Model doğruluğunu yorumlama ve geliştirme ve güvenilirlik puanlarını analiz etme
Güvenilirlik puanı, elde edilen sonucun doğru algılandığı istatistiksel kesinlik derecesini ölçerek olasılığı gösterir. Tahmini doğruluk, etiketlenmiş değerleri tahmin etmek için eğitim verilerinin birkaç farklı bileşimi çalıştırılarak hesaplanır. Bu makalede doğruluk ve güvenilirlik puanlarını yorumlamayı ve doğruluk ve güvenilirlik sonuçlarını geliştirmek için bu puanları kullanmaya yönelik en iyi yöntemleri öğrenin.
Güvenilirlik puanları
Not
- Alan düzeyinde güvenilirlik, özel modeller için 2024-07-31-preview API sürümünden başlayarak sözcük güven puanının hesaba katmak üzere güncelleştirmeyi alıyor.
- Tablolar, tablo satırları ve tablo hücreleri için güvenilirlik puanları, özel modeller için 2024-07-31-preview API sürümünden itibaren kullanılabilir.
Belge Zekası çözümleme sonuçları tahmin edilen sözcükler, anahtar-değer çiftleri, seçim işaretleri, bölgeler ve imzalar için tahmini bir güvenilirlik döndürür. Şu anda tüm belge alanları güvenilirlik puanı döndürmez.
Alan güvenilirliği, tahminin doğru olduğunu 0 ile 1 arasında bir tahmini olasılığı gösterir. Örneğin, 0,95 (%95) güvenilirlik değeri, tahminin 20 defadan 19'unun doğru olduğunu gösterir. Doğruluğun kritik olduğu senaryolarda, tahminin otomatik olarak kabul edilip edilmeyeceğini veya insan incelemesi için bayrak eklenip işaretlenmeyeceğini belirlemek için güvenilirlik kullanılabilir.
Belge Intelligence Studio
Önceden oluşturulmuş fatura modelini analiz etti
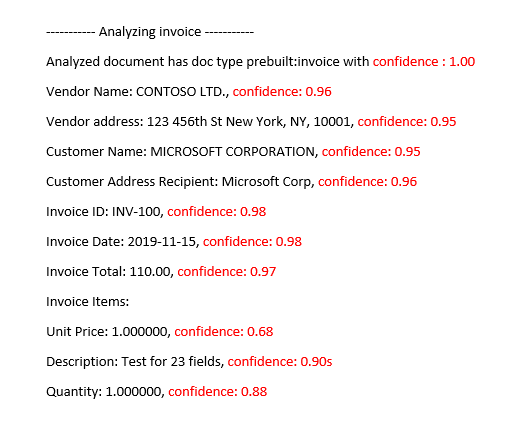
Güvenilirlik puanlarını geliştirme
Analiz işleminden sonra JSON çıkışını gözden geçirin. Düğümün confidence altındaki her anahtar/değer sonucunun pageResults değerlerini inceleyin. Ayrıca, metin okuma işlemine karşılık gelen düğümdeki readResults güvenilirlik puanına da bakmalısınız. Okuma sonuçlarının güvenilirliği anahtar/değer ayıklama sonuçlarının güvenilirliğini etkilemez, bu nedenle her ikisini de denetlemeniz gerekir. Bazı ipuçları şunlardır:
Nesnenin
readResultsgüvenilirlik puanı düşükse, giriş belgelerinizin kalitesini artırın.Nesnenin
pageResultsgüvenilirlik puanı düşükse, analiz ettiğiniz belgelerin aynı türde olduğundan emin olun.İş akışlarınıza insan incelemesi eklemeyi göz önünde bulundurun.
Her alanda farklı değerlere sahip formları kullanın.
Özel modeller için daha büyük bir eğitim belgesi kümesi kullanın. Daha büyük bir eğitim kümesi, modelinize alanları daha yüksek doğrulukla tanımayı öğretir.
Özel modeller için doğruluk puanları
Not
- Özel sinirsel ve üretken modeller eğitim sırasında doğruluk puanları sağlamaz.
(v3.0 ve ileri) veya train (v2.1) özel model işleminin çıkışı build tahmini doğruluk puanını içerir. Bu puan, modelin görsel olarak benzer bir belgedeki etiketlenmiş değeri doğru tahmin etme özelliğini temsil eder. Doğruluk, %0 (düşük) ile %100 (yüksek) arasında bir yüzde değeri aralığında ölçülür. En iyisi %80 veya daha yüksek bir puan hedeflemektir. Finansal veya tıbbi kayıtlar gibi daha hassas vakalar için %100'e yakın bir puan öneririz. Daha kritik otomasyon iş akışlarını doğrulamak için bir insan inceleme aşaması da ekleyebilirsiniz.
Document Intelligence Studio
Eğitilen özel model (fatura)

Özel modeller için doğruluk ve güvenilirlik puanlarını yorumlama
Özel şablon modelleri eğitildiğinde tahmini doğruluk puanı oluşturur. Özel modelle analiz edilen belgelerde ayıklanan alanlar için güvenilirlik puanı belirlenir. Özel bir modelden güvenilirlik puanını yorumlarken modelden döndürülen tüm güvenilirlik puanlarını dikkate almanız gerekir. Tüm güvenilirlik puanlarının listesiyle başlayalım.
- Belge türü güvenilirlik puanı: Belge türü güvenilirliği, analiz edilen belgenin eğitim veri kümesindeki belgelere benzediğini gösteren bir göstergedir. Belge türü güvenilirliği düşük olduğunda, çözümlenen belgedeki şablon veya yapısal varyasyonları gösterir. Belge türü güvenilirliğini artırmak için, belgeyi belirli bir çeşitlemeyle etiketleyip eğitim veri kümenize ekleyin. Model yeniden eğitildikten sonra, bu çeşitleme sınıfını işlemek için daha iyi bir donanıma sahip olmalıdır.
- Alan düzeyinde güvenilirlik: Ayıklanan etiketli her alanın ilişkili bir güvenilirlik puanı vardır. Bu puan, modelin ayıklanan değerin konumuna olan güvenini yansıtır. Güvenilirlik puanlarını değerlendirirken, ayıklanan sonuç için kapsamlı bir güven oluşturmak için temel alınan ayıklama güvenilirliğine de bakmanız gerekir.
OCRAlan için bileşik güvenilirlik puanı oluşturmak üzere alan türüne bağlı olarak metin ayıklama veya seçim işaretlerinin sonuçlarını değerlendirin. - Sözcük güvenilirlik puanı Belge içinde ayıklanan her sözcüğün ilişkili güvenilirlik puanı vardır. Puan, transkripsiyonun güvenilirliğini temsil eder. Pages dizisi bir sözcük dizisi içerir ve her sözcüğün ilişkili bir yayılma alanı ve güvenilirlik puanı vardır. Özel alandan ayıklanan değerlerdeki yayılma alanları, ayıklanan sözcüklerin yayılma alanlarıyla eşleşmektedir.
- Seçim işareti güvenilirlik puanı: Sayfalar dizisi bir dizi seçim işareti de içerir. Her seçim işaretinin, seçim işaretinin güvenilirliğini ve seçim durumu algılamasını temsil eden bir güvenilirlik puanı vardır. Etiketli bir alanda seçim işareti olduğunda, özel alan seçimi seçim işareti güveni ile birlikte genel güvenilirlik doğruluğunun doğru bir gösterimidir.
Aşağıdaki tabloda, özel modelinizin performansını ölçmek için hem doğruluk hem de güvenilirlik puanlarının nasıl yorumlanıp yorumlanamları gösterilmektedir.
| Doğruluk | Güven | Sonuç |
|---|---|---|
| Yüksek | Yüksek | • Model etiketli anahtarlar ve belge biçimleriyle iyi performans gösteriyor. • Dengeli bir eğitim veri kümeniz var. |
| Yüksek | Düşük | • Analiz edilen belge eğitim veri kümesinden farklı görünür. • Model, en az beş etiketli belge daha ile yeniden eğitme avantajından yararlanabilir. • Bu sonuçlar, eğitim veri kümesi ile analiz edilen belge arasında bir biçim varyasyonu olduğunu da gösterebilir. Yeni bir model eklemeyi göz önünde bulundurun. |
| Düşük | Yüksek | • Bu sonuç pek olası değildir. • Düşük doğruluk puanları için daha fazla etiketli veri ekleyin veya görsel olarak ayrı belgeleri birden çok modele bölün. |
| Düşük | Düşük | • Daha fazla etiketli veri ekleyin. • Görsel olarak ayrı belgeleri birden çok modele bölün. |
Özel modeller için yüksek model doğruluğundan emin olun
Belgelerinizin görsel yapısındaki farklar modelinizin doğruluğunu etkiler. Analiz edilen belgeler eğitimde kullanılan belgelerden farklı olduğunda bildirilen doğruluk puanları tutarsız olabilir. Bir belge kümesi insanlara benzer görünürken yapay zeka modeline farklı görünebilir. Takip etmek gerekirse, en yüksek doğrulukta eğitim modellerine yönelik en iyi yöntemlerin listesidir. Bu yönergelerin takip edilmesi, analiz sırasında daha yüksek doğruluk ve güvenilirlik puanlarına sahip bir model üretmeli ve insan incelemesi için bayrak eklenmiş belge sayısını azaltmalıdır.
Bir belgenin tüm çeşitlemelerinin eğitim veri kümesine dahil olduğundan emin olun. Çeşitlemeler, dijital ve taranmış PDF’ler gibi farklı biçimler içerir.
Modelin her iki pdf belgesi türünü de analiz etmesini bekliyorsanız eğitim veri kümesine her türden en az beş örnek ekleyin.
Özel şablon ve sinir modelleri için farklı modelleri eğitmek için görsel olarak ayrı belge türlerini ayırın.
- Genel bir kural olarak, kullanıcı tarafından girilen tüm değerleri kaldırırsanız ve belgeler benzer görünürse, mevcut modele daha fazla eğitim verisi eklemeniz gerekir.
- Belgeler farklıysa eğitim verilerinizi farklı klasörlere bölün ve her çeşitleme için bir model eğitin. Ardından farklı varyasyonları tek bir modelde birleştirebilirsiniz.
Fazla etiket olmadığından emin olun.
İmza ve bölge etiketlemesinin çevresindeki metni içermediğinden emin olun.
Tablo, satır ve hücre güvenilirliği
API ve ileriye doğru tablo, satır ve hücre güvenilirliğinin eklenmesiyle 2024-02-29-preview birlikte, tablo, satır ve hücre puanlarını yorumlamaya yardımcı olması gereken bazı yaygın sorular şunlardır:
S: Hücreler için yüksek güvenilirlik puanı, ancak satır için düşük güvenilirlik puanı görmek mümkün mü?
Y: Evet. Tablo güvenilirliğinin farklı düzeyleri (hücre, satır ve tablo) bir tahminin doğruluğunu belirli bir düzeyde yakalamaya yöneliktir. Diğer olası eksikleri olan bir satıra ait doğru tahmin edilen hücre yüksek hücre güvenilirliğine sahip olabilir, ancak satırın güvenilirliği düşük olmalıdır. Benzer şekilde, tablodaki diğer satırlarla ilgili güçlükler içeren doğru bir satır yüksek satır güvenilirliğine sahip olurken, tablonun genel güvenilirliği düşük olacaktır.
S: Hücreler birleştirildiğinde beklenen güvenilirlik puanı nedir? Birleştirme işlemi, değiştirilecek şekilde tanımlanan sütun sayısıyla sonuçlandığından puanlar nasıl etkilenir?
Y: Tablonun türünden bağımsız olarak, birleştirilmiş hücrelere yönelik beklenti, daha düşük güvenilirlik değerlerine sahip olmalarıdır. Ayrıca, eksik olan hücrenin (bitişik bir hücreyle birleştirildiği için) değeri de daha düşük güvene sahip NULL olmalıdır. Bu değerlerin ne kadar daha düşük olabileceği eğitim veri kümesine bağlıdır. Hem birleştirilmiş hem de düşük puana sahip eksik hücrenin genel eğilimi tutulmalıdır.
S: Bir değer isteğe bağlı olduğunda güvenilirlik puanı nedir? Değer eksikse, değeri ve yüksek güvenilirlik puanı olan bir NULL hücreyi beklemeniz gerekir mi?
Y: Eğitim veri kümeniz hücrelerin isteğe bağlılığını temsil ediyorsa modelin bir değerin eğitim kümesinde ne sıklıkta görünme eğiliminde olduğunu ve dolayısıyla çıkarım sırasında ne bekleyebileceğinizi bilmesine yardımcı olur. Bu özellik, bir tahminin güvenilirliğini veya hiç tahminde bulunmama (NULL) işleminin güvenilirliğini hesaplarken kullanılır. Eğitim kümesinde çoğunlukla boş olan eksik değerler için yüksek güvene sahip boş bir alan bekleyebilirsiniz.
S: Bir alan isteğe bağlıysa ve mevcut değilse veya eksikse güvenilirlik puanları nasıl etkilenir? Güvenilirlik puanının bu soruya yanıt verdiği beklentisi mi var?
Y: Bir satırda değer eksik olduğunda, hücreye bir NULL değer ve güvenilirlik atanır. Burada yüksek güvenilirlik puanı, model tahmininin (değer olmaması) doğru olma olasılığının daha yüksek olduğu anlamına gelmelidir. Buna karşılık, düşük bir puan modelden daha fazla belirsizlik sinyali vermelidir (ve bu nedenle değerin kaçırılması gibi bir hata olasılığı).
S: Sayfalar arasında bölünmüş bir satır içeren çok sayfalı bir tablo ayıklanırken hücre güvenilirliği ve satır güveni beklentisi ne olmalıdır?
Y: Hücre güvenilirliğinin yüksek, satır güvenilirliğinin ise bölünmeyen satırlardan daha düşük olması beklenebilir. Eğitim veri kümesindeki bölünmüş satırların oranı güvenilirlik puanını etkileyebilir. Genel olarak, bölünmüş satır tablodaki diğer satırlardan farklı görünür (bu nedenle model doğru olduğundan daha az emin olur).
S: Düzgün bir şekilde biten ve sayfa sınırlarında başlayan satırlara sahip çapraz sayfa tabloları için, güvenilirlik puanlarının sayfalar arasında tutarlı olduğunu varsaymak doğru mudur?
Y: Evet. Satırlar, belgenin neresinde (veya hangi sayfada) olduklarından bağımsız olarak şekil ve içerik olarak benzer göründüğünden, ilgili güvenilirlik puanları tutarlı olmalıdır.
S: Yeni güvenilirlik puanlarını kullanmanın en iyi yolu nedir?
Y: Yukarıdan aşağıya bir yaklaşımla başlayan tüm tablo güvenilirliği düzeylerine bakın: Tablonun bütün olarak güvenilirliğini denetleyerek başlayın, ardından satır düzeyine gidin ve tek tek satırlara bakın, son olarak hücre düzeyinde güvenlere bakın. Tablonun türüne bağlı olarak, birkaç nokta vardır:
Sabit tablolar için hücre düzeyinde güvenilirlik, nesnelerin doğruluğu hakkında zaten oldukça fazla bilgi yakalar. Bu, her hücrenin üzerinden geçmek ve güvenine bakmak, tahminin kalitesini belirlemeye yardımcı olmak için yeterli olabileceği anlamına gelir. Dinamik tablolar için düzeylerin üst üste oluşturulması amaçlandığından yukarıdan aşağıya yaklaşım daha önemlidir.