Yapay Zeka, bugün bildiğimiz gibi perakende sektöründe dönüşüm potansiyeli sunar. Perakendecilerin yapay zeka tarafından desteklenen bir müşteri deneyimi mimarisi geliştireceğine inanmak mantıklıdır. Bazı beklentiler, yapay zeka ile geliştirilmiş bir platformun hiper kişiselleştirme nedeniyle gelir artışı sağlamasıdır. Dijital ticaret müşteri beklentilerini, tercihlerini ve davranışlarını daha da yüksekleştirmeye devam ediyor. Gerçek zamanlı katılım, ilgili öneriler ve hiper kişiselleştirme gibi talepler tek bir düğmeye tıklamayla hız ve kolaylık sağlar. Uygulamalarda doğal konuşma, görme vb. aracılığıyla zeka sağlarız. Bu zeka, müşterilerin alışveriş yapma şeklini kesintiye uğratırken değeri artıracak perakende sektöründe iyileştirmeler sağlar.
Bu belge, görsel arama yapay zeka kavramına odaklanır ve uygulanmasıyla ilgili dikkat edilmesi gereken birkaç önemli nokta sunar. Bir iş akışı örneği sağlar ve aşamalarını ilgili Azure teknolojileriyle eşler. Bu kavram, müşterilerin mobil cihazlarıyla çekilen veya İnternet'te bulunan bir görüntüden yararlanabilmesini temel alır. Bu kişiler, deneyimin amacına bağlı olarak ilgili ve benzer öğeler üzerinde arama yapar. Bu nedenle görsel arama, kullanılabilir olan tüm geçerli öğeleri hızla ortaya çıkarabilmek için metinli girişten birden çok meta veri noktasına sahip bir görüntüye olan hızı artırır.
Görsel arama motorları
Görsel arama altyapıları, görüntüleri giriş olarak ve çoğunlukla (ancak yalnızca değil) çıkış olarak kullanarak bilgileri alır.
Motorlar perakende sektöründe giderek daha yaygın hale geliyor ve çok iyi nedenlerden dolayı:
- 2017'de yayınlanan bir Emarketer raporuna göre, internet kullanıcılarının yaklaşık %75'i satın alma işlemi yapmadan önce bir ürünün resimlerini veya videolarını arıyor.
- Slyce (görsel arama şirketi) 2015 raporuna göre, tüketicilerin %74'ünün metin aramalarının verimsiz olduğunu da görüyoruz.
Bu nedenle, Piyasalar ve Piyasalar tarafından yapılan araştırmaya göre, görüntü tanıma pazarı 2019'a kadar 25 milyar dolardan fazla değere sahip olacak.
Teknoloji, gelişimine önemli ölçüde katkıda bulunan büyük e-ticaret markalarını zaten ele almıştır. En öne çıkan erken benimseyenler muhtemelen şunlardır:
- Uygulamalarında Görüntü Arama ve "eBay'de Bul" araçlarıyla eBay (bu şu anda yalnızca bir mobil deneyimdir).
- Lens görsel bulma aracıyla Pinterest.
- Bing Görsel Arama ile Microsoft.
Benimseme ve uyarlama
Neyse ki görsel aramadan kâr elde etmek için çok büyük miktarda bilgi işlem gücüne ihtiyacınız yoktur. Görüntü kataloğu olan tüm işletmeler, Microsoft'un Azure hizmetlerinde yerleşik olarak bulunan yapay zeka uzmanlığından yararlanabilir.
Bing Görsel Arama API'si, görüntülerden bağlam bilgilerini ayıklamanın, örneğin ev mobilyalarını, modayı, çeşitli ürün türlerini vb. tanımlamanın bir yolunu sağlar.
Ayrıca görsel olarak benzer görüntüleri kendi kataloğundan, göreli alışveriş kaynaklarına sahip ürünlerden ve ilgili aramalardan döndürür. İlginç olsa da, şirketiniz bu kaynaklardan biri değilse bu sınırlı kullanım olacaktır.
Bing şunları da sağlar:
- Görüntüde bulunan nesneleri veya kavramları keşfetmenizi sağlayan etiketler.
- Resimdeki ilgi çekici bölgeler için sınırlayıcı kutular (örneğin, giyim veya mobilya öğeleri için).
Arama alanını (ve süresini) bir şirketin ürün kataloğuna önemli ölçüde daraltarak bölge ve ilgi alanı kategorisindeki nesnelerle kısıtlamak için bu bilgileri alabilirsiniz.
Kendi uygulamanızı uygulama
Görsel arama uygularken dikkate alınması gereken birkaç önemli bileşen vardır:
- Görüntüleri alma ve filtreleme
- Depolama ve alma teknikleri
- Özellik kazandırma, kodlama veya "karma oluşturma"
- Benzerlik ölçüleri veya mesafeler ve derecelendirme
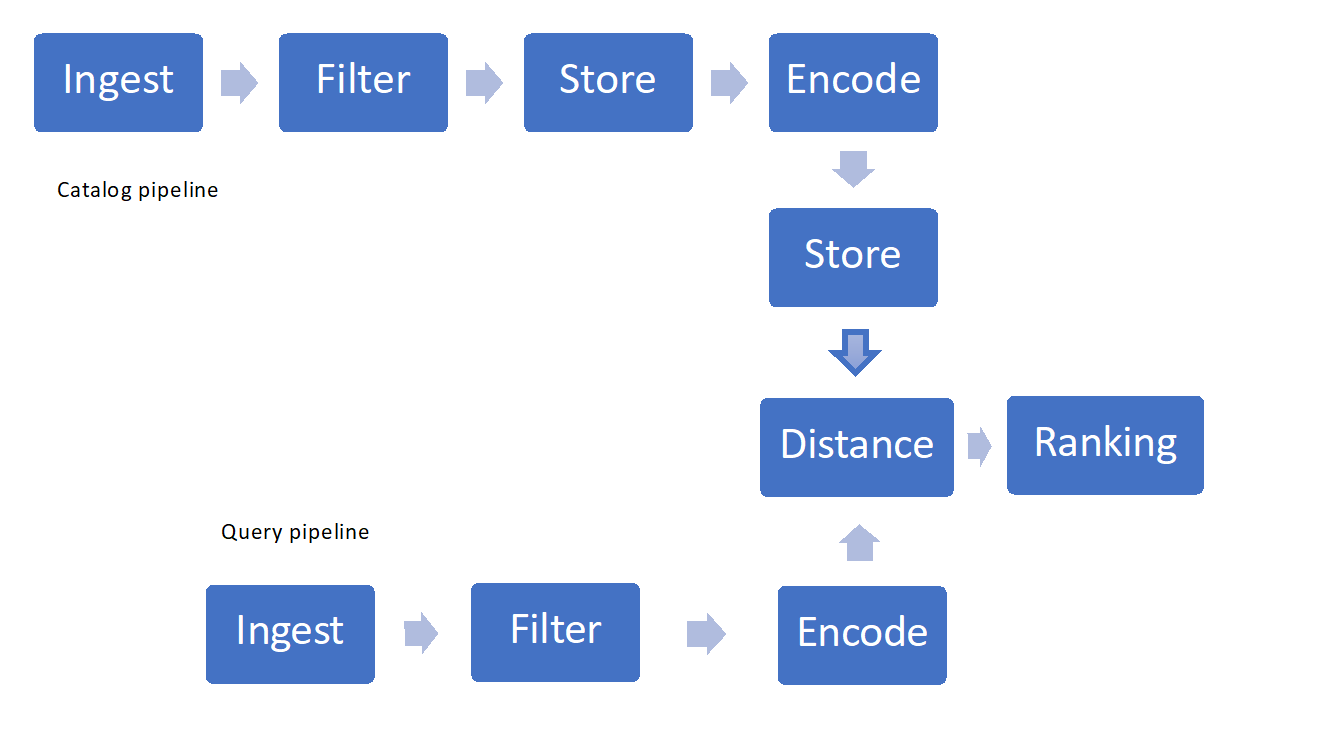
Şekil 1: Görsel Arama İşlem Hattı Örneği
Resimlerin kaynağını belirleme
Bir resim kataloğuna sahip değilseniz, algoritmaları moda MNIST'i, derin moda gibi açık kullanılabilir veri kümelerinde eğitmeniz gerekebilir. Bunlar çeşitli ürün kategorileri içerir ve genellikle görüntü kategorilerini ve arama algoritmalarını karşılaştırmak için kullanılır.

Şekil 2: DeepFashion veri kümesinden bir örnek
Görüntüleri filtreleme
Daha önce bahsedilenler gibi karşılaştırma veri kümelerinin çoğu önceden işlenmiştir.
Kendi karşılaştırmanızı oluşturursanız, en azından tüm görüntülerin aynı boyutta olmasını ve çoğunlukla modelinizin eğitilmiş olduğu giriş tarafından dikte edilmiş olmasını istersiniz.
Çoğu durumda, görüntülerin parlaklığını normalleştirmek de en iyisidir. Aramanızın ayrıntı düzeyine bağlı olarak, renk yedekli bilgiler de olabilir, bu nedenle siyah beyaza küçültmek işlem sürelerinde yardımcı olur.
Son olarak, görüntü veri kümesinin temsil ettiği farklı sınıflar arasında dengelenmesi gerekir.
Görüntü veritabanı
Veri katmanı, mimarinizin özellikle hassas bir bileşenidir. Bu, şu içeriği içerir:
- Görüntüler
- Görüntülerle ilgili meta veriler (boyut, etiketler, ürün SKU'ları, açıklama)
- Makine öğrenmesi modeli tarafından oluşturulan veriler (örneğin, görüntü başına 4096 öğeli sayısal vektör)
Farklı kaynaklardan görüntü aldıkça veya en iyi performans için çeşitli makine öğrenmesi modelleri kullandığınızda verilerin yapısı değişir. Bu nedenle, yarı yapılandırılmış verilerle başa çıkabilen ve sabit şema içermeyen bir teknoloji veya birleşim seçmek önemlidir.
Ayrıca en az sayıda yararlı veri noktası (görüntü tanımlayıcısı veya anahtarı, ürün sku'su, açıklama veya etiket alanı gibi) gerektirebilirsiniz.
Azure Cosmos DB , üzerinde oluşturulan uygulamalar için gerekli esnekliği ve çeşitli erişim mekanizmalarını sunar (bu, katalog aramanıza yardımcı olur). Ancak, en iyi fiyatı/performansı sağlamak için dikkatli olmak gerekir. Azure Cosmos DB, belge eklerinin depolanmasına izin verir, ancak hesap başına toplam sınır vardır ve bu yüksek maliyetli bir teklif olabilir. Gerçek görüntü dosyalarını bloblarda depolamak ve veritabanına bunlara bağlantı eklemek yaygın bir uygulamadır. Azure Cosmos DB söz konusu olduğunda bu, söz konusu görüntüyle ilişkili katalog özelliklerini (SKU, etiket vb.) ve görüntü dosyasının URL'sini içeren bir ek (örneğin, Azure Blob depolama, OneDrive vb.) içeren bir belge oluşturmak anlamına gelir.
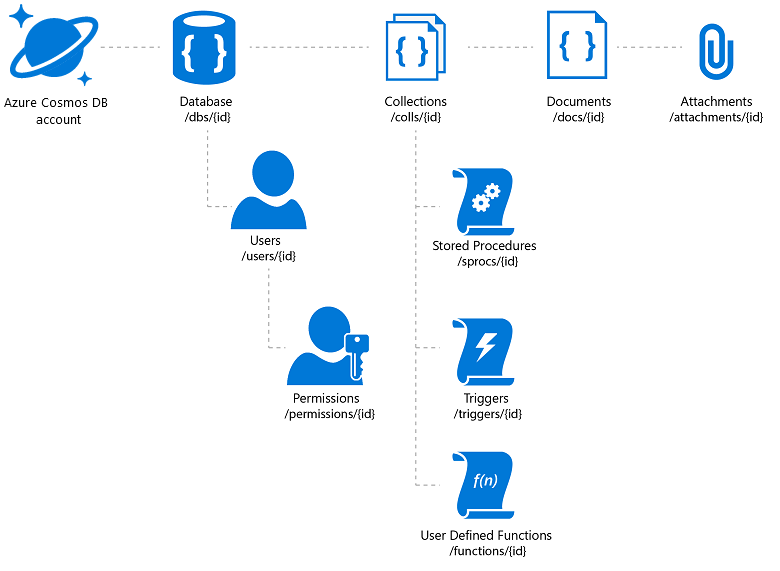
Şekil 3: Azure Cosmos DB Hiyerarşik Kaynak Modeli
Azure Cosmos DB'nin genel dağıtımından yararlanmayı planlıyorsanız, bunun bağlantılı dosyaları değil belgeleri ve ekleri çoğaltacağını unutmayın. Bunlar için bir içerik dağıtım ağı kullanmayı düşünebilirsiniz.
Diğer geçerli teknolojiler, Azure SQL Veritabanı (sabit şema kabul edilebilirse) ve blobların, hatta ucuz ve hızlı depolama ve alma için Azure Tablolarının ve bloblarının birleşimidir.
Özellik ayıklama ve kodlama
Kodlama işlemi, veritabanındaki resimlerden tuzlu özellikleri ayıklar ve bunların her birini binlerce bileşene sahip olabilecek seyrek bir "özellik" vektörüyle (birçok sıfır içeren bir vektör) eşler. Bu vektör, resmi karakterize eden özelliklerin (kenarlar ve şekiller gibi) sayısal bir gösterimidir. Koda çok benz.
Özellik ayıklama teknikleri genellikle aktarım öğrenme mekanizmalarını kullanır. Bu durum, önceden eğitilmiş bir sinir ağı seçtiğinizde, her görüntüyü bu ağ üzerinden çalıştırdığınızda ve görüntü veritabanınızda oluşturulan özellik vektörlerini depoladığınızda oluşur. Bu şekilde, ağı eğiten kişiden öğrenmeyi "aktarırsınız". Microsoft, ResNet50 gibi görüntü tanıma görevleri için yaygın olarak kullanılan önceden eğitilmiş birkaç ağ geliştirmiş ve yayımlamıştır.
Sinir ağına bağlı olarak, özellik vektöru az çok uzun ve seyrek olacaktır, bu nedenle bellek ve depolama gereksinimleri farklılık gösterir.
Ayrıca, farklı ağların farklı kategoriler için geçerli olduğunu fark edebilirsiniz, bu nedenle görsel aramanın uygulanması aslında farklı boyutta özellik vektörleri oluşturabilir.
Önceden eğitilmiş sinir ağlarının kullanımı nispeten kolaydır, ancak görüntü kataloğunuzda eğitilen özel bir model kadar verimli olmayabilir. Bu önceden eğitilmiş ağlar genellikle belirli görüntü koleksiyonunuzu aramak yerine karşılaştırma veri kümelerinin sınıflandırılması için tasarlanmıştır.
Arama alanını kısıtlamak, bellek ve depolama gereksinimlerini azaltmak için çok yararlı olacak, hem kategori tahmini hem de yoğun (daha küçük, seyrek değil) vektör oluşturmaları için bunları değiştirmek ve yeniden eğitmek isteyebilirsiniz. İkili vektörler kullanılabilir ve genellikle belge kodlama ve alma tekniklerinden türetilen bir terim olan " semantik karma" olarak adlandırılır. İkili gösterim daha fazla hesaplamayı basitleştirir.

Şekil 4: Görsel Arama için ResNet Değişiklikleri – F. Yang ve diğerleri, 2017
İster önceden eğitilmiş modelleri seçin ister kendi modelinizi geliştirin, yine de modelin özellik kazandırma ve/veya eğitimini nerede çalıştırabileceğinize karar vermeniz gerekir.
Azure çeşitli seçenekler sunar: VM'ler, Azure Batch, Batch AI, Databricks kümeleri. Ancak her durumda en iyi fiyat/performans GPU kullanımıyla verilir.
Microsoft kısa süre önce GPU maliyetinin (Brainwave projesi) bir bölümünde hızlı hesaplama için FPGA'ların kullanılabilirliğini duyurdu. Ancak, yazma sırasında bu teklif belirli ağ mimarileriyle sınırlıdır, bu nedenle performanslarını yakından değerlendirmeniz gerekir.
Benzerlik ölçüsü veya uzaklığı
Görüntüler özellik vektör alanında temsil edildiğinde benzerlikleri bulmak, bu tür bir boşluktaki noktalar arasında bir mesafe ölçüsü tanımlama sorununa dönüşür. Bir uzaklık tanımlandıktan sonra, benzer görüntülerin kümelerini hesaplayabilir ve/veya benzerlik matrisleri tanımlayabilirsiniz. Seçilen mesafe ölçümüne bağlı olarak sonuçlar farklılık gösterebilir. Örneğin gerçek sayı vektörlerine göre en yaygın Öklid mesafe ölçüsünü anlamak kolaydır: mesafenin büyüklüğünü yakalar. Ancak, hesaplama açısından oldukça verimsizdir.
Kosinüs uzaklığı genellikle vektörün büyüklüğü yerine yönünü yakalamak için kullanılır.
İkili gösterimler üzerinde Hamming uzaklığı gibi alternatifler verimlilik ve hız için bazı doğruluk ticaret.
Vektör boyutu ve uzaklık ölçüsünün birleşimi, aramanın ne kadar yoğun ve yoğun bellek kullanımlı olacağını belirler.
Arama ve derecelendirme
Benzerlik tanımlandıktan sonra, giriş olarak geçirilene en yakın N öğelerini almak ve ardından tanımlayıcıların listesini döndürmek için verimli bir yöntem tanımlamamız gerekir. Bu, "görüntü derecelendirme" olarak da bilinir. Büyük bir veri kümesinde, her uzaklığı hesaplama süresi engelleyicidir, bu nedenle yaklaşık en yakın komşu algoritmaları kullanırız. Bunlar için çeşitli açık kaynak kitaplıklar vardır, bu nedenle bunları sıfırdan kodlamanız gerekmez.
Son olarak, bellek ve hesaplama gereksinimleri eğitilen model için dağıtım teknolojisi seçimini ve yüksek kullanılabilirliği belirler. Genellikle, arama alanı bölümlenir ve derecelendirme algoritmasının birkaç örneği paralel olarak çalışır. Ölçeklenebilirlik ve kullanılabilirlik sağlayan seçeneklerden biri Azure Kubernetes kümeleridir. Bu durumda, derecelendirme modelini birkaç kapsayıcıya (arama alanının bir bölümünü işleme) ve birkaç düğüme (yüksek kullanılabilirlik için) dağıtmanız önerilir.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Giovanni Marchetti | Yönetici, Azure Çözüm Mimarları
- Mariya Zorotovich | Müşteri Deneyimi Başkanı, HLS & Gelişen Teknoloji
Diğer katkıda bulunanlar:
- Scott Seely | Yazılım Mimarı
Sonraki adımlar
Görsel arama uygulamak karmaşık bir şey değildir. Microsoft'un yapay zeka araştırma ve araçlarından yararlanırken Bing'i kullanabilir veya Azure hizmetleriyle kendi hizmetlerinizi oluşturabilirsiniz.
Geliştirme
- Özelleştirilmiş hizmet oluşturmaya başlamak için bkz . Bing Görsel Arama API'sine Genel Bakış
- İlk isteğinizi oluşturmak için hızlı başlangıçlara bakın: C# | Java | Node.js Python |
- Görsel Arama API'si Başvurusu'nu inceleyin.
Background
- Derin Öğrenme Görüntü Segmentasyonu: Microsoft makalesinde görüntüleri arka planlardan ayırma işlemi açıklanmaktadır
- Ebay'de Görsel Arama: Cornell Üniversitesi araştırması
- Pinterest Cornell Üniversitesi araştırmasında Görsel Keşif
- Semantik Hashing University of Toronto araştırması