บทช่วยสอน: สร้าง ประเมิน และให้คะแนนแบบจําลองการตรวจหาข้อบกพร่องของเครื่อง
บทช่วยสอนนี้แสดงตัวอย่างแบบ end-to-end ของเวิร์กโฟลว์ Synapse Data Science ใน Microsoft Fabric สถานการณ์นี้ใช้การเรียนรู้ของเครื่องเพื่อเข้าถึงการวินิจฉัยข้อบกพร่องอย่างเป็นระบบมากขึ้น เพื่อระบุปัญหาเชิงรุกและเพื่อดําเนินการก่อนที่เครื่องจะล้มเหลวจริง เป้าหมายคือการคาดเดาว่าเครื่องจะประสบความล้มเหลวตามอุณหภูมิกระบวนการความเร็วในการหมุนเป็นต้น
บทช่วยสอนนี้ครอบคลุมขั้นตอนเหล่านี้:
- ติดตั้งไลบรารีแบบกําหนดเอง
- โหลดและประมวลผลข้อมูล
- ทําความเข้าใจข้อมูลผ่านการวิเคราะห์ข้อมูลเชิงสํารวจ
- ใช้ Scikit-learn, LightGBM และ MLflow เพื่อฝึกแบบจําลองการเรียนรู้ของเครื่อง และใช้คุณลักษณะ Fabric Autologging เพื่อติดตามการทดลอง
- ให้คะแนนแบบจําลองที่ได้รับการฝึกด้วยคุณลักษณะ Fabric
PREDICTบันทึกแบบจําลองที่ดีที่สุด และโหลดแบบจําลองดังกล่าวสําหรับการคาดการณ์ - แสดงประสิทธิภาพของแบบจําลองที่โหลดด้วยการแสดงภาพ Power BI
ข้อกำหนดเบื้องต้น
รับการสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนเพื่อทดลองใช้งาน Microsoft Fabric ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์ทางด้านซ้ายของโฮมเพจของคุณเพื่อสลับไปยังประสบการณ์วิทยาศาสตร์ข้อมูล Synapse

- หากจําเป็น ให้สร้าง Microsoft Fabric lakehouse ตามที่อธิบายไว้ใน สร้างเลคเฮ้าส์ใน Microsoft Fabric
ติดตามในสมุดบันทึก
คุณสามารถเลือกหนึ่งในตัวเลือกเหล่านี้เพื่อติดตามในสมุดบันทึกได้:
- เปิดและเรียกใช้สมุดบันทึกที่มีอยู่ภายในในประสบการณ์วิทยาศาสตร์ข้อมูล
- อัปโหลดสมุดบันทึกของคุณจาก GitHub ไปยังประสบการณ์ด้านวิทยาศาสตร์ข้อมูล
เปิดสมุดบันทึกที่มีอยู่แล้วภายใน
สมุดบันทึกความล้มเหลวของเครื่องตัวอย่างจะมาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกตัวอย่างที่มีอยู่แล้วภายในของบทช่วยสอนในประสบการณ์ Synapse Data Science:
ไปที่หน้าแรกของ Synapse Data Science
เลือก ใช้ตัวอย่าง
เลือกตัวอย่างที่สอดคล้องกัน:
- จากแท็บ เวิร์กโฟลว์แบบ End-to-end (Python) ตามค่าเริ่มต้น ถ้าตัวอย่างมีไว้สําหรับบทช่วยสอน Python
- จากแท็บ เวิร์กโฟลว์แบบครอบคลุม (R) ถ้าตัวอย่างมีไว้สําหรับบทช่วยสอน R
- จากแท็บ บทช่วยสอน ด่วน ถ้าตัวอย่างมีไว้สําหรับบทช่วยสอนด่วน
แนบเลคเฮ้าส์ลงในสมุดบันทึก ก่อนที่คุณจะเริ่มเรียกใช้โค้ด
นําเข้าสมุดบันทึกจาก GitHub
AISample - สมุดบันทึกการบํารุงรักษา เชิงคาดการณ์มาพร้อมกับบทช่วยสอนนี้
เมื่อต้องการเปิดสมุดบันทึกที่มาพร้อมกับบทช่วยสอนนี้ ให้ทําตามคําแนะนําใน เตรียมระบบของคุณสําหรับบทช่วยสอนวิทยาศาสตร์ข้อมูล เพื่อนําเข้าสมุดบันทึกไปยังพื้นที่ทํางานของคุณ
ถ้าคุณต้องการคัดลอกและวางรหัสจากหน้านี้แทน คุณสามารถสร้าง สมุดบันทึกใหม่ได้
ตรวจสอบให้แน่ใจว่าแนบ lakehouse เข้ากับสมุดบันทึก ก่อนที่คุณจะเริ่มเรียกใช้รหัส
ขั้นตอนที่ 1: ติดตั้งไลบรารีแบบกําหนดเอง
สําหรับการพัฒนาแบบจําลองการเรียนรู้ของเครื่องหรือการวิเคราะห์ข้อมูลเฉพาะกิจ คุณอาจจําเป็นต้องติดตั้งไลบรารีแบบกําหนดเองสําหรับเซสชัน Apache Spark ของคุณได้อย่างรวดเร็ว คุณมีสองตัวเลือกในการติดตั้งไลบรารี
- ใช้ความสามารถในการติดตั้งแบบอินไลน์ (
%pipหรือ%conda) ของสมุดบันทึกของคุณเพื่อติดตั้งไลบรารีในสมุดบันทึกปัจจุบันของคุณเท่านั้น - อีกวิธีหนึ่งคือ คุณสามารถสร้างสภาพแวดล้อม Fabric ติดตั้งไลบรารีจากแหล่งข้อมูลสาธารณะ หรืออัปโหลดไลบรารีแบบกําหนดเอง จากนั้นผู้ดูแลระบบพื้นที่ทํางานของคุณสามารถแนบสภาพแวดล้อมเป็นค่าเริ่มต้นสําหรับพื้นที่ทํางานได้ ไลบรารีทั้งหมดในสภาพแวดล้อมจะพร้อมใช้งานสําหรับใช้ในข้อกําหนดงานของสมุดบันทึกและ Spark ในพื้นที่ทํางาน สําหรับข้อมูลเพิ่มเติมเกี่ยวกับสภาพแวดล้อม ดูสร้าง กําหนดค่า และใช้สภาพแวดล้อมใน Microsoft Fabric
สําหรับบทช่วยสอนนี้ ใช้ %pip install เพื่อติดตั้ง imblearn ไลบรารีในสมุดบันทึกของคุณ
หมายเหตุ
เคอร์เนล PySpark เริ่มต้นใหม่หลังจาก %pip install เรียกใช้ ติดตั้งไลบรารีที่จําเป็นก่อนที่คุณจะเรียกใช้เซลล์อื่นๆ
# Use pip to install imblearn
%pip install imblearn
ขั้นตอนที่ 2: โหลดข้อมูล
ชุดข้อมูลจะจําลองการบันทึกพารามิเตอร์ของเครื่องผลิตเป็นฟังก์ชันของเวลาซึ่งเป็นเรื่องปกติในการตั้งค่าอุตสาหกรรม ซึ่งประกอบด้วยจุดข้อมูล 10,000 จุดที่จัดเก็บเป็นแถวที่มีคุณลักษณะเป็นคอลัมน์ คุณลักษณะประกอบด้วย:
ตัวระบุที่ไม่ซ้ํากัน (UID) ในช่วงตั้งแต่ 1 ถึง 10000
รหัสผลิตภัณฑ์ที่ประกอบด้วยตัวอักษร L (สําหรับระดับต่ํา), M (สําหรับสื่อ) หรือ H (สําหรับสูง) เพื่อระบุตัวแปรคุณภาพผลิตภัณฑ์และหมายเลขลําดับประจําสินค้าเฉพาะแบบตัวแปร ตัวแปรต่ํา ปานกลาง และมีคุณภาพสูงประกอบด้วย 60%, 30% และ 10% ของผลิตภัณฑ์ทั้งหมด ตามลําดับ
อุณหภูมิอากาศ, องศาเคลวิน (K)
อุณหภูมิกระบวนการ, ในองศาเคลวิน
ความเร็วในการหมุนตามรอบต่อนาที (RPM)
แรงบิดในนิวตัน-เมตร (นิวตัน-เมตร)
การสึกหรอของเครื่องมือ, ในไม่กี่นาที ตัวแปรคุณภาพ H, M และ L เพิ่ม 5, 3 และ 2 นาทีของการสึกหรอของเครื่องมือตามลําดับไปยังเครื่องมือที่ใช้ในกระบวนการ
ป้ายชื่อความล้มเหลวของเครื่องเพื่อระบุว่าเครื่องล้มเหลวในจุดข้อมูลเฉพาะหรือไม่ จุดข้อมูลเฉพาะนี้สามารถมีโหมดความล้มเหลวอิสระห้าโหมดต่อไปนี้:
- Tool Wear Failure (TWF): เครื่องมือจะถูกแทนที่หรือล้มเหลวในเวลาการสึกหรอของเครื่องมือแบบสุ่มระหว่าง 200 และ 240 นาที
- ความล้มเหลวในการกระจายความร้อน (HDF): การกระจายความร้อนทําให้เกิดความล้มเหลวของกระบวนการหากความแตกต่างระหว่างอุณหภูมิของอากาศและอุณหภูมิของกระบวนการน้อยกว่า 8.6 K และความเร็วในการหมุนของเครื่องมือน้อยกว่า 1380 RPM
- Power Failure (PWF): ผลิตภัณฑ์ของแรงบิดและความเร็วการหมุน (ในเรด/วินาที) เท่ากับพลังงานที่จําเป็นสําหรับกระบวนการ กระบวนการล้มเหลวหากพลังงานนี้ลดลงต่ํากว่า 3,500 W หรือเกิน 9,000 W
- ความล้มเหลวของ OverStrain (OSF): หากผลิตภัณฑ์ของการสึกหรอของเครื่องมือและแรงบิดเกิน 11,000 ต่ําสุด Nm สําหรับตัวแปรผลิตภัณฑ์ L (12,000 สําหรับ M, 13,000 สําหรับ H) กระบวนการจะล้มเหลวเนื่องจากการโอเวอร์สเตรน
- ความล้มเหลวแบบสุ่ม (RNF): แต่ละกระบวนการมีโอกาสล้มเหลว 0.1% โดยไม่คํานึงถึงพารามิเตอร์ของกระบวนการ
หมายเหตุ
ถ้าโหมดความล้มเหลวด้านบนอย่างน้อยหนึ่งโหมดเป็นจริง กระบวนการจะล้มเหลว และป้ายชื่อ "เครื่องล้มเหลว" ถูกตั้งค่าเป็น 1 วิธีการเรียนรู้ของเครื่องไม่สามารถระบุได้ว่าโหมดความล้มเหลวใดที่ทําให้กระบวนการล้มเหลว
ดาวน์โหลดชุดข้อมูลและอัปโหลดไปยัง lakehouse
เชื่อมต่อไปยังคอนเทนเนอร์ชุดข้อมูลเปิดของ Azure และโหลดชุดข้อมูลการบํารุงรักษาเชิงทํานาย รหัสนี้จะดาวน์โหลดเวอร์ชันสาธารณะของชุดข้อมูล และจากนั้นเก็บไว้ใน Fabric lakehouse:
สำคัญ
เพิ่มเลคเฮาส์ลงในสมุดบันทึกก่อนที่คุณจะเรียกใช้ มิฉะนั้น คุณจะได้รับข้อผิดพลาด สําหรับข้อมูลเกี่ยวกับการเพิ่มเลคเฮ้าส์ ดูเชื่อมต่อเลคเฮาส์และสมุดโน๊ต
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
หลังจากที่คุณดาวน์โหลดชุดข้อมูลลงใน lakehouse แล้ว คุณสามารถโหลดเป็น Spark DataFrame:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
ตารางนี้แสดงตัวอย่างของข้อมูล:
| UDI | รหัสผลิตภัณฑ์ | ขนิด | อุณหภูมิอากาศ [K] | อุณหภูมิกระบวนการ [K] | ความเร็วรอบการหมุน [รอบต่อนาที] | แรงบิด[นิวตัน-เมตร] | การสึกหรอของเครื่องมือ [นาที] | เป้าหมาย | ชนิดความล้มเหลว |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | ไม่มีความล้มเหลว |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | ไม่มีความล้มเหลว |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | ไม่มีความล้มเหลว |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | ไม่มีความล้มเหลว |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | ไม่มีความล้มเหลว |
เขียน Spark DataFrame ลงในตาราง delta ของเลคเฮ้าส์
จัดรูปแบบข้อมูล (ตัวอย่างเช่น แทนที่ช่องว่างด้วยขีดล่าง) เพื่ออํานวยความสะดวกในการดําเนินการ Spark ในขั้นตอนต่อไป:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
ตารางนี้แสดงตัวอย่างของข้อมูลที่มีชื่อคอลัมน์ที่จัดรูปแบบใหม่:
| UDI | Product_ID | ขนิด | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[นาที] | เป้าหมาย | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | ไม่มีความล้มเหลว |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | ไม่มีความล้มเหลว |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | ไม่มีความล้มเหลว |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | ไม่มีความล้มเหลว |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | ไม่มีความล้มเหลว |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
ขั้นตอนที่ 3: ประมวลผลข้อมูลล่วงหน้าและดําเนินการวิเคราะห์ข้อมูลเชิงสํารวจ
แปลง Spark DataFrame เป็น pandas DataFrame เพื่อใช้ไลบรารีการลงจุดยอดนิยมที่เข้ากันได้กับ Pandas
เคล็ดลับ
สําหรับชุดข้อมูลขนาดใหญ่ คุณอาจจําเป็นต้องโหลดส่วนหนึ่งของชุดข้อมูลนั้น
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
แปลงคอลัมน์เฉพาะของชุดข้อมูลเป็นชนิดเลขทศนิยมหรือจํานวนเต็มตามที่จําเป็น และแมปสตริง ('L', 'M', 'H') ให้เป็นค่าตัวเลข (0, 1, 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
สํารวจข้อมูลผ่านการแสดงภาพ
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
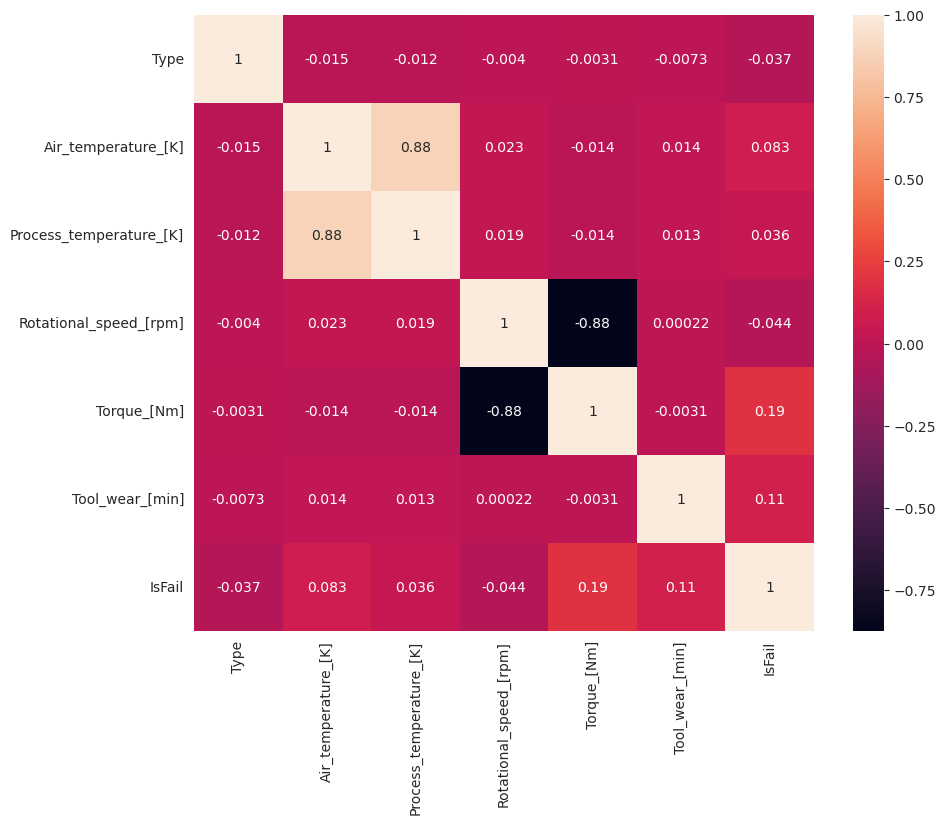
ตามที่คาดไว้ ความล้มเหลว (IsFail) สัมพันธ์กับคุณลักษณะ (คอลัมน์) ที่เลือก เมทริกซ์สหสัมพันธ์แสดงว่า Air_temperature, Process_temperature, Rotational_speed, Torque, และ Tool_wear มีความสัมพันธ์สูงสุดกับ IsFail ตัวแปร
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])

ดังที่กราฟที่ลงจุดแสดง Air_temperatureตัวแปร , Process_temperatureRotational_speed, Torque, และ Tool_wear จะไม่กระจัดกระจาย ดูเหมือนว่าพวกเขาจะมีความต่อเนื่องที่ดีในพื้นที่คุณลักษณะ พล็อตเหล่านี้ยืนยันว่าการฝึกแบบจําลองการเรียนรู้ของเครื่องบนชุดข้อมูลนี้น่าจะสร้างผลลัพธ์ที่เชื่อถือได้ซึ่งสามารถนําไปใช้กับชุดข้อมูลใหม่ได้ทั่วไป
ตรวจสอบตัวแปรเป้าหมายสําหรับความไม่สมดุลของคลาส
นับจํานวนของตัวอย่างสําหรับเครื่องที่ล้มเหลวและไม่ได้ผล และตรวจสอบความสมดุลของข้อมูลสําหรับแต่ละคลาส (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()

การลงจุดจะระบุว่าคลาสไม่มีความล้มเหลว (แสดงอยู่ใน IsFail=0 การลงจุดที่สอง) ประกอบด้วยตัวอย่างส่วนใหญ่ ใช้เทคนิคการสุ่มตัวอย่างมากเกินไปเพื่อสร้างชุดข้อมูลการฝึกที่สมดุลมากขึ้น:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
ตัวอย่างเกินความสมดุลของคลาสในชุดข้อมูลการฝึกอบรม
การวิเคราะห์ก่อนหน้านี้แสดงให้เห็นว่าชุดข้อมูลไม่สมดุลสูง ความไม่สมดุลนั้นกลายเป็นปัญหาเนื่องจากชั้นน้อยมีตัวอย่างน้อยเกินไปสําหรับแบบจําลองเพื่อเรียนรู้ขอบเขตการตัดสินใจอย่างมีประสิทธิภาพ
SMOTE สามารถแก้ปัญหาได้ SMOTE เป็นเทคนิคการสุ่มตัวอย่างที่ใช้กันอย่างกว้างขวางซึ่งสร้างตัวอย่างสังเคราะห์ ซึ่งสร้างตัวอย่างสําหรับระดับชั้นน้อยตามระยะห่างของยูคลิเดียนระหว่างจุดข้อมูล วิธีนี้แตกต่างจากการสุ่มตัวอย่างมากเกินไป เนื่องจากสร้างตัวอย่างใหม่ที่ไม่เพียงแต่ทําซ้ําคลาสรองเท่านั้น วิธีการนี้กลายเป็นเทคนิคที่มีประสิทธิภาพมากขึ้นในการจัดการชุดข้อมูลที่ไม่สมดุล
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
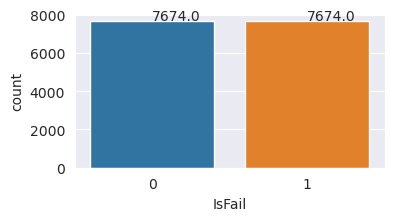
คุณปรับสมดุลชุดข้อมูลเรียบร้อยแล้ว คุณสามารถย้ายไปยังการฝึกแบบจําลองได้แล้ว
ขั้นตอนที่ 4: ฝึกและประเมินแบบจําลอง
MLflow ลงทะเบียนแบบจําลอง ฝึก และเปรียบเทียบแบบจําลองต่าง ๆ และเลือกแบบจําลองที่ดีที่สุดสําหรับวัตถุประสงค์การคาดการณ์ คุณสามารถใช้แบบจําลองสามแบบต่อไปนี้สําหรับการฝึกแบบจําลอง:
- ตัวจําแนกประเภทฟอเรสต์แบบสุ่ม
- ตัวจําแนกประเภทการถดถอยโลจิสติก
- ตัวจําแนกประเภท XGBoost
ฝึกตัวจําแนกประเภทฟอเรสต์แบบสุ่ม
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
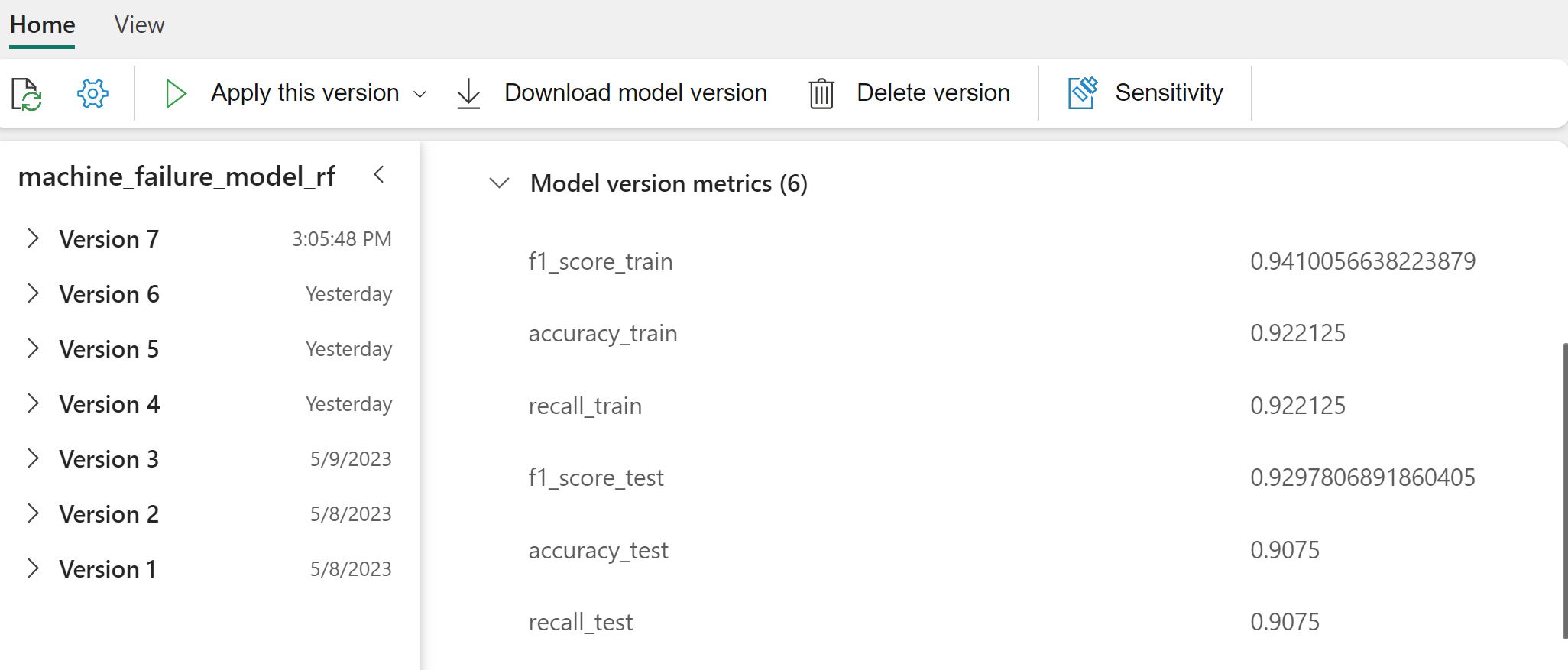
จากผลลัพธ์ ทั้งชุดข้อมูลการฝึกอบรมและการทดสอบจะให้คะแนน F1 ความแม่นยําและการเรียกใช้ประมาณ 0.9 เมื่อใช้ตัวจําแนกประเภทป่าแบบสุ่ม
ฝึกตัวจําแนกประเภทการถดถอยโลจิสติกส์
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
ฝึกตัวจําแนกประเภท XGBoost
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
ขั้นตอนที่ 5: เลือกแบบจําลองที่ดีที่สุดและคาดการณ์เอาต์พุต
ในส่วนก่อนหน้านี้ คุณได้ฝึกตัวจําแนกประเภทที่แตกต่างกันสามตัว: ฟอเรสต์แบบสุ่ม การถดถอยโลจิสติกส์ และ XGBoost ตอนนี้คุณมีตัวเลือกในการเข้าถึงผลลัพธ์ทางโปรแกรมหรือใช้ส่วนติดต่อผู้ใช้ (UI)
สําหรับตัวเลือก เส้นทาง UI ให้นําทางไปยังพื้นที่ทํางานของคุณและกรองแบบจําลอง
เลือกแต่ละแบบจําลองสําหรับรายละเอียดของประสิทธิภาพของแบบจําลอง
ตัวอย่างนี้แสดงวิธีการเข้าถึงแบบจําลองผ่าน MLflow ทางโปรแกรม:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
แม้ว่า XGBoost จะให้ผลลัพธ์ที่ดีที่สุดสําหรับชุดการฝึก แต่จะทํางานได้ไม่ดีในชุดข้อมูลทดสอบ ประสิทธิภาพที่ไม่ดีแสดงว่ามีการติดตั้งมากเกินไป ตัวจําแนกประเภทการถดถอยโลจิสติกส์ดําเนินการได้ไม่ดีทั้งในการฝึกอบรมและการทดสอบชุดข้อมูล โดยรวมแล้วป่าแบบสุ่มมีความสมดุลที่ดีระหว่างประสิทธิภาพการฝึกอบรมและการหลีกเลี่ยงการมากเกินไป
ในส่วนถัดไป เลือกแบบจําลองฟอเรสต์แบบสุ่มที่ลงทะเบียนและดําเนินการคาดการณ์ด้วย คุณลักษณะ PREDICT :
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
MLFlowTransformerด้วยวัตถุที่คุณสร้างขึ้นเพื่อโหลดแบบจําลองสําหรับการอนุมาน ให้ใช้ Transformer API เพื่อให้คะแนนแบบจําลองบนชุดข้อมูลทดสอบ:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
ตารางนี้แสดงเอาต์พุต:
| ขนิด | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[นาที] | คาด คะเน |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36.8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24.0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80.0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26.0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48.0 | 9.0 | 0 |
บันทึกข้อมูลลงในเลคเฮ้าส์ ข้อมูลจะพร้อมใช้งานสําหรับการใช้งานในภายหลัง - ตัวอย่างเช่น แดชบอร์ด Power BI
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
ขั้นตอนที่ 6: ดูข่าวกรองธุรกิจผ่านการแสดงภาพใน Power BI
แสดงผลลัพธ์ในรูปแบบออฟไลน์ด้วยแดชบอร์ด Power BI
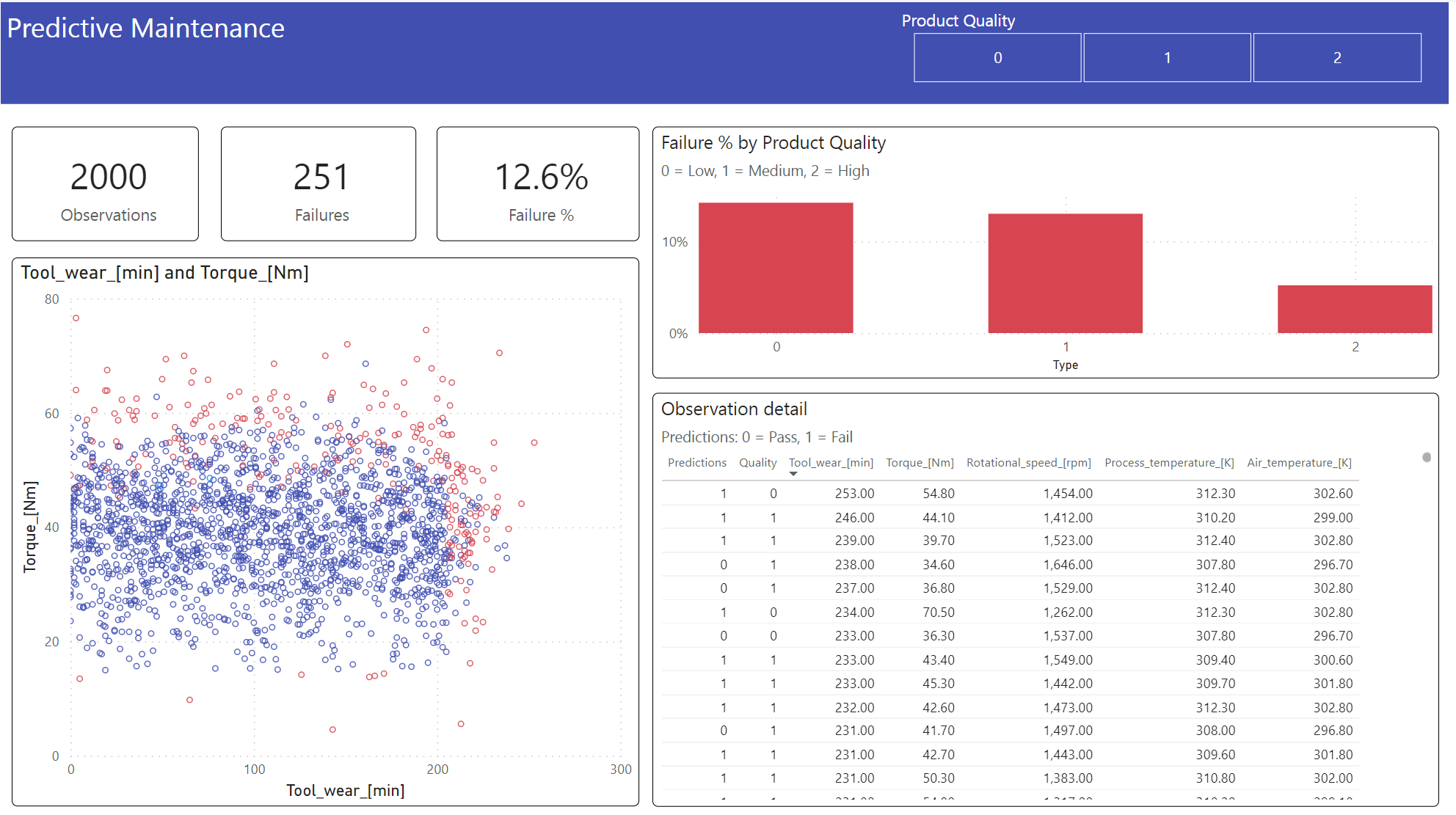
แดชบอร์ดแสดงให้เห็นว่า Tool_wear และ Torque สร้างขอบเขตที่เห็นได้ชัดระหว่างกรณีที่ล้มเหลวและไม่ได้ผล ตามที่คาดไว้จากการวิเคราะห์ความสัมพันธ์ก่อนหน้านี้ในขั้นตอนที่ 2