Azure AI Belge Zekası ile Alma Artırılmış Nesil
Bu içerik şunlar için geçerlidir: ![]() v4.0 (önizleme)
v4.0 (önizleme)
Giriş
Alma Artırılmış Nesil (RAG), ChatGPT gibi önceden eğitilmiş bir Büyük Dil Modelini (LLM) dış veri alma sistemiyle birleştirerek özgün eğitim verilerinin dışında yeni verileri birleştiren gelişmiş bir yanıt oluşturan bir tasarım desenidir. Uygulamalarınıza bilgi alma sistemi ekleyerek belgelerinizle sohbet edebilir, büyüleyici içerik oluşturabilir ve verileriniz için Azure OpenAI modellerinin gücüne erişebilirsiniz. Ayrıca, LLM tarafından bir yanıt formüle ettiği için kullanılan veriler üzerinde daha fazla denetime sahip olursunuz.
Belge Yönetim Bilgileri Düzeni modeli , gelişmiş bir makine öğrenmesi tabanlı belge analizi API'sidir. Düzen modeli, gelişmiş içerik ayıklama ve belge yapısı analizi özellikleri için kapsamlı bir çözüm sunar. Düzen modeliyle, büyük metin gövdelerini rastgele bölmeler yerine anlamsal içeriğe göre daha küçük, anlamlı öbeklere bölmek için metni ve yapısal öğeleri kolayca ayıklayabilirsiniz. Ayıklanan bilgiler Markdown biçimine kolayca çıkarılabilir ve sağlanan yapı taşları temelinde anlamsal öbekleme stratejinizi tanımlamanızı sağlar.
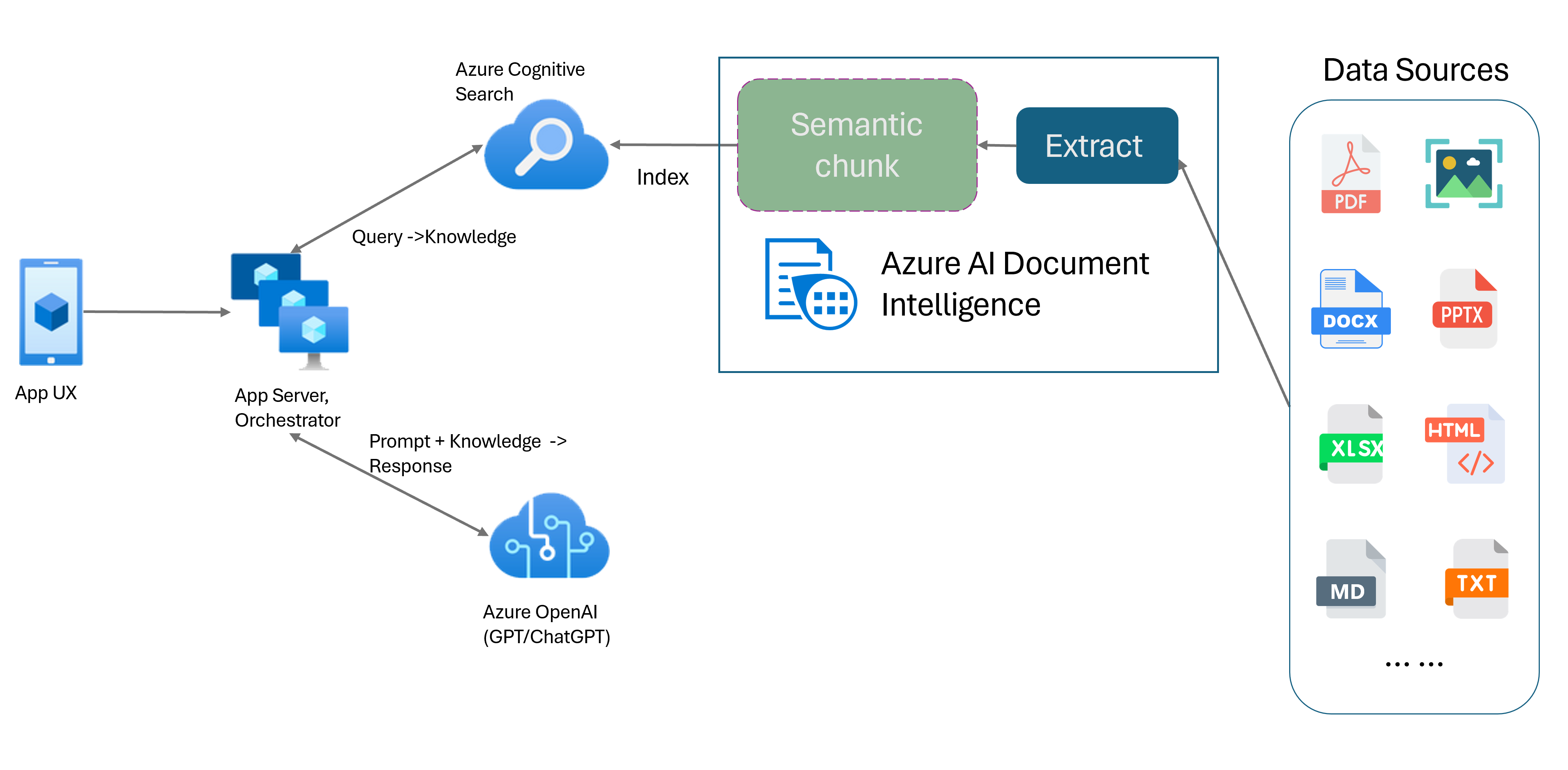
Anlamsal öbekleme
Doğal dil işleme (NLP) uygulamaları için uzun cümleler zorlayıcıdır. Özellikle birden çok yan tümceden, karmaşık isim veya fiil tümceciklerinden, göreli yan tümcelerden ve parantez içinde gruplandırmalardan oluştuğunda. Aynı insan sahibi gibi bir NLP sisteminin de sunulan tüm bağımlılıkları başarıyla izlemesi gerekir. Anlamsal öbeklemenin amacı, bir cümle gösteriminin semantik olarak tutarlı parçalarını bulmaktır. Bu parçalar daha sonra bağımsız olarak işlenebilir ve bilgi, yorumlama veya anlamsal ilgi kaybı olmadan anlamsal gösterimler olarak yeniden birleştirilebilir. Metnin doğal anlamı, öbekleme işlemi için bir kılavuz olarak kullanılır.
Metin verileri öbekleme stratejileri, RAG yanıtını ve performansını iyileştirmede önemli bir rol oynar. Sabit boyutlu ve anlamsal iki ayrı öbekleme yöntemidir:
Sabit boyutlu öbekleme. Günümüzde RAG'de kullanılan öbekleme stratejilerinin çoğu, öbek olarak bilinen sabit boyutlu metin kesimlerini temel alır. Sabit boyutlu öbekler, günlükler ve veriler gibi güçlü bir anlam yapısına sahip olmayan metinlerle hızlı, kolay ve etkilidir. Ancak anlamsal anlama ve kesin bağlam gerektiren metinler için önerilmez. Pencerenin sabit boyutlu yapısı, sözcüklerin, cümlelerin veya paragrafların kesilmesine, kavramanın engellenmesine ve bilgi ve anlama akışının kesintiye uğramasına neden olabilir.
Anlamsal öbekleme. Bu yöntem, semantik anlayışa göre metni öbeklere böler. Bölme sınırları tümce konusuna odaklanır ve önemli hesaplama algoritmaları karmaşık kaynaklar kullanır. Ancak, her öbek içinde semantik tutarlılığı korumanın ayrı bir avantajı vardır. Metin özetleme, yaklaşım analizi ve belge sınıflandırma görevleri için kullanışlıdır.
Belge Yönetim Bilgileri Düzeni modeliyle anlamsal öbekleme
Markdown, YAPıLANDıRıLMıŞ ve biçimlendirilmiş bir işaretleme dilidir ve RAG'de semantik öbek oluşturmayı etkinleştirmek için popüler bir giriştir (Alma-Artırılmış Oluşturma). Düzen modelindeki Markdown içeriğini kullanarak belgeleri paragraf sınırlarına göre bölebilir, tablolar için belirli öbekler oluşturabilir ve oluşturulan yanıtların kalitesini artırmak için öbekleme stratejinize ince ayar yapabilirsiniz.
Düzen modelini kullanmanın avantajları
Basitleştirilmiş işleme. Dijital ve taranmış PDF'ler, resimler, office dosyaları (docx, xlsx, pptx) ve HTML gibi farklı belge türlerini tek bir API çağrısıyla ayrıştırabilirsiniz.
Ölçeklenebilirlik ve yapay zeka kalitesi. Düzen modeli Optik Karakter Tanıma (OCR), tablo ayıklama ve belge yapısı analizinde yüksek oranda ölçeklenebilir. 309 basılı ve 12 el yazısı dili destekler ve yapay zeka özellikleriyle yüksek kaliteli sonuçlar elde edilmesini sağlar.
Büyük dil modeli (LLM) uyumluluğu. Markdown biçimli Düzen modeli çıkışı LLM dostudur ve iş akışlarınıza sorunsuz tümleştirmeyi kolaylaştırır. Belgedeki herhangi bir tabloyu Markdown biçimine dönüştürebilir ve daha iyi LLM anlamak için belgeleri ayrıştırma çabasından kaçınabilirsiniz.
Document Intelligence Studio ile işlenen metin görüntüsü ve Düzen modeli kullanılarak MarkDown çıktısı

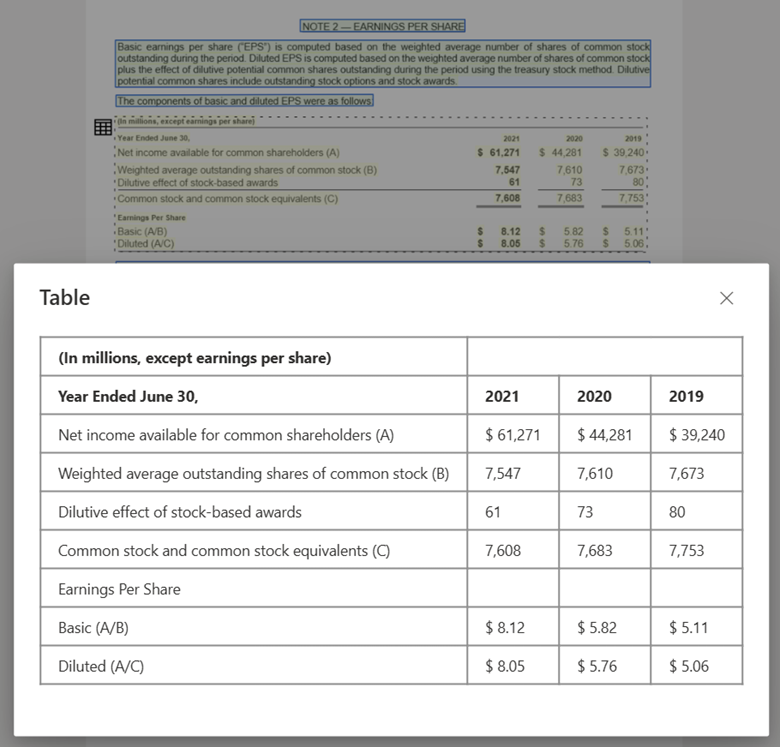
Düzen modeli kullanılarak Document Intelligence Studio ile işlenen tablo görüntüsü
Kullanmaya başlayın
Belge Yönetim Bilgileri Düzeni modeli 2024-07-31-preview ve 2023-10-31-preview aşağıdaki geliştirme seçeneklerini destekler:
Başlamaya hazır mısınız?
Belge Makine Zekası Stüdyosu
Başlamak için Document Intelligence Studio hızlı başlangıcını izleyebilirsiniz. Ardından, sağlanan örnek kodu kullanarak Belge Zekası özelliklerini kendi uygulamanızla tümleştirebilirsiniz.
Düzen modeliyle başlayın. Stüdyoda RAG kullanmak için aşağıdaki Çözümle seçeneklerini belirlemeniz gerekir:
**Required**- Geçerli belge → çözümleme aralığını çalıştırın.
- Tüm sayfalar → sayfa aralığı.
- Markdown'→ çıkış biçimi stili.
**Optional**- ayrıca ilgili isteğe bağlı algılama parametrelerini de seçebilirsiniz.
Kaydet'i seçin.
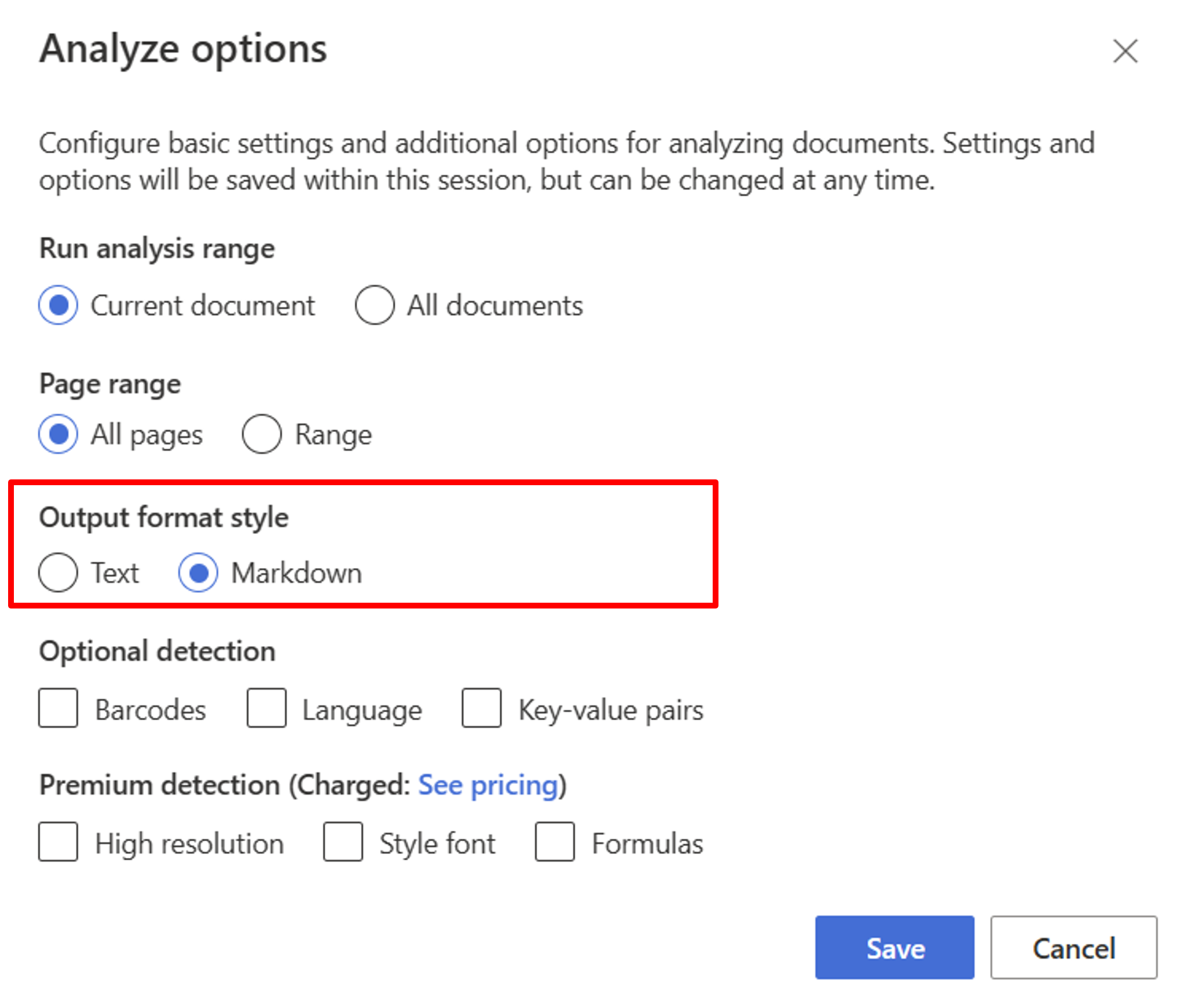
Çıkışı görüntülemek için Analizi çalıştır düğmesini seçin.

SDK veya REST API
Tercih ettiğiniz programlama dili SDK'sı veya REST API için Belge Zekası hızlı başlangıcını izleyebilirsiniz. Belgelerinizden içerik ve yapı ayıklamak için Düzen modelini kullanın.
Ayrıca, markdown çıkış biçiminde bir belgeyi analiz etmek için kod örnekleri ve ipuçları için GitHub depolarına göz atabilirsiniz.
Anlamsal öbekleme ile belge sohbeti oluşturma
Verilerinizde Azure OpenAI, belgelerinizde desteklenen sohbeti çalıştırmanıza olanak tanır. Verilerinizde Azure OpenAI, tablo ve paragraflara göre uzun metinleri öbekleyerek belge verilerini ayıklamak ve ayrıştırmak için Belge Yönetim Bilgileri Düzeni modelini uygular. Ayrıca, GitHub depomuzda bulunan Azure OpenAI örnek betiklerini kullanarak öbekleme stratejinizi özelleştirebilirsiniz.
Azure AI Belge Zekası artık belge yükleyicilerinden biri olarak LangChain ile tümleştirilmiştir. Verileri ve çıkışı Markdown biçimine kolayca yüklemek için kullanabilirsiniz. Daha fazla bilgi için belge yükleyici olarak Azure AI Document Intelligence ve LangChain'de getr olarak Azure Search ile RAG deseni için basit bir tanıtım gösteren örnek kodumuza bakın.
Veri çözümü hızlandırıcı kod örneğinizle sohbette uçtan uca temel RAG desen örneği gösterilir. Belge yükleme ve semantik öbekleme için Azure AI Search'i bir retriever olarak ve Azure AI Document Intelligence'ı kullanır.
Kullanım örneği
Belgede belirli bir bölüm arıyorsanız, aradığınız bölümü hızlı ve kolay bir şekilde bulmanıza yardımcı olan bölüm üst bilgilerine dayalı olarak belgeyi daha küçük öbeklere bölmek için anlamsal öbekleme kullanabilirsiniz:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Sonraki adımlar
Azure AI Belge Zekası hakkında daha fazla bilgi edinin.
Document Intelligence Studio ile kendi formlarınızı ve belgelerinizi işlemeyi öğrenin.
Belge Zekası hızlı başlangıcını tamamlayın ve seçtiğiniz geliştirme dilinde bir belge işleme uygulaması oluşturmaya başlayın.