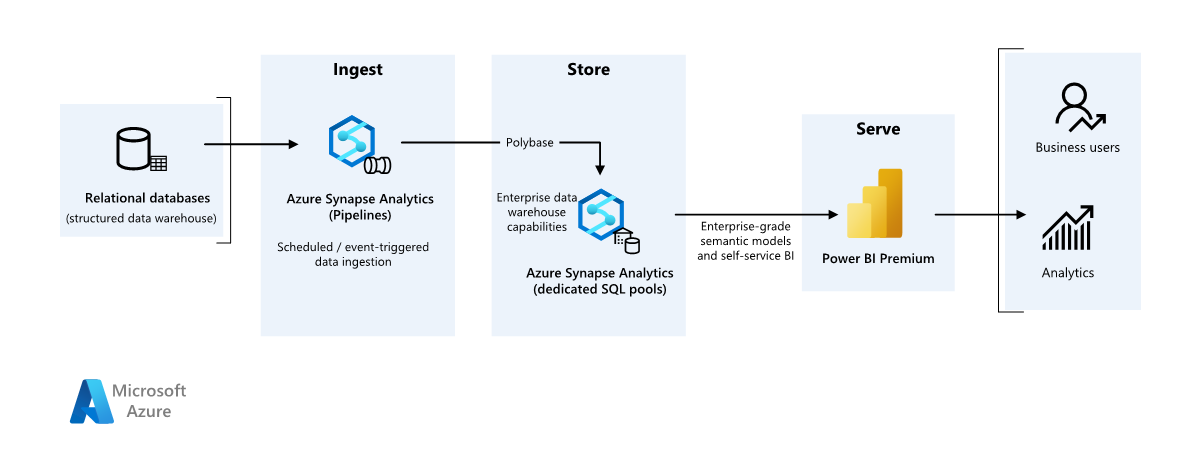
Bu örnek senaryo, verilerin şirket içi veri ambarından bir bulut ortamına nasıl alınabileceğini ve ardından bir iş zekası (BI) modeli kullanılarak nasıl hizmet verilebileceğini gösterir. Bu yaklaşım, bulut tabanlı bileşenlerle tam modernleştirmeye yönelik bir son hedef veya ilk adım olabilir.
Aşağıdaki adımlar , Azure Synapse Analytics uçtan uca senaryoyu oluşturur. Bir SQL veritabanından Azure Synapse SQL havuzlarına veri almak için Azure Pipelines'ı kullanır ve ardından verileri analiz için dönüştürür.
Mimari

Bu mimarinin bir Visio dosyasını indirin.
İş Akışı
Data source
- Kaynak veriler Azure'daki bir SQL Server veritabanında bulunur. Şirket içi ortamın benzetimini yapmak için bu senaryoya yönelik dağıtım betikleri bir Azure SQL veritabanı sağlar. AdventureWorks örnek veritabanı, kaynak veri şeması ve örnek veriler olarak kullanılır. Şirket içi veritabanından veri kopyalama hakkında bilgi için bkz . SQL Server'a ve SQL Server'dan veri kopyalama ve dönüştürme.
Veri alımı ve veri depolama
Azure Data Lake 2 . Nesil, veri alımı sırasında geçici bir hazırlama alanı olarak kullanılır. Ardından PolyBase'i kullanarak verileri Azure Synapse ayrılmış SQL havuzuna kopyalayabilirsiniz.
Azure Synapse Analytics , büyük verilerde analiz gerçekleştirmek için tasarlanmış dağıtılmış bir sistemdir. Yüksek hacimli paralel işleme (MPP) özelliğini destekleyen Azure Synapse yüksek performanslı analiz çalıştırmaya uygundur. Azure Synapse ayrılmış SQL havuzu, şirket içinden sürekli alım için bir hedeftir. Daha fazla işlem için ve DirectQuery aracılığıyla Power BI verilerinin sunulması için kullanılabilir.
Azure Pipelines , Azure Synapse çalışma alanınızda veri alımını ve dönüşümü yönetmek için kullanılır.
Analiz ve raporlama
- Bu senaryoda veri modelleme yaklaşımı, kurumsal model ve BI Anlam modeli birleştirilerek sunulur. Kurumsal model Bir Azure Synapse ayrılmış SQL havuzunda depolanır ve BI Anlam modeli Power BI Premium kapasitelerinde depolanır. Power BI verilere DirectQuery aracılığıyla erişir.
Bileşenler
Bu senaryoda aşağıdaki bileşenler kullanılır:
Basitleştirilmiş mimari
Senaryo ayrıntıları
Bir kuruluşun SQL veritabanında depolanan büyük bir şirket içi veri ambarı vardır. Kuruluş analiz gerçekleştirmek için Azure Synapse'i kullanmak ve ardından Power BI kullanarak bu içgörülere hizmet etmek istiyor.
Kimlik Doğrulaması
Microsoft Entra, Power BI panolarına ve uygulamalarına bağlanan kullanıcıların kimliğini doğrular. Azure Synapse tarafından sağlanan havuzdaki veri kaynağına bağlanmak için çoklu oturum açma kullanılır. Yetkilendirme kaynakta gerçekleşir.
Artımlı yükleme
Otomatik ayıklama, dönüştürme, yükleme (ETL) veya ayıklama, yükleme, dönüştürme (ELT) işlemi çalıştırdığınızda, yalnızca önceki çalıştırmadan sonra değişen verileri yüklemek en verimli yöntemdir. Tüm verileri yükleyen tam yük yerine artımlı yük olarak adlandırılır. Artımlı yük gerçekleştirmek için hangi verilerin değiştiğini belirlemek için bir yol gerekir. En yaygın yaklaşım, kaynak tablodaki bir sütunun en son değerini (tarih saat sütunu veya benzersiz bir tamsayı sütunu) izleyen yüksek su işareti değeri kullanmaktır.
SQL Server 2016'dan başlayarak, veri değişikliklerinin tam geçmişini tutan sistem sürümüne sahip tablolar olan zamana bağlı tabloları kullanabilirsiniz. Veritabanı altyapısı, her değişikliğin geçmişini otomatik olarak ayrı bir geçmiş tablosunda kaydeder. Sorguya yan FOR SYSTEM_TIME tümce ekleyerek geçmiş verileri sorgulayabilirsiniz. Dahili olarak, veritabanı altyapısı geçmiş tablosunu sorgular, ancak uygulama için saydamdır.
Not
SQL Server'ın önceki sürümleri için değişiklik veri yakalama (CDC) kullanabilirsiniz. Ayrı bir değişiklik tablosu sorgulamanız gerektiğinden ve değişiklikler zaman damgası yerine günlük dizisi numarasıyla izlendiğinden, bu yaklaşım zamansal tablolardan daha az kullanışlıdır.
Zamana bağlı tablolar, zaman içinde değişebilen boyut verileri için kullanışlıdır. Olgu tabloları genellikle satış gibi sabit bir işlemi temsil eder ve bu durumda sistem sürümü geçmişini tutmak mantıklı değildir. Bunun yerine, işlemler genellikle filigran değeri olarak kullanılabilen işlem tarihini temsil eden bir sütuna sahiptir. Örneğin, AdventureWorks Veri Ambarı'nda tabloların SalesLT.* bir LastModified alanı vardır.
ELT işlem hattının genel akışı aşağıdadır:
Kaynak veritabanındaki her tablo için, son ELT işinin çalıştırıldığında kesme süresini izleyin. Bu bilgileri veri ambarında depolayın. İlk kurulumda, tüm zamanlar olarak
1-1-1900ayarlanır.Veri dışarı aktarma adımı sırasında kesme süresi, kaynak veritabanındaki bir dizi saklı yordama parametre olarak geçirilir. Bu saklı yordamlar, kesme zamanından sonra değiştirilen veya oluşturulan tüm kayıtları sorgular. Örnekteki tüm tablolar için sütununu
ModifiedDatekullanabilirsiniz.Veri geçişi tamamlandığında kesme sürelerini depolayan tabloyu güncelleştirin.
Veri işlem hattı
Bu senaryoda veri kaynağı olarak AdventureWorks örnek veritabanı kullanılır. Artımlı veri yükleme düzeni, yalnızca en son işlem hattı çalıştırmasının ardından değiştirilmiş veya eklenmiş verileri yüklediğimizden emin olmak için uygulanır.
Meta veri temelli kopyalama aracı
Azure Pipelines içindeki meta veri temelli yerleşik kopyalama aracı , ilişkisel veritabanımızda yer alan tüm tabloları artımlı olarak yükler. Sihirbaz tabanlı deneyimde gezinerek Veri Kopyalama aracını kaynak veritabanına bağlayabilir ve her tablo için artımlı veya tam yüklemeyi yapılandırabilirsiniz. Veri Kopyalama aracı daha sonra artımlı yükleme işlemi için verileri depolamak için gereken denetim tablosunu (örneğin, her tablonun yüksek filigran değeri/sütunu) oluşturmak için hem işlem hatlarını hem de SQL betiklerini oluşturur. Bu betikler çalıştırıldıktan sonra işlem hattı, kaynak veri ambarı içindeki tüm tabloları Synapse ayrılmış havuzuna yüklemeye hazır olur.
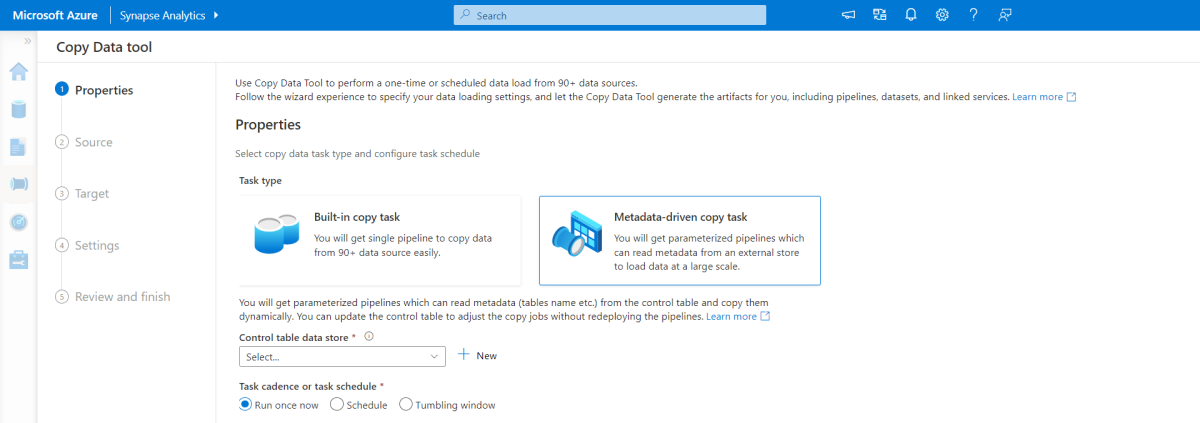
Araç, verileri yüklemeden önce veritabanındaki tüm tabloları yinelemek için üç işlem hattı oluşturur.
Bu araç tarafından oluşturulan işlem hatları:
- İşlem hattı çalıştırmasında kopyalanacak tablo gibi nesne sayısını sayın.
- Yüklenecek/kopyalanacak her nesne üzerinde yineleme yapın ve sonra:
- Delta yükünün gerekli olup olmadığını denetleyin; aksi takdirde normal bir tam yükü tamamlar.
- Denetim tablosundan yüksek filigran değerini alın.
- Kaynak tablolardaki verileri Data Lake Storage 2. Nesil hazırlama hesabına kopyalayın.
- Seçilen kopyalama yöntemiyle ayrılmış SQL havuzuna veri yükleyin; örneğin PolyBase, Kopyala komutu.
- Denetim tablosundaki yüksek filigran değerini güncelleştirin.
Azure Synapse SQL havuzuna veri yükleme
Kopyalama etkinliği verileri SQL veritabanından Azure Synapse SQL havuzuna kopyalar. Bu örnekte SQL veritabanımız Azure'da olduğundan, SQL veritabanındaki verileri okumak ve verileri belirtilen hazırlama ortamına yazmak için Azure tümleştirme çalışma zamanını kullanırız.
Copy deyimi daha sonra hazırlama ortamındaki verileri Synapse ayrılmış havuzuna yüklemek için kullanılır.
Azure Pipelines’ı kullanma
Azure Synapse'teki işlem hatları, artımlı yük desenini tamamlamak için sıralı etkinlik kümesini tanımlamak için kullanılır. Tetikleyiciler, el ile veya belirtilen bir zamanda tetiklenebilen işlem hattını başlatmak için kullanılır.
Verileri dönüştürme
Başvuru mimarimizdeki örnek veritabanı büyük olmadığından, bölüm içermeyen çoğaltılmış tablolar oluşturduk. Üretim iş yükleri için, dağıtılmış tabloların kullanılması sorgu performansını geliştirme olasılığı yüksektir. Daha fazla bilgi için bkz . Azure Synapse'te dağıtılmış tablolar tasarlama kılavuzu. Örnek betikler sorguları statik bir kaynak sınıfı kullanarak çalıştırır.
Üretim ortamında hepsini bir kez deneme dağıtımıyla hazırlama tabloları oluşturmayı göz önünde bulundurun. Ardından kümelenmiş columnstore dizinleri ile verileri dönüştürün ve üretim tablolarına taşıyın ve bu da genel olarak en iyi sorgu performansını sunar. Columnstore dizinleri, birçok kaydı taraan sorgular için iyileştirilmiştir. Columnstore dizinleri tek tek aramalar için( yani tek bir satır arama) için de iyi performans göstermez. Sık sık tekli aramalar yapmanız gerekiyorsa, tabloya kümelenmemiş dizin ekleyebilirsiniz. Tekli aramalar, kümelenmemiş bir dizin kullanarak çok daha hızlı çalıştırılabilir. Ancak tekil aramalar genellikle veri ambarı senaryolarında OLTP iş yüklerine göre daha az yaygındır. Daha fazla bilgi için bkz . Azure Synapse'te tabloları dizine ekleme.
Not
Kümelenmiş columnstore tabloları , varchar(max)veya nvarchar(max) veri türlerini desteklemezvarbinary(max). Bu durumda, yığın veya kümelenmiş dizini göz önünde bulundurun. Bu sütunları ayrı bir tabloya koyabilirsiniz.
Verilere erişmek, verileri modellemek ve görselleştirmek için Power BI Premium'ı kullanma
Power BI Premium, azure synapse tarafından sağlanan havuz başta olmak üzere Azure'daki veri kaynaklarına bağlanmak için çeşitli seçenekleri destekler:
- İçeri aktarma: Veriler Power BI modeline aktarılır.
- DirectQuery: Veriler doğrudan ilişkisel depolamadan çekilir.
- Bileşik model: Bazı tablolar için İçeri Aktar'ı, diğerleri için de DirectQuery'i birleştirin.
Kullanılan veri miktarı ve model karmaşıklığı yüksek olmadığından, iyi bir kullanıcı deneyimi sunabilmemiz için bu senaryo DirectQuery panosuyla sunulur. DirectQuery, sorguyu altındaki güçlü işlem altyapısına devreder ve kaynakta kapsamlı güvenlik özelliklerini kullanır. Ayrıca DirectQuery kullanmak, sonuçların her zaman en son kaynak verilerle tutarlı olmasını sağlar.
İçeri aktarma modu en hızlı sorgu yanıt süresini sağlar ve model tamamen Power BI'ın belleğine sığdığında, yenilemeler arasındaki veri gecikme süresi tolere edilebilir ve kaynak sistem ile son model arasında bazı karmaşık dönüştürmeler olabilir. Bu durumda, son kullanıcılar Power BI yenilemesinde gecikme olmadan en son verilere ve kapasite boyutuna bağlı olarak 25-400 GB arasında bir Power BI veri kümesinin işleyebileceğinden daha büyük olan tüm geçmiş verilere tam erişim ister. Ayrılmış SQL havuzundaki veri modeli zaten bir yıldız şemasında olduğundan ve dönüştürme gerektirmediği için DirectQuery uygun bir seçimdir.
Power BI Premium 2 . Nesil, büyük modelleri, sayfalandırılmış raporları, dağıtım işlem hatlarını ve yerleşik Analysis Services uç noktasını işlemenizi sağlar. Benzersiz değer teklifine sahip ayrılmış kapasiteniz de olabilir.
BI modeli büyüdükçe veya pano karmaşıklığı arttığında bileşik modellere geçebilir ve karma tablolar ve önceden toplanmış bazı veriler aracılığıyla arama tablolarının bölümlerini içeri aktarmaya başlayabilirsiniz. İçeri aktarılan veri kümeleri için Power BI'da sorgu önbelleğe almayı etkinleştirmenin yanı sıra depolama modu özelliği için çift tabloları kullanmak da bir seçenektir.
Bileşik modelde veri kümeleri sanal geçiş katmanı görevi görür. Kullanıcı görselleştirmelerle etkileşime geçtiğinde Power BI, Synapse SQL havuzları için çift depolama alanına SQL sorguları oluşturur: bellekte veya doğrudan sorguda hangisinin daha verimli olduğuna bağlı olarak. Altyapı, bellek içi sorgudan doğrudan sorguya ne zaman geçeceğine karar verir ve mantığı Synapse SQL havuzuna gönderir. Sorgu tablolarının bağlamlarına bağlı olarak, önbelleğe alınmış (içeri aktarılan) veya önbelleğe alınmamış bileşik modeller gibi davranabilir. Önbelleğe alınacak tabloyu seçin ve seçin, bir veya daha fazla DirectQuery kaynağındaki verileri birleştirin ve/veya DirectQuery kaynaklarıyla içeri aktarılan verilerin bir karışımındaki verileri birleştirin.
Öneriler: Azure Synapse Analytics tarafından sağlanan havuz üzerinden DirectQuery kullanılırken:
- Yinelenen kullanım için kullanıcı veritabanında sorgu sonuçlarını önbelleğe almak için Azure Synapse sonuç kümesi önbelleğini kullanın, sorgu performansını milisaniyeye kadar geliştirin ve işlem kaynağı kullanımını azaltın. Önbelleğe alınmış sonuç kümelerini kullanan sorgular Azure Synapse Analytics'te eşzamanlılık yuvaları kullanmaz ve bu nedenle mevcut eşzamanlılık sınırlarına göre sayılmaz.
- Verileri tıpkı bir tablo gibi önceden hesaplamak, depolamak ve korumak için Azure Synapse gerçekleştirilmiş görünümlerini kullanın. Gerçekleştirilmiş görünümlerde verilerin tümünü veya bir alt kümesini kullanan sorgular daha hızlı performans elde edebilir ve bunları kullanmak için tanımlı gerçekleştirilmiş görünüme doğrudan başvuruda bulunmaları gerekmez.
Dikkat edilmesi gereken noktalar
Bu önemli noktalar, bir iş yükünün kalitesini artırmak için kullanılabilecek bir dizi yol gösteren ilke olan Azure İyi Tasarlanmış Çerçeve'nin yapı taşlarını uygular. Daha fazla bilgi için bkz . Microsoft Azure İyi Tasarlanmış Çerçeve.
Güvenlik
Güvenlik, kasıtlı saldırılara ve değerli verilerinizin ve sistemlerinizin kötüye kullanılmasına karşı güvence sağlar. Daha fazla bilgi için bkz . Güvenlik sütununa genel bakış.
Veri ihlalleri, kötü amaçlı yazılım bulaşmaları ve kötü amaçlı kod ekleme ile ilgili sık sık kullanılan başlıklar, bulut modernleştirmesi isteyen şirketlere yönelik kapsamlı güvenlik endişeleri listesinde yer alır. Kurumsal müşterilerin, sorunları gidermeyi göze alamayacakları için endişelerini giderebilecek bir bulut sağlayıcısına veya hizmet çözümüne ihtiyacı vardır.
Bu senaryo, katmanlı güvenlik denetimlerinin bir bileşimini kullanarak en zorlu güvenlik sorunlarını giderir: ağ, kimlik, gizlilik ve yetkilendirme. Verilerin büyük bir kısmı Azure Synapse tarafından sağlanan havuzda depolanır ve Power BI çoklu oturum açma aracılığıyla DirectQuery'yi kullanarak kullanılır. Kimlik doğrulaması için Microsoft Entra Id kullanabilirsiniz. Sağlanan havuzların veri yetkilendirmesi için kapsamlı güvenlik denetimleri de vardır.
Bazı yaygın güvenlik soruları şunlardır:
- Kimlerin hangi verileri görebileceğini nasıl denetleyebilirim?
- Kuruluşların, veri ihlali risklerini azaltmak için federal, yerel ve şirket yönergelerine uymak için verilerini korumaları gerekir. Azure Synapse, uyumluluk elde etmek için birden çok veri koruma özelliği sunar.
- Kullanıcının kimliğini doğrulama seçenekleri nelerdir?
- Azure Synapse, erişim denetimi ve kimlik doğrulaması aracılığıyla kimlerin hangi verilere erişebileceğini denetlemeye yönelik çok çeşitli özellikleri destekler.
- Ağlarımın ve verilerimin bütünlüğünü, gizliliğini ve erişimini korumak için hangi ağ güvenlik teknolojisini kullanabilirim?
- Azure Synapse'in güvenliğini sağlamak için göz önünde bulundurulabilecek bir dizi ağ güvenlik seçeneği vardır.
- Tehditleri algılayıp bana bildiren araçlar nelerdir?
- Azure Synapse, veritabanlarını denetlemek, korumak ve izlemek için SQL denetimi, SQL tehdit algılama ve güvenlik açığı değerlendirmesi gibi birçok tehdit algılama özelliği sağlar.
- Depolama hesabımdaki verileri korumak için ne yapabilirim?
- Azure Depolama hesapları, hızlı ve tutarlı yanıt süreleri gerektiren veya saniyede çok sayıda giriş-çıkış işlemi (IOP) olan iş yükleri için idealdir. Depolama hesapları tüm Azure Depolama veri nesnelerinizi içerir ve depolama hesabı güvenliği için birçok seçeneğe sahiptir.
Maliyet iyileştirme
Maliyet iyileştirmesi, gereksiz giderleri azaltmanın ve operasyonel verimlilikleri iyileştirmenin yollarını aramaktır. Daha fazla bilgi için bkz . Maliyet iyileştirme sütununa genel bakış.
Bu bölümde, bu çözümde yer alan farklı hizmetlerin fiyatlandırması hakkında bilgi sağlanır ve örnek bir veri kümesiyle bu senaryo için alınan kararlardan bahsediliyor.
Azure Synapse
Azure Synapse Analytics sunucusuz mimarisi, işlem ve depolama düzeylerinizi bağımsız olarak ölçeklendirmenize olanak tanır. İşlem kaynakları kullanıma göre ücretlendirilir ve bu kaynakları isteğe bağlı olarak ölçeklendirebilir veya duraklatabilirsiniz. Depolama kaynakları terabayt başına faturalandırılır, bu nedenle daha fazla veri aldıkça maliyetleriniz artar.
Azure Pipelines
Azure Synapse'teki işlem hatları için fiyatlandırma ayrıntıları, Azure Synapse fiyatlandırma sayfasındaki Veri Entegrasyonu sekmesinde bulunabilir. İşlem hattının fiyatını etkileyen üç ana bileşen vardır:
- Veri işlem hattı etkinlikleri ve tümleştirme çalışma zamanı saatleri
- Veri akışları küme boyutu ve yürütmesi
- İşlem ücretleri
Fiyat, bileşenlere veya etkinliklere, sıklıklara ve tümleştirme çalışma zamanı birimlerinin sayısına bağlı olarak değişir.
Örnek veri kümesi için, işlem hattının çekirdeği için veri kopyalama etkinliği olan standart Azure tarafından barındırılan tümleştirme çalışma zamanı, kaynak veritabanındaki tüm varlıklar (tablolar) için günlük bir zamanlamaya göre tetiklenmektedir. Senaryo veri akışı içermiyor. İşlem hatlarıyla ayda 1 milyondan az işlem olduğundan operasyonel maliyet yoktur.
Azure Synapse ayrılmış havuzu ve depolama
Azure Synapse ayrılmış havuzu için fiyatlandırma ayrıntıları, Azure Synapse fiyatlandırma sayfasındaki Veri Depolama sekmesinde bulunabilir. Ayrılmış tüketim modeli kapsamında müşteriler, sağlanan veri ambarı birimi (DWU) birimleri başına, çalışma süresi saati başına faturalandırılır. Katkıda bulunan bir diğer faktör de veri depolama maliyetleridir: bekleyen verilerinizin boyutu + anlık görüntüler + varsa coğrafi yedeklilik.
Örnek veri kümesi için analiz yükü için iyi bir deneyim sağlayan 500DWU sağlayabilirsiniz. Raporlamanın iş saatleri içinde işlem ve çalıştırmaya devam edebilirsiniz. Üretime alınırsa, ayrılmış veri ambarı kapasitesi maliyet yönetimi için cazip bir seçenektir. Önceki bölümlerde ele alınan maliyet/performans ölçümlerini en üst düzeye çıkarmak için farklı teknikler kullanılmalıdır.
Blob depolama
Depolama maliyetlerini düşürmek için Azure Depolama ayrılmış kapasite özelliğini kullanmayı göz önünde bulundurun. Bu modelle, sabit depolama kapasitesini bir veya üç yıl ayırdığınızda indirim elde edersiniz. Daha fazla bilgi için bkz . Ayrılmış kapasite ile Blob depolama maliyetlerini iyileştirme.
Bu senaryoda kalıcı depolama alanı yoktur.
Power BI Premium
Power BI Premium fiyatlandırma ayrıntılarına Power BI fiyatlandırma sayfasından ulaşabilirsiniz.
Bu senaryoda, zorlu analiz gereksinimlerini karşılamak için yerleşik olarak bir dizi performans geliştirmesi içeren Power BI Premium çalışma alanları kullanılır.
Operasyonel mükemmellik
Operasyonel mükemmellik, bir uygulamayı dağıtan ve üretimde çalışır durumda tutan operasyon süreçlerini kapsar. Daha fazla bilgi için bkz . Operasyonel mükemmellik sütununa genel bakış.
DevOps önerileri
Üretim, geliştirme ve test ortamları için ayrı kaynak grupları oluşturun. Ayrı kaynak grupları dağıtımları yönetmeyi, test dağıtımlarını silmeyi ve erişim haklarını atamayı kolaylaştırır.
Her iş yükünü ayrı bir dağıtım şablonuna yerleştirin ve kaynakları kaynak denetim sistemlerinde depolayın. Şablonları birlikte veya tek tek sürekli tümleştirme ve sürekli teslim (CI/CD) işleminin bir parçası olarak dağıtarak otomasyon sürecini kolaylaştırabilirsiniz. Bu mimaride dört ana iş yükü vardır:
- Veri ambarı sunucusu ve ilgili kaynaklar
- Azure Synapse işlem hatları
- Power BI varlıkları: panolar, uygulamalar, veri kümeleri
- Şirket içi ortamdan buluta simülasyon senaryosu
İş yüklerinin her biri için ayrı bir dağıtım şablonuna sahip olmayı hedefleyin.
İş yüklerinizi pratik yerlerde hazırlamayı göz önünde bulundurun. Çeşitli aşamalara dağıtın ve sonraki aşamaya geçmeden önce her aşamada doğrulama denetimleri çalıştırın. Bu şekilde, güncelleştirmeleri üretim ortamlarınıza denetimli bir şekilde gönderebilirsiniz ve tahmin edilmeyen dağıtım sorunlarını en aza indirebilirsiniz. Canlı üretim ortamlarını güncelleştirmek için mavi-yeşil dağıtım ve kanarya yayın stratejilerini kullanın.
Başarısız dağıtımları işlemek için iyi bir geri alma stratejisine sahip olun. Örneğin, dağıtım geçmişinizden daha önceki ve başarılı bir dağıtımı otomatik olarak yeniden dağıtabilirsiniz.
--rollback-on-errorAzure CLI'daki bayrağına bakın.Azure İzleyici , tümleşik izleme deneyimi için veri ambarınızın ve azure analiz platformunun tamamının performansını analiz etmek için önerilen seçenektir. Azure Synapse Analytics , veri ambarı iş yükünüz hakkındaki içgörüleri göstermek için Azure portalında bir izleme deneyimi sağlar. Azure portalı, ölçümler ve günlükler için yapılandırılabilir saklama süreleri, uyarılar, öneriler ve özelleştirilebilir grafikler ve panolar sağladığından veri ambarınızı izlerken önerilen araçtır.
Hızlı başlangıç
- Portal: Azure Synapse kavram kanıtı (POC)
- Azure CLI: Azure CLI ile Azure Synapse çalışma alanı oluşturma
- Terraform: Terraform ve Microsoft Azure ile modern veri ambarı
Performans verimliliği
Performans verimliliği, kullanıcılar tarafından anlamlı bir şekilde yerleştirilen talepleri karşılamak amacıyla iş yükünüzü ölçeklendirme becerisidir. Daha fazla bilgi için bkz . Performans verimliliği sütununa genel bakış.
Bu bölümde, bu veri kümesini barındırmaya yönelik boyutlandırma kararlarıyla ilgili ayrıntılar sağlanır.
Azure Synapse tarafından sağlanan havuz
Aralarından seçim yapabileceğiniz bir dizi veri ambarı yapılandırması vardır.
| Veri ambarı birimleri | # of compute node | Düğüm başına dağıtım sayısı |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Özellikle daha büyük veri ambarı birimlerinde ölçeği genişletmenin performans avantajlarını görmek için en az 1 TB veri kümesi kullanın. Ayrılmış SQL havuzunuz için en fazla sayıda veri ambarı birimini bulmak için ölçeği artırmayı ve azaltmayı deneyin. Verilerinizi yükledikten sonra farklı sayıda veri ambarı birimiyle birkaç sorgu çalıştırın. Ölçeklendirme hızlı olduğundan, bir saat veya daha kısa bir sürede çeşitli performans düzeylerini deneyebilirsiniz.
En fazla veri ambarı birimi sayısını bulma
Geliştirme aşamasındaki ayrılmış bir SQL havuzu için, daha az sayıda veri ambarı birimi seçerek başlayın. DW400c veya DW200c iyi bir başlangıç noktasıdır. Gözlemlediğiniz performansla karşılaştırıldığında seçilen veri ambarı birimi sayısını gözlemleyerek uygulama performansınızı izleyin. Doğrusal bir ölçek varsayın ve veri ambarı birimlerini ne kadar artırmanız veya azaltmanız gerektiğini belirleyin. İş gereksinimleriniz için en uygun performans düzeyine ulaşana kadar ayarlamalar yapmaya devam edin.
Synapse SQL havuzunu ölçeklendirme
- Azure portalı ile Synapse SQL havuzu için işlem ölçeklendirme
- Azure PowerShell ile ayrılmış SQL havuzu için işlem ölçeklendirme
- T-SQL kullanarak Azure Synapse Analytics'te ayrılmış SQL havuzu için işlem ölçeklendirme
- Duraklatma, izleme ve otomasyon
Azure Pipelines
Azure Synapse'teki işlem hatlarının ölçeklenebilirlik ve performans iyileştirme özellikleri ve kullanılan kopyalama etkinliği için Kopyalama etkinliği performans ve ölçeklenebilirlik kılavuzuna bakın.
Power BI Premium
Bu makalede, BI özelliklerini göstermek için Power BI Premium 2. Nesil kullanılır. Power BI Premium için kapasite SKU'ları şu anda P1 (sekiz sanal çekirdek) ile P5 (128 sanal çekirdek) arasındadır. Gerekli kapasiteyi seçmenin en iyi yolu kapasite yükleme değerlendirmesinden geçmek, sürekli izleme için 2. Nesil ölçümler uygulamasını yüklemek ve Power BI Premium ile Otomatik Ölçeklendirme'yi kullanmayı göz önünde bulundurmaktır.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Galina Polyakova | Üst Düzey Bulut Çözümü Mimarı
- Noah Costar | Bulut Çözümü Mimarı
- George Stevens | Bulut Çözümü Mimarı
Diğer katkıda bulunanlar:
- Jim McLeod | Bulut Çözümü Mimarı
- Miguel Myers | Üst Düzey Program Yöneticisi
Genel olmayan LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
- Power BI Premium nedir?
- Microsoft Entra ID nedir?
- Azure Databricks ile Azure Data Lake Storage 2. Nesil ve Blob Depolama'ya erişme
- Azure Synapse Analytics nedir?
- Azure Data Factory ve Azure Synapse Analytics’teki işlem hatları ve etkinlikler
- Azure SQL nedir?