Felsök långsamma förfrågningar i SQL-servern
Ursprunglig produktversion: SQL Server
Ursprungligt KB-nummer: 243589
Introduktion
Den här artikeln beskriver hur du hanterar ett prestandaproblem som kan uppstå för databasprogram när du använder SQL Server: långsamma prestanda för en specifik fråga eller grupp med frågor. Följande metod hjälper dig att begränsa orsaken till problemet med långsamma frågor och leda dig till lösning.
Hitta långsamma frågor
För att fastställa att du har problem med frågeprestanda på din SQL Server-instans börjar du med att undersöka frågor efter deras körningstid (förfluten tid). Kontrollera om tiden överskrider ett tröskelvärde som du har angett (i millisekunder) baserat på en etablerad prestandabaslinje. I en stresstestmiljö kan du till exempel ha fastställt ett tröskelvärde för att din arbetsbelastning inte ska vara längre än 300 ms, och du kan använda det här tröskelvärdet. Sedan kan du identifiera alla frågor som överskrider tröskelvärdet, med fokus på varje enskild fråga och dess förutbestämda varaktighet för prestandabaslinje. Slutligen bryr sig företagsanvändare om den totala varaktigheten för databasfrågor; Därför är huvudfokus på körningens varaktighet. Andra mått som CPU-tid och logiska läsningar samlas in för att begränsa undersökningen.
För närvarande kör du instruktioner genom att kontrollera total_elapsed_time och cpu_time kolumner i sys.dm_exec_requests. Kör följande fråga för att hämta data:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;För tidigare körningar av frågan kontrollerar du last_elapsed_time och last_worker_time kolumner i sys.dm_exec_query_stats. Kör följande fråga för att hämta data:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCKommentar
Om
avg_wait_timevisar ett negativt värde är det en parallell fråga.Om du kan köra frågan på begäran i SQL Server Management Studio (SSMS) eller Azure Data Studio kör du den med SET STATISTICS TIME
ONoch SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFSedan ser du cpu-tid, förfluten tid och logiska läsningar från Meddelanden så här:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Om du kan samla in en frågeplan kontrollerar du data från egenskaperna för körningsplan.
Kör frågan med Inkludera faktisk körningsplan på.
Välj operatorn längst till vänster från Körningsplan.
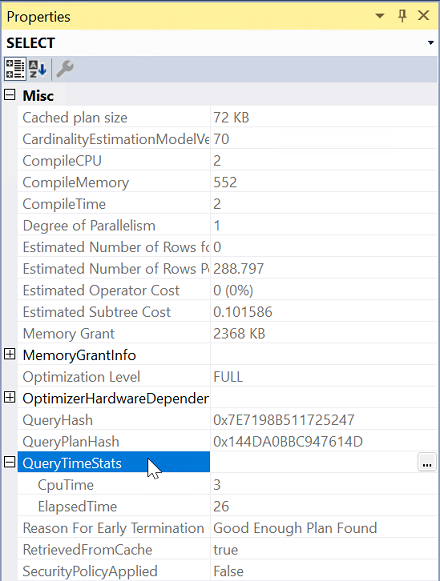
Från Egenskaper expanderar du egenskapen QueryTimeStats .
Kontrollera ElapsedTime och CpuTime.
Körs jämfört med väntar: varför är frågorna långsamma?
Om du hittar frågor som överskrider ditt fördefinierade tröskelvärde kan du undersöka varför de kan vara långsamma. Orsaken till prestandaproblem kan grupperas i två kategorier, som körs eller väntar:
VÄNTAR: Frågor kan vara långsamma eftersom de väntar länge på en flaskhals. Se en detaljerad lista över flaskhalsar i typer av väntetyper.
KÖRS: Frågor kan vara långsamma eftersom de körs (körs) under lång tid. Med andra ord använder dessa frågor aktivt CPU-resurser.
En fråga kan köras vissa perioder och vänta under vissa perioder under frågans livstid (varaktighet). Men ditt fokus är att avgöra vilken som är den dominerande kategorin som bidrar till dess långa tid. Därför är den första uppgiften att fastställa vilken kategori frågorna tillhör. Det är enkelt: om en fråga inte körs väntar den. Helst ägnar en fråga större delen av sin förflutna tid i ett körningstillstånd och mycket lite tid på att vänta på resurser. I bästa fall körs även en fråga inom eller under en fördefinierad baslinje. Jämför den förflutna tiden och CPU-tiden för frågan för att fastställa problemtypen.
Typ 1: CPU-bunden (löpare)
Om cpu-tiden är nära, lika med eller högre än den förflutna tiden, kan du behandla den som en CPU-bunden fråga. Om den förflutna tiden till exempel är 3 000 millisekunder (ms) och CPU-tiden är 2 900 ms innebär det att större delen av den förflutna tiden spenderas på processorn. Sedan kan vi säga att det är en CPU-bunden fråga.
Exempel på frågor som körs (CPU-bundna):
| Förfluten tid (ms) | CPU-tid (ms) | Läsningar (logiska) |
|---|---|---|
| 3200 | 3000 | 300 000 |
| 1080 | 1000 | 20 |
Logiska läsningar – läsning av data-/indexsidor i cacheminnet – är oftast drivrutinerna för CPU-användning i SQL Server. Det kan finnas scenarier där CPU-användning kommer från andra källor: en while-loop (i T-SQL eller annan kod som XProcs- eller SQL CRL-objekt). Det andra exemplet i tabellen illustrerar ett sådant scenario, där majoriteten av processorn inte kommer från läsningar.
Kommentar
Om CPU-tiden är större än varaktigheten anger detta att en parallell fråga körs. flera trådar använder processorn samtidigt. Mer information finns i Parallella frågor – löpare eller servitör.
Typ 2: Väntar på en flaskhals (servitör)
En fråga väntar på en flaskhals om den förflutna tiden är betydligt större än CPU-tiden. Den förflutna tiden inkluderar tiden som kör frågan på CPU -tiden (CPU-tid) och tiden som väntar på att en resurs ska släppas (väntetid). Om den förflutna tiden till exempel är 2 000 ms och cpu-tiden är 300 ms är väntetiden 1700 ms (2 000–300 = 1 700). Mer information finns i Typer av väntetider.
Exempel på väntande frågor:
| Förfluten tid (ms) | CPU-tid (ms) | Läsningar (logiska) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
Parallella frågor – löpare eller servitör
Parallella frågor kan använda mer CPU-tid än den totala varaktigheten. Målet med parallellitet är att tillåta att flera trådar kör delar av en fråga samtidigt. Under en sekund av klocktiden kan en fråga använda åtta sekunders CPU-tid genom att köra åtta parallella trådar. Därför blir det svårt att fastställa en CPU-bunden fråga eller en väntande fråga baserat på den förflutna tids- och CPU-tidsskillnaden. Men som en allmän regel följer du de principer som anges i ovanstående två avsnitt. Sammanfattningen är:
- Om den förflutna tiden är mycket större än CPU-tiden bör du betrakta den som en servitör.
- Om CPU-tiden är mycket större än den förflutna tiden bör du betrakta den som en löpare.
Exempel på parallella frågor:
| Förfluten tid (ms) | CPU-tid (ms) | Läsningar (logiska) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Visuell representation på hög nivå av metoden

Diagnostisera och lösa väntande frågor
Om du har fastställt att dina frågor av intresse är servitörer är nästa steg att fokusera på att lösa flaskhalsproblem. Annars går du till steg 4: Diagnostisera och lösa frågor som körs.
Om du vill optimera en fråga som väntar på flaskhalsar identifierar du hur lång väntetiden är och var flaskhalsen är (väntetypen). När väntetypen har bekräftats kan du minska väntetiden eller eliminera väntetiden helt.
Om du vill beräkna den ungefärliga väntetiden subtraherar du CPU-tiden (arbetstiden) från den förflutna tiden för en fråga. Cpu-tiden är vanligtvis den faktiska körningstiden och den återstående delen av frågans livslängd väntar.
Exempel på hur du beräknar ungefärlig väntetid:
| Förfluten tid (ms) | CPU-tid (ms) | Väntetid (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identifiera flaskhalsen eller vänta
Kör följande fråga för att identifiera historiska frågor som väntar länge (till exempel >20 % av den totala förflutna tiden är väntetiden). Den här frågan använder prestandastatistik för cachelagrade frågeplaner sedan SQL Server startades.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCKör följande fråga för att identifiera att frågor körs med längre väntetider än 500 ms:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Om du kan samla in en frågeplan kontrollerar du WaitStats från körningsplanens egenskaper i SSMS:
- Kör frågan med Inkludera faktisk körningsplan på.
- Högerklicka på operatorn längst till vänster på fliken Körningsplan
- Välj Egenskaper och sedan egenskapen WaitStats .
- Kontrollera WaitTimeMs och WaitType.
Om du är bekant med scenarier med PSSDiag/SQLdiag eller SQL LogScout LightPerf/GeneralPerf kan du använda någon av dem för att samla in prestandastatistik och identifiera väntande frågor på din SQL Server-instans. Du kan importera de insamlade datafilerna och analysera prestandadata med SQL Nexus.
Referenser för att eliminera eller minska väntetider
Orsakerna och lösningarna för varje väntetyp varierar. Det finns ingen allmän metod för att lösa alla väntetyper. Här följer artiklar om hur du felsöker och löser vanliga problem med väntetyp:
- Förstå och lösa blockeringsproblem (LCK_M_*)
- Förstå och lösa blockeringsproblem i Azure SQL Database
- Felsöka långsamma SQL Server-prestanda som orsakas av I/O-problem (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Lös sista sidans inläggskonkurrens för PAGELATCH_EX i SQL-servern
- Minne ger förklaringar och lösningar (RESOURCE_SEMAPHORE)
- Felsöka långsamma frågor som beror på ASYNC_NETWORK_IO väntetyp
- Felsöka hög HADR_SYNC_COMMIT väntetyp med AlwaysOn-tillgänglighetsgrupper
- Så här fungerar det: CMEMTHREAD och felsökning av dem
- Att göra parallellitet väntar åtgärdsbart (CXPACKET och CXCONSUMER)
- THREADPOOL-väntan
Beskrivningar av många väntetyper och vad de anger finns i tabellen i Typer av väntetider.
Diagnostisera och lösa problem med frågor som körs
Om CPU-tiden (arbetartiden) ligger mycket nära den totala varaktigheten som förflutit ägnar frågan större delen av sin livslängd åt att köra. När SQL Server-motorn kör hög CPU-användning kommer vanligtvis den höga CPU-användningen från frågor som driver ett stort antal logiska läsningar (den vanligaste orsaken).
Kör följande instruktion för att identifiera de frågor som ansvarar för hög CPU-aktivitet för närvarande:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Om frågor inte driver processorn just nu kan du köra följande instruktion för att leta efter historiska CPU-bundna frågor:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Vanliga metoder för att lösa problem med CPU-bundna frågor som körs länge
- Granska frågans frågeplan
- Uppdatera statistik
- Identifiera och tillämpa saknade index. Fler steg om hur du identifierar saknade index finns i Justera icke-illustrerade index med indexförslag som saknas
- Designa om eller skriva om frågorna
- Identifiera och lösa parameterkänsliga planer
- Identifiera och lösa problem med SARG-förmåga
- Identifiera och lösa problem med radmål där långvariga kapslade loopar kan orsakas av TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION (FAST N). Mer information finns i Förbättringar av Row Goals Gone Rogue och Showplan – Row Goal EstimateRowsWithoutRowGoal
- Utvärdera och lösa problem med kardinalitetsuppskattning . Mer information finns i Minskad frågeprestanda efter uppgradering från SQL Server 2012 eller tidigare till 2014 eller senare
- Identifiera och lösa kvantiteter som inte verkar vara kompletta. Mer information finns i Felsöka frågor som aldrig verkar sluta i SQL Server
- Identifiera och lösa långsamma frågor som påverkas av timeout för optimeraren
- Identifiera problem med hög CPU-prestanda. Mer information finns i Felsöka problem med hög CPU-användning i SQL Server
- Felsök en fråga som visar betydande prestandaskillnader mellan två servrar
- Öka datorresurserna i systemet (CPU:er)
- Felsöka uppdateringsprestandaproblem med smala och breda planer
Rekommenderade resurser
- Identifieringsbara typer av flaskhalsar för frågeprestanda i SQL Server och Azure SQL Managed Instance
- Verktyg för övervakning och justering av prestanda
- Alternativ för automatisk justering i SQL Server
- Index arkitektur och designriktlinjer
- Felsöka tidsgränsfel för frågor
- Felsök höga CPU-användningsproblem i SQL-servern
- Försämrade frågeprestanda efter uppgradering från SQL Server 2012 eller tidigare till SQL Server 2014 eller senare