Övning – Skala arbetsbelastningens prestanda
I den här övningen tar du det problem du stötte på i den första övningen och förbättrar prestandan genom att skala fler processorer för Azure SQL Database. Du använder databasen som du distribuerade i föregående övning.
Du hittar alla skript för den här övningen i mappen 04-Performance\monitor_and_scale på GitHub-lagringsplatsen som du klonade eller zip-filen som du laddade ned.
Skala upp Azure SQL-prestanda
När du skalar om prestanda för ett problem som verkar vara relaterat till CPU-kapaciteten identifierar du först vad du har för alternativ. Sedan skalar du om processorerna via gränssnitten för Azure SQL.
Bestäm hur du ska skala om dina prestanda. Eftersom arbetsbelastningen är CPU-bunden är ett sätt att förbättra prestandan att öka processorkapaciteten eller hastigheten. En SQL Server-användare behöver flytta till en annan dator eller konfigurera om en virtuell dator för att få mer CPU-kapacitet. I vissa fall kanske inte ens en SQL Server-administratör har behörighet att göra dessa skalningsändringar. Processen kan ta tid och du kan till och med behöva migrera databasen.
För Azure kan du använda
ALTER DATABASE, Azure CLI eller Azure-portalen för att öka processorkapaciteten utan databasmigrering från användarens sida.Det finns olika alternativ för att skala ut fler CPU-resurser i Azure-portalen. I databasens översiktsfönster väljer du prisnivån för den aktuella distributionen. Via SKU kan du ändra tjänstnivån och antalet virtuella kärnor.
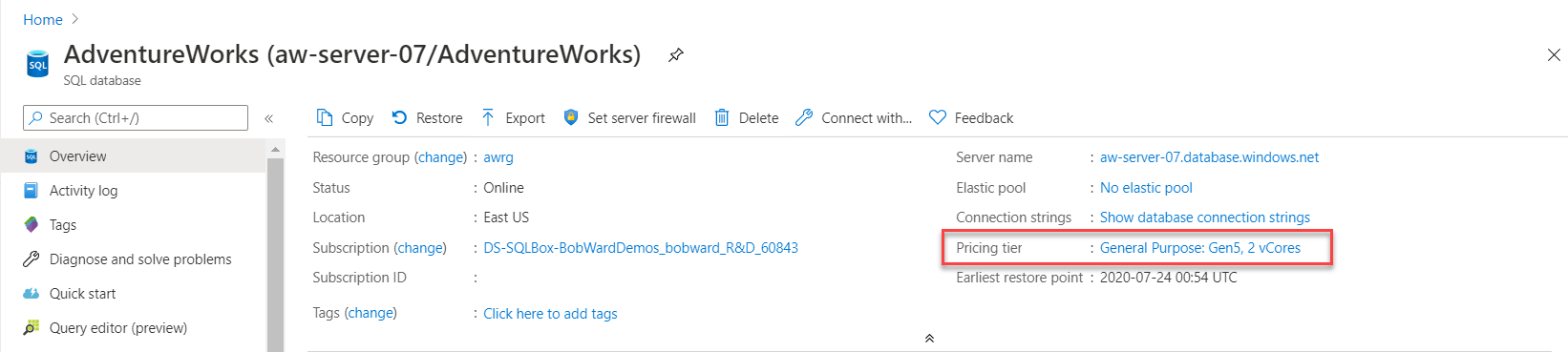
Här kan du se alternativ för att ändra eller skala beräkningsresurser. För Generell användning kan du enkelt skala upp till exempelvis 8 virtuella kärnor.
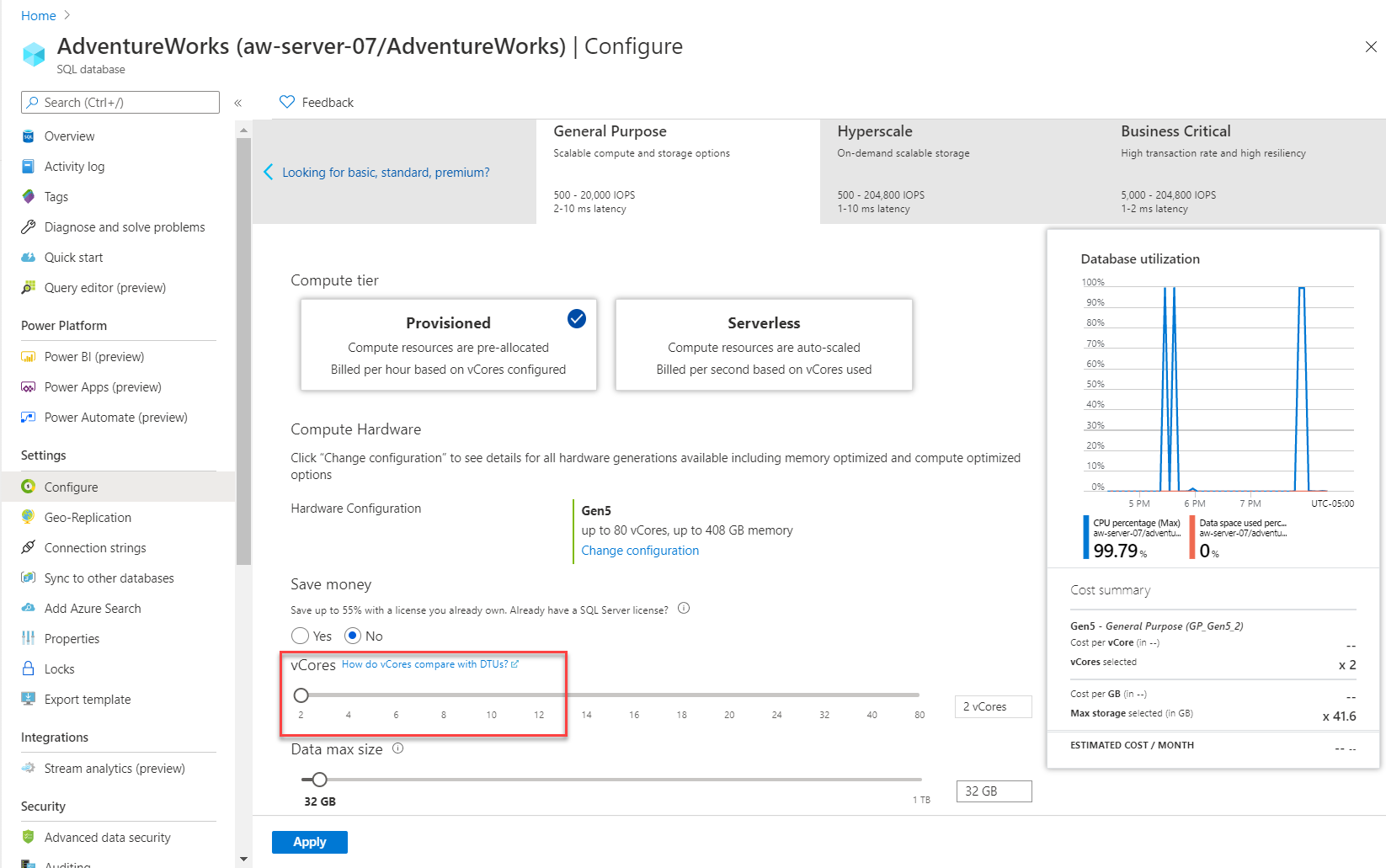
Du kan också använda en annan metod till att skala om arbetsbelastningen.
För att vi ska se riktiga skillnader i rapporter i den här övningen måste du först tömma frågearkivet. I SQL Server Management Studio (SSMS) väljer du databasen AdventureWorks och använder menyn Arkiv>öppen>fil. Öppna skriptet flushhquerystore.sql i SSMS i kontexten för AdventureWorks-databasen . Texten i frågeredigerarens fönster borde se ut så här:
EXEC sp_query_store_flush_db;Välj Kör för att köra den här T-SQL-batchen.
Kommentar
Om du kör föregående fråga rensas minnesintern del av Query Store-data till disk.
Öppna skriptet get_service_objective.sql i SSMS. Texten i frågeredigerarens fönster borde se ut så här:
SELECT database_name,slo_name,cpu_limit,max_db_memory, max_db_max_size_in_mb, primary_max_log_rate,primary_group_max_io, volume_local_iops,volume_pfs_iops FROM sys.dm_user_db_resource_governance; GO SELECT DATABASEPROPERTYEX('AdventureWorks', 'ServiceObjective'); GODet här är en metod för att ta reda på tjänstnivån via T-SQL. Pris- eller tjänstnivån kallas även för ett tjänstmål (service objective). Välj Kör för att köra T-SQL-batcharna.
För den aktuella Azure SQL Database-distributionen borde resultatet se ut som på följande bild:
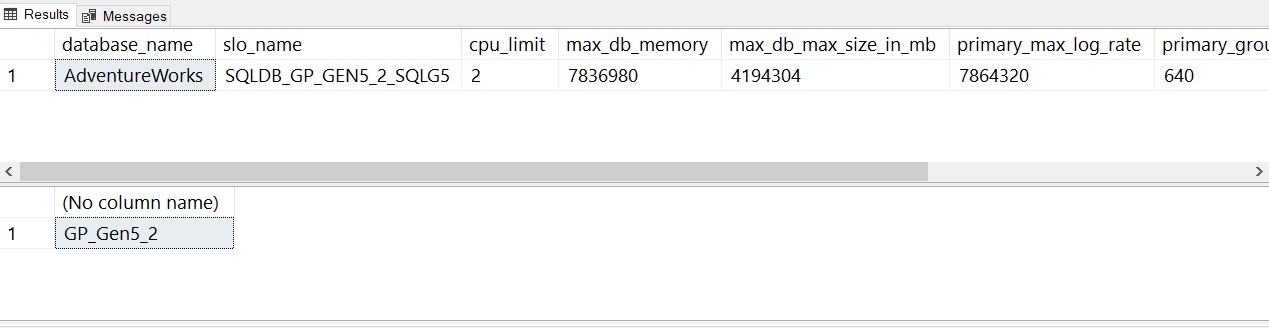
Observera att termen slo_name också används för tjänstmål. slo står för service level objective (servicenivåmål).
De olika
slo_namevärdena är inte dokumenterade, men du kan se från strängvärdet att den här databasen använder en tjänstnivå för generell användning med två virtuella kärnor:Kommentar
SQLDB_OP_...är strängen som används för nivån Affärskritisk.Lägg märke till att du kan klicka på din SQL Server-måldistribution för att få rätt syntaxalternativ när du visar dokumentationen för ALTER DATABASE. Välj SQL Database enkel databas/elastisk pool om du vill se alternativen för Azure SQL Database. För att matcha den beräkningsskala som du hittade i portalen behöver du tjänstmålet
'GP_Gen5_8'.Ändra tjänstmålet för databasen för att skala fler processorer. Öppna skriptet modify_service_objective.sql i SSMS och kör T-SQL-batchen. Texten i frågeredigerarens fönster borde se ut så här:
ALTER DATABASE AdventureWorks MODIFY (SERVICE_OBJECTIVE = 'GP_Gen5_8');Den här instruktionen returneras omedelbart, men omskalningen av beräkningsresurserna sker i bakgrunden. En så här liten skalning bör ta mindre än en minut. Databasen är offline en kort stund för att göra ändringen mer effektiv. Du kan övervaka förloppet för skalningsaktiviteten i Azure-portalen.
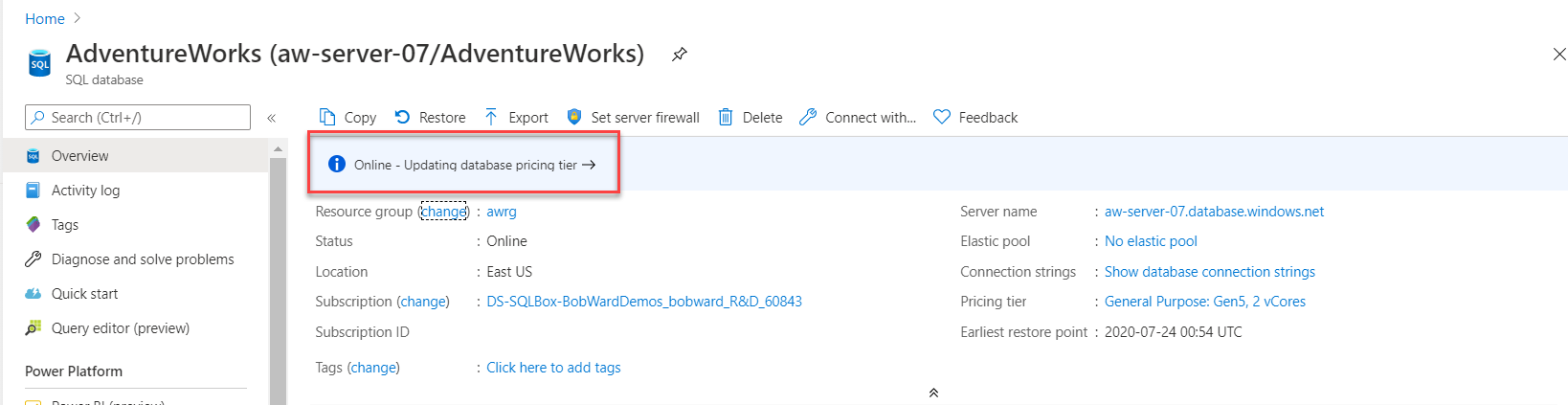
Gå till Object Explorer, under mappen Systemdatabaser, högerklicka på databasen master och välj Ny fråga. Kör den här frågan i SSMS-frågeredigerarens fönster:
SELECT * FROM sys.dm_operation_status;Det här är ett annat sätt att övervaka förloppet för en ändring av tjänstmålet för Azure SQL Database. Den här DMV:n visar historik över databasändringar med ALTER DATABASE avseende tjänstmålet. Den visar även ändringens aktiva förlopp.
Här är ett exempel på utdata från DMV:n i tabellformat när du har kört ovanstående ALTER DATABASE-instruktion:
Artikel Värde session_activity_id 97F9474C-0334-4FC5-BFD5-337CDD1F9A21 resource_type 0 resource_type_desc Databas major_resource_id AdventureWorks minor_resource_id operation ALTER DATABASE tillstånd 1 state_desc IN_PROGRESS percent_complete 0 error_code 0 error_desc error_severity 0 error_state 0 start_time [datum och tid] last_modify_time [datum och tid] När du ändrar tjänstmålet tillåts frågor mot databasen tills den slutliga ändringen har implementerats. Program kan inte ansluta under en kort tidsperiod. För Azure SQL Managed Instance tillåts frågor och anslutningar under nivåändringen medan alla databasåtgärder, som att skapa nya databaser, förhindras. I dessa fall får du följande felmeddelande: "Åtgärden kunde inte slutföras eftersom en ändring på tjänstnivå pågår för den hanterade instansen [server]". Vänta tills åtgärden har slutförts och försök igen.”
När detta är klart använder du föregående frågor som anges från get_service_objective.sql i SSMS för att kontrollera att det nya tjänstmålet eller tjänstnivån på 8 virtuella kärnor har börjat gälla.
Köra arbetsbelastningen efter uppskalning
Nu när databasen har mer processorkapacitet ska vi köra arbetsbelastningen som vi gjorde i föregående övning för att se om prestandan har förbättrats.
Nu när skalningen är slutförd ska vi se efter om arbetsbelastningens varaktighet är kortare och om väntetiderna på CPU-resurser har minskat. Kör arbetsbelastningen igen med hjälp av kommandot sqlworkload.cmd som du körde i föregående övning.
Använd SSMS och kör samma fråga från den första övningen i den här modulen och granska resultatet från skriptet dmdbresourcestats.sql:
SELECT * FROM sys.dm_db_resource_stats;Den genomsnittliga CPU-resursanvändningen bör ha minskat från de nästan 100 procent du såg i den föregående övningen. Visar normalt
sys.dm_db_resource_statsen timmes aktivitet. Om du ändrar storlek på databasen återställssys.dm_db_resource_stats.Använd SSMS och kör samma fråga från den första övningen i den här modulen och granska resultatet från skriptet dmexecrequests.sql.
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Nu ser du att fler frågor har statusen RUNNING. Det innebär att våra arbetare har mer CPU-kapacitet för att köra.
Titta på den nya arbetsbelastningens varaktighet. Arbetsbelastningens varaktighet från ssqlworkload.cmd ska nu vara mycket mindre, cirka 25–30 sekunder.
Studera Query Store-rapporter
Nu ska vi titta på samma Query Store-rapporter som vi gjorde i den föregående övningen.
Använd samma metoder som i den första övningen i den här modulen och titta på rapporten om de mest resurskrävande frågorna från SSMS:
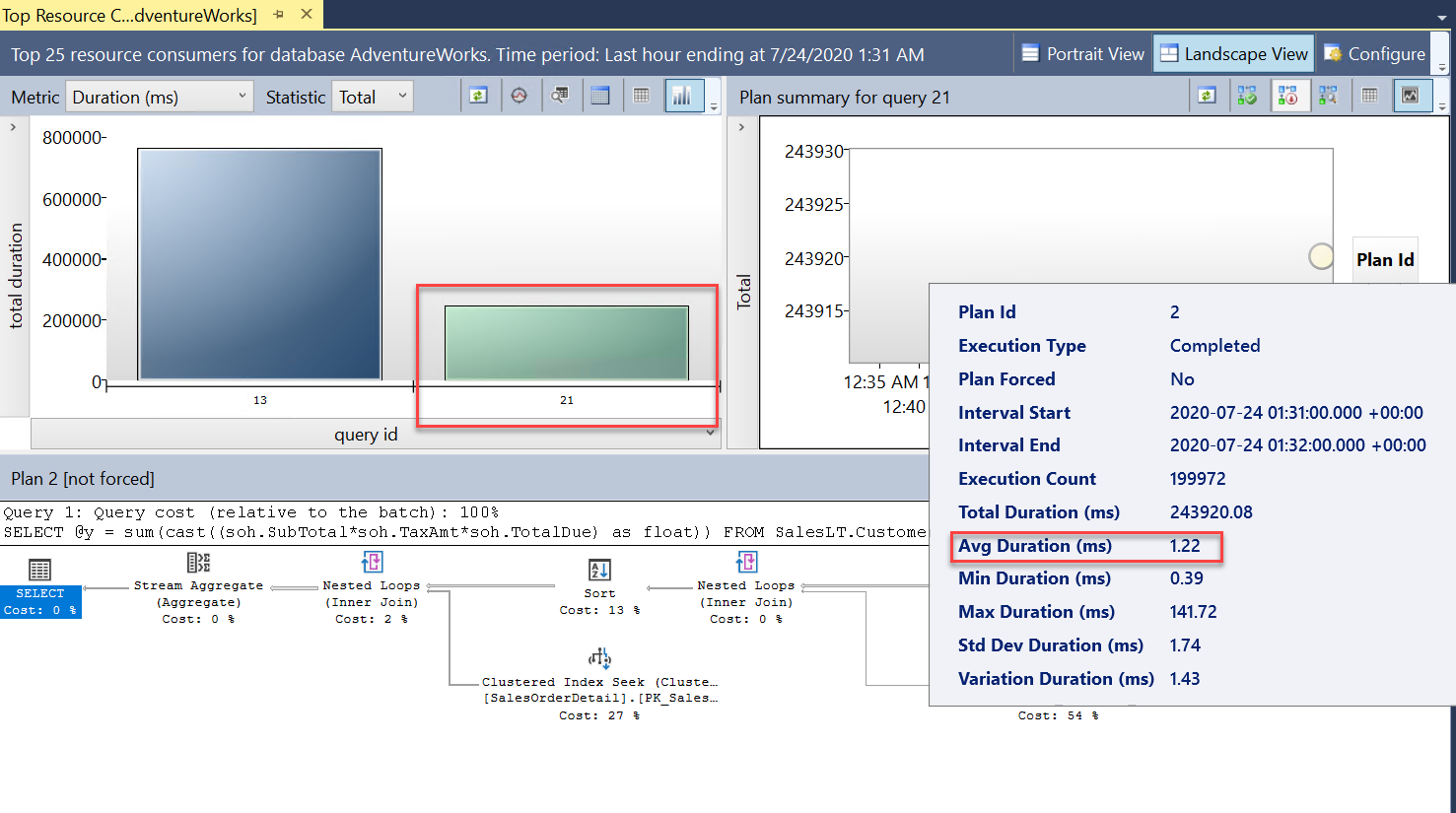
Nu ser du två frågor (
query_id). De är samma fråga men visas med olika värden förquery_idi Query Store eftersom skalningsåtgärden krävde en omstart så att frågan behövde kompileras om. I rapporten kan du se att den totala och genomsnittliga varaktigheten var betydligt mindre.Titta också på rapporten Frågeväntestatistik och välj väntefältet för PROCESSOR. Du ser att den genomsnittliga väntetiden för frågan är kortare och en lägre procentandel av den totala varaktigheten. Det här är ett bra tecken på att processorn inte är en lika stor resursflaskhals som när databasen hade färre virtuella kärnor:
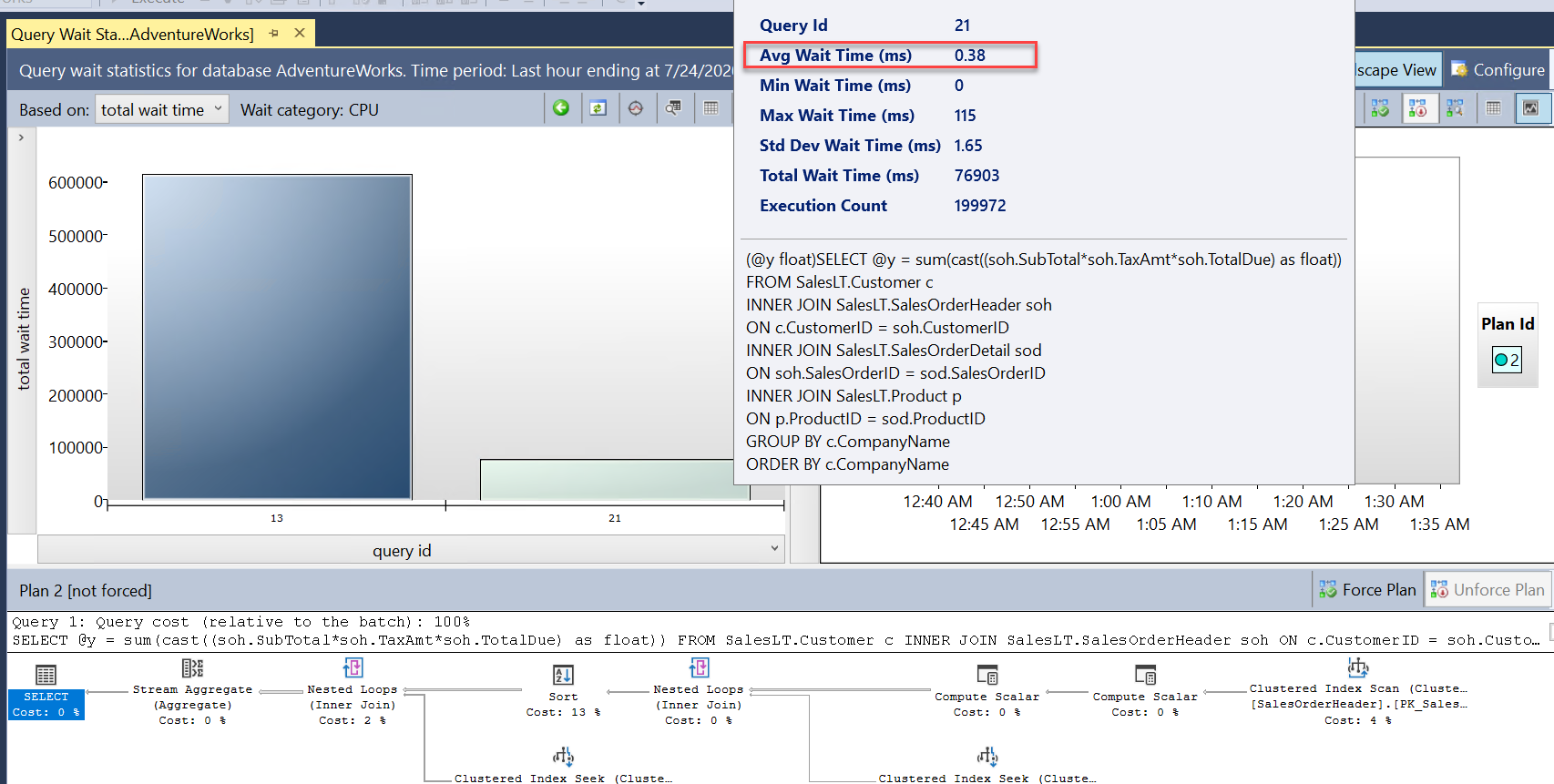
Du kan stänga alla rapporter och fönster i frågeredigeraren. Lämna SSMS anslutet eftersom du behöver det i nästa övning.
Observera ändringar från Azure-mått
Gå till AdventureWorks-databasen i Azure-portalen och titta på fliken Övervakning i fönstret Översikt igen för beräkningsanvändning:
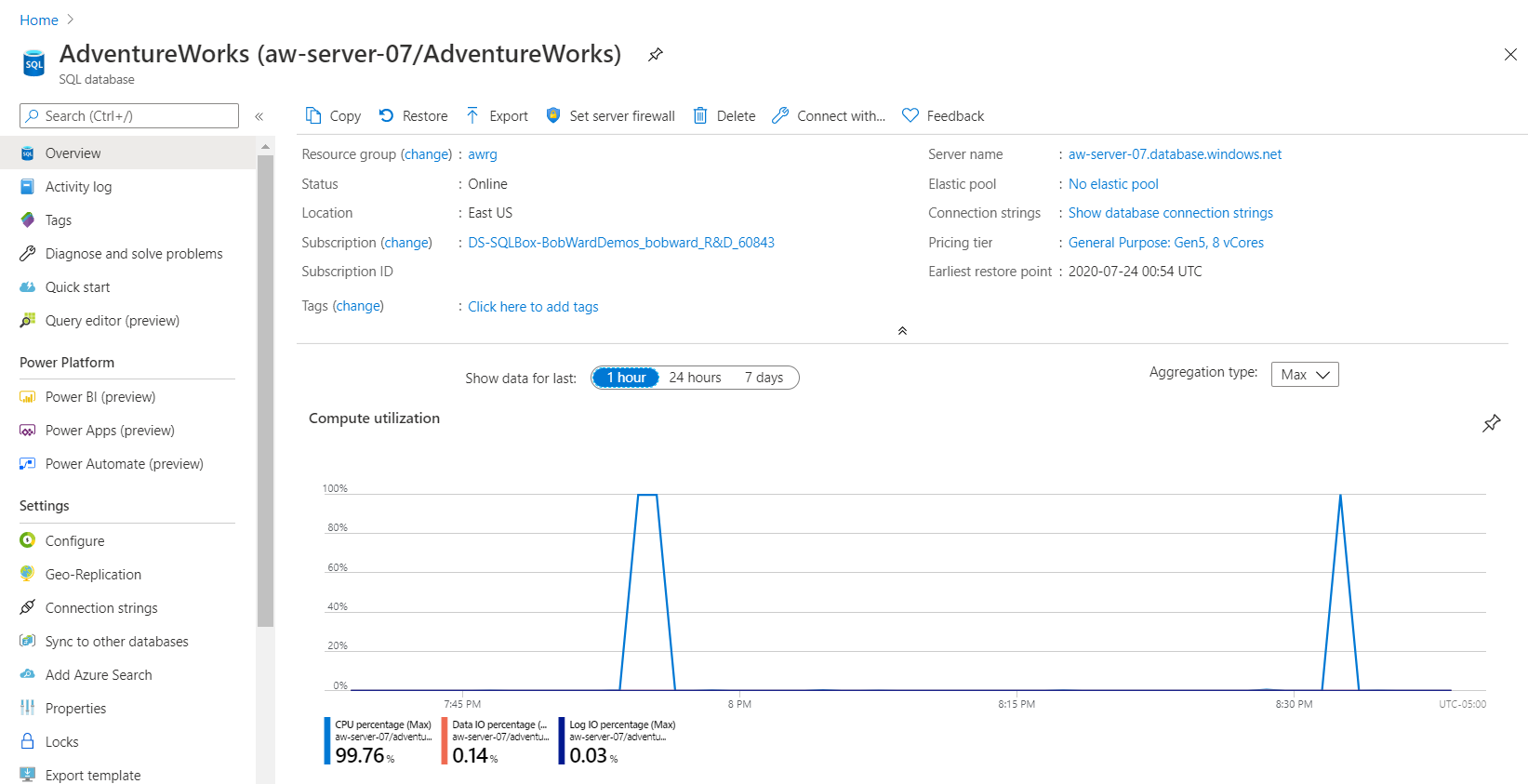
Observera att varaktigheten är kortare vid hög CPU-användning, vilket innebär att det krävs mindre processorresurser för att köra arbetsbelastningen.
Det här diagrammet kan vara lite missvisande. På menyn Övervakning använder du Mått och anger sedan måttet till CPU-gräns. Diagrammet med processorjämförelsen ser ut ungefär så här:
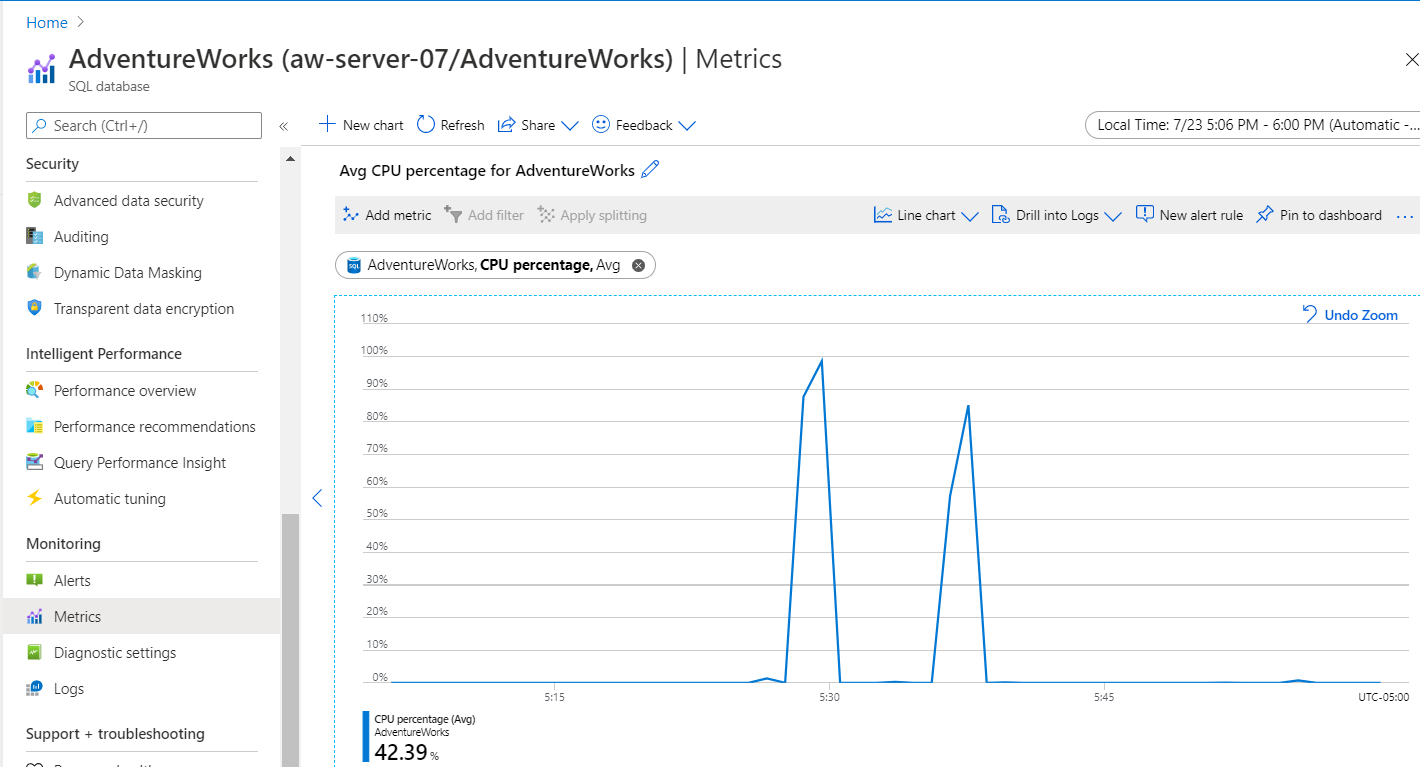
Dricks
Om du fortsätter att öka antalet virtuella kärnor för den här databasen kan du förbättra prestandan upp till ett tröskelvärde där alla frågor har massor av processorresurser. Det betyder inte att du måste matcha antalet virtuella kärnor med antalet samtidiga användare för arbetsbelastningen. Dessutom kan du ändra prisnivån så att den använder serverlös beräkningsnivå i stället för Etablerad. Då används mer automatisk skalning för arbetsbelastningen. Om du till exempel valde ett lägsta värde på 2 virtuella kärnor för den här arbetsbelastningen och det maximala värdet för virtuell kärna på 8, skulle den här arbetsbelastningen omedelbart skalas till 8 virtuella kärnor.
I nästa övning ser du ett prestandaproblem och löser det genom att tillämpa metodtips för programprestanda.