Veri deposu modellerini anlama
Modern iş sistemleri giderek daha büyük hacimlerde heterojen verileri yönetir. Bu durum tek bir veri deposunun genellikle en iyi yaklaşım olmadığı anlamına geliyor. Bunun yerine, her biri belirli bir iş yüküne veya kullanım düzenine odaklanan farklı veri depolarında farklı veri türlerini depolamak genellikle daha iyidir. Polyglot kalıcılık terimi, veri deposu teknolojilerinin bir karışımını kullanan çözümleri ifade etmek için kullanılır. Bu nedenle, ana depolama modellerini ve bunların dezavantajlarını anlamak önemlidir.
Gereksinimleriniz için doğru veri deposunu seçmek temel bir tasarım kararıdır. SQL ve NoSQL veritabanları arasından seçilebilecek yüzlerce uygulama vardır. Veri depoları, genellikle verileri nasıl yapılandırdıkları ve destekledikleri işlem türlerine göre kategorilere ayrılır. Bu makalede en yaygın depolama modellerinden bazıları açıklanmaktadır. Belirli bir veri deposu teknolojisinin birden çok depolama modelini destekleyebileceğini unutmayın. Örneğin, bir ilişkisel veritabanı yönetim sistemi (RDBMS) anahtar/değer ya da grafik depolamayı destekleyebilir. Aslında, tek bir veritabanı sisteminin çeşitli modelleri desteklediği çok modelli destek olarak adlandırılan genel bir eğilim vardır. Ancak yüksek düzeyde farklı modelleri anlamak hala faydalıdır.
Belirli bir kategorideki tüm veri depoları aynı özellik kümesini sağlamaz. Çoğu veri deposu verileri sorgulamak ve veri işlemek için sunucu tarafı işlevler sunar. Bazen bu işlevler, veri depolama motorunda yerleşiktir. Diğer durumlarda, veri depolama ve işleme özellikleri ayrılır; işleme ve analiz için çeşitli seçenekler olabilir. Veri depoları da farklı programlama ve yönetim arabirimlerini destekler.
Genellikle, gereksinimleriniz için hangi depolama modelinin en uygun model olduğunu değerlendirerek başlamanız gerekir. Ardından, bu kategoride belirli bir veri deposunu, özellik kümesi, maliyet ve yönetim kolaylığı gibi etkenlere göre değerlendirmelisiniz.
Dekont
Azure için Microsoft Bulut Benimseme Çerçevesi'nde bulut benimseme için veri hizmeti gereksinimlerinizi belirleme ve gözden geçirme hakkında daha fazla bilgi edinin. Benzer şekilde, depolama araçlarını ve hizmetlerini seçme hakkında da bilgi edinebilirsiniz.
İşletimsel veritabanı yönetim sistemleri
İlişkisel veritabanları, verileri satırlar ve sütunlar içeren bir dizi iki boyutlu tablo olarak düzenler. Çoğu satıcı, verileri almak ve yönetmek için Yapılandırılmış Sorgu Dili (SQL) diyalektini sağlar. Bir RDBMS genellikle bilgileri güncelleştirmek için ACID (Atomic, Consistent, Isolated, Durable) modeline uyan, işlemsel olarak tutarlı bir mekanizma uygular.
Bir RDBMS genellikle veri yapısı önceden tanımlanan ve tüm okuma veya yazma işlemlerinin şemayı kullanması gereken bir yazma şeması modelini destekler.
Bu model, güçlü tutarlılık garantilerinin önemli olduğu ve tüm değişikliklerin atomik olduğu ve işlemlerin verileri her zaman tutarlı bir durumda bıraktığı durumlarda çok kullanışlıdır. Ancak RDBMS genellikle verileri bir şekilde parçalamadan yatay olarak ölçeği genişletemez. Ayrıca, bir RDBMS'deki veriler normalleştirilmelidir ve bu her veri kümesi için uygun değildir.
Azure hizmetleri
- | Azure SQL Veritabanı(Güvenlik Temeli)
- | MySQL için Azure Veritabanı(Güvenlik Temeli)
- | PostgreSQL için Azure Veritabanı(Güvenlik Temeli)
- | MariaDB için Azure Veritabanı(Güvenlik Temeli)
İş Yükü
- Kayıtlar sık sık oluşturulur ve güncelleştirilir.
- Tek bir işlemde birden çok işlemin tamamlanması gerekir.
- Veritabanı kısıtlamaları kullanılarak ilişkiler uygulanır.
- Sorgu performansının iyileştirilmesi için dizinler kullanılır.
Veri türü
- Veri yüksek oranda normalleştirilmiştir.
- Veritabanı şemaları gereklidir ve zorunlu tutulur.
- Veritabanındaki veri varlıkları arasında çoka çok ilişkiler.
- Şemada kısıtlamalar tanımlanır ve veritabanındaki tüm verilere uygulanır.
- Veriler yüksek bütünlük gerektirir. Dizin ve ilişkilerin doğru olarak saklanması gerekir.
- Veriler güçlü tutarlılık gerektirir. İşlemler, tüm kullanıcı ve işlemler için tüm verilerin %100 tutarlı olmasını sağlayacak şekilde çalışır.
- Tek tek veri girişlerinin boyutu küçük ve orta boyutludur.
Örnekler
- Stok Yönetimi
- Sipariş yönetimi
- Raporlama veritabanı
- Muhasebe
Anahtar/değer depoları
Anahtar/değer deposu her veri değerini benzersiz bir anahtarla ilişkilendirir. Çoğu anahtar/değer deposu yalnızca basit sorgu, ekleme ve silme işlemlerini destekler. Bir değeri kısmen veya tamamen değiştirmek için, uygulamanın tüm değerde mevcut verilerin üzerine yazması gerekir. Çoğu uygulamada tek bir değerin okunması veya yazılması atomik bir işlemdir.
Bir uygulama rastgele verileri bir değer kümesi olarak depolayabilir. Tüm şema bilgileri uygulama tarafından sağlanmalıdır. Anahtar/değer deposu değeri anahtara göre alır veya depolar.
Anahtar/değer depoları, basit aramalar gerçekleştiren uygulamalar için yüksek oranda iyileştirilir, ancak farklı anahtar/değer depolarında veri sorgulamanız gerekiyorsa daha az uygundur. Anahtar/değer depoları da değere göre sorgulama için iyileştirilmemiştir.
Veri deposu, ayrı makinelerde birden çok düğüm arasında verileri kolayca dağıtabileceğinden tek anahtar/değer deposu son derece ölçeklenebilir olabilir.
Azure hizmetleri
- Tablo için Azure Cosmos DB ve NoSQL | için Azure Cosmos DB (Azure Cosmos DB Güvenlik Temeli)
- | Redis için Azure Cache(Güvenlik Temeli)
- Azure Tablo Depolama | (Güvenlik Temeli)
İş Yükü
- Verilere sözlük gibi tek bir anahtar kullanılarak erişilir.
- Birleştirme, kilitleme veya birleşim gerekmez.
- Toplama mekanizması kullanılmaz.
- Genellikle ikincil dizinler kullanılmaz.
Veri türü
- Her anahtar tek bir değerle ilişkilendirilir.
- Şema zorlama yoktur.
- Varlıklar arasında ilişki yoktur.
Örnekler
- Verileri önbelleğe alma
- Oturum yönetimi
- Kullanıcı tercihi ve profil yönetimi
- Ürün önerisi ve reklam sunma
Belge veritabanları
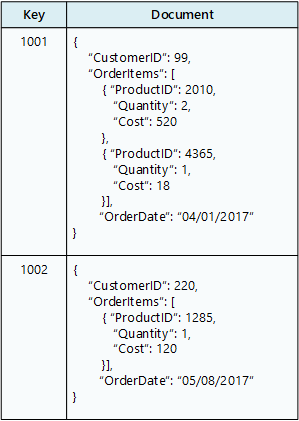
Belge veritabanı, her belgenin adlandırılmış alanlar ve verilerden oluştuğu bir belge koleksiyonu depolar. Veriler basit değerler veya listeler ve alt koleksiyonlar gibi karmaşık öğeler olabilir. Belgeler benzersiz anahtarlar tarafından alınır.
Belge genellikle müşteri veya sipariş gibi tek bir varlığın verilerini içerir. Belge, RDBMS'deki çeşitli ilişkisel tablolara yayılacak bilgiler içerebilir. Belgelerin aynı yapıya sahip olması gerekmez. İş gereksinimleri değiştikçe uygulamalar belgelerde farklı veriler depolayabilir.
Azure hizmeti
İş Yükü
- Sık sık ekleme ve güncelleştirme işlemleri gerçekleştirilir.
- Nesne ilişkisel empedans uyuşmazlığı yoktur. Belgeler uygulama kodunda kullanılan nesne yapılarıyla daha iyi eşleşebilir.
- Tek tek belgeler alınır ve tek bir blok olarak yazılır.
- Veriler birden çok alanda dizin gerektirir.
Veri türü
- Veriler normalleştirilmişlikten çıkarılmış bir şekilde yönetilebilir.
- Tek tek belge verilerinin boyutu göreceli olarak küçüktür.
- Her bir belge türü kendi şemasını kullanabilir.
- Belgeler isteğe bağlı alanlar içerebilir.
- Belge verileri yarı yapılandırılmıştır, yani her bir alanın veri türleri kesin bir şekilde tanımlanmamıştır.
Örnekler
- Ürün kataloğu
- İçerik yönetimi
- Stok Yönetimi
Graf veritabanları
Bir grafik veritabanı, düğümler ve kenarlar olmak üzere iki tür bilgi depolar. Kenarlar düğümler arasındaki ilişkileri belirtir. Düğümler ve kenarlar, bir tablodaki sütunlara benzer şekilde bu düğüm veya kenar hakkında bilgi sağlayan özelliklere sahip olabilir. Kenarlar ayrıca ilişkinin yapısını gösteren bir yöne sahip olabilir.
Graph veritabanları düğümler ve kenarlar ağı genelinde verimli bir şekilde sorgular gerçekleştirebilir ve varlıklar arasındaki ilişkileri analiz edebilir. Aşağıdaki diyagramda, bir kuruluşun grafik olarak yapılandırılmış personel veritabanı gösterilmektedir. Varlıklar çalışanlar ve departmanlardır ve kenarlar raporlama ilişkilerini ve çalışanların çalıştığı departmanları gösterir.
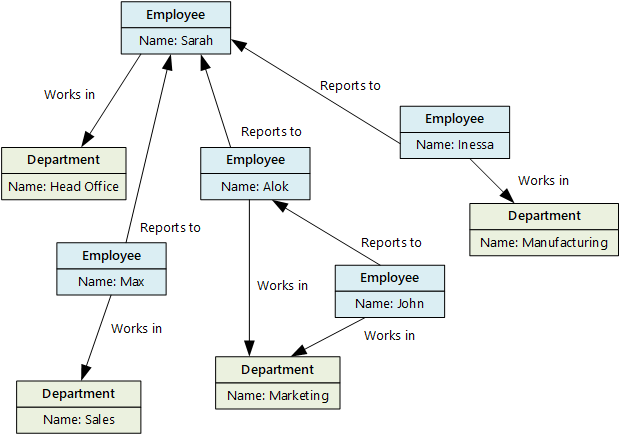
Bu yapı, "Doğrudan veya dolaylı olarak Sarah'a rapor veren tüm çalışanları bul" veya "John ile aynı departmanda kimler çalışıyor?" gibi sorguların gerçekleştirilmesini kolaylaştırır. Çok sayıda varlık ve ilişki içeren büyük grafikler için çok karmaşık analizleri çok hızlı bir şekilde gerçekleştirebilirsiniz. Pek çok grafik veritabanı, ilişkiler ağını verimli bir şekilde işlemenizi sağlayan bir sorgu dili sağlar.
Azure hizmetleri
İş Yükü
- İlgili veri öğeleri arasında çok sayıda atlama içeren veri öğeleri arasındaki karmaşık ilişkiler.
- Veri öğeleri arasındaki ilişki dinamiktir ve zamanla değişir.
- Nesneler arasındaki ilişkiler, geçiş için yabancı anahtarlar ve birleştirmelere gereksinim duymayan birinci sınıf öğelerdir.
Veri türü
- Düğümler ve ilişkiler.
- Düğümler tablo satırlarına veya JSON belgelerine benzer.
- İlişkiler en az düğümler kadar önemlidir ve sorgu dilinde doğrudan kullanıma sunulur.
- Birden çok telefon numarası olan bir kişi gibi bileşik nesneler genellikle ayrı, daha küçük düğümlere bölünür ve geçiş imkanı tanıyan ilişkilerle birleştirilir
Örnekler
- Kuruluş şemaları
- Sosyal grafikler
- Sahtekarlık algılama
- Öneri altyapıları
Veri analizi
Veri analizi depoları verileri almak, depolamak ve analiz etmek için yüksek düzeyde paralel çözümler sunar. Veriler, ölçeklenebilirliği en üst düzeye çıkarmak için birden çok sunucuya dağıtılır. Sınırlayıcı dosyalar (CSV), parquet ve ORC gibi büyük veri dosyası biçimleri veri analizinde yaygın olarak kullanılır. Geçmiş veriler genellikle blob depolama veya Azure Data Lake Storage 2. Nesil gibi veri depolarında depolanır ve bu depolara Azure Synapse, Databricks veya HDInsight tarafından dış tablolar olarak erişilir. Performans için parquet dosyaları olarak depolanan verilerin kullanıldığı tipik bir senaryo, Synapse SQL ile dış tabloları kullanma makalesinde açıklanmıştır.
Azure hizmetleri
- Azure Synapse Analytics | (Güvenlik Temeli)
- Azure Data Lake | (Güvenlik Temeli)
- Azure Veri Gezgini | (Güvenlik Temeli)
- Azure Analysis Services
- HDInsight | (Güvenlik Temeli)
- Azure Databricks | (Güvenlik Temeli)
İş Yükü
- Veri analizi
- Enterprise BI
Veri türü
- Birden çok kaynaktan geçmiş veriler.
- Genellikle bilgi ve boyut tablolarından oluşan bir “yıldız” veya “kar tanesi” şemasında normalleştirilmişlikten çıkarılır.
- Genellikle bir zamanlama temelinde yeni verilerle birlikte yüklenir.
- Boyut tabloları genellikle bir varlığın yavaş değişen boyut olarak adlandırılan birden fazla geçmiş sürümünü içerir.
Örnekler
- Kurumsal veri ambarı
Sütun ailesi veritabanları
Bir sütun ailesi veritabanı verileri satırlar ve sütunlar halinde düzenler. En basit biçimiyle bir sütun ailesi veritabanı, en azından kavramsal olarak ilişkisel bir veri tabanına çok benzer görünür. Sütun ailesi veri tabanının asıl gücü, seyrek verilerin yapılandırılmasında normalleştirilmişlikten çıkarılmış yaklaşımıdır.
Bir sütun ailesi veri tabanının satırlar ve sütunlarla tablo verilerini içerdiğini, ancak sütun gruplarının sütun ailesi olarak bilinen gruplara ayrıldığını düşünebilirsiniz. Her sütun ailesi mantıksal olarak ilgili ve genellikle bir birim halinde alınan veya yönetilen sütunların kümesini içerir. Ayrı olarak erişilen diğer veriler ayrı sütun ailelerinde depolanabilir. Bir sütun ailesi içinde yeni sütunlar dinamik olarak eklenebilir ve satırlar seyrek olabilir (diğer bir deyişle, bir satırın her sütun için bir değere sahip olması gerekmez).
Aşağıdaki diyagramda iki sütun ailesi (Identity ve Contact Info) içeren bir örnek gösterilmektedir. Tek bir varlık için veriler her sütun ailesi için aynı satır anahtarına sahiptir. Bir sütun ailesindeki herhangi bir nesne için satırların dinamik olarak değişebildiği bu yapı, sütun ailesi yaklaşımın önemli bir avantajıdır; bu veri depolama biçimini yapılandırılmış, geçici verileri depolamak için uygun bir hale getirir.

Bir anahtar/değer deposu veya belge veritabanı aksine, çoğu sütun ailesi veritabanı verileri karma hesaplaması yerine anahtar sırasına göre depolar. Birçok uygulama, bir sütun ailesinde belirli sütunlarda dizin oluşturmanıza izin verir. Dizinler, satır anahtarı yerine sütun değerine göre veri almanızı sağlar.
Bir satırda okuma ve yazma işlemleri tek sütun ailesinde genellikle atomiktir, ancak bazı uygulamalar birden çok sütun ailesini kapsayan tüm bir satırda atomik özellik sağlar.
Azure hizmetleri
İş Yükü
- Çoğu sütun ailesi veritabanı, yazma işlemlerini son derece hızlı bir şekilde gerçekleştirir.
- Güncelleştirme ve silme işlemleri nadiren gerçekleşir.
- Yüksek aktarım hızı ve düşük gecikmeli erişim sağlayacak şekilde tasarlanmıştır.
- Çok daha büyük bir kayıt içindeki belirli bir alan kümesine kolay sorgu erişimini destekler.
- Büyük oranda ölçeklenebilir.
Veri türü
- Veriler bir anahtar sütunu ile bir veya daha fazla sütun ailesinden oluşan tablolarda depolanır.
- Belirli sütunlar ayrı satırlara göre farklılık gösterebilir.
- Tek tek hücrelere get ve put komutları aracılığıyla erişilir
- Bir tarama komutu kullanılarak birden çok satır döndürülür.
Örnekler
- Öneriler
- Kişiselleştirme
- Algılayıcı verileri
- Telemetri
- Mesajlaşma
- Sosyal medya analizi
- Web analizi
- Etkinlik izleme
- Hava durumu ve diğer zaman serisi verileri
Arama Motoru Veritabanları
Arama motoru veritabanı, uygulamaların dış veri depolarında tutulan bilgileri aramasına olanak tanır. Arama motoru veritabanı çok büyük hacimli verilerin dizinini oluşturabilir ve bu dizinlere neredeyse gerçek zamanlı erişim sağlayabilir.
Dizinler çok boyutlu olabilir ve büyük metin verilerinde serbest metin aramayı destekleyebilir. Dizin oluşturma, arama motoru veritabanı tarafından tetiklenen bir gönderme modeli ya da dış uygulama kodu tarafından başlatılan bir çekme modeli kullanılarak gerçekleştirilebilir.
Arama, tam veya benzer olabilir. Benzer arama, bir terimler kümesiyle eşleşen belgeleri bulur ve ne kadar yakından eşleştiğini hesaplar. Bazı arama motorları da eş anlamlılar, tarz genişletmeleri (örneğin, eşleşen dogs için pets) ve kaynak (aynı kök ile eşleşen sözcükler) ölçütlerine göre sonuç döndürebilen dil analizlerini destekler.
Azure hizmeti
İş Yükü
- Birden çok kaynaktan ve hizmetten veri dizinleri.
- Sorgular geçicidir ve karmaşık olabilir.
- Tam metin arama gereklidir.
- Geçici self servis sorgu gereklidir.
Veri türü
- Yarı yapılandırılmış veya yapılandırılmamış metin
- Yapılandırılmış verilere başvuru içeren metin
Örnekler
- Ürün katalogları
- Site araması
- Günlük Kaydı
Zaman serisi veritabanları
Zaman serisi verileri, zamana göre düzenlenmiş bir değer kümesidir. Zaman serisi veritabanları genellikle çok sayıda kaynaktan gerçek zamanlı olarak büyük miktarda veri toplar. Güncelleştirmeler nadirdir ve silme işlemleri genellikle toplu işlemler halinde yapılır. Zaman serisi veritabanına yazılan kayıtlar genellikle küçük olsa da, çoğunlukla çok sayıda kayıt vardır ve toplam veri boyutu hızlı bir şekilde büyüyebilir.
Azure hizmeti
İş Yükü
- Kayıtlar genellikle zaman sırasına göre sıralı olarak eklenir.
- İşlemlerin aşırı bir oranı (%95-99) yazma işlemidir.
- Güncelleştirme işlemleri nadiren gerçekleşir.
- Silme işlemleri toplu olarak, bitişik blok veya kayıtlarda gerçekleştirilir.
- Veriler, genellikle paralel olarak artan veya azalan zaman sırasına göre sıralı olarak okunur.
Veri türü
- Birincil anahtar ve sıralama mekanizması olarak bir zaman damgası kullanılır.
- Etiketler tür, kaynak ve girişle ilgili diğer bilgiler hakkında ek bilgiler tanımlayabilir.
Örnekler
- İzleme ve olay telemetrisi.
- Algılayıcı veya diğer IOT verileri.
Nesne depolama
Nesne depolama, büyük ikili nesneleri (görüntüler, dosyalar, video ve ses akışları, büyük uygulama veri nesneleri ve belgeler, sanal makine disk görüntüleri) almak için optimize edilmiştir. Büyük veri dosyaları da bu modelde popüler olarak kullanılır; örneğin sınırlayıcı dosyası (CSV), parquet ve ORC. Nesne depoları son derece büyük miktarlarda yapılandırılmamış verileri yönetebilir.
Azure hizmeti
İş Yükü
- Anahtar tarafından tanımlanır.
- İçerik genellikle sınırlayıcı, resim veya video dosyası gibi bir varlıktır.
- İçerik dayanıklı ve herhangi bir uygulama katmanının dışında olmalıdır.
Veri türü
- Veri boyutu büyüktür.
- Değer donuktur.
Örnekler
- Resimler, videolar, Office belgeleri, PDF’ler
- Statik HTML, JSON, CSS
- Günlük ve denetim dosyaları
- Veritabanı yedeklemeleri
Paylaşılan dosyalar
Bazı durumlarda, basit düz dosyalar kullanmak bilgileri depolamak ve almak için en etkili yöntem olabilir. Dosya paylaşımları, dosyaların bir ağ üzerinden erişilebilmesini sağlar. Uygun güvenlik ve eş zamanlı erişim denetimi mekanizmalarıyla, verilerin bu şekilde paylaşımı, dağıtılmış hizmetlerin basit okuma ve yazma istekleri gibi temel, alt düzey işlemleri gerçekleştirmek için yüksek düzeyde ölçeklenebilir veri erişimi sağlamasına olanak verebilir.
Azure hizmeti
İş Yükü
- Dosya sistemi ile etkileşim kuran mevcut uygulamalardan geçiş.
- SMB arabirimi gerektirir.
Veri türü
- Hiyerarşik bir klasör kümesindeki dosyalar.
- Standart G/Ç kitaplıkları ile erişilebilir.
Örnekler
- Eski dosyalar
- Paylaşılan içerik, bir grup VM veya uygulama örneği arasında erişilebilir
Farklı veri depolama modellerinin anlaşılmasına yardımcı olan bir sonraki adım, iş yükünüzü ve uygulamanızı değerlendirmek ve hangi veri deposunun özel gereksinimlerinizi karşılanacağına karar vermektir. Bu işleme yardımcı olması için veri depolama karar ağacını kullanın.
Sonraki adımlar
- Azure Cloud Depolama Çözümleri ve Hizmetleri
- Depolama seçeneklerinizi gözden geçirin
- Azure Depolama’ya giriş
- Azure Veri Gezgini'a giriş