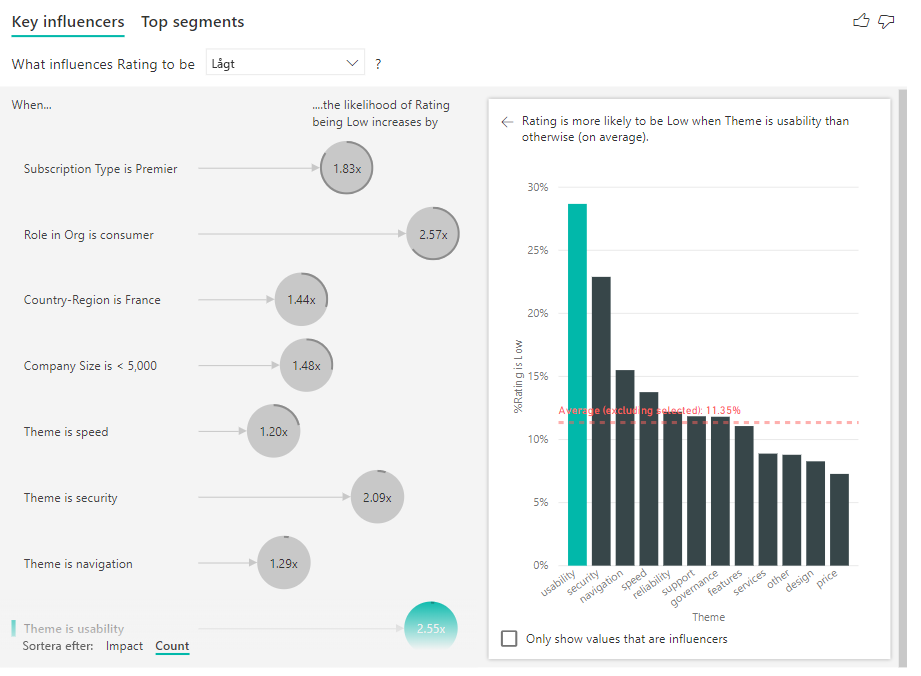
Att ha en fullständig ring runt cirkeln innebär att påverkaren innehåller 100 % av data. Du kan ändra antalstypen så att den är relativ till den maximala påverkaren med listrutan Antal typ i analyskortet i formateringsfönstret. Nu representeras påverkaren med mest data av en fullständig ring och alla andra antal kommer att vara i förhållande till den.
Analysera ett mått som är numeriskt
Om du flyttar ett osummat numeriskt fält till fältet Analysera kan du välja hur du ska hantera det scenariot. Du kan ändra beteendet för det visuella objektet genom att gå till formateringsfönstret och växla mellan kategorisk analystyp och typ av kontinuerlig analys.
En kategorisk analystyp beter sig enligt beskrivningen ovan. Om du till exempel tittade på undersökningspoäng från 1 till 10 kan du fråga "Vad påverkar undersökningspoängen till att vara 1?"
En typ av kontinuerlig analys ändrar frågan till en kontinuerlig. I exemplet ovan skulle vår nya fråga vara "Vad påverkar undersökningspoängen att öka/minska?"
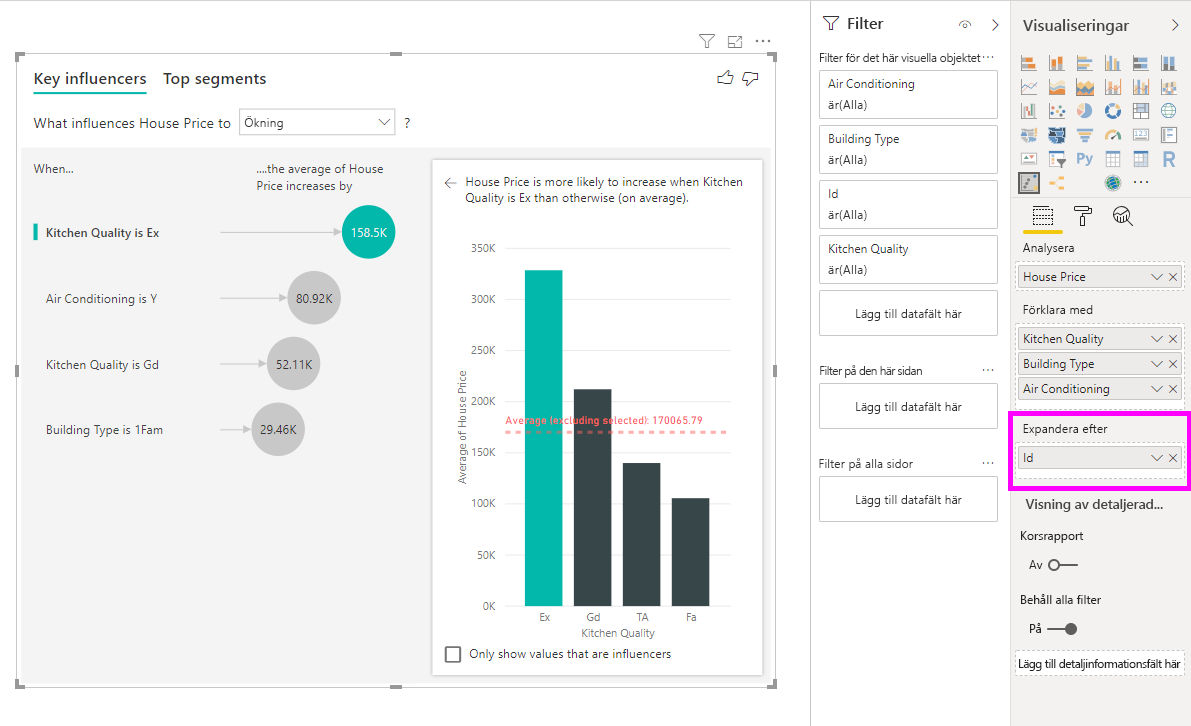
Den här skillnaden är användbar när du har många unika värden i det fält som du analyserar. I exemplet nedan tittar vi på huspriser. Det är inte meningsfullt att fråga "Vad påverkar huspriset att vara 156 214?" eftersom det är mycket specifikt och vi sannolikt inte har tillräckligt med data för att härleda ett mönster.
I stället kanske vi vill fråga: "Vad påverkar huspriset att öka"? vilket gör att vi kan behandla huspriser som ett intervall snarare än distinkta värden.
Tolka resultaten: Viktiga påverkare
Kommentar
Exemplen i det här avsnittet använder husprisdata för offentlig domän. Du kan ladda ned exempeldatauppsättningen om du vill följa med.
I det här scenariot tittar vi på "Vad påverkar huspriset att öka". Ett antal förklarande faktorer kan påverka ett huspris som Year Built (år huset byggdes), KitchenQual (kökskvalitet) och YearRemodAdd (år då huset byggdes om).
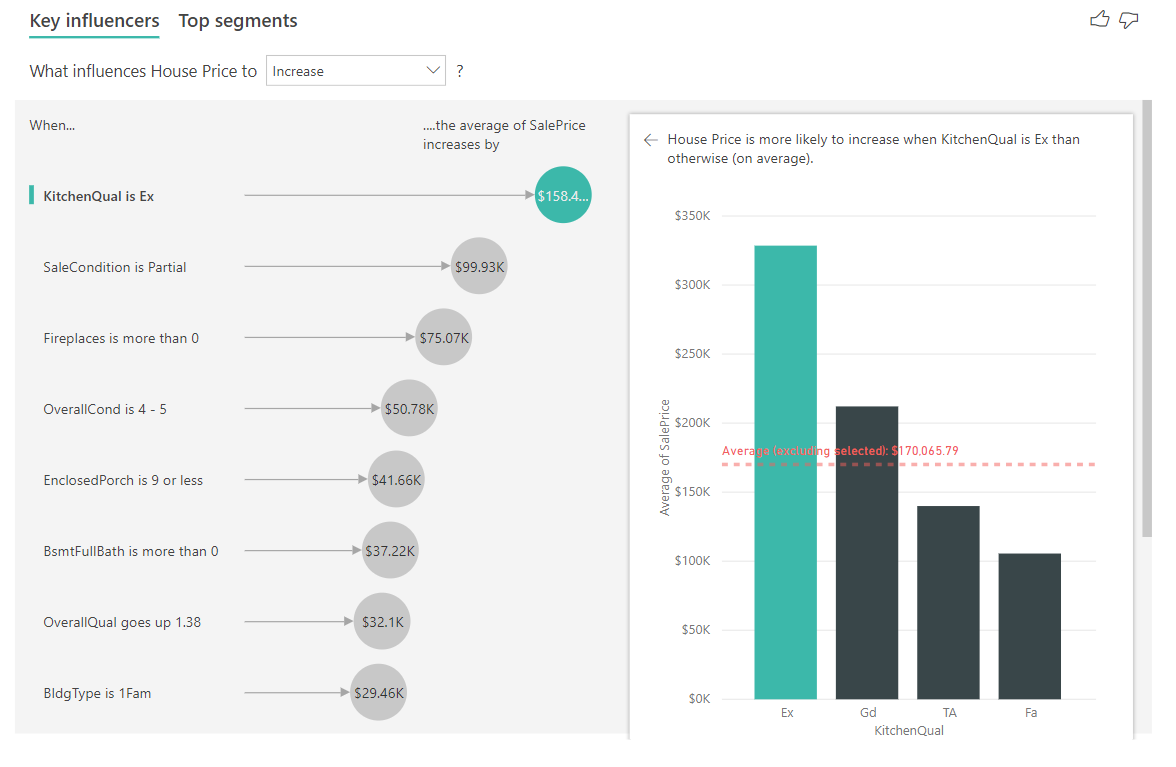
I exemplet nedan tittar vi på vår bästa influencer som är kökskvaliteten är Utmärkt. Resultaten liknar de som vi såg när vi analyserade kategoriska mått med några viktiga skillnader:
- Kolumndiagrammet till höger tittar på medelvärdena snarare än procentsatserna. Det visar oss därför vad det genomsnittliga huspriset för ett hus med ett utmärkt kök är (grön bar) jämfört med det genomsnittliga huspriset för ett hus utan ett utmärkt kök (prickad linje)
- Talet i bubblan är fortfarande skillnaden mellan den röda streckade linjen och det gröna fältet, men det uttrycks som ett tal (158,49 000 usd) i stället för sannolikheten (1,93 x). Så i genomsnitt är hus med utmärkta kök nästan $ 160K dyrare än hus utan utmärkta kök.
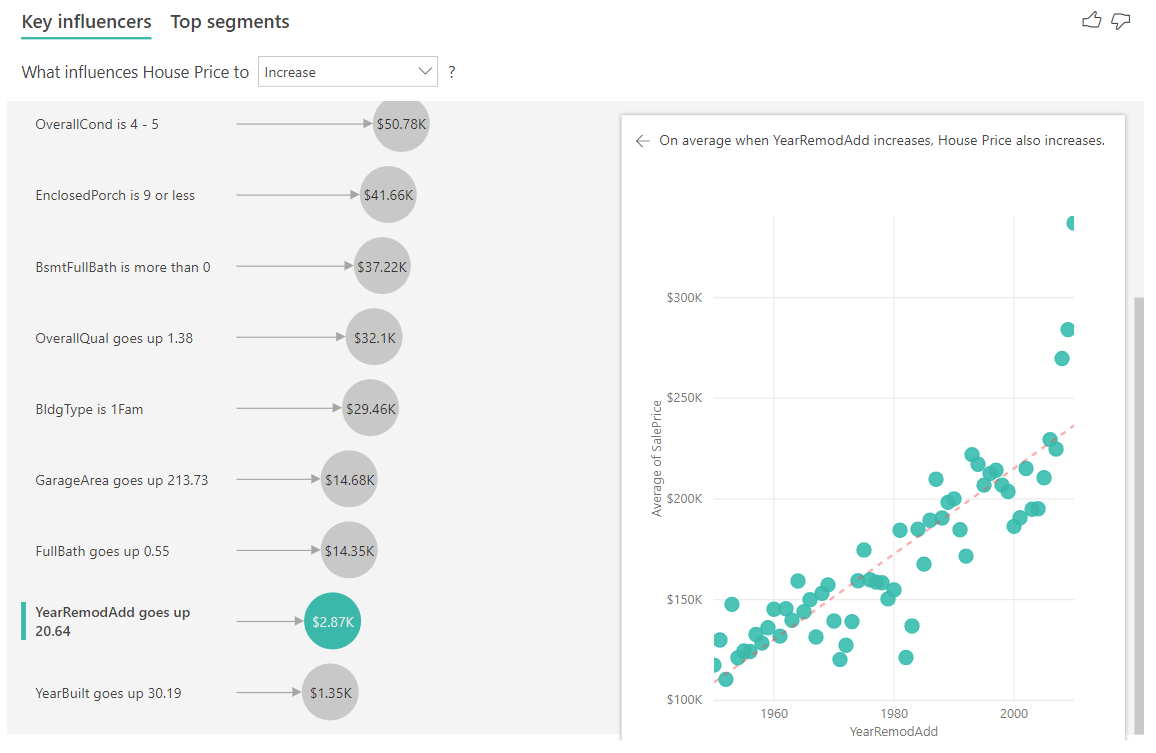
I exemplet nedan tittar vi på vilken inverkan en kontinuerlig faktor (årshuset byggdes om) har på huspriset. Skillnaderna jämfört med hur vi analyserar kontinuerliga påverkare för kategoriska mått är följande:
- Punktdiagrammet i den högra rutan ritar upp det genomsnittliga huspriset för varje distinkt värde på året som har byggts om.
- Värdet i bubblan visar hur mycket det genomsnittliga huspriset ökar (i det här fallet 2,87 000 dollar) när året då huset byggdes om ökar med sin standardavvikelse (i det här fallet 20 år)
Slutligen, när det gäller åtgärder, tittar vi på det genomsnittliga året ett hus byggdes. Analysen är följande:
- Punktdiagrammet i den högra rutan ritar det genomsnittliga huspriset för varje distinkt värde i tabellen
- Värdet i bubblan visar hur mycket det genomsnittliga huspriset ökar (i det här fallet 1,35 000 kr) när det genomsnittliga året ökar med standardavvikelsen (i det här fallet 30 år)
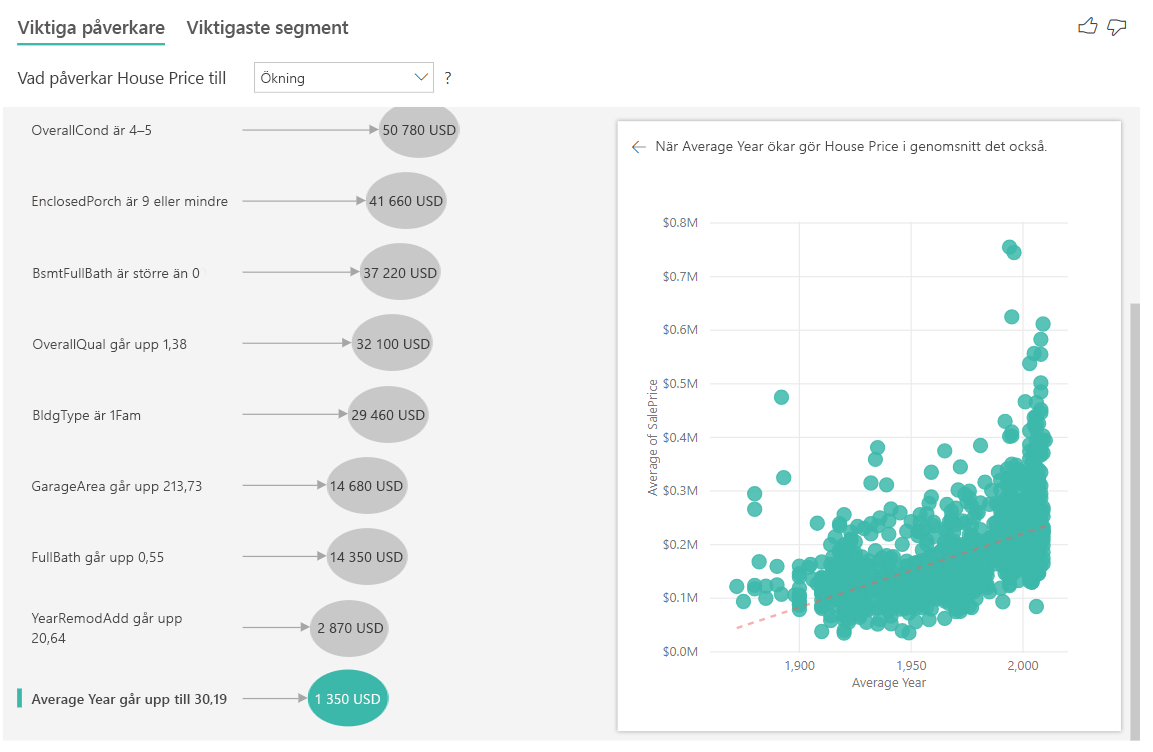
Tolka resultaten: De främsta segmenten
De viktigaste segmenten för numeriska mål visar grupper där huspriserna i genomsnitt är högre än i den totala datamängden. Nedan kan vi till exempel se att Segment 1 består av hus där GarageCars (antalet bilar garaget får plats) är större än 2 och RoofStyle är Hip. Hus med dessa egenskaper har ett genomsnittligt pris på $ 355K jämfört med det totala genomsnittet i data som är $ 180K.
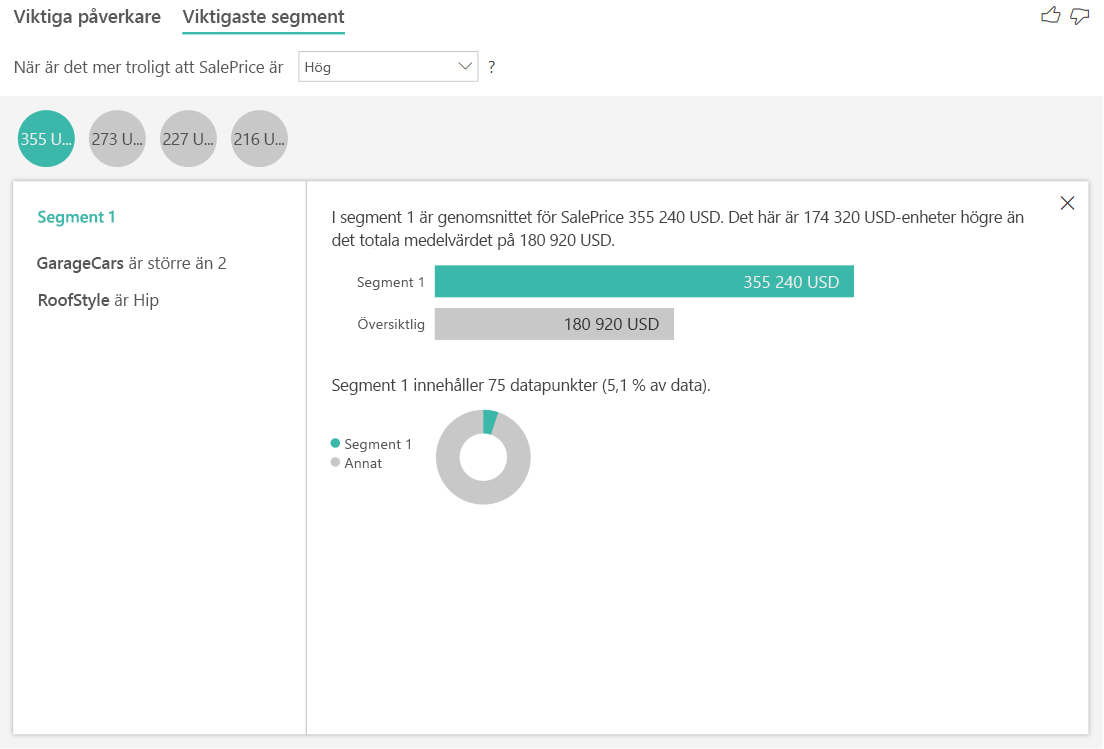
Analysera ett mått som är ett mått eller en sammanfattad kolumn
När det gäller ett mått eller en sammanfattad kolumn är analysen standardvärdet för den kontinuerliga analystyp som beskrivs ovan. Värdet kan inte ändras. Den största skillnaden mellan att analysera en mått-/sammanfattad kolumn och en oavslutad numerisk kolumn är den nivå där analysen körs.
När det gäller oavslutade kolumner körs analysen alltid på tabellnivå. I husprisexemplet ovan analyserade vi måttet Huspris för att se vad som påverkar ett huspris att öka/minska. Analysen körs automatiskt på tabellnivå. Vår tabell har ett unikt ID för varje hus så analysen körs på husnivå.
För mått och sammanfattade kolumner vet vi inte omedelbart vilken nivå de ska analyseras på. Om huspriset sammanfattades som ett genomsnitt skulle vi behöva överväga vilken nivå vi skulle vilja att det här genomsnittliga huspriset beräknades. Är det det genomsnittliga huspriset på grannskapsnivå? Eller kanske en regional nivå?
Mått och sammanfattade kolumner analyseras automatiskt på nivån för de Förklara efter-fält som används. Anta att vi har tre fält i Explain By som vi är intresserade av: Kökskvalitet, Byggnadstyp och Luftkonditionering. Genomsnittligt huspris beräknas för varje unik kombination av dessa tre fält. Det är ofta bra att växla till en tabellvy för att ta en titt på hur data som utvärderas ser ut.
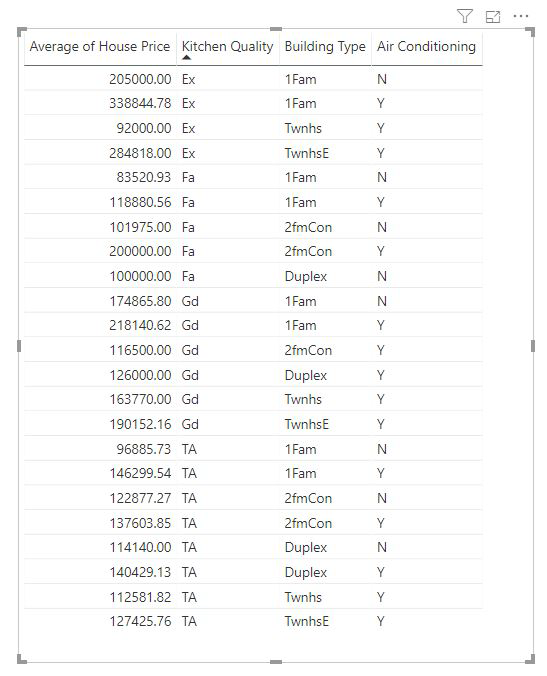
Den här analysen är mycket sammanfattad och därför blir det svårt för regressionsmodellen att hitta eventuella mönster i de data som den kan lära sig av. Vi bör köra analysen på en mer detaljerad nivå för att få bättre resultat. Om vi vill analysera huspriset på husnivå skulle vi uttryckligen behöva lägga till ID-fältet i analysen. Ändå vill vi inte att hus-ID:t ska betraktas som en påverkare. Det är inte bra att lära sig att när hus-ID ökar ökar priset på ett hus. Alternativet Expandera efter fältbrunn är praktiskt här. Du kan använda Expandera efter för att lägga till fält som du vill använda för att ange analysnivån utan att leta efter nya påverkare.
Ta en titt på hur visualiseringen ser ut när vi lägger till ID i Expandera efter. När du har definierat nivån där du vill att måttet ska utvärderas är tolkningen av påverkare exakt densamma som för osummade numeriska kolumner.
Om du vill veta mer om hur du kan analysera mått med visualisering av viktiga påverkare kan du titta på följande video. Information om hur Power BI använder ML.NET i bakgrunden för att resonera över data- och ytinsikter på ett naturligt sätt finns i Power BI identifierar viktiga påverkare med hjälp av ML.NET.
Kommentar
Den här videon kan använda tidigare versioner av Power BI Desktop eller Power BI-tjänst.
Överväganden och felsökning
Vilka är begränsningarna för det visuella objektet?
Det visuella objektet för viktiga påverkare har vissa begränsningar:
- Direct Query stöds inte
- Live Anslut ion till Azure Analysis Services och SQL Server Analysis Services stöds inte
- Publicera på webben stöds inte
- .NET Framework 4.6 eller senare krävs
- SharePoint Online-inbäddning stöds inte
Jag ser ett fel om att inga påverkare eller segment hittades. Varför är det?
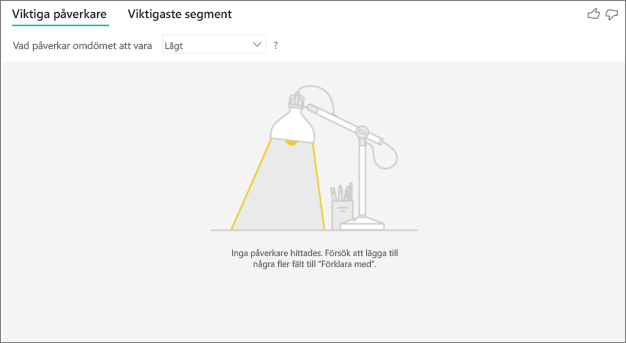
Det här felet uppstår när du inkluderade fält i Förklara med men inga påverkare hittades.
- Du inkluderade måttet som du analyserade i både Analysera och Förklara av. Ta bort den från Förklara med.
- Dina förklarande fält har för många kategorier med få observationer. Den här situationen gör det svårt för visualiseringen att avgöra vilka faktorer som är påverkare. Det är svårt att generalisera baserat på bara några få observationer. Om du analyserar ett numeriskt fält kanske du vill växla från kategorisk analys till kontinuerlig analys i formateringsfönstret under kortet Analys .
- Dina förklarande faktorer har tillräckligt med observationer för att generalisera, men visualiseringen hittade inga meningsfulla korrelationer att rapportera.
Jag ser ett fel om att måttet jag analyserar inte har tillräckligt med data för att köra analysen på. Varför är det?
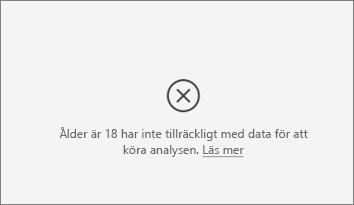
Visualiseringen fungerar genom att titta på mönster i data för en grupp jämfört med andra grupper. Den letar till exempel efter kunder som gav låga omdömen jämfört med kunder som gav höga omdömen. Om data i din modell bara har några få observationer är mönster svåra att hitta. Om visualiseringen inte har tillräckligt med data för att hitta meningsfulla påverkare indikerar det att mer data behövs för att köra analysen.
Vi rekommenderar att du har minst 100 observationer för det valda tillståndet. I det här fallet är tillståndet kunder som omsättning. Du behöver också minst 10 observationer för de tillstånd som du använder för jämförelse. I det här fallet är jämförelsetillståndet kunder som inte tappar.
Om du analyserar ett numeriskt fält kanske du vill växla från kategorisk analys till kontinuerlig analys i formateringsfönstret under kortet Analys .
Jag ser ett felmeddelande om att när "Analysera" inte sammanfattas körs analysen alltid på radnivå i den överordnade tabellen. Det är inte tillåtet att ändra den här nivån via fälten "Expandera efter". Varför är det?
När du analyserar en numerisk eller kategorisk kolumn körs analysen alltid på tabellnivå. Om du till exempel analyserar huspriser och tabellen innehåller en ID-kolumn körs analysen automatiskt på hus-ID-nivå.
När du analyserar ett mått eller en sammanfattad kolumn måste du uttryckligen ange på vilken nivå du vill att analysen ska köras på. Du kan använda Expandera med för att ändra analysnivån för mått och sammanfattade kolumner utan att lägga till nya påverkare. Om huspriset har definierats som ett mått kan du lägga till kolumnen hus-ID i Expandera med för att ändra analysnivån.
Jag ser ett fel om att ett fält i Förklara med inte är unikt relaterat till tabellen som innehåller måttet jag analyserar. Varför är det?
Analysen körs på tabellnivå för det fält som analyseras. Om du till exempel analyserar kundfeedback för din tjänst kan du ha en tabell som anger om en kund gav ett högt omdöme eller ett lågt omdöme. I det här fallet körs din analys på kundtabellnivå.
Om du har en relaterad tabell som definieras på en mer detaljerad nivå än tabellen som innehåller ditt mått visas det här felet. Här är ett exempel:
- Du analyserar vad som driver kunderna att ge låga omdömen om din tjänst.
- Du vill se om den enhet som kunden använder din tjänst på påverkar de recensioner de ger.
- En kund kan använda tjänsten på flera olika sätt.
- I följande exempel använder kund 100000000 både en webbläsare och en surfplatta för att interagera med tjänsten.
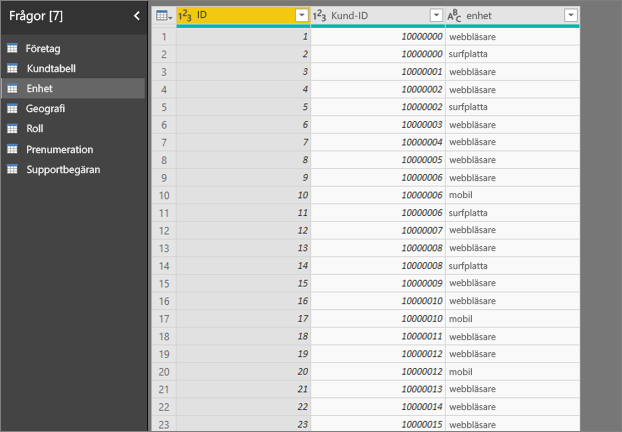
Om du försöker använda enhetskolumnen som en förklarande faktor visas följande fel:

Det här felet visas eftersom enheten inte har definierats på kundnivå. En kund kan använda tjänsten på flera enheter. För att visualiseringen ska kunna hitta mönster måste enheten vara ett attribut för kunden. Det finns flera lösningar som är beroende av din förståelse av verksamheten:
- Du kan ändra sammanfattningen av enheter så att den räknas. Använd till exempel antal om antalet enheter kan påverka den poäng som en kund ger.
- Du kan pivotera enhetskolumnen för att se om användning av tjänsten på en specifik enhet påverkar en kunds omdöme.
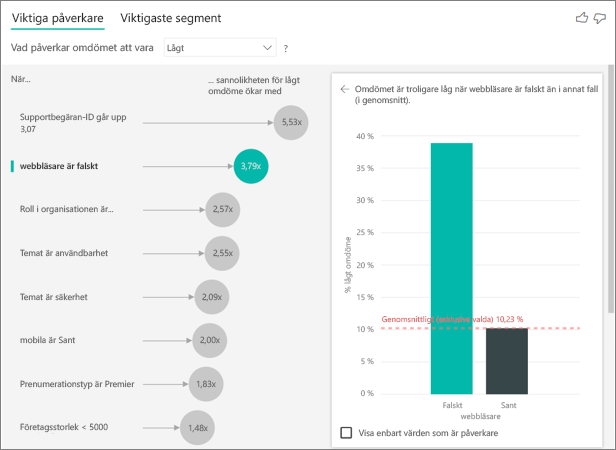
I det här exemplet pivoterades data för att skapa nya kolumner för webbläsare, mobil och surfplatta (se till att du tar bort och återskapar dina relationer i modellvyn när du har pivoterat dina data). Nu kan du använda dessa specifika enheter i Förklara med. Alla enheter visar sig vara påverkare och webbläsaren har störst effekt på kundpoängen.
Mer exakt är kunder som inte använder webbläsaren för att använda tjänsten 3,79 gånger mer benägna att ge en låg poäng än de kunder som gör det. Lägre ned i listan, för mobilt är inversen sann. Kunder som använder mobilappen är mer benägna att ge en låg poäng än de kunder som inte gör det.
Jag ser en varning om att mått inte ingick i min analys. Varför är det?
Analysen körs på tabellnivå för det fält som analyseras. Om du analyserar kundomsättning kan du ha en tabell som anger om en kund har omsnörtat eller inte. I det här fallet körs din analys på kundtabellnivå.
Mått och aggregeringar analyseras som standard på tabellnivå. Om det fanns ett mått för genomsnittliga månatliga utgifter skulle det analyseras på kundtabellnivå.
Om kundtabellen inte har någon unik identifierare kan du inte utvärdera måttet och det ignoreras av analysen. För att undvika den här situationen kontrollerar du att tabellen med måttet har en unik identifierare. I det här fallet är det kundtabellen och den unika identifieraren är kund-ID. Det är också enkelt att lägga till en indexkolumn med hjälp av Power Query.
Jag ser en varning om att måttet jag analyserar har fler än 10 unika värden och att den här mängden kan påverka kvaliteten på min analys. Varför är det?
AI-visualiseringen kan analysera kategoriska fält och numeriska fält. När det gäller kategorifält kan ett exempel vara Omsättning är Ja eller Nej och Kundnöjdhet är Hög, Medel eller Låg. Att öka antalet kategorier som ska analyseras innebär att det finns färre observationer per kategori. Den här situationen gör det svårare för visualiseringen att hitta mönster i data.
När du analyserar numeriska fält kan du välja mellan att behandla numeriska fält som text, i vilket fall du ska köra samma analys som du gör för kategoriska data (kategorisk analys). Om du har många distinkta värden rekommenderar vi att du byter analys till Kontinuerlig analys eftersom det innebär att vi kan härleda mönster från när talen ökar eller minskar i stället för att behandla dem som distinkta värden. Du kan växla från Kategorisk analys till Kontinuerlig analys i formateringsfönstret under kortet Analys.
För att hitta starkare påverkare rekommenderar vi att du grupperar liknande värden i en enda enhet. Om du till exempel har ett mått för pris får du förmodligen bättre resultat genom att gruppera liknande priser i kategorierna Hög, Medel och Låg jämfört med enskilda prispunkter.
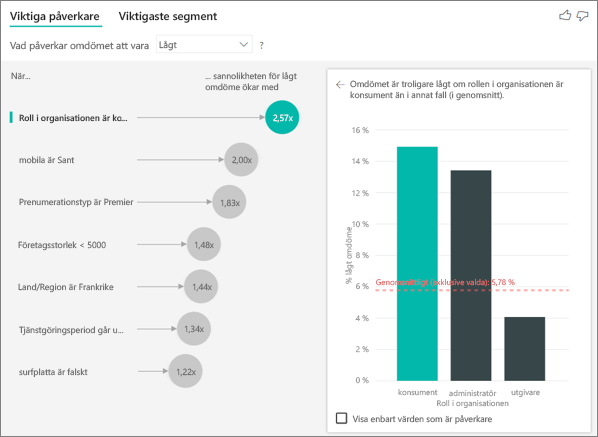
Det finns faktorer i mina data som ser ut att vara viktiga påverkare, men det är de inte. Hur kan det hända?
I följande exempel har kunder som är konsumenter låga omdömen, med 14,93 % av omdömena som är låga. Administratörsrollen har också en hög andel låga omdömen, 13,42 %, men den anses inte vara en påverkare.
Anledningen till den här bestämningen är att visualiseringen även tar hänsyn till antalet datapunkter när den hittar påverkare. I följande exempel finns mer än 29 000 konsumenter och 10 gånger färre administratörer, cirka 2 900. Endast 390 av dem gav ett lågt betyg. Det visuella objektet har inte tillräckligt med data för att avgöra om det hittade ett mönster med administratörsklassificeringar eller om det bara är en chans att hitta.
Vilka är datapunktsgränserna för viktiga påverkare? Vi kör analysen på ett exempel på 10 000 datapunkter. Bubblorna på ena sidan visar alla influencers som hittades. Kolumndiagrammen och punktdiagrammen på andra sidan följer samplingsstrategierna för dessa visuella kärnobjekt.
Hur beräknar du viktiga påverkare för kategorisk analys?
I bakgrunden använder AI-visualiseringen ML.NET för att köra en logistisk regression för att beräkna viktiga påverkare. En logistisk regression är en statistisk modell som jämför olika grupper med varandra.
Om du vill se vad som driver låga omdömen tittar den logistiska regressionen på hur kunder som gav en låg poäng skiljer sig från de kunder som gav en hög poäng. Om du har flera kategorier, till exempel höga, neutrala och låga poäng, tittar du på hur de kunder som gav ett lågt omdöme skiljer sig från de kunder som inte gav ett lågt omdöme. I det här fallet, hur skiljer sig de kunder som gav en låg poäng från de kunder som gav ett högt omdöme eller ett neutralt omdöme?
Den logistiska regressionen söker efter mönster i data och letar efter hur kunder som gav ett lågt omdöme kan skilja sig från de kunder som gav ett högt omdöme. Det kan till exempel bero på att kunder med fler supportärenden ger en högre andel låga omdömen än kunder med få eller inga supportärenden.
Den logistiska regressionen tar också hänsyn till hur många datapunkter som finns. Om kunder som spelar en administratörsroll till exempel ger proportionellt fler negativa poäng, men det bara finns några få administratörer, anses den här faktorn inte vara inflytelserik. Den här bestämningen görs eftersom det inte finns tillräckligt med tillgängliga datapunkter för att härleda ett mönster. Ett statistiskt test, känt som ett Wald-test, används för att avgöra om en faktor anses vara en påverkare. Det visuella objektet använder ett p-värde på 0,05 för att fastställa tröskelvärdet.
Hur beräknar du viktiga påverkare för numerisk analys?
I bakgrunden använder AI-visualiseringen ML.NET för att köra en linjär regression för att beräkna viktiga påverkare. En linjär regression är en statistisk modell som tittar på hur resultatet av fältet du analyserar ändringar baserat på dina förklarande faktorer.
Om vi till exempel analyserar huspriserna tittar en linjär regression på den effekt som ett utmärkt kök kommer att ha på huspriset. Har hus med utmärkta kök i allmänhet lägre eller högre huspriser jämfört med hus utan utmärkta kök?
Den linjära regressionen tar också hänsyn till antalet datapunkter. Till exempel, om hus med tennisbanor har högre priser men vi har få hus med en tennisbana, anses denna faktor inte vara inflytelserik. Den här bestämningen görs eftersom det inte finns tillräckligt med tillgängliga datapunkter för att härleda ett mönster. Ett statistiskt test, känt som ett Wald-test, används för att avgöra om en faktor anses vara en påverkare. Det visuella objektet använder ett p-värde på 0,05 för att fastställa tröskelvärdet.
Hur beräknar du segment?
I bakgrunden använder AI-visualiseringen ML.NET för att köra ett beslutsträd för att hitta intressanta undergrupper. Målet med beslutsträdet är att få en undergrupp med datapunkter som är relativt höga i det mått som du är intresserad av. Det kan vara kunder med låga betyg eller hus med höga priser.
Beslutsträdet tar varje förklarande faktor och försöker resonera vilken faktor som ger den bästa uppdelningen. Om du till exempel filtrerar data så att de endast omfattar stora företagskunder, kommer det att skilja ut kunder som gav ett högt omdöme jämfört med ett lågt omdöme? Eller kanske är det bättre att filtrera data så att de endast omfattar kunder som kommenterat säkerheten?
När beslutsträdet har delats upp tar det undergruppen med data och avgör den näst bästa uppdelningen för dessa data. I det här fallet är undergruppen kunder som kommenterat säkerheten. Efter varje delning överväger beslutsträdet även om det har tillräckligt med datapunkter för att den här gruppen ska vara tillräckligt representativ för att härleda ett mönster från eller om det är en avvikelse i data och inte ett verkligt segment. Ett annat statistiskt test används för att kontrollera den statistiska signifikansen för det delade villkoret med p-värdet 0,05.
När beslutsträdet har körts tar det alla delningar, till exempel säkerhetskommentarer och stora företag, och skapar Power BI-filter. Den här kombinationen av filter paketeras som ett segment i det visuella objektet.
Varför blir vissa faktorer påverkare eller slutar att vara påverkare när jag flyttar fler fält till fältet Förklara efter ?
Visualiseringen utvärderar alla förklarande faktorer tillsammans. En faktor kan vara en influerare av sig själv, men när den beaktas med andra faktorer kanske den inte gör det. Anta att du vill analysera vad som driver ett huspris att vara högt, med sovrum och husstorlek som förklarande faktorer:
- I sig kan fler sovrum vara en drivkraft för att huspriserna ska vara höga.
- Att inkludera husstorlek i analysen innebär att du nu tittar på vad som händer med sovrum medan husstorleken förblir konstant.
- Om husstorleken är fast på 1 500 kvadratmeter är det osannolikt att en kontinuerlig ökning av antalet sovrum dramatiskt kommer att öka huspriset.
- Sovrum kanske inte är lika viktiga för en faktor som det var innan husets storlek övervägdes.
Om du delar rapporten med en Power BI-kollega måste du båda ha enskilda Power BI Pro-licenser eller att rapporten sparas i Premium-kapacitet. Se delningsrapporter.