ผู้ให้คําแนะนํา Apache Spark สําหรับคําแนะนําแบบเรียลไทม์บนสมุดบันทึก
โปรแกรมแนะนํา Apache Spark จะวิเคราะห์คําสั่งและโค้ดที่เรียกใช้โดย Apache Spark และแสดงคําแนะนําแบบเรียลไทม์สําหรับการเรียกใช้สมุดบันทึก Apache Spark advisor มีรูปแบบที่มีอยู่แล้วภายในเพื่อช่วยให้ผู้ใช้หลีกเลี่ยงข้อผิดพลาดทั่วไปได้ ซึ่งมีคําแนะนําสําหรับการปรับโค้ดให้เหมาะสม ทําการวิเคราะห์ข้อผิดพลาด และค้นหาสาเหตุที่แท้จริงของความล้มเหลว
คําแนะนําในตัว
คําแนะนํา Spark ซึ่งเป็นเครื่องมือที่รวมเข้ากับ Impulse มีรูปแบบที่มีอยู่แล้วภายในสําหรับการตรวจสอบและแก้ไขปัญหาในแอปพลิเคชัน Apache Spark บทความนี้อธิบายรูปแบบบางอย่างที่รวมอยู่ในเครื่องมือ
คุณสามารถเปิดบานหน้าต่าง การทํางาน ล่าสุดตามชนิดของคําแนะนําที่คุณต้องการ
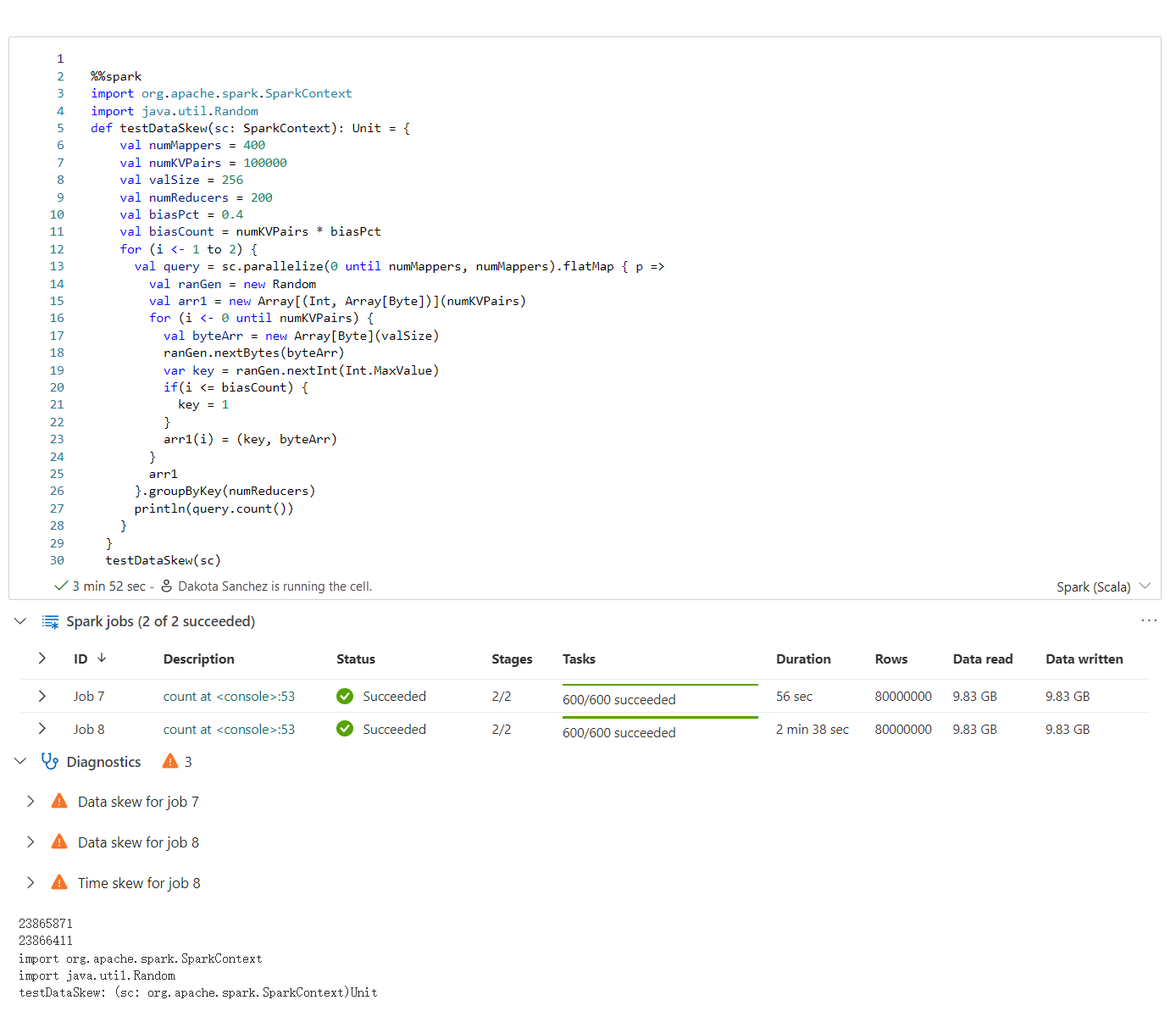
อาจส่งกลับผลลัพธ์ที่ไม่สอดคล้องกันเมื่อใช้ 'randomSplit'
ระบบอาจส่งกลับผลลัพธ์ที่ไม่สอดคล้องกันหรือไม่แม่นยําเมื่อทํางานกับเมธอด randomSplit ใช้การแคช Apache Spark (RDD) ก่อนใช้เมธอด randomSplit()
เมธอด randomSplit() เทียบเท่ากับการดําเนินการ sample() บนเฟรมข้อมูลของคุณหลายครั้ง ในกรณีที่แต่ละตัวอย่างซ้ํา พาร์ติชัน และเรียงลําดับเฟรมข้อมูลของคุณภายในพาร์ติชัน การกระจายข้อมูลข้ามพาร์ติชันและลําดับการจัดเรียงมีความสําคัญสําหรับทั้ง randomSplit() และ sample() ถ้าการเปลี่ยนแปลงเมื่อข้อมูลถูกดึงข้อมูล อาจมีค่าที่ซ้ํากันหรือขาดหายไประหว่างการแยก และตัวอย่างเดียวกันที่ใช้เมล็ดเดียวกันอาจสร้างผลลัพธ์ที่แตกต่างกัน
ความไม่สอดคล้องกันเหล่านี้อาจไม่เกิดขึ้นในทุกการเรียกใช้ แต่เพื่อกําจัดทั้งหมด แคชในเฟรมข้อมูลของคุณ พาร์ติชันใหม่บนคอลัมน์ หรือใช้ฟังก์ชันรวมเช่น groupBy
ชื่อตาราง/มุมมองถูกใช้งานอยู่แล้ว
มีมุมมองที่ใช้ชื่อเดียวกันกับตารางที่สร้างขึ้นอยู่แล้ว หรือมีตารางอยู่แล้วโดยใช้ชื่อเดียวกันกับมุมมองที่สร้างขึ้น เมื่อใช้ชื่อนี้ในคิวรีหรือแอปพลิเคชัน เฉพาะมุมมองเท่านั้นที่จะถูกส่งกลับไม่ว่าชื่อจะถูกสร้างก่อนก็ตาม เพื่อหลีกเลี่ยงข้อขัดแย้ง ให้เปลี่ยนชื่อตารางหรือมุมมอง
ไม่สามารถจดจําคําแนะนําได้
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
ไม่พบชื่อความสัมพันธ์ที่ระบุ
ไม่พบความสัมพันธ์ที่ระบุในคําแนะนํา ตรวจสอบว่าสะกดความสัมพันธ์อย่างถูกต้องและสามารถเข้าถึงได้ภายในขอบเขตของคําแนะนํา
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
คําแนะนําในคิวรีป้องกันไม่ให้มีการใช้คําแนะนําอื่น
คิวรีที่เลือกประกอบด้วยคําแนะนําที่ป้องกันไม่ให้มีการใช้คําแนะนําอื่น
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
เปิดใช้งาน 'spark.advise.divisionExprConvertRule.enable' เพื่อลดการเผยแพร่ข้อผิดพลาดการปัดเศษ
คิวรีนี้มีนิพจน์ชนิด Double เราขอแนะนําให้คุณเปิดใช้งานการกําหนดค่า 'spark.advise.divisionExprConvertRule.enable' ซึ่งสามารถช่วยลดนิพจน์การหารและลดการเผยแพร่ข้อผิดพลาดการปัดเศษได้
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
เปิดใช้งาน 'spark.advise.nonEqJoinConvertRule.enable' เพื่อปรับปรุงประสิทธิภาพการทํางานของคิวรี
คิวรีนี้ประกอบด้วยการรวมที่ใช้เวลานาน เนื่องจากเงื่อนไข "Or" ภายในคิวรี เราขอแนะนําให้คุณเปิดใช้งานการกําหนดค่า 'spark.advise.nonEqJoinConvertRule.enable' ซึ่งสามารถช่วยในการแปลงการรวมที่ทริกเกอร์โดยเงื่อนไข "Or" เป็น SMJ หรือ BHJ เพื่อเร่งความเร็วคิวรีนี้
ประสบการณ์ผู้ใช้
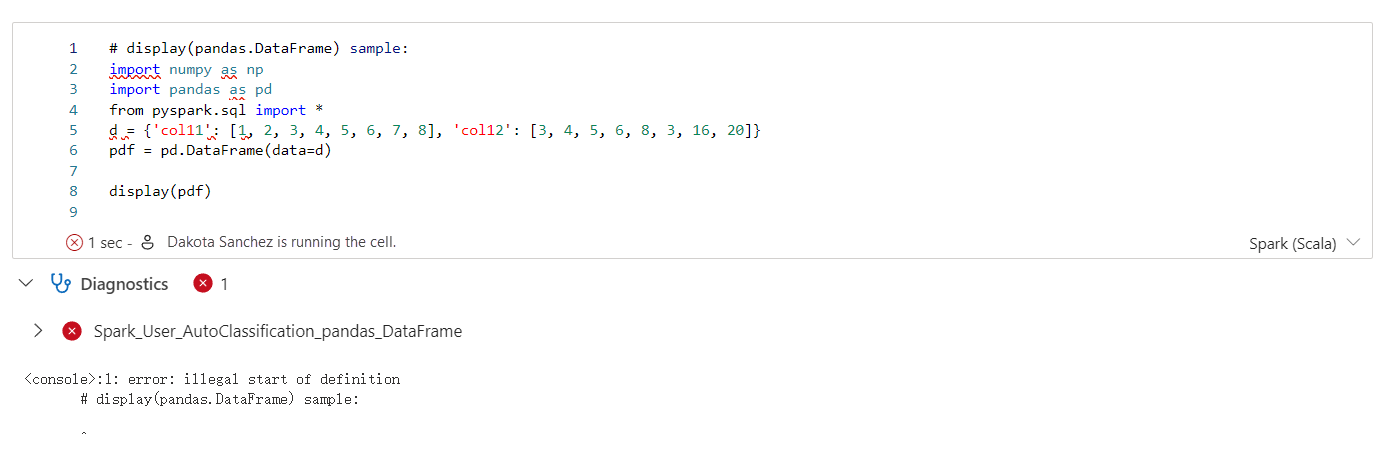
โปรแกรมช่วยแนะนํา Apache Spark จะแสดงคําแนะนํา รวมถึงข้อมูล คําเตือน และข้อผิดพลาดที่ผลลัพธ์ของเซลล์ Notebook ในแบบเรียลไทม์
ข้อมูล

คำ เตือน
ข้อ ผิด พลาด
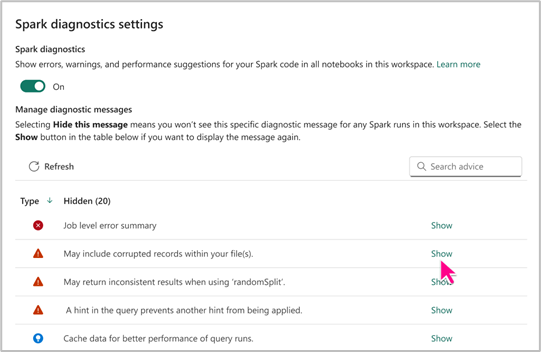
การตั้งค่า Spark Advisor
การตั้งค่า Spark advisor ช่วยให้คุณสามารถเลือกว่าจะแสดงหรือซ่อนคําแนะนํา Spark ชนิดเฉพาะตามความต้องการของคุณหรือไม่ นอกจากนี้ คุณมีความยืดหยุ่นในการเปิดหรือปิดใช้งาน Spark Advisor สําหรับสมุดบันทึกของคุณภายในพื้นที่ทํางานโดยขึ้นอยู่กับการกําหนดลักษณะของคุณ
คุณสามารถเข้าถึงการตั้งค่า Spark Advisor ที่ระดับ Fabric Notebook เพื่อเพลิดเพลินไปกับสิทธิประโยชน์และรับประกันถึงประสบการณ์การเขียนสมุดบันทึกที่มีประสิทธิภาพ