จัดการไลบรารี Apache Spark ใน Microsoft Fabric
ไลบรารีคือคอลเลกชันของโค้ดที่เขียนไว้ล่วงหน้าซึ่งนักพัฒนาสามารถนําเข้าเพื่อให้มีฟังก์ชันการทํางาน ด้วยการใช้ไลบรารี คุณสามารถประหยัดเวลาและไม่ต้องเขียนโค้ดตั้งแต่เริ่มต้นเพื่อทํางานทั่วไปได้ ให้นําเข้าไลบรารีและใช้ฟังก์ชันและคลาสเพื่อให้ได้ฟังก์ชันการทํางานที่ต้องการแทน Microsoft Fabric มีกลไกหลายแบบเพื่อช่วยให้คุณจัดการและใช้ไลบรารีได้
- ไลบรารีในตัว: รันไทม์ Fabric Spark แต่ละรายการมีชุดไลบรารีที่ติดตั้งไว้ล่วงหน้าที่ได้รับความนิยมมากมาย คุณสามารถค้นหารายการไลบรารีที่มีอยู่ภายในเต็มรูปแบบได้ใน Fabric Spark Runtime
- ไลบรารีสาธารณะ: ไลบรารีสาธารณะมีต้นทางจากที่เก็บ เช่น PyPI และ Conda ซึ่งได้รับการรองรับในปัจจุบัน
- ไลบรารีแบบกําหนดเอง: ไลบรารีแบบกําหนดเองอ้างอิงถึงโค้ดที่คุณหรือองค์กรของคุณสร้างขึ้น ผ้ารองรับในรูปแบบ .whl, .jar และ .tar.gz Fabric รองรับ .tar.gz เฉพาะภาษา R เท่านั้น สําหรับไลบรารีแบบกําหนดเองของ Python ให้ใช้รูปแบบ .whl
สรุปแนวทางปฏิบัติที่ดีที่สุดสําหรับการจัดการไลบรารี
สถานการณ์สมมติต่อไปนี้อธิบายแนวทางปฏิบัติที่ดีที่สุดเมื่อใช้ไลบรารีใน Microsoft Fabric
สถานการณ์ที่ 1: ผู้ดูแลระบบตั้งค่าไลบรารีเริ่มต้นสําหรับพื้นที่ทํางาน
หากต้องการตั้งค่าไลบรารีเริ่มต้น คุณจะต้องเป็นผู้ดูแลระบบของพื้นที่ทํางาน ในฐานะผู้ดูแลระบบ คุณสามารถทํางานเหล่านี้ได้:
- สร้างสภาพแวดล้อมใหม่
- ติดตั้งไลบรารีที่จําเป็นในสภาพแวดล้อม
- แนบสภาพแวดล้อมนี้เป็นสภาพแวดล้อมเริ่มต้นของพื้นที่ทํางาน
เมื่อสมุดบันทึกและข้อกําหนดงาน Spark ของคุณแนบมากับ การตั้งค่าพื้นที่ทํางาน จะมีการเริ่มเซสชันที่มีไลบรารีที่ติดตั้งอยู่ในสภาพแวดล้อมเริ่มต้นของพื้นที่ทํางาน
สถานการณ์ที่ 2: ยืนยันข้อมูลจําเพาะของไลบรารีสําหรับหนึ่งหรือหลายรายการโค้ด
ถ้าคุณมีไลบรารีทั่วไปสําหรับรายการโค้ดที่แตกต่างกันและไม่จําเป็นต้องอัปเดตบ่อย ให้ ติดตั้งไลบรารีในสภาพแวดล้อม และ แนบไว้กับรายการ โค้ดเป็นตัวเลือกที่ดี
ซึ่งจะใช้เวลาสักครู่เพื่อทําให้ไลบรารีในสภาพแวดล้อมมีผลบังคับใช้เมื่อเผยแพร่ โดยปกติแล้วจะใช้เวลา 5-15 นาที ขึ้นอยู่กับความซับซ้อนของไลบรารี ในระหว่างกระบวนการนี้ ระบบจะช่วยในการแก้ไขข้อขัดแย้งที่อาจเกิดขึ้นและดาวน์โหลดการขึ้นต่อกันที่จําเป็น
ประโยชน์ประการหนึ่งของวิธีการนี้คือ ไลบรารีที่ติดตั้งเรียบร้อยแล้วจะรับประกันว่าจะพร้อมใช้งานเมื่อเซสชัน Spark เริ่มต้นด้วยสภาพแวดล้อมที่แนบมา ซึ่งช่วยประหยัดความพยายามในการบํารุงรักษาไลบรารีทั่วไปสําหรับโครงการของคุณ
ขอแนะนําสําหรับสถานการณ์ไปป์ไลน์ที่มีความเสถียร
สถานการณ์ที่ 3: การติดตั้งแบบอินไลน์ในการเรียกใช้แบบโต้ตอบ
ถ้าคุณกําลังใช้สมุดบันทึกเพื่อเขียนโค้ดแบบโต้ตอบ การใช้ การติดตั้ง แบบอินไลน์เพื่อเพิ่มไลบรารี PyPI/conda ใหม่เพิ่มเติม หรือตรวจสอบความถูกต้องของไลบรารีแบบกําหนดเองของคุณสําหรับการใช้งานครั้งเดียวเป็นแนวทางปฏิบัติที่ดีที่สุด คําสั่งแบบอินไลน์ใน Fabric ช่วยให้คุณสามารถมีไลบรารีที่มีผลบังคับใช้ในเซสชัน Spark ของสมุดบันทึกปัจจุบัน ซึ่งช่วยให้ติดตั้งได้อย่างรวดเร็ว แต่ไลบรารีที่ติดตั้งไว้ไม่คงอยู่ในเซสชันที่แตกต่างกัน
เนื่องจาก %pip install การสร้างทรีการขึ้นต่อกันที่แตกต่างกันเป็นครั้งคราว ซึ่งอาจนําไปสู่ความขัดแย้งของไลบรารี คําสั่งแบบอินไลน์จะถูกปิดใช้งานตามค่าเริ่มต้นในการเรียกใช้ไปป์ไลน์และไม่ควรใช้ในไปป์ไลน์ของคุณ
ข้อมูลสรุปของชนิดไลบรารีที่สนับสนุน
| ชนิดไลบรารี | การจัดการไลบรารีสภาพแวดล้อม | การติดตั้งแบบอินไลน์ |
|---|---|---|
| Python Public (PyPI & Conda) | รองรับ | รองรับ |
| Python Custom (.whl) | รองรับ | รองรับ |
| R Public (CRAN) | ไม่รองรับ | รองรับ |
| R แบบกําหนดเอง (.tar.gz) | ได้รับการสนับสนุนเป็นไลบรารีแบบกําหนดเอง | รองรับ |
| เหยือก | ได้รับการสนับสนุนเป็นไลบรารีแบบกําหนดเอง | รองรับ |
การติดตั้งแบบอินไลน์
คําสั่งแบบอินไลน์สนับสนุนการจัดการไลบรารีในแต่ละเซสชันสมุดบันทึก
การติดตั้ง Python แบบอินไลน์
ระบบรีสตาร์ทตัวแปล Python เพื่อใช้การเปลี่ยนแปลงไลบรารี ตัวแปรใด ๆ ที่กําหนดไว้ก่อนที่คุณเรียกใช้เซลล์คําสั่งจะสูญหาย เราขอแนะนําให้คุณใส่คําสั่งทั้งหมดสําหรับการเพิ่ม การลบ หรือการอัปเดตแพคเกจ Python ที่จุดเริ่มต้นของสมุดบันทึกของคุณ
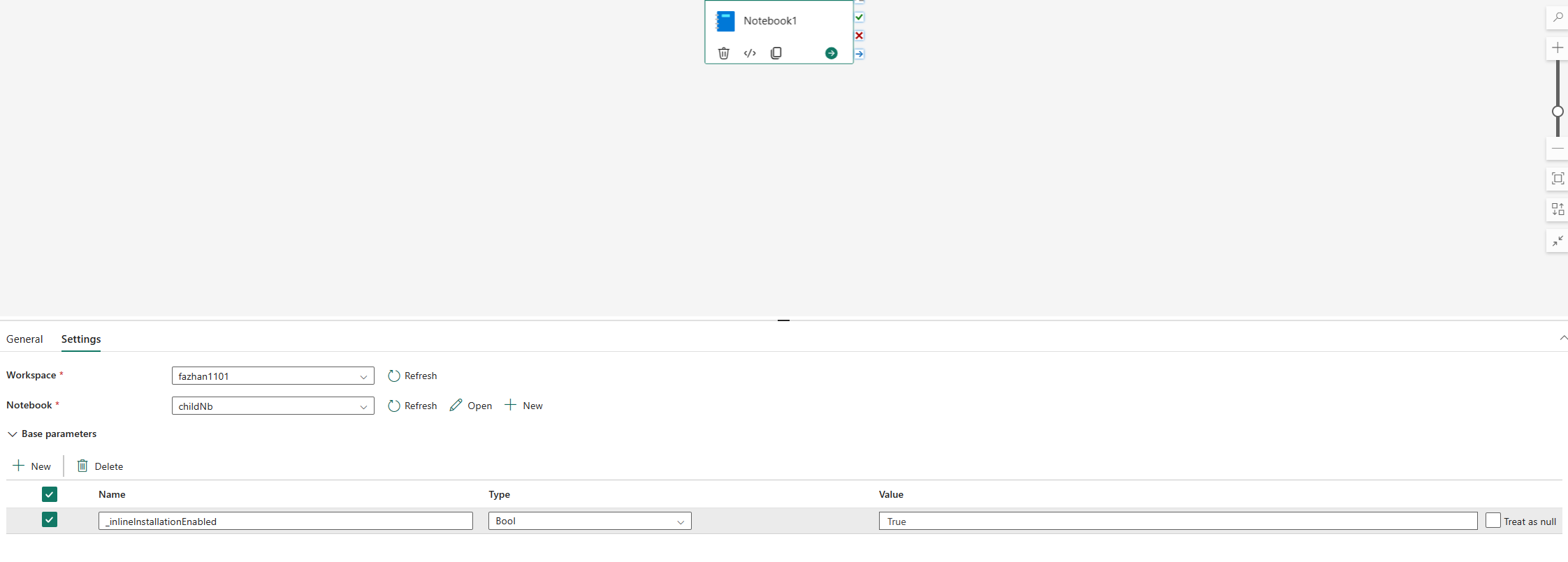
คําสั่งแบบอินไลน์สําหรับการจัดการไลบรารี Python จะถูกปิดใช้งานในไปป์ไลน์สมุดบันทึกที่เรียกใช้ตามค่าเริ่มต้น ถ้าคุณต้องการเปิดใช้งาน %pip install สําหรับไปป์ไลน์ เพิ่ม "_inlineInstallationEnabled" เป็นพารามิเตอร์บูลีนเท่ากับจริงในพารามิเตอร์กิจกรรมของสมุดบันทึก
หมายเหตุ
อาจทําให้ %pip install ผลลัพธ์ไม่สอดคล้องกันเป็นครั้งคราว ขอแนะนําให้ติดตั้งไลบรารีในสภาพแวดล้อมและใช้ในไปป์ไลน์
ในการอ้างอิงสมุดบันทึกทํางาน คําสั่งแบบอินไลน์สําหรับการจัดการไลบรารี Python จะไม่ได้รับการสนับสนุน เพื่อให้แน่ใจว่าความถูกต้องของการดําเนินการ ขอแนะนําให้ลบคําสั่งแบบอินไลน์เหล่านี้ออกจากสมุดบันทึกที่อ้างอิง
เราขอแนะนําให้%pipใช้ แทน!pip
!pip เป็นคําสั่งเชลล์ภายใน IPython ซึ่งมีข้อจํากัดดังต่อไปนี้:
-
!pipติดตั้งแพคเกจบนโหนดโปรแกรมควบคุมเท่านั้น ไม่ใช่โหนดตัวดําเนินการ - แพคเกจที่ติดตั้งผ่าน
!pipจะไม่ส่งผลกระทบต่อข้อขัดแย้งกับแพคเกจที่มีอยู่แล้วภายใน หรือว่าแพคเกจจะถูกนําเข้าในสมุดบันทึกอยู่แล้วหรือไม่
อย่างไรก็ตาม %pip จะจัดการสถานการณ์เหล่านี้ ไลบรารีที่ติดตั้งผ่าน %pip มีพร้อมใช้งานบนโหนดโปรแกรมควบคุมและตัวดําเนินการและยังคงมีประสิทธิภาพแม้ไลบรารีจะถูกนําเข้าอยู่แล้ว
เคล็ดลับ
โดยปกติ %conda install แล้วคําสั่งจะใช้เวลานานกว่าคําสั่งใน %pip install การติดตั้งไลบรารี Python ใหม่ ซึ่งจะตรวจสอบการขึ้นต่อกันแบบเต็มและแก้ไขข้อขัดแย้ง
คุณอาจต้องการใช้ %conda install เพื่อความน่าเชื่อถือและความเสถียรมากขึ้น คุณสามารถใช้ %pip install ถ้าคุณแน่ใจว่าไลบรารีที่คุณต้องการติดตั้งไม่ขัดแย้งกับไลบรารีที่ติดตั้งไว้ล่วงหน้าในสภาพแวดล้อมรันไทม์
สําหรับคําสั่งแบบอินไลน์และการชี้แจง Python ที่พร้อมใช้งานทั้งหมด โปรดดู คําสั่ง %pip และ คําสั่ง %conda
จัดการไลบรารีสาธารณะของ Python ผ่านการติดตั้งแบบอินไลน์
ในตัวอย่างนี้ ดูวิธีการใช้คําสั่งแบบอินไลน์เพื่อจัดการไลบรารี สมมติว่าคุณต้องการใช้ altair ไลบรารีการแสดงภาพที่มีประสิทธิภาพสําหรับ Python สําหรับการสํารวจข้อมูลครั้งเดียว สมมติว่าไลบรารีไม่ได้ติดตั้งอยู่ในพื้นที่ทํางานของคุณ ตัวอย่างต่อไปนี้ใช้คําสั่ง conda เพื่อแสดงขั้นตอน
คุณสามารถใช้คําสั่งแบบอินไลน์เพื่อเปิดใช้งาน การสลับ บนเซสชันสมุดบันทึกของคุณโดยไม่มีผลต่อเซสชันอื่นของสมุดบันทึกหรือรายการอื่นๆ
เรียกใช้คําสั่งต่อไปนี้ในเซลล์รหัสสมุดบันทึก คําสั่งแรกจะติดตั้งไลบรารี altair นอกจากนี้ติดตั้ง vega_datasets ซึ่งประกอบด้วยแบบจําลองความหมายที่คุณสามารถใช้เพื่อแสดงภาพ
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandผลลัพธ์ของเซลล์ระบุผลลัพธ์ของการติดตั้ง
นําเข้าแพคเกจและแบบจําลองความหมายโดยการเรียกใช้โค้ดต่อไปนี้ในเซลล์สมุดบันทึกอื่น
import altair as alt from vega_datasets import dataในตอนนี้คุณสามารถเล่นกับไลบรารี altair ที่มีขอบเขตเซสชัน
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
จัดการไลบรารีแบบกําหนดเองของ Python ผ่านการติดตั้งแบบอินไลน์
คุณสามารถอัปโหลดไลบรารีแบบกําหนดเอง Python ของคุณไปยังโฟลเดอร์ทรัพยากรของสมุดบันทึกของคุณหรือสภาพแวดล้อมที่แนบมา โฟลเดอร์ทรัพยากรเป็นระบบไฟล์ที่มีอยู่ภายในซึ่งได้รับจากสมุดบันทึกและสภาพแวดล้อมแต่ละรายการ ดู ทรัพยากร สมุดบันทึก สําหรับรายละเอียดเพิ่มเติม หลังจากอัปโหลดคุณสามารถลากและวางไลบรารีแบบกําหนดเองไปยังเซลล์โค้ดคําสั่งแบบอินไลน์เพื่อติดตั้งไลบรารีจะถูกสร้างขึ้นโดยอัตโนมัติ หรือคุณสามารถใช้คําสั่งต่อไปนี้เพื่อติดตั้ง
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
การติดตั้งแบบอินไลน์ R
เพื่อจัดการไลบรารี R Fabric สนับสนุนinstall.packages()คําสั่ง , remove.packages()และdevtools:: สําหรับคําสั่งแบบอินไลน์และคําสั่งแบบอินไลน์ที่พร้อมใช้งานทั้งหมด โปรดดูคําสั่ง install.packages และ remove.package command
จัดการไลบรารีสาธารณะ R ผ่านการติดตั้งแบบอินไลน์
ทําตามตัวอย่างนี้เพื่อทําตามขั้นตอนของการติดตั้งไลบรารีสาธารณะ R
เมื่อต้องการติดตั้งไลบรารีตัวดึงข้อมูล R:
สลับภาษาการทํางานไปยัง SparkR (R) ในริบบอนสมุดบันทึก
ติดตั้งไลบรารี caesar โดยการเรียกใช้คําสั่งต่อไปนี้ในเซลล์สมุดบันทึก
install.packages("caesar")ตอนนี้คุณสามารถใช้งานไลบรารี caesar ที่มีขอบเขตเซสชันด้วยงาน Spark ได้แล้ว
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
จัดการไลบรารี Jar ผ่านการติดตั้งแบบอินไลน์
ไฟล์ .jar สนับสนุนในเซสชันสมุดบันทึกด้วยคําสั่งต่อไปนี้
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
เซลล์โค้ดใช้ที่เก็บข้อมูลของ Lakehouse เป็นตัวอย่าง ที่ notebook explorer คุณสามารถคัดลอกไฟล์แบบเต็มเส้นทาง ABFS และแทนที่ในรหัส
