บทช่วยสอน: สร้าง ประเมิน และให้คะแนนแบบจําลองการคาดการณ์การเลิกใช้บริการ
บทช่วยสอนนี้แสดงตัวอย่างแบบ end-to-end ของเวิร์กโฟลว์ Synapse Data Science ใน Microsoft Fabric สถานการณ์สมมติจะสร้างแบบจําลองเพื่อคาดการณ์ว่าลูกค้าจะเลิกใช้บริการหรือไม่ อัตราการเลิกใช้บริการหรืออัตราที่มาซึ่งเกี่ยวข้องกับอัตราที่ลูกค้าธนาคารสิ้นสุดธุรกิจกับธนาคาร
บทช่วยสอนนี้ครอบคลุมขั้นตอนเหล่านี้:
- ติดตั้งไลบรารีแบบกําหนดเอง
- โหลดข้อมูล
- ทําความเข้าใจและประมวลผลข้อมูลผ่านการวิเคราะห์ข้อมูลเชิงสํารวจ และแสดงการใช้คุณลักษณะ Fabric Data Wrangler
- ใช้ scikit-learn และ LightGBM เพื่อฝึกแบบจําลองการเรียนรู้ของเครื่อง และติดตามการทดลองด้วยฟีเจอร์ MLflow และ Fabric Autologging
- ประเมินและบันทึกแบบจําลองการเรียนรู้ของเครื่องขั้นสุดท้าย
- แสดงประสิทธิภาพของแบบจําลองด้วยการแสดงภาพ Power BI
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric

- หากจําเป็น ให้สร้าง Microsoft Fabric lakehouse ตามที่อธิบายไว้ใน สร้างเลคเฮ้าส์ใน Microsoft Fabric
ติดตามในสมุดบันทึก
คุณสามารถเลือกหนึ่งในตัวเลือกเหล่านี้เพื่อติดตามในสมุดบันทึกได้:
- เปิดและเรียกใช้สมุดบันทึกที่มีอยู่ภายใน
- อัปโหลดสมุดบันทึกของคุณจาก GitHub
เปิดสมุดบันทึกที่มีอยู่แล้วภายใน
ตัวอย่าง Customer churn notebook มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกตัวอย่างสําหรับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
นําเข้าสมุดบันทึกจาก GitHub
AIsample - Customer Churn.ipynb notebook มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล การนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางโค้ดจากหน้านี้ สร้างสมุดบันทึกใหม่
ตรวจสอบให้แน่ใจว่า แนบ lakehouse เข้ากับ สมุดบันทึกก่อนที่คุณจะเริ่มเรียกใช้โค้ด
ขั้นตอนที่ 1: ติดตั้งไลบรารีแบบกําหนดเอง
สําหรับการพัฒนาแบบจําลองการเรียนรู้ของเครื่องหรือการวิเคราะห์ข้อมูลเฉพาะกิจ คุณอาจจําเป็นต้องติดตั้งไลบรารีแบบกําหนดเองสําหรับเซสชัน Apache Spark ของคุณได้อย่างรวดเร็ว คุณมีสองตัวเลือกในการติดตั้งไลบรารี
- ใช้ความสามารถในการติดตั้งแบบอินไลน์ (
%pipหรือ%conda) ของสมุดบันทึกของคุณเพื่อติดตั้งไลบรารีในสมุดบันทึกปัจจุบันของคุณเท่านั้น - อีกวิธีหนึ่งคือ คุณสามารถสร้างสภาพแวดล้อม Fabric ติดตั้งไลบรารีจากแหล่งข้อมูลสาธารณะ หรืออัปโหลดไลบรารีแบบกําหนดเอง จากนั้นผู้ดูแลระบบพื้นที่ทํางานของคุณสามารถแนบสภาพแวดล้อมเป็นค่าเริ่มต้นสําหรับพื้นที่ทํางานได้ ไลบรารีทั้งหมดในสภาพแวดล้อมจะพร้อมใช้งานสําหรับใช้ในข้อกําหนดงานของสมุดบันทึกและ Spark ในพื้นที่ทํางาน สําหรับข้อมูลเพิ่มเติมเกี่ยวกับสภาพแวดล้อม ให้ดู สร้าง กําหนดค่า และใช้สภาพแวดล้อมใน Microsoft Fabric
สําหรับบทช่วยสอนนี้ ให้ใช้ %pip install เพื่อติดตั้งไลบรารี imblearn ในสมุดบันทึกของคุณ
โน้ต
เคอร์เนล PySpark รีสตาร์ทหลังจาก %pip install ทํางาน ติดตั้งไลบรารีที่จําเป็นก่อนที่คุณจะเรียกใช้เซลล์อื่นๆ
# Use pip to install libraries
%pip install imblearn
ขั้นตอนที่ 2: โหลดข้อมูล
ชุดข้อมูลใน churn.csv ประกอบด้วยสถานะการเลิกใช้บริการของลูกค้า 10,000 ราย พร้อมกับแอตทริบิวต์ 14 รายการที่มี:
- คะแนนเครดิต
- ตําแหน่งที่ตั้งทางภูมิศาสตร์ (เยอรมนี ฝรั่งเศส สเปน)
- เพศ (ชาย, หญิง)
- อายุ
- ระยะเวลาการครอบครอง (จํานวนปีที่บุคคลเป็นลูกค้าที่ธนาคารนั้น)
- ยอดคงเหลือบัญชี
- เงินเดือนโดยประมาณ
- จํานวนผลิตภัณฑ์ที่ลูกค้าซื้อผ่านธนาคาร
- สถานะบัตรเครดิต (ลูกค้ามีบัตรเครดิตหรือไม่ก็ตาม)
- สถานะสมาชิกที่ใช้งานอยู่ (ไม่ว่าบุคคลนั้นจะเป็นลูกค้าธนาคารที่ใช้งานอยู่หรือไม่)
ชุดข้อมูลยังรวมถึงคอลัมน์หมายเลขแถว รหัสลูกค้า และนามสกุลของลูกค้า ค่าในคอลัมน์เหล่านี้ไม่ควรมีอิทธิพลต่อการตัดสินใจของลูกค้าในการออกจากธนาคาร
เหตุการณ์การปิดบัญชีธนาคารของลูกค้าจะกําหนดการเลิกใช้บริการสําหรับลูกค้านั้น คอลัมน์ Exited ชุดข้อมูลอ้างอิงถึงการละทิ้งลูกค้า เนื่องจากเรามีบริบทเพียงเล็กน้อยเกี่ยวกับแอตทริบิวต์เหล่านี้ เราจึงไม่ต้องการข้อมูลพื้นหลังเกี่ยวกับชุดข้อมูล เราต้องการทําความเข้าใจว่าแอตทริบิวต์เหล่านี้มีส่วนร่วมในสถานะ Exited อย่างไร
จากลูกค้า 10,000 รายเหล่านั้น มีลูกค้าเพียง 2037 รายเท่านั้น (ประมาณ 20%) ออกจากธนาคาร เนื่องจากอัตราส่วนความไม่สมดุลของคลาส เราขอแนะนําให้สร้างข้อมูลสังเคราะห์ ความแม่นยําของเมทริกซ์ความสับสนอาจไม่เกี่ยวข้องกันสําหรับการจําแนกประเภทที่ไม่สมดุล เราอาจต้องการวัดความแม่นยําโดยใช้พื้นที่ภายใต้เส้นโค้ง Precision-Recall (AUPRC)
- ตารางนี้แสดงตัวอย่างของข้อมูล
churn.csv:
| รหัสลูกค้า | นามสกุล | CreditScore | ภูมิศาสตร์ | เพศ | อายุ | ระยะเวลาการครอบครอง | ตาชั่ง | NumOfProducts | HasCrCard | IsActiveMember | ประมาณเงินเดือน | ออกจากระบบแล้ว |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | ฮาร์กราฟ | 619 | ฝรั่งเศส | หญิง | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | ภูเขา | 608 | สเปน | หญิง | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
ดาวน์โหลดชุดข้อมูลและอัปโหลดไปยัง lakehouse
กําหนดพารามิเตอร์เหล่านี้เพื่อให้คุณสามารถใช้สมุดบันทึกนี้กับชุดข้อมูลที่แตกต่างกันได้:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
รหัสนี้จะดาวน์โหลดเวอร์ชันสาธารณะของชุดข้อมูล และจากนั้นจัดเก็บชุดข้อมูลนั้นในแฟบริคเลคเฮ้าส์:
สําคัญ
เพิ่มเลคเฮ้าส์ ลงในสมุดบันทึกก่อนที่คุณจะเรียกใช้ ความล้มเหลวในการทําเช่นนั้นจะส่งผลให้เกิดข้อผิดพลาด
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
เริ่มการบันทึกเวลาที่จําเป็นในการเรียกใช้สมุดบันทึก:
# Record the notebook running time
import time
ts = time.time()
อ่านข้อมูลดิบจากเลคเฮ้าส์
รหัสนี้อ่านข้อมูลดิบจากส่วน ไฟล์
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
สร้าง DataFrame ของ pandas จากชุดข้อมูล
รหัสนี้แปลง Spark DataFrame เป็น Pandas DataFrame เพื่อการประมวลผลและการแสดงภาพที่ง่ายขึ้น:
df = df.toPandas()
ขั้นตอนที่ 3: ดําเนินการวิเคราะห์ข้อมูลเชิงสํารวจ
แสดงข้อมูลดิบ
สํารวจข้อมูลดิบด้วย displayคํานวณสถิติพื้นฐานบางอย่าง และแสดงมุมมองแผนภูมิ ก่อนอื่น คุณต้องนําเข้าไลบรารีที่จําเป็นสําหรับการแสดงภาพข้อมูล - ตัวอย่างเช่น seaborn Seaborn เป็นไลบรารีการแสดงภาพข้อมูล Python และมีอินเทอร์เฟซระดับสูงเพื่อสร้างวิชวลบน dataframes และอาร์เรย์
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
ใช้ Data Wrangler เพื่อดําเนินการทําความสะอาดข้อมูลเริ่มต้น
เปิดใช้ Data Wrangler โดยตรงจากสมุดบันทึกเพื่อสํารวจและแปลงกรอบข้อมูลของ pandas เลือกรายการแบบเลื่อนลง Data Wrangler จากแถบเครื่องมือแนวนอนเพื่อเรียกดู DataFrame ของ pandas ที่เปิดใช้งานซึ่งพร้อมสําหรับการแก้ไข เลือก DataFrame ที่คุณต้องการเปิดใน Data Wrangler
โน้ต
ไม่สามารถเปิด Data Wrangler ได้ในขณะที่เคอร์เนลสมุดบันทึกไม่ว่าง การดําเนินการของเซลล์ต้องเสร็จสิ้นก่อนที่คุณจะเปิดใช้งาน Data Wrangler เรียนรู้เพิ่มเติมเกี่ยวกับWrangler

หลังจากเปิดใช้งาน Data Wrangler ภาพรวมเชิงพรรณนาของแผงข้อมูลจะถูกสร้างขึ้น ดังที่แสดงในภาพต่อไปนี้ ภาพรวมประกอบด้วยข้อมูลเกี่ยวกับขนาดของ DataFrame ค่าที่ขาดหายไป และอื่น ๆ คุณสามารถใช้ Data Wrangler เพื่อสร้างสคริปต์เพื่อวางแถวที่มีค่าที่ขาดหายไป แถวที่ซ้ํากัน และคอลัมน์ที่มีชื่อเฉพาะ จากนั้น คุณสามารถคัดลอกสคริปต์ลงในเซลล์ เซลล์ถัดไปแสดงสคริปต์ที่คัดลอก


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
กําหนดแอตทริบิวต์
รหัสนี้กําหนดแอตทริบิวต์จัดกลุ่ม ตัวเลข และเป้าหมาย:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
แสดงสรุปตัวเลขห้าตัว
ใช้การลงจุดกล่องเพื่อแสดงสรุปจํานวนห้าตัว
- คะแนนต่ําสุด
- ควอร์ไทล์แรก
- มัธยฐาน
- ควอร์ไทล์ที่สาม
- คะแนนสูงสุด
สําหรับแอตทริบิวต์ตัวเลข
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
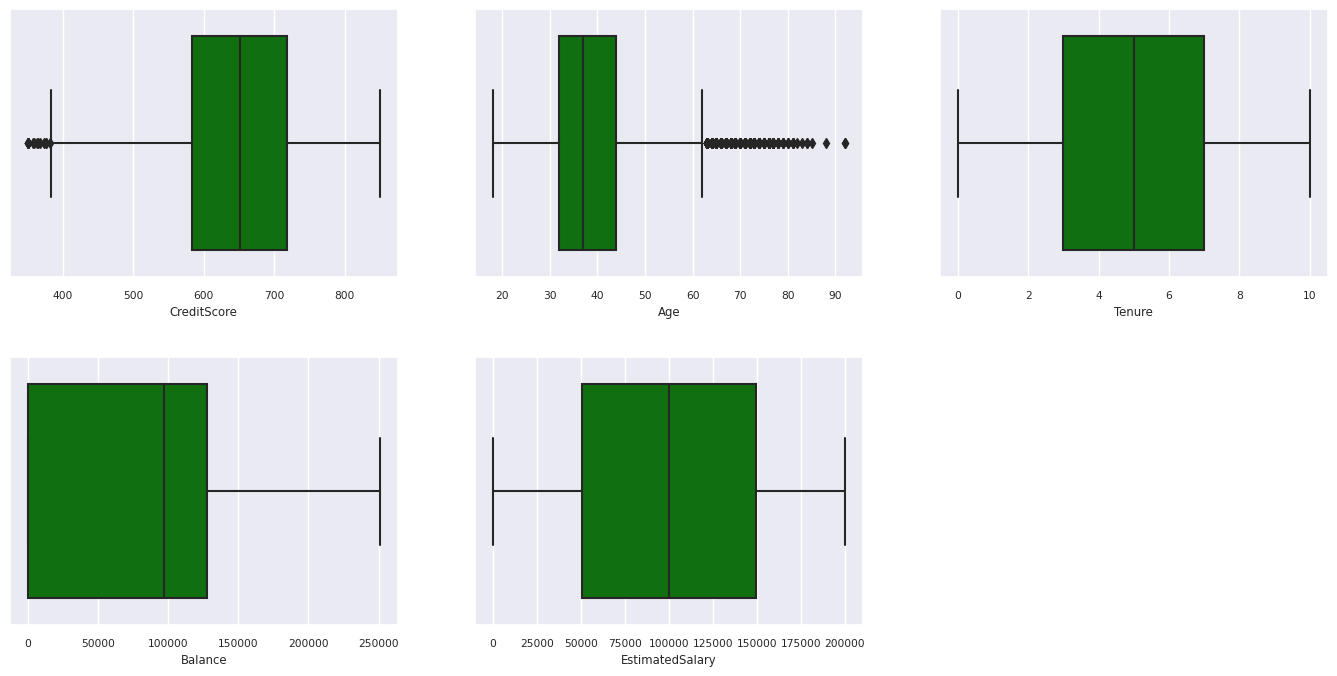
แสดงการกระจายของลูกค้าที่ออกจากงานและลูกค้าที่ไม่อยู่
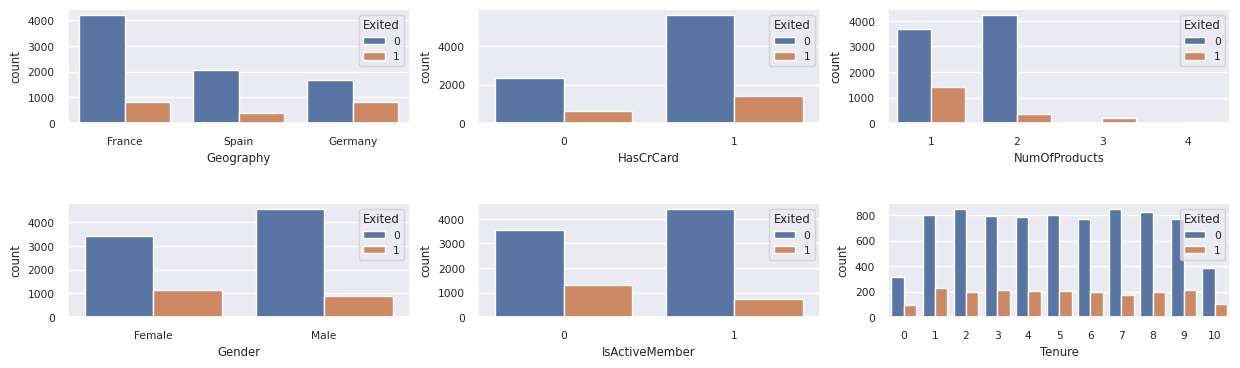
แสดงการกระจายของลูกค้าที่ถูกออกจากระบบเทียบกับลูกค้าที่ไม่ถูกส่งออกทั่วทั้งแอตทริบิวต์ประเภท:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
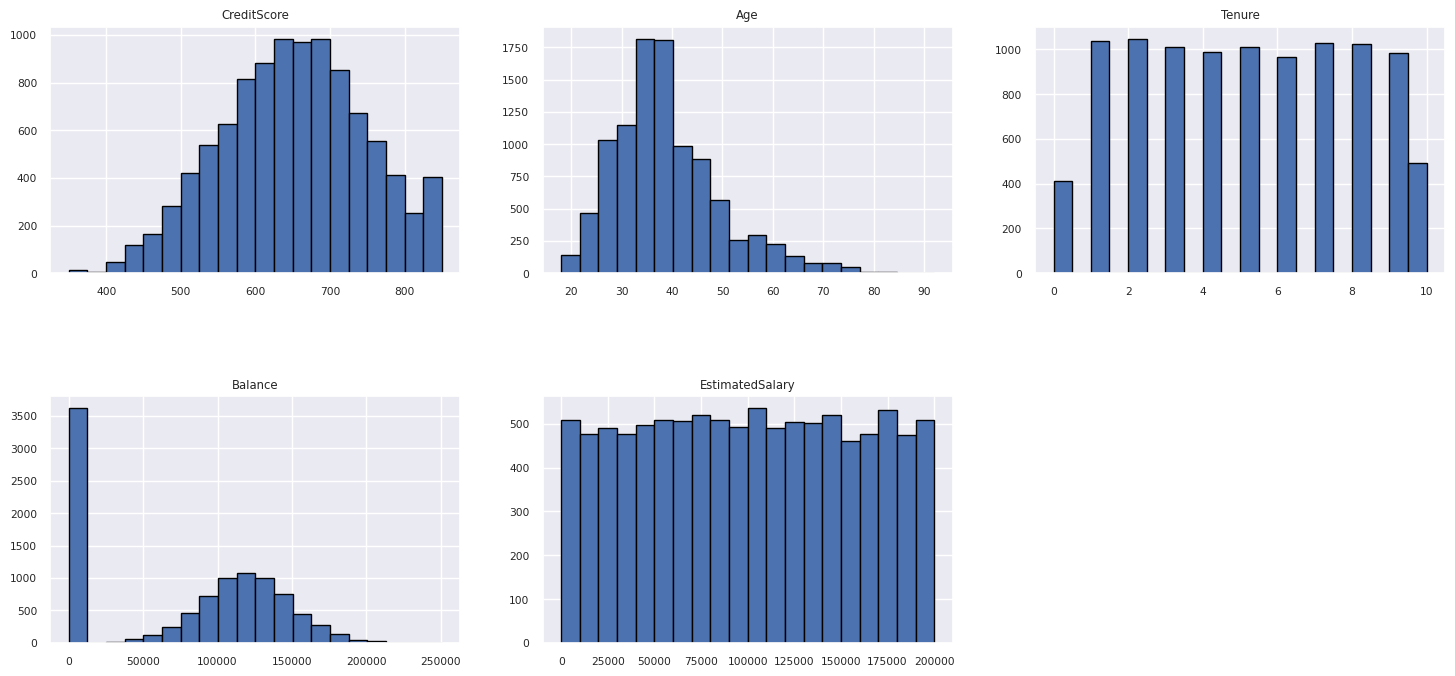
แสดงการกระจายของแอตทริบิวต์ตัวเลข
ใช้ฮิสโทแกรมเพื่อแสดงการกระจายความถี่ของแอตทริบิวต์ตัวเลข:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
ดําเนินการวิศวกรรมคุณลักษณะ
วิศวกรรมคุณลักษณะนี้สร้างแอตทริบิวต์ใหม่ตามแอตทริบิวต์ปัจจุบัน:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
ใช้ Data Wrangler เพื่อดําเนินการเข้ารหัสอย่างหนึ่งร้อน
ด้วยขั้นตอนเดียวกันนี้เมื่อต้องการเปิดใช้ Data Wrangler ตามที่อธิบายไว้ก่อนหน้านี้ ให้ใช้ Data Wrangler เพื่อดําเนินการเข้ารหัสแบบหนึ่งร้อน เซลล์นี้แสดงสคริปต์ที่สร้างที่คัดลอกสําหรับการเข้ารหัสอย่างหนึ่งที่กําลังร้อน:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
สร้างตารางส่วนที่แตกต่างเพื่อสร้างรายงาน Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
ข้อมูลสรุปของการสังเกตการณ์จากการวิเคราะห์ข้อมูลการสํารวจ
- ลูกค้าส่วนใหญ่มาจากฝรั่งเศส สเปนมีอัตราการเลิกใช้บริการต่ําสุดเมื่อเทียบกับฝรั่งเศสและเยอรมนี
- ลูกค้าส่วนใหญ่มีบัตรเครดิต
- ลูกค้าบางรายอายุเกิน 60 ปีและมีคะแนนเครดิตต่ํากว่า 400 อย่างไรก็ตามไม่สามารถถือว่าเป็นค่าผิดปกติได้
- ลูกค้าน้อยมากมีผลิตภัณฑ์ธนาคารมากกว่าสองรายการ
- ลูกค้าที่ไม่ได้ใช้งานมีอัตราการเลิกใช้บริการที่สูงขึ้น
- เพศและระยะเวลาการครอบครองมีผลกระทบต่อการตัดสินใจของลูกค้าเล็กน้อยในการปิดบัญชีธนาคาร
ขั้นตอนที่ 4: ดําเนินการฝึกอบรมและติดตามแบบจําลอง
ด้วยข้อมูลที่มีอยู่ ตอนนี้คุณสามารถกําหนดแบบจําลองได้แล้ว ใช้แบบจําลองฟอเรสต์แบบสุ่มและ LightGBM ในสมุดบันทึกนี้
ใช้ไลบรารี scikit-learn และ LightGBM เพื่อใช้แบบจําลองที่มีโค้ดสองถึงสามบรรทัด นอกจากนี้ ใช้ MLfLow และ Fabric Autologging เพื่อติดตามการทดลอง
ตัวอย่างรหัสนี้จะโหลดตารางเดลต้าจากเลคเฮาส์ คุณสามารถใช้ตารางเดลต้าอื่น ๆ ที่ตนเองใช้เลคเฮาส์เป็นแหล่งข้อมูลได้
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
สร้างการทดลองสําหรับการติดตามและการบันทึกแบบจําลองโดยใช้ MLflow
ส่วนนี้แสดงวิธีการสร้างการทดลอง และระบุแบบจําลองและพารามิเตอร์การฝึกอบรมและเมตริกการให้คะแนน นอกจากนี้ยังแสดงวิธีการฝึกแบบจําลอง บันทึกแบบจําลอง และบันทึกแบบจําลองที่ได้รับการฝึกไว้สําหรับการใช้งานในภายหลัง
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
การล็อกอัตโนมัติจะจับทั้งค่าพารามิเตอร์อินพุตและเมตริกเอาต์พุตของแบบจําลองการเรียนรู้ของเครื่องโดยอัตโนมัติตามแบบจําลองที่ได้รับการฝึกไว้ ข้อมูลนี้จะถูกบันทึกไปยังพื้นที่ทํางานของคุณที่ MLflow API หรือการทดลองที่สอดคล้องกันในพื้นที่ทํางานของคุณสามารถเข้าถึงและแสดงภาพได้
เมื่อเสร็จสิ้น การทดลองของคุณจะคล้ายกับรูปภาพนี้:

การทดลองทั้งหมดที่มีชื่อที่เกี่ยวข้องจะถูกบันทึก และคุณสามารถติดตามพารามิเตอร์และเมตริกประสิทธิภาพการทํางานได้ เมื่อต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ autologging ดู Autologging ใน Microsoft Fabric
ตั้งค่าข้อกําหนดการทดลองและการบันทึกอัตโนมัติ
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
นําเข้า scikit-learn และ LightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
เตรียมการฝึกอบรมและทดสอบชุดข้อมูล
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
นํา SMOTE ไปใช้กับข้อมูลการฝึก
การจัดประเภทแบบไม่สมดุลมีปัญหาเนื่องจากมีตัวอย่างน้อยเกินไปของคลาสน้อยสําหรับแบบจําลองเพื่อเรียนรู้ขอบเขตการตัดสินใจอย่างมีประสิทธิภาพ ในการจัดการกับปัญหานี้ เทคนิคการสุ่มตัวอย่างเล็กน้อยสังเคราะห์ (SMOTE) เป็นเทคนิคที่ใช้กันอย่างแพร่หลายมากที่สุดในการสังเคราะห์ตัวอย่างใหม่สําหรับระดับเล็กน้อย เข้าถึง SMOTE ด้วยไลบรารี imblearn ที่คุณติดตั้งในขั้นตอนที่ 1
ใช้ SMOTE กับชุดข้อมูลการฝึกอบรมเท่านั้น คุณต้องออกจากชุดข้อมูลทดสอบในการกระจายแบบไม่สมดุลเดิม เพื่อให้ได้ประมาณประสิทธิภาพของแบบจําลองที่ถูกต้องบนข้อมูลต้นฉบับ การทดลองนี้แสดงถึงสถานการณ์ในการผลิต
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
สําหรับข้อมูลเพิ่มเติม โปรดดู SMOTE และ จากการสุ่มตัวอย่างมากกว่าการสุ่มตัวอย่างไปยัง SMOTE และ ADASYN เว็บไซต์ imbalanced-learn โฮสต์ทรัพยากรเหล่านี้
ฝึกแบบจําลอง
ใช้ฟอเรสต์แบบสุ่มเพื่อฝึกแบบจําลองด้วยความลึกสูงสุดสี่รายการ และด้วยฟีเจอร์สี่รายการ:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
ใช้ฟอเรสต์แบบสุ่มเพื่อฝึกแบบจําลอง ให้ความลึกสูงสุดแปดตัว และหกคุณลักษณะ:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
ฝึกแบบจําลองด้วย LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
ดูวัตถุทดลองเพื่อติดตามประสิทธิภาพของแบบจําลอง
การเรียกใช้การทดลองจะถูกบันทึกไว้ในอาร์ติแฟกตการทดลองโดยอัตโนมัติ คุณสามารถค้นหาวัตถุนั้นในพื้นที่ทํางานได้ ชื่อวัตถุจะยึดตามชื่อที่ใช้ในการตั้งค่าการทดลอง แบบจําลองที่ได้รับการฝึกทั้งหมด การเรียกใช้ เมตริกประสิทธิภาพการทํางาน และพารามิเตอร์แบบจําลองจะถูกบันทึกไว้ในหน้าการทดสอบ
วิธีดูการทดลองของคุณ:
- บนแผงด้านซ้าย ให้เลือกพื้นที่ทํางานของคุณ
- ค้นหาและเลือกชื่อการทดสอบ ในกรณีนี้ sample-bank-churn-experiment
ขั้นตอนที่ 5: ประเมินและบันทึกแบบจําลองการเรียนรู้ของเครื่องขั้นสุดท้าย
เปิดการทดสอบที่บันทึกไว้จากพื้นที่ทํางานเพื่อเลือกและบันทึกแบบจําลองที่ดีที่สุด:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
ประเมินประสิทธิภาพของแบบจําลองที่บันทึกไว้ในชุดข้อมูลทดสอบ
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
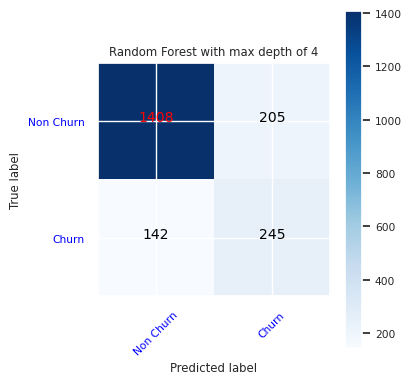
แสดงค่าบวก/ลบจริง/เท็จโดยใช้เมทริกซ์ความสับสน
ในการประเมินความแม่นยําของการจัดประเภท สร้างสคริปต์ที่ลงจุดเมทริกซ์ความสับสน คุณยังสามารถลงจุดเมทริกซ์ความสับสนโดยใช้เครื่องมือ SynapseML ดังที่แสดงในตัวอย่างการตรวจจับการฉ้อโกง
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
สร้างเมทริกซ์ความสับสนสําหรับตัวจําแนกประเภทฟอเรสต์แบบสุ่ม โดยให้ความลึกสูงสุดสี่รายการ ด้วยสี่คุณลักษณะ:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
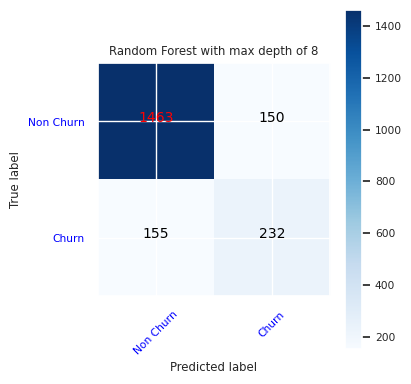
สร้างเมทริกซ์ความสับสนสําหรับตัวจําแนกประเภทฟอเรสต์แบบสุ่มที่มีความลึกสูงสุดแปดตัว ด้วยคุณลักษณะหกประการ:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
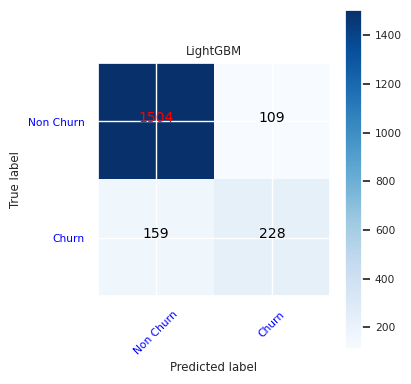
สร้างเมทริกซ์ความสับสนสําหรับ LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
บันทึกผลลัพธ์สําหรับ Power BI
บันทึกเฟรมส่วนที่แตกต่างไปยังเลคเฮ้าส์เพื่อย้ายผลลัพธ์การคาดการณ์แบบจําลองไปยังการแสดงภาพ Power BI
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
ขั้นตอนที่ 6: เข้าถึงการแสดงภาพใน Power BI
เข้าถึงตารางที่บันทึกไว้ใน Power BI:
- ทางด้านซ้าย ให้เลือก OneLake
- เลือกเลคเฮ้าส์ที่คุณเพิ่มลงในสมุดบันทึกนี้
- ในส่วน เปิด ของเลคเฮ้าส์นี้ ให้เลือก เปิด
- บนริบบอน ให้เลือก แบบจําลองความหมายใหม่ เลือก
df_pred_resultsจากนั้นเลือก ยืนยัน เพื่อสร้างแบบจําลองความหมาย Power BI ใหม่ที่เชื่อมโยงกับการคาดการณ์ - เปิดแบบจําลองความหมายใหม่ คุณสามารถค้นหาได้ใน OneLake
- เลือก สร้างรายงานใหม่ ภายใต้ไฟล์จากเครื่องมือที่ด้านบนของหน้าแบบจําลองความหมายเพื่อเปิดหน้าการเขียนรายงาน Power BI
สกรีนช็อตต่อไปนี้แสดงตัวอย่างการแสดงภาพ แผงข้อมูลแสดงตารางและคอลัมน์ delta เพื่อเลือกจากตาราง หลังจากเลือกประเภทที่เหมาะสม (x) และแกนค่า (y) คุณสามารถเลือกตัวกรองและฟังก์ชัน - ตัวอย่างเช่น ผลรวมหรือค่าเฉลี่ยของคอลัมน์ตาราง
โน้ต
ในสกรีนช็อตนี้ ตัวอย่างที่แสดงจะอธิบายการวิเคราะห์ผลลัพธ์การคาดการณ์ที่บันทึกไว้ใน Power BI:

อย่างไรก็ตาม สําหรับกรณีใช้งานที่ลูกค้าเลิกใช้บริการจริง ผู้ใช้อาจต้องมีชุดข้อกําหนดของการแสดงภาพข้อมูลอย่างละเอียดยิ่งขึ้นเพื่อสร้าง โดยขึ้นอยู่กับความเชี่ยวชาญเฉพาะเรื่อง และสิ่งที่ทีมวิเคราะห์บริษัทและธุรกิจ และบริษัทได้กําหนดมาตรฐานเป็นเมตริก
รายงาน Power BI แสดงให้เห็นว่าลูกค้าที่ใช้ผลิตภัณฑ์ธนาคารมากกว่าสองรายการมีอัตราการเลิกใช้บริการที่สูงขึ้น อย่างไรก็ตาม ลูกค้าเพียงไม่กี่รายมีผลิตภัณฑ์มากกว่าสองรายการ (ดูการลงจุดในบานหน้าต่างด้านล่างซ้าย) ธนาคารควรรวบรวมข้อมูลเพิ่มเติม แต่ควรตรวจสอบคุณสมบัติอื่น ๆ ที่สัมพันธ์กับผลิตภัณฑ์เพิ่มเติม
ลูกค้าของธนาคารในประเทศเยอรมนีมีอัตราการเลิกใช้บริการที่สูงขึ้นเมื่อเทียบกับลูกค้าในฝรั่งเศสและสเปน (ดูการลงจุดในบานหน้าต่างด้านล่างขวา) จากผลลัพธ์ของรายงาน การตรวจสอบปัจจัยที่สนับสนุนให้ลูกค้าออกจากงานอาจช่วยได้
มีลูกค้าที่มีอายุกลางมากขึ้น (ระหว่าง 25 ถึง 45) ลูกค้าระหว่าง 45 ถึง 60 มีแนวโน้มที่จะออกจากที่นี่มากขึ้น
ในที่สุดลูกค้าที่มีคะแนนเครดิตต่ํากว่ามีแนวโน้มที่จะออกจากธนาคารสําหรับสถาบันการเงินอื่น ๆ ธนาคารควรสํารวจวิธีที่จะส่งเสริมให้ลูกค้ามีคะแนนเครดิตที่ต่ํากว่าและยอดคงเหลือบัญชีเพื่ออยู่กับธนาคาร
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")
เนื้อหาที่เกี่ยวข้อง
- แบบจําลองการเรียนรู้ของเครื่อง ใน Microsoft Fabric
- แบบจําลองการเรียนรู้ของเครื่อง Train
- การทดลองการเรียนรู้ของเครื่อง ใน Microsoft Fabric