การให้คะแนนแบบจําลองการเรียนรู้ของเครื่องด้วย PREDICT ใน Microsoft Fabric
Microsoft Fabric ช่วยให้ผู้ใช้สามารถดําเนินการแบบจําลองการเรียนรู้ของเครื่องด้วยฟังก์ชันที่ปรับขนาดได้ที่เรียกว่า PREDICT ซึ่งสนับสนุนการให้คะแนนกลุ่มในกลไกการคํานวณใด ๆ ผู้ใช้สามารถสร้างการคาดการณ์แบบกลุ่มได้โดยตรงจากสมุดบันทึก Microsoft Fabric หรือจากหน้ารายการของแบบจําลอง ML ที่กําหนด
ในบทความนี้ คุณจะได้เรียนรู้วิธีการทํานายทั้งสองวิธี ไม่ว่าคุณจะเขียนโค้ดด้วยตนเองหรือใช้ประสบการณ์ UI ที่แนะนําเพื่อจัดการกับการให้คะแนนชุดสําหรับคุณ
ข้อกำหนดเบื้องต้น
รับการสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนเพื่อทดลองใช้งาน Microsoft Fabric ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์ทางด้านซ้ายของโฮมเพจของคุณเพื่อสลับไปยังประสบการณ์วิทยาศาสตร์ข้อมูล Synapse

ข้อจำกัด
- ในขณะนี้ฟังก์ชัน PREDICT ได้รับการสนับสนุนสําหรับชุดที่จํากัดของรสชาติแบบจําลอง ML รวมถึง:
- PyTorch
- Sklearn
- Spark
- TensorFlow
- ONNX
- XGBoost
- LightGBM
- CatBoost
- Statsmodels
- ศาสดาพยากรณ์
- Keras
- PREDICT จําเป็นต้องใช้ แบบจําลอง ML เพื่อบันทึกในรูปแบบ MLflow ที่มีลายเซ็นที่เติม
- PREDICT ไม่สนับสนุน แบบจําลอง ML ที่มีอินพุตหรือเอาต์พุตหลายตัว
เรียกการคาดการณ์จากสมุดบันทึก
PREDICT สนับสนุนแบบจําลองแพคเกจ MLflow ในรีจิสทรีของ Microsoft Fabric ถ้ามีแบบจําลอง ML ที่ได้รับการฝึกและลงทะเบียนแล้วในพื้นที่ทํางานของคุณ คุณสามารถข้ามไปยังขั้นตอนที่ 2 ได้ ถ้าไม่ใช่ ขั้นตอนที่ 1 ให้รหัสตัวอย่างเพื่อแนะนําคุณผ่านการฝึกแบบจําลองการถดถอยโลจิสติกส์ตัวอย่าง คุณสามารถใช้แบบจําลองนี้เพื่อสร้างการคาดการณ์ชุดงานในตอนท้ายของกระบวนการ
ฝึกแบบจําลอง ML และลงทะเบียนด้วย MLflow โค้ดตัวอย่างต่อไปนี้ใช้ MLflow API เพื่อสร้างการทดลองการเรียนรู้ของเครื่องและเริ่มต้นการเรียกใช้ MLflow สําหรับแบบจําลองการถดถอยโลจิสติกส์ scikit-learn จากนั้นเวอร์ชันแบบจําลองจะถูกจัดเก็บและลงทะเบียนในรีจิสทรี Microsoft Fabric ดู วิธีการฝึกแบบจําลอง ML ด้วย scikit-learn เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับแบบจําลองการฝึกอบรมและการติดตามการทดลองของคุณเอง
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )โหลดในข้อมูลทดสอบเป็น Spark DataFrame หากต้องการสร้างการคาดการณ์แบบกลุ่มโดยใช้รูปแบบ ML ที่ได้รับการฝึกในขั้นตอนก่อนหน้านี้ คุณจําเป็นต้องทดสอบข้อมูลในรูปแบบของ Spark DataFrame คุณสามารถแทนที่ค่าสําหรับ
testตัวแปรในรหัสต่อไปนี้ด้วยข้อมูลของคุณเอง# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))MLFlowTransformerสร้างวัตถุเพื่อโหลดแบบจําลอง ML สําหรับการอนุมาน หากต้องการสร้างMLFlowTransformerออบเจ็กต์สําหรับการสร้างการคาดการณ์ชุดงาน คุณต้องดําเนินการต่อไปนี้:- ระบุคอลัมน์จาก
testDataFrame ที่คุณต้องการเป็นข้อมูลป้อนเข้าแบบจําลอง (ในกรณีนี้ทั้งหมด) - เลือกชื่อสําหรับคอลัมน์ผลลัพธ์ใหม่ (ในกรณีนี้คือ
predictions) และ - ระบุชื่อแบบจําลองที่ถูกต้องและรุ่นแบบจําลองสําหรับการสร้างการคาดการณ์เหล่านั้น
ถ้าคุณกําลังใช้แบบจําลอง ML ของคุณเอง ให้แทนที่ค่าสําหรับคอลัมน์อินพุต ชื่อคอลัมน์ผลลัพธ์ ชื่อแบบจําลอง และเวอร์ชันแบบจําลอง
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- ระบุคอลัมน์จาก
สร้างการคาดการณ์โดยใช้ฟังก์ชัน PREDICT หากต้องการเรียกใช้ฟังก์ชัน PREDICT คุณสามารถใช้ Transformer API, Spark SQL API หรือฟังก์ชันที่ผู้ใช้กําหนดเองแบบ PySpark (UDF) ได้ ส่วนต่อไปนี้แสดงวิธีการสร้างการคาดการณ์ชุดงานด้วยข้อมูลทดสอบและแบบจําลอง ML ที่กําหนดไว้ในขั้นตอนก่อนหน้านี้โดยใช้วิธีการที่แตกต่างกันสําหรับการเรียกใช้การคาดการณ์
คาดการณ์ด้วย API ตัวแปลง
โค้ดต่อไปนี้จะเรียกใช้ฟังก์ชัน PREDICT กับ Transformer API หากคุณใช้แบบจําลอง ML ของคุณเองให้แทนที่ค่าสําหรับแบบจําลองและทดสอบข้อมูล
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
คาดการณ์ด้วย Spark SQL API
โค้ดต่อไปนี้จะเรียกใช้ฟังก์ชัน PREDICT ด้วย Spark SQL API หากคุณใช้แบบจําลอง ML ของคุณเองให้แทนที่ค่าสําหรับ model_namemodel_version, และ features ด้วยชื่อแบบจําลองรุ่นแบบจําลองและคอลัมน์คุณลักษณะของคุณ
หมายเหตุ
การใช้ Spark SQL API เพื่อสร้างการคาดการณ์ยังคงต้องให้คุณสร้างออบเจ็กต์ MLFlowTransformer (ตามขั้นตอนที่ 3)
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
ทํานายด้วยฟังก์ชันที่ผู้ใช้กําหนดเอง
โค้ดต่อไปนี้จะเรียกใช้ฟังก์ชัน PREDICT ด้วย PySpark UDF หากคุณใช้แบบจําลอง ML ของคุณเองให้แทนที่ค่าสําหรับแบบจําลองและคุณลักษณะ
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
สร้างรหัสคาดการณ์จากหน้ารายการของแบบจําลอง ML
จากหน้ารายการของแบบจําลอง ML คุณสามารถเลือกหนึ่งในตัวเลือกต่อไปนี้เพื่อเริ่มสร้างการคาดการณ์ชุดงานสําหรับเวอร์ชันแบบจําลองเฉพาะด้วยการคาดการณ์
- ใช้ประสบการณ์ UI ที่แนะนําเพื่อสร้างรหัสการคาดการณ์
- คัดลอกเทมเพลตโค้ดลงในสมุดบันทึกและกําหนดค่าพารามิเตอร์ด้วยตัวคุณเอง
ใช้ประสบการณ์ UI ที่แนะนํา
ประสบการณ์ UI ที่แนะนําจะแนะนําคุณตามขั้นตอนเพื่อ:
- เลือกข้อมูลต้นทางสําหรับการให้คะแนน
- แมปข้อมูลอย่างถูกต้องกับข้อมูลป้อนเข้าของแบบจําลอง ML ของคุณ
- ระบุปลายทางสําหรับเอาต์พุตของแบบจําลองของคุณ
- สร้างสมุดบันทึกที่ใช้ PREDICT เพื่อสร้างและจัดเก็บผลลัพธ์การคาดการณ์
เพื่อใช้ประสบการณ์ที่มีผู้แนะแนวทาง
ไปที่หน้ารายการสําหรับเวอร์ชันแบบจําลอง ML ที่กําหนด
เลือก ใช้แบบจําลองนี้ในตัวช่วยสร้าง จากรายการ ดรอปดาวน์ใช้เวอร์ชัน นี้

การเลือกจะเปิดขึ้นหน้าต่าง "ใช้การคาดการณ์แบบจําลอง ML" ในขั้นตอน "เลือกตารางอินพุต"
เลือกตารางอินพุตจากเลคเฮ้าส์ในพื้นที่ทํางานปัจจุบันของคุณ

เลือก ถัดไป เพื่อไปที่ขั้นตอน "แมปคอลัมน์อินพุต"
แมปชื่อคอลัมน์จากตารางต้นทางไปยังเขตข้อมูลอินพุตของแบบจําลอง ML ซึ่งดึงมาจากลายเซ็นของแบบจําลอง คุณต้องระบุคอลัมน์อินพุตสําหรับเขตข้อมูลที่จําเป็นของแบบจําลองทั้งหมด นอกจากนี้ ชนิดข้อมูลสําหรับคอลัมน์ต้นทางต้องตรงกับชนิดข้อมูลที่คาดไว้ของแบบจําลอง
เคล็ดลับ
ตัวช่วยสร้างจะเติมข้อมูลการแมปนี้ถ้าชื่อของคอลัมน์ของตารางอินพุตตรงกับชื่อคอลัมน์ที่บันทึกในลายเซ็นแบบจําลอง ML
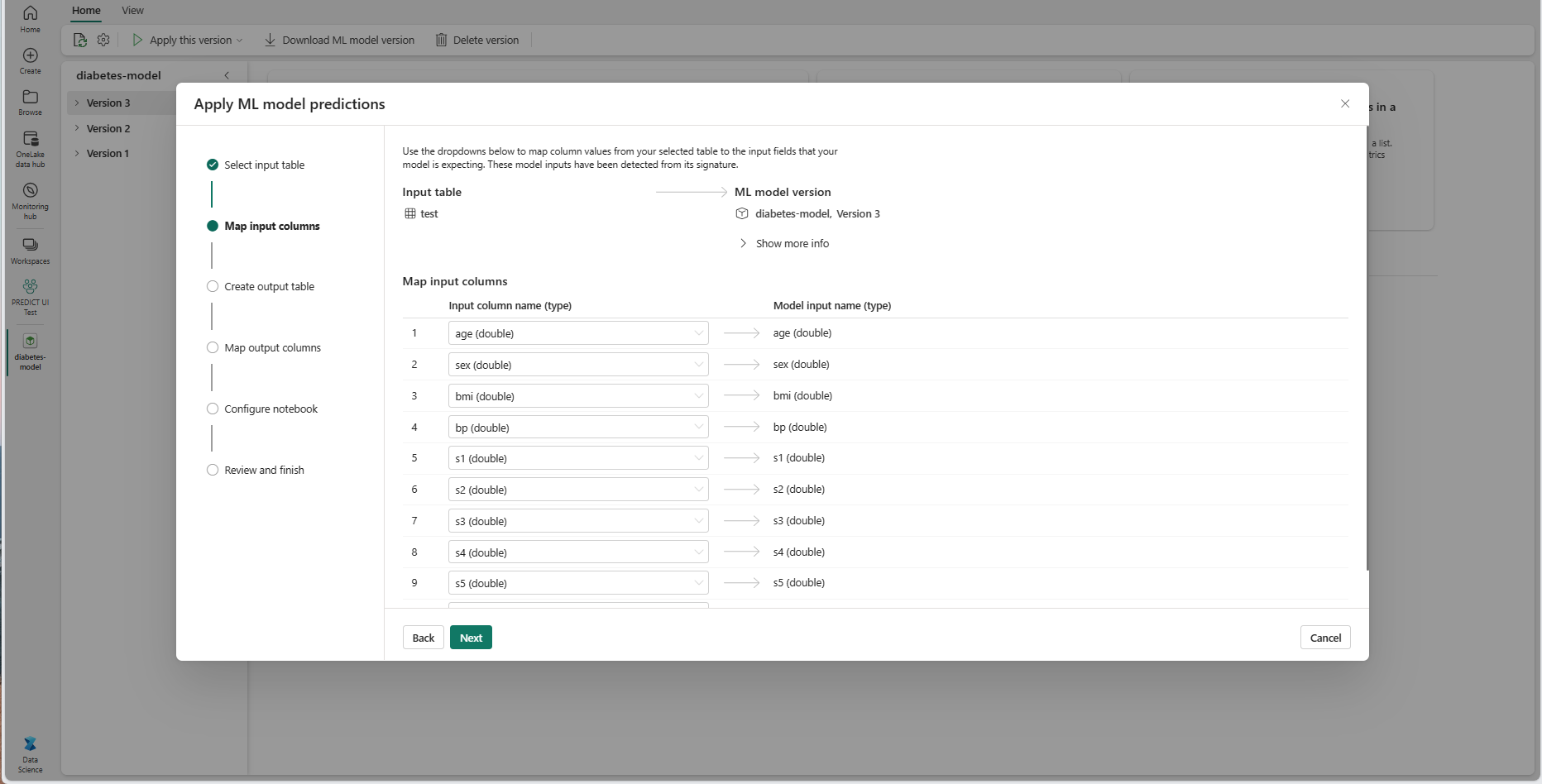
เลือก ถัดไป เพื่อไปที่ขั้นตอน "สร้างตารางผลลัพธ์"
ระบุชื่อตารางใหม่ภายในเลคเฮ้าส์ที่เลือกของพื้นที่ทํางานปัจจุบันของคุณ ตารางผลลัพธ์นี้จัดเก็บค่าอินพุตของแบบจําลอง ML ของคุณด้วยค่าการคาดการณ์ที่ผนวกอยู่ ตามค่าเริ่มต้น ตารางผลลัพธ์จะถูกสร้างขึ้นในเลคเฮ้าส์เดียวกันเป็นตารางข้อมูลป้อนเข้า แต่มีตัวเลือกในการเปลี่ยนบ้านทะเลสาบปลายทางให้ใช้งานด้วย

เลือก ถัดไป เพื่อไปที่ขั้นตอน "แมปคอลัมน์ผลลัพธ์"
ใช้เขตข้อมูลข้อความที่ระบุเพื่อตั้งชื่อคอลัมน์ในตารางผลลัพธ์ที่จัดเก็บการคาดการณ์ของแบบจําลอง ML

เลือก ถัดไป เพื่อไปขั้นตอน "กําหนดค่าสมุดบันทึก"
ระบุชื่อสําหรับสมุดบันทึกใหม่ที่จะเรียกใช้รหัส PREDICT ที่สร้างขึ้น ตัวช่วยสร้างแสดงตัวอย่างของโค้ดที่สร้างขึ้นในขั้นตอนนี้ คุณสามารถคัดลอกโค้ดไปยังคลิปบอร์ดของคุณและวางลงในสมุดบันทึกที่มีอยู่ได้ถ้าคุณต้องการ

เลือก ถัดไป เพื่อไปที่ขั้นตอน "ตรวจสอบและเสร็จสิ้น"
ตรวจทานรายละเอียดในหน้าสรุป และเลือก สร้างสมุดบันทึก เพื่อเพิ่มสมุดบันทึกใหม่ที่มีรหัสที่สร้างขึ้นไปยังพื้นที่ทํางานของคุณ คุณจะถูกนําไปยังสมุดบันทึกนั้นโดยตรง ซึ่งคุณสามารถเรียกใช้รหัสเพื่อสร้างและจัดเก็บการคาดการณ์ได้








ใช้เทมเพลตโค้ดที่สามารถกําหนดเองได้
หากต้องการใช้เทมเพลตโค้ดสําหรับการสร้างการคาดการณ์ชุดงาน:
- ไปที่หน้ารายการสําหรับเวอร์ชันแบบจําลอง ML ที่กําหนด
- เลือก คัดลอกรหัสที่จะใช้ จาก ดรอปดาวน์ใช้เวอร์ชัน นี้ การเลือกจะช่วยให้คุณสามารถคัดลอกเทมเพลตโค้ดที่ปรับแต่งได้
คุณสามารถวางเทมเพลตโค้ดนี้ลงในสมุดบันทึกเพื่อสร้างการคาดการณ์ชุดงานด้วยแบบจําลอง ML ของคุณ หากต้องการเรียกใช้เทมเพลตโค้ดให้เสร็จสมบูรณ์ คุณต้องแทนที่ค่าต่อไปนี้ด้วยตนเอง:
<INPUT_TABLE>: เส้นทางไฟล์สําหรับตารางที่มีการป้อนข้อมูลเข้าไปยังแบบจําลอง ML<INPUT_COLS>: อาร์เรย์ของชื่อคอลัมน์จากตารางอินพุตเพื่อป้อนค่าไปยังแบบจําลอง ML<OUTPUT_COLS>: ชื่อสําหรับคอลัมน์ใหม่ในตารางผลลัพธ์ที่จัดเก็บการคาดการณ์<MODEL_NAME>: ชื่อของแบบจําลอง ML ที่จะใช้สําหรับการสร้างการคาดการณ์<MODEL_VERSION>: เวอร์ชันของแบบจําลอง ML ที่จะใช้สําหรับการสร้างการคาดการณ์<OUTPUT_TABLE>: เส้นทางไฟล์สําหรับตารางที่จัดเก็บการคาดการณ์

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)