Felsöka långsamma SQL Server-prestanda som orsakas av I/O-problem
Gäller för: SQL Server
Den här artikeln innehåller vägledning om vilka I/O-problem som orsakar långsamma SQL Server-prestanda och hur du felsöker problemen.
Definiera långsamma I/O-prestanda
Prestandaövervakningsräknare används för att fastställa långsamma I/O-prestanda. Dessa räknare mäter hur snabbt I/O-undersystemet hanterar varje I/O-begäran i genomsnitt när det gäller klocktid. De specifika prestandaövervakningsräknarna som mäter I/O-svarstid i Windows är Avg Disk sec/ Read, Avg. Disk sec/Writeoch Avg. Disk sec/Transfer (kumulativa för både läsningar och skrivningar).
I SQL Server fungerar det på samma sätt. Vanligtvis tittar du på om SQL Server rapporterar några I/O-flaskhalsar mätt i klocktid (millisekunder). SQL Server gör I/O-begäranden till operativsystemet genom att anropa Win32-funktionerna, till exempel WriteFile(), ReadFile()WriteFileGather(), och ReadFileScatter(). När den publicerar en I/O-begäran, tidsintervallar SQL Server begäran och rapporterar varaktigheten för begäran med hjälp av väntetyper. SQL Server använder väntetyper för att ange I/O-väntetider på olika platser i produkten. I/O-relaterade väntetider är:
- / PAGEIOLATCH_SHPAGEIOLATCH_EX
- WRITELOG
- IO_COMPLETION
- ASYNC_IO_COMPLETION
- BACKUPIO
Om dessa väntetider överskrider 10–15 millisekunder konsekvent anses I/O vara en flaskhals.
Obs!
För att ge kontext och perspektiv har Microsoft CSS i en värld av felsökning av SQL Server observerat fall där en I/O-begäran tog över en sekund och så högt som 15 sekunder per överföring – sådana I/O-system behöver optimering. På motsvarande sätt har Microsoft CSS sett system där dataflödet ligger under en millisekunder/överföring. Med dagens SSD/NVMe-teknik varierar de annonserade dataflödeshastigheterna i tiotals mikrosekunder per överföring. Därför är siffran 10–15 millisekunder/överföring ett mycket ungefärligt tröskelvärde som vi har valt baserat på samlad erfarenhet mellan Windows- och SQL Server-tekniker under årens lopp. När talen överskrider det här ungefärliga tröskelvärdet börjar SQL Server-användare vanligtvis se svarstider i sina arbetsbelastningar och rapportera dem. I slutändan definieras det förväntade dataflödet för ett I/O-undersystem av tillverkaren, modellen, konfigurationen, arbetsbelastningen och potentiellt flera andra faktorer.
Metodik
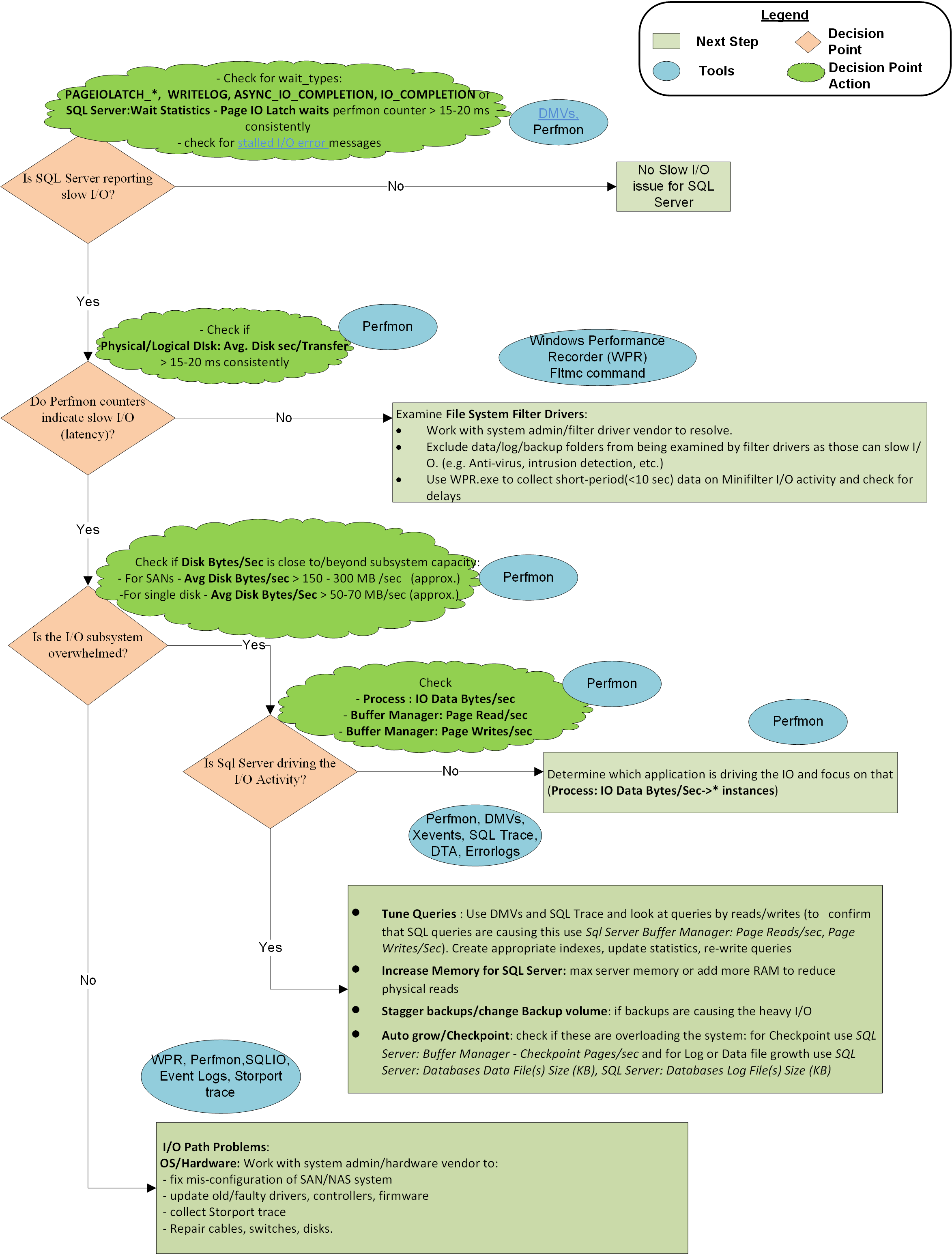
Ett flödesdiagram i slutet av den här artikeln beskriver den metod som Microsoft CSS använder för att hantera långsamma I/O-problem med SQL Server. Det är inte en fullständig eller exklusiv metod men har visat sig vara användbar för att isolera problemet och lösa det.
Du kan välja något av följande två alternativ för att lösa problemet:
Alternativ 1: Utför stegen direkt i en notebook-fil via Azure Data Studio
Obs!
Innan du försöker öppna den här notebook-filen kontrollerar du att Azure Data Studio är installerat på den lokala datorn. Om du vill installera det går du till Lär dig hur du installerar Azure Data Studio.
Alternativ 2: Följ stegen manuellt
Metoden beskrivs i följande steg:
Steg 1: Rapporterar SQL Server långsam I/O?
SQL Server kan rapportera I/O-svarstid på flera sätt:
- I/O-väntetyper
- DMV
sys.dm_io_virtual_file_stats - Fellogg eller programhändelselogg
I/O-väntetyper
Kontrollera om I/O-svarstid rapporteras av SQL Server-väntetyper. Värdena PAGEIOLATCH_*, WRITELOGoch ASYNC_IO_COMPLETION och för flera andra mindre vanliga väntetyper bör vanligtvis ligga under 10–15 millisekunder per I/O-begäran. Om dessa värden är större konsekvent finns det ett I/O-prestandaproblem och kräver ytterligare undersökning. Följande fråga kan hjälpa dig att samla in den här diagnostikinformationen i systemet:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Filstatistik i sys.dm_io_virtual_file_stats
Om du vill visa svarstiden på databasfilnivå som rapporterats i SQL Server kör du följande fråga:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Titta på kolumnerna AvgLatency och LatencyAssessment för att förstå svarstidsinformationen.
Fel 833 rapporterades i felloggen eller programhändelseloggen
I vissa fall kan du observera fel 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) i felloggen. Du kan kontrollera SQL Server-felloggarna i systemet genom att köra följande PowerShell-kommando:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Mer information om det här felet finns i avsnittet MSSQLSERVER_833 .
Steg 2: Anger Perfmon-räknare I/O-svarstid?
Om SQL Server rapporterar I/O-svarstid kan du läsa OS-räknare. Du kan avgöra om det finns ett I/O-problem genom att undersöka svarstidsräknaren Avg Disk Sec/Transfer. Följande kodfragment anger ett sätt att samla in den här informationen via PowerShell. Den samlar in räknare på alla diskvolymer: "_total". Ändra till en specifik enhetsvolym (till exempel "D:"). Kör följande fråga i SQL Server för att ta reda på vilka volymer som är värdar för dina databasfiler:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Samla in Avg Disk Sec/Transfer mått på valfri volym:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Om värdena för den här räknaren konsekvent överstiger 10–15 millisekunder måste du titta närmare på problemet. Tillfälliga toppar räknas inte i de flesta fall, men se till att dubbelkolla varaktigheten för en topp. Om toppen varade i en minut eller mer är det mer en platå än en topp.
Om prestandaövervakarens räknare inte rapporterar svarstid, men SQL Server gör det, är problemet mellan SQL Server och Partitionshanteraren, d.v.s. filterdrivrutiner. Partitionshanteraren är ett I/O-lager där operativsystemet samlar in Perfmon-räknare . Åtgärda svarstiden genom att säkerställa rätt undantag för filterdrivrutiner och lösa problem med filterdrivrutiner. Filterdrivrutiner används av program som antivirusprogram, säkerhetskopieringslösningar, kryptering, komprimering och så vidare. Du kan använda det här kommandot för att lista filterdrivrutiner på systemen och de volymer som de ansluter till. Sedan kan du leta upp drivrutinsnamnen och programvaruleverantörerna i artikeln Allokerade filterhöjder .
fltmc instances
Mer information finns i Så här väljer du antivirusprogram som ska köras på datorer som kör SQL Server.
Undvik att använda EFS (Encrypting File System) och komprimering av filsystem eftersom de gör att asynkron I/O blir synkron och därför långsammare. Mer information finns i artikeln Asynkront disk-I/O visas som synkron i Windows .
Steg 3: Överbelastas I/O-undersystemet bortom kapaciteten?
Om SQL Server och operativsystemet anger att I/O-undersystemet är långsamt kontrollerar du om orsaken är att systemet överbelastas bortom kapaciteten. Du kan kontrollera kapaciteten genom att titta på I/O-räknare Disk Bytes/Sec, Disk Read Bytes/Seceller Disk Write Bytes/Sec. Kontrollera med systemadministratören eller maskinvaruleverantören om de förväntade dataflödesspecifikationerna för ditt SAN (eller andra I/O-undersystem). Du kan till exempel push-överföra högst 200 MB/s I/O via ett 2 GB/sek HBA-kort eller en dedikerad port på 2 GB/sek på en SAN-växel. Den förväntade dataflödeskapaciteten som definieras av en maskinvarutillverkare definierar hur du går vidare härifrån.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Steg 4: Driver SQL Server den tunga I/O-aktiviteten?
Om I/O-undersystemet överbelastas utöver kapaciteten kan du ta reda på om SQL Server är den skyldige genom att titta på Buffer Manager: Page Reads/Sec (den vanligaste syndaren) och Page Writes/Sec (mycket mindre vanligt) för den specifika instansen. Om SQL Server är den huvudsakliga I/O-drivrutinen och I/O-volymen är utöver vad systemet kan hantera, kan du arbeta med programutvecklingsteamen eller programleverantören för att:
- Finjustera frågor, till exempel bättre index, uppdatera statistik, skriva om frågor och göra om databasen.
- Öka maximalt serverminne eller lägg till mer RAM-minne i systemet. Mer RAM cachelagra fler data- eller indexsidor utan att ofta läsa från disken, vilket minskar I/O-aktiviteten. Ökat minne kan också minska
Lazy Writes/sec, som drivs av lazy writer-tömningar när det ofta finns ett behov av att lagra fler databassidor i det begränsade tillgängliga minnet. - Om du upptäcker att sidskrivningar är källan till tung I/O-aktivitet undersöker
Buffer Manager: Checkpoint pages/secdu om det beror på massiva sidspolningar som krävs för att uppfylla konfigurationskraven för återställningsintervall. Du kan antingen använda indirekta kontrollpunkter för att jämna ut I/O över tid eller öka maskinvaru-I/O-dataflödet.
Orsaker
I allmänhet är följande problem de övergripande orsakerna till varför SQL Server-frågor lider av I/O-svarstid:
Maskinvaruproblem:
En SAN-felkonfiguration (växel, kablar, HBA, lagring)
Överskred I/O-kapaciteten (obalanserad i hela SAN-nätverket, inte bara serverdelslagring)
Problem med drivrutiner eller inbyggd programvara
Maskinvaruleverantörer och/eller systemadministratörer måste vara engagerade i det här skedet.
Frågeproblem: SQL Server mättar diskvolymer med I/O-begäranden och push-överför I/O-undersystemet bortom kapaciteten, vilket gör att I/O-överföringshastigheten blir hög. I det här fallet är lösningen att hitta de frågor som orsakar ett stort antal logiska läsningar (eller skrivningar) och finjustera dessa frågor för att minimera disk-I/O-användning av lämpliga index är det första steget för att göra det. Håll också statistiken uppdaterad eftersom de ger frågeoptimeraren tillräcklig information för att välja den bästa planen. Felaktig databasdesign och frågedesign kan också leda till en ökning av I/O-problem. Därför kan omdesign av frågor och ibland tabeller hjälpa till med förbättrad I/O.
Filterdrivrutiner: SQL Server I/O-svaret kan påverkas allvarligt om filterdrivrutiner för filsystem bearbetar tung I/O-trafik. Lämpliga filundantag från antivirusgenomsökning och korrekt filterdrivrutinsdesign från programvaruleverantörer rekommenderas för att förhindra påverkan på I/O-prestanda.
Andra program: Ett annat program på samma dator med SQL Server kan mätta I/O-sökvägen med stora läs- eller skrivbegäranden. Den här situationen kan push-överföra I/O-undersystemet bortom kapacitetsbegränsningar och orsaka I/O-långsamhet för SQL Server. Identifiera programmet och justera det eller flytta det någon annanstans för att eliminera dess inverkan på I/O-stacken.
Grafisk representation av metoden
Information om I/O-relaterade väntetyper
Följande är beskrivningar av vanliga väntetyper som observeras i SQL Server när disk-I/O-problem rapporteras.
PAGEIOLATCH_EX
Inträffar när en aktivitet väntar på en spärr för en data- eller indexsida (buffert) i en I/O-begäran. Spärrbegäran är i exklusivt läge. Ett exklusivt läge används när bufferten skrivs till disk. Långa väntetider kan tyda på problem med diskundersystemet.
PAGEIOLATCH_SH
Inträffar när en aktivitet väntar på en spärr för en data- eller indexsida (buffert) i en I/O-begäran. Spärrbegäran är i delat läge. Läget Delat används när bufferten läse från disken. Långa väntetider kan tyda på problem med diskundersystemet.
PAGEIOLATCH_UP
Inträffar när en uppgift väntar på en spärr för en buffert i en I/O-begäran. Spärrbegäran är i uppdateringsläge. Långa väntetider kan tyda på problem med diskundersystemet.
WRITELOG
Inträffar när en aktivitet väntar på att en transaktionslogg ska tömmas. En tömning sker när Log Manager skriver sitt tillfälliga innehåll till disken. Vanliga åtgärder som orsakar loggspolningar är transaktionsincheckningar och kontrollpunkter.
Vanliga orsaker till långa väntetider WRITELOG är:
Svarstid för transaktionsloggdisk: Det här är den vanligaste orsaken till
WRITELOGväntetider. I allmänhet rekommenderar vi att du behåller data och loggfiler på separata volymer. Transaktionsloggskrivningar är sekventiella skrivningar medan läsning eller skrivning av data från en datafil är slumpmässig. Att blanda data och loggfiler på en enhetsvolym (särskilt konventionella snurrande diskenheter) orsakar överdriven rörelse av diskhuvud.För många VVLF:er: För många virtuella loggfiler kan orsaka
WRITELOGväntetider. För många VVLF:er kan orsaka andra typer av problem, till exempel lång återställning.För många små transaktioner: Även om stora transaktioner kan leda till blockering kan för många små transaktioner leda till en annan uppsättning problem. Om du inte uttryckligen påbörjar en transaktion resulterar alla infognings-, borttagnings- eller uppdateringstransaktioner i en transaktion (vi anropar den här automatiska transaktionen). Om du gör 1 000 infogningar i en loop genereras 1 000 transaktioner. Varje transaktion i det här exemplet måste checkas in, vilket resulterar i en tömning av transaktionslogg och 1 000 transaktionsspolningar. Gruppera om möjligt enskilda uppdateringar, ta bort eller infoga i en större transaktion för att minska transaktionsloggens tömningar och öka prestandan. Den här åtgärden kan leda till färre
WRITELOGväntetider.Schemaläggningsproblem gör att Log Writer-trådar inte schemaläggs tillräckligt snabbt: Före SQL Server 2016 utförde en enda Loggskrivare-tråd alla loggskrivningar. Om det hade uppstått problem med trådschemaläggning (till exempel hög CPU-användning) kan både Loggskrivare-tråden och loggspolning fördröjas. I SQL Server 2016 lades upp till fyra loggskrivartrådar till för att öka loggskrivningens dataflöde. Se SQL 2016 – det går bara snabbare: flera loggskrivare. I SQL Server 2019 har upp till åtta Log Writer-trådar lagts till, vilket förbättrar dataflödet ännu mer. I SQL Server 2019 kan varje vanlig arbetstråd också göra loggskrivningar direkt i stället för att publicera till loggskrivarens tråd. Med dessa förbättringar
WRITELOGskulle väntetider sällan utlösas av schemaläggningsproblem.
ASYNC_IO_COMPLETION
Inträffar när några av följande I/O-aktiviteter inträffar:
- Massinfogningsprovidern ("Infoga massinfogning") använder den här väntetypen när du utför I/O.
- Läser Ångra-filen i LogShipping och dirigerar Async I/O för loggöverföring.
- Läsa faktiska data från datafilerna under en datasäkerhetskopia.
IO_COMPLETION
Inträffar i väntan på att I/O-åtgärder ska slutföras. Den här väntetypen omfattar vanligtvis I/Os som inte är relaterade till datasidor (buffertar). Exempel inkluderar:
- Läsning och skrivning av sort/hash-resultat från/till disk under spill (kontrollera prestanda för tempdb-lagring ).
- Läsa och skriva ivriga spolar till disk (kontrollera tempdb-lagring ).
- Läsa loggblock från transaktionsloggen (under alla åtgärder som gör att loggen läse från disken , till exempel återställning).
- Läser en sida från disken när databasen inte har konfigurerats ännu.
- Kopiera sidor till en databasögonblicksbild (Kopiera vid skrivning).
- Stänger databasfil och filavkomprimering.
BACKUPIO
Inträffar när en säkerhetskopieringsaktivitet väntar på data eller väntar på att en buffert ska lagra data. Den här typen är inte typisk, förutom när en uppgift väntar på en bandmontering.