Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği yüksek kullanılabilirlik
Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği Kubernetes'te kapsayıcılı uygulama olarak dağıtılır. Yerleşik sağlamak için durum bilgisi olan kümeler ve kalıcı depolama gibi Kubernetes yapılarını kullanır:
- Sistem durumunu izleme
- Hata algılama
- Hizmet durumunu korumak için otomatik yük devretme.
Daha fazla güvenilirlik için Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği yüksek kullanılabilirlik yapılandırmasında ek çoğaltmalarla dağıtılacak şekilde de yapılandırabilirsiniz. Arc veri hizmetleri veri denetleyicisi aşağıdakileri yönetir:
- İzleme
- Hata algılama
- Otomatik yük devretme
Arc özellikli veri hizmeti, kullanıcı müdahalesi olmadan bu hizmeti sağlar. Hizmet:
- Kullanılabilirlik grubunu ayarlar
- Veritabanı yansıtma uç noktalarını yapılandırıyor
- Kullanılabilirlik grubuna veritabanları ekler
- Yük devretme ve yükseltmeyi koordine eder.
Bu belgede her iki yüksek kullanılabilirlik türü de incelenmiştir.
Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği, SQL yönetilen örneğinin bir olarak dağıtılıp dağıtılmadığına bağlı olarak farklı yüksek kullanılabilirlik düzeyleri sağlarGenel Amaçlı hizmet katmanı veya İş Açısından Kritik hizmet katmanı.
Genel Amaçlı hizmet katmanında yüksek kullanılabilirlik
Genel Amaçlı hizmet katmanında yalnızca bir çoğaltma kullanılabilir ve yüksek kullanılabilirlik Kubernetes düzenlemesi aracılığıyla sağlanır. Örneğin, yönetilen örnek kapsayıcı görüntüsünü içeren bir pod veya düğüm kilitlenirse, Kubernetes başka bir pod veya düğümü kaldırmaya çalışır ve aynı kalıcı depolama alanına bağlanır. Bu süre boyunca SQL yönetilen örneği uygulamalar tarafından kullanılamaz. Yeni pod çalışırken uygulamaların yeniden bağlanması ve işlemi yeniden denemesi gerekir. Kullanılan hizmet türü ise load balancer uygulamalar aynı birincil uç noktaya yeniden bağlanabilir ve Kubernetes bağlantıyı yeni birincil sunucuya yönlendirir. Hizmet türü ise nodeport uygulamaların yeni IP adresine yeniden bağlanması gerekir.
Yerleşik yüksek kullanılabilirliği doğrulama
Kubernetes tarafından sağlanan yerleşik yüksek kullanılabilirliği doğrulamak için şunları yapabilirsiniz:
- Mevcut yönetilen örneğin podunu silme
- Kubernetes'in bu eylemden kurtarıldığını doğrulayın
Kurtarma sırasında Kubernetes başka bir podu önyükler ve kalıcı depolamayı ekler.
Önkoşullar
- Kubernetes kümesi paylaşılan, uzak depolama gerektirir
- Azure Arc tarafından etkinleştirilen ve tek bir çoğaltmayla dağıtılan bir SQL Yönetilen Örneği (varsayılan)
Podları görüntüleyin.
kubectl get pods -n <namespace of data controller>Yönetilen örnek podunu silin.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Örneğin:
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedYönetilen örneğin kurtarıldığını doğrulamak için podları görüntüleyin.
kubectl get pods -n <namespace of data controller>Örneğin:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Pod içindeki tüm kapsayıcılar kurtarıldıktan sonra yönetilen örneğe bağlanabilirsiniz.
İş Açısından Kritik hizmet katmanında yüksek kullanılabilirlik
İş Açısından Kritik hizmet katmanında Kubernetes düzenlemesi tarafından yerel olarak sağlananlara ek olarak Azure Arc için SQL Yönetilen Örneği, kapsanan bir kullanılabilirlik grubu sağlar. İçerilen kullanılabilirlik grubu SQL Server Always On teknolojisi üzerine kurulmuştur. Daha yüksek kullanılabilirlik düzeyleri sağlar. İş Açısından Kritik hizmet katmanıyla dağıtılan Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği 2 veya 3 çoğaltma ile dağıtılabilir. Bu çoğaltmalar her zaman birbiriyle eşitlenmiş olarak tutulur.
Kapsanan kullanılabilirlik gruplarında pod kilitlenmeleri veya düğüm hataları uygulama için saydamdır. Kapsanan kullanılabilirlik grubu, birincil verilerden tüm verileri içeren ve bağlantıları almaya hazır olan en az bir pod daha sağlar.
Kapsanan kullanılabilirlik grupları
Kullanılabilirlik grubu bir veya daha fazla kullanıcı veritabanını mantıksal bir gruba bağlar, böylece yük devretme olduğunda veritabanları grubunun tamamı ikincil çoğaltmaya tek bir birim olarak yük devreder. Kullanılabilirlik grubu yalnızca kullanıcı veritabanlarındaki verileri çoğaltır, ancak oturum açma bilgileri, izinler veya aracı işleri gibi sistem veritabanlarındaki verileri çoğaltmaz. Kapsanan kullanılabilirlik grubu, ve master gibi msdb sistem veritabanlarından meta veriler içerir. Birincil çoğaltmada oturum açma bilgileri oluşturulduğunda veya değiştirildiğinde, bunlar ikincil çoğaltmalarda da otomatik olarak oluşturulur. Benzer şekilde, birincil çoğaltmada bir aracı işi oluşturulduğunda veya değiştirildiğinde, ikincil çoğaltmalar da bu değişiklikleri alır.
Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği bu kapsanan kullanılabilirlik grubu kavramını alır ve kubernetes işlecini ekler, böylece bunlar büyük ölçekte dağıtılabilir ve yönetilebilir.
Kullanılabilirlik gruplarını içeren özellikler aşağıdakileri etkinleştirir:
Birden çok çoğaltmayla dağıtıldığında Arc özellikli SQL yönetilen örneğiyle aynı ada sahip adlı tek bir kullanılabilirlik grubu oluşturulur. Varsayılan olarak, kapsanan AG'nin birincil de dahil olmak üzere üç çoğaltması vardır. Kullanılabilirlik grubu için tüm CRUD işlemleri, kullanılabilirlik grubu oluşturma veya çoğaltmaları oluşturulan kullanılabilirlik grubuna birleştirme dahil olmak üzere dahili olarak yönetilir. Bir örnekte daha fazla kullanılabilirlik grubu oluşturamazsınız.
ve gibi
mastermsdbtüm kullanıcı ve sistem veritabanları dahil olmak üzere tüm veritabanları otomatik olarak kullanılabilirlik grubuna eklenir. Bu özellik, kullanılabilirlik grubu çoğaltmaları genelinde tek sistemli bir görünüm sağlar. Doğrudan örneğe bağlanıyorsanız hem hem decontainedag_mastercontainedag_msdbveritabanlarına dikkat edin.containedag_*Veritabanları kullanılabilirlik grubunun içindeki vemsdbdeğerlerini temsil edermaster.Kullanılabilirlik grubundaki veritabanlarına bağlanmak için otomatik olarak bir dış uç nokta sağlanır. Bu uç nokta
<managed_instance_name>-external-svc, kullanılabilirlik grubu dinleyicisinin rolünü oynar.
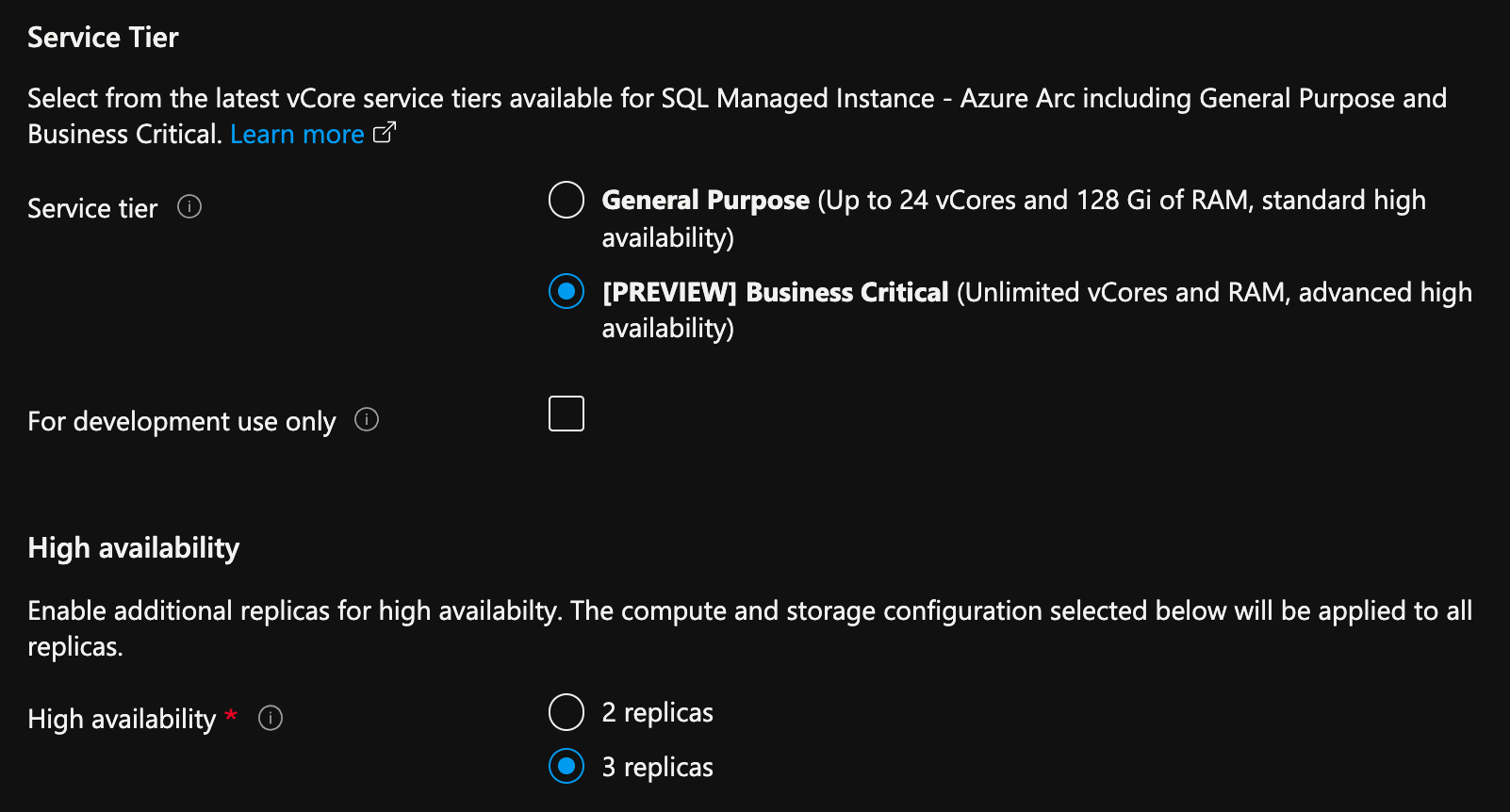
Azure portalını kullanarak Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği birden çok çoğaltmayla dağıtma
Azure portalında, Azure Arc tarafından etkinleştirilen oluşturma SQL Yönetilen Örneği sayfasında:
- İşlem + Depolama altında İşlem + Depolamayı Yapılandır'ı seçin. Portalda gelişmiş ayarlar gösterilir.
- Hizmet katmanı'nın altında İş Açısından Kritik'ı seçin.
- Geliştirme amacıyla kullanılıyorsa "Yalnızca geliştirme amaçlı kullanım için" seçeneğini işaretleyin.
- Yüksek kullanılabilirlik'in altında 2 çoğaltma veya 3 çoğaltma seçin.
Azure CLI kullanarak birden çok çoğaltmayla dağıtma
Azure Arc tarafından etkinleştirilen bir SQL Yönetilen Örneği İş Açısından Kritik hizmet katmanında dağıtıldığında dağıtım birden çok çoğaltma oluşturur. Bu örnekler arasında kapsanan kullanılabilirlik gruplarının kurulumu ve yapılandırması sağlama sırasında otomatik olarak gerçekleştirilir.
Örneğin, aşağıdaki komut 3 çoğaltmalı bir yönetilen örnek oluşturur.
Dolaylı olarak bağlı mod:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Örnek:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Doğrudan bağlı mod:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Örnek:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Varsayılan olarak, tüm çoğaltmalar zaman uyumlu modda yapılandırılır. Bu, birincil örnekteki tüm güncelleştirmelerin ikincil örneklerin her birine zaman uyumlu olarak çoğaltıldığı anlamına gelir.
Yüksek kullanılabilirlik durumunu görüntüleme ve izleme
Dağıtım tamamlandıktan sonra SQL Server Management Studio'dan birincil uç noktaya bağlanın.
Birincil çoğaltmanın uç noktasını doğrulayın ve alın ve SQL Server Management Studio'dan buna bağlanın.
Örneğin, SQL örneği kullanılarak service-type=loadbalancerdağıtıldıysa, bağlanılacak uç noktayı almak için aşağıdaki komutu çalıştırın:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
veya
kubectl get sqlmi -A
Birincil ve ikincil uç noktaları ve AG durumunu alma
kubectl describe sqlmi Birincil ve ikincil uç noktaları ve yüksek kullanılabilirlik durumunu görüntülemek için veya az sql mi-arc show komutlarını kullanın.
Örnek:
kubectl describe sqlmi sqldemo -n my-namespace
veya
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Örnek çıkış:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
SQL Server Management Studio ile birincil uç noktaya bağlanabilir ve DMV'leri şu şekilde doğrulayabilirsiniz:
SELECT * FROM sys.dm_hadr_availability_replica_states
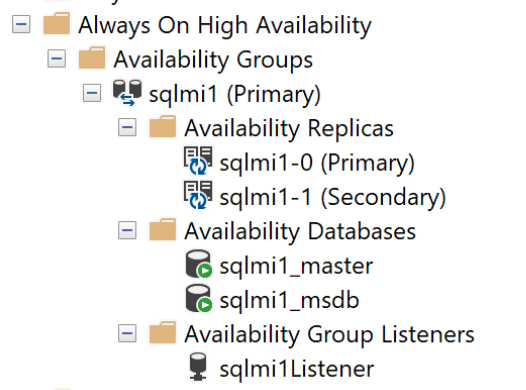
Ve Kapsanan Kullanılabilirlik Panosu:
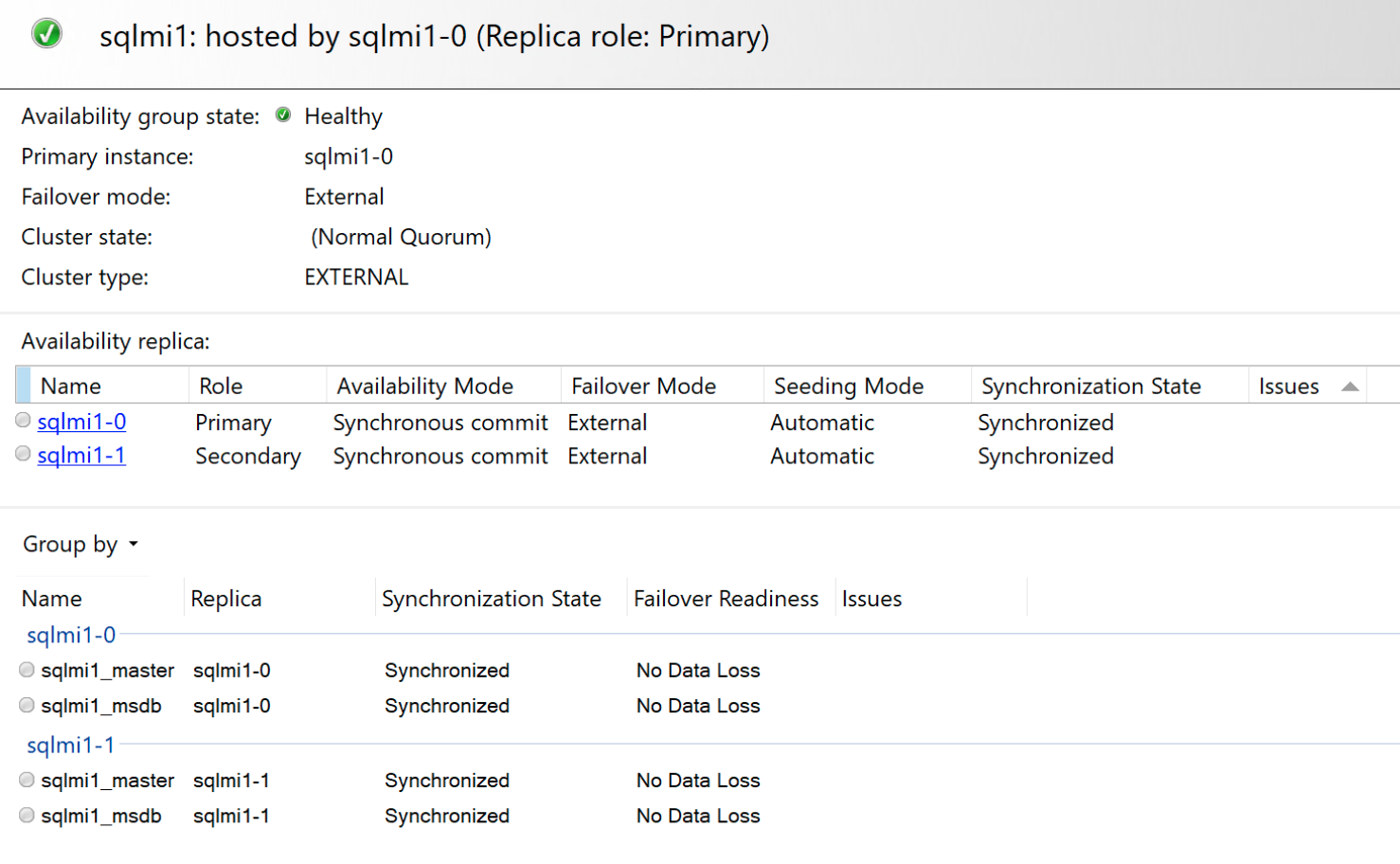
Yük devretme senaryoları
SQL Server Always On kullanılabilirlik gruplarının aksine, kapsanan kullanılabilirlik grubu yönetilen bir yüksek kullanılabilirlik çözümüdür. Bu nedenle, yük devretme modları SQL Server Always On kullanılabilirlik gruplarında kullanılabilen tipik modlarla karşılaştırıldığında sınırlıdır.
İki çoğaltmalı yapılandırmada veya üç çoğaltma yapılandırmasında İş Açısından Kritik hizmet katmanı SQL yönetilen örneklerini dağıtın. Hataların etkileri ve sonraki kurtarılabilirlik her yapılandırmada farklıdır. Üç çoğaltma örneği, iki çoğaltma örneğinden daha yüksek düzeyde kullanılabilirlik ve kurtarma sağlar.
İki çoğaltma yapılandırmasında, her iki düğüm durumu SYNCHRONIZEDda olduğunda, birincil çoğaltma kullanılamaz duruma gelirse, ikincil çoğaltma otomatik olarak birincil çoğaltmaya yükseltilir. Başarısız çoğaltma kullanılabilir duruma geldiğinde, bekleyen tüm değişikliklerle güncelleştirilir. Çoğaltmalar arasında bağlantı sorunları varsa, birincil çoğaltmada bir başarı geri döndürülmeden önce her işlemin her iki çoğaltmada da işlenmesi gerektiğinden, birincil çoğaltma herhangi bir işlem işlemeyebilir.
Üç çoğaltma yapılandırmasında, bir işlemin uygulamaya bir başarı iletisi döndürmeden önce 3 çoğaltmadan en az 2'sinde işlemesi gerekir. Hata durumunda kubernetes başarısız çoğaltmayı kurtarmayı denerken ikincillerden biri otomatik olarak birincile yükseltilir. Çoğaltma kullanılabilir olduğunda, otomatik olarak kapsanan kullanılabilirlik grubuyla birleştirilir ve bekleyen değişiklikler eşitlenir. Çoğaltmalar arasında bağlantı sorunları varsa ve 2'den fazla çoğaltma eşitlenmemişse, birincil çoğaltma hiçbir işlem işlemez.
Not
Sıfıra yakın veri kaybına ulaşmak için iki çoğaltma yapılandırmasından daha fazla üç çoğaltma yapılandırmasında bir İş Açısından Kritik SQL Yönetilen Örneği dağıtmanız önerilir.
Birincil çoğaltmadan ikincillerden birine yük devretmek için, planlı bir olay için aşağıdaki komutu çalıştırın:
Birincil sunucuya bağlanırsanız, SQL örneğinin yükünü ikincillerden birine devretmek için aşağıdaki T-SQL'i kullanabilirsiniz:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
İkincil sunucuya bağlanırsanız, istenen ikincil çoğaltmayı birincil çoğaltmaya yükseltmek için aşağıdaki T-SQL'i kullanabilirsiniz.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Tercih edilen birincil çoğaltma
Ayrıca, AZ CLI kullanarak belirli bir çoğaltmayı birincil çoğaltma olarak aşağıdaki gibi ayarlayabilirsiniz:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Örnek:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Not
Kubernetes tercih edilen çoğaltmayı ayarlamaya çalışır, ancak bu garanti değildir.
Veritabanını çok çoğaltmalı örneğe geri yükleme
Veritabanını kullanılabilirlik grubuna geri yüklemek için ek adımlar gerekir. Aşağıdaki adımlarda bir veritabanının yönetilen örneğe nasıl geri yükleneceği ve kullanılabilirlik grubuna nasıl ekleneceği gösterilmektedir.
Yeni bir Kubernetes hizmeti oluşturarak birincil örnek dış uç noktasını kullanıma sunma.
Birincil çoğaltmayı barındıran podu belirleyin. Yönetilen örneğe bağlanın ve şu komutu çalıştırın:
SELECT @@SERVERNAMESorgu, birincil çoğaltmayı barındıran podu döndürür.
Kubernetes kümeniz hizmetleri kullanıyorsa
NodePortaşağıdaki komutu çalıştırarak Birincil örneğe Kubernetes hizmetini oluşturun. değerini önceki adımda döndürülen sunucunun adıyla,<serviceName>kubernetes hizmeti için tercih edilen adla değiştirin<podName>.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortBir LoadBalancer hizmeti için, oluşturulan
LoadBalancerhizmetin türü olması dışında aynı komutu çalıştırın. Örneğin:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerAzure Kubernetes Service'e karşı çalıştırılacak bu komutun bir örneği aşağıda verilmiştir ve burada birincili barındıran pod şöyledir
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerKubernetes hizmetinin IP'sini oluşturun:
kubectl get services -n <namespaceName>Veritabanını birincil örnek uç noktasına geri yükleyin.
Veritabanı yedekleme dosyasını birincil örnek kapsayıcısına ekleyin.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Örnek
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcAşağıdaki komutu çalıştırarak veritabanı yedekleme dosyasını geri yükleyin.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOÖrnek
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOveritabanını kullanılabilirlik grubuna ekleyin.
Veritabanının AG'ye eklenmesi için tam kurtarma modunda çalışması ve günlük yedeklemesinin alınması gerekir. Geri yüklenen veritabanını kullanılabilirlik grubuna eklemek için aşağıdaki TSQL deyimlerini çalıştırın.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>Aşağıdaki örnek, örneğe geri yüklenen adlı
WideWorldImportersbir veritabanı ekler:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Önemli
En iyi yöntem olarak, şu komutu çalıştırarak yukarıda oluşturulan Kubernetes hizmetini silmeniz gerekir:
kubectl delete svc sql2-0-p -n arc
Sınırlamalar
Azure Arc kullanılabilirlik grupları tarafından etkinleştirilen SQL Yönetilen Örneği, Büyük Veri Kümesi kullanılabilirlik gruplarıyla aynı sınırlamalara sahiptir. Daha fazla bilgi için bkz . Sql Server Büyük Veri Kümesini yüksek kullanılabilirlikle dağıtma.
İlgili içerik
Azure Arc tarafından etkinleştirilen SQL Yönetilen Örneği Özellikleri ve Özellikleri hakkında daha fazla bilgi edinin