Dinamik yönetim görünümlerini kullanarak Azure SQL Veritabanı performansını izleme
Şunlar için geçerlidir: ![]() Azure SQL Veritabanı
Azure SQL Veritabanı
İş yükü performansını izlemek ve engellenen veya uzun süre çalışan sorgular, kaynak performans sorunları, yetersiz sorgu planları ve daha fazlası nedeniyle ortaya çıkan performans sorunlarını tanılamak için dinamik yönetim görünümlerini (DMV' ler) kullanabilirsiniz.
Bu makalede, T-SQL aracılığıyla dinamik yönetim görünümlerini sorgulayarak yaygın performans sorunlarını algılama hakkında bilgi sağlanır. Aşağıdakiler gibi herhangi bir sorgu aracını kullanabilirsiniz:
İzinler
Azure SQL Veritabanı işlem boyutuna, dağıtım seçeneğine ve DMV'deki verilere bağlı olarak, DMV'yi sorgulamak için , veya veya VIEW SERVER PERFORMANCE STATEveya VIEW SERVER SECURITY STATE izni gerekebilirVIEW DATABASE STATE. İzine son iki izin eklenir VIEW SERVER STATE . Sunucu durumunu görüntüleme izinleri, ilgili sunucu rollerindeki üyelik aracılığıyla verilir. Belirli bir DMV'yi sorgulamak için hangi izinlerin gerekli olduğunu belirlemek için dinamik yönetim görünümlerine bakın ve DMV'yi açıklayan makaleyi bulun.
Bir veritabanı kullanıcısına VIEW DATABASE STATE izin vermek için aşağıdaki sorguyu çalıştırın ve yerine database_user veritabanındaki kullanıcı sorumlusunun adını yazın:
GRANT VIEW DATABASE STATE TO [database_user];
Mantıksal sunucuda adlı login_name oturum açma bilgilerine sunucu rolü üyeliği ##MS_ServerStateReader## vermek için veritabanına bağlanın master ve örnek olarak aşağıdaki sorguyu çalıştırın:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
İzin verme işleminin geçerlilik kazanması birkaç dakika sürebilir. Daha fazla bilgi için bkz . Sunucu düzeyinde rollerin sınırlamaları.
Kaynak kullanımını izleme
Aşağıdaki görünümleri kullanarak veritabanı düzeyinde kaynak kullanımını izleyebilirsiniz. Bu görünümler tek başına veritabanları ve elastik havuzdaki veritabanları için geçerlidir.
Aşağıdaki görünümleri kullanarak elastik havuz düzeyinde kaynak kullanımını izleyebilirsiniz:
Azure portalında SQL Veritabanı Sorgu Performansı İçgörüleri'ni kullanarak veya Sorgu Deposu aracılığıyla sorgu düzeyinde kaynak kullanımını izleyebilirsiniz.
sys.dm_db_resource_stats
her veritabanında sys.dm_db_resource_stats görünümünü kullanabilirsiniz. Görünüm, sys.dm_db_resource_stats işlem boyutunun sınırlarına göre son kaynak kullanım verilerini gösterir. Sınıra doğru CPU, veri G/Ç, günlük yazma, çalışan iş parçacıkları ve bellek kullanımı yüzdeleri her 15 saniyelik aralıkta kaydedilir ve yaklaşık bir saat boyunca tutulur.
Bu görünüm ayrıntılı kaynak kullanım verileri sağladığından, önce geçerli durum çözümlemeleri veya sorun giderme işlemleri için kullanın sys.dm_db_resource_stats . Örneğin, bu sorgu son bir saat içindeki geçerli veritabanı için ortalama ve en yüksek kaynak kullanımını gösterir:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
Diğer sorgular için sys.dm_db_resource_stats'deki örneklere bakın.
sys.resource_stats
Veritabanındaki master sys.resource_stats görünümü, veritabanınızın performansını belirli hizmet katmanında ve işlem boyutunda izlemenize yardımcı olabilecek ek bilgilere sahiptir. Veriler 5 dakikada bir toplanır ve yaklaşık 14 gün boyunca tutulur. Bu görünüm, veritabanınızın kaynakları nasıl kullandığına ilişkin daha uzun vadeli bir geçmiş analizi için kullanışlıdır.
Aşağıdaki grafikte, haftada bir saat için P2 işlem boyutuna sahip bir Premium veritabanı için CPU kaynağı kullanımı gösterilmektedir. Bu grafik Pazartesi günü başlar, beş iş günü gösterir ve ardından uygulamada çok daha az olduğu bir hafta sonu gösterir.
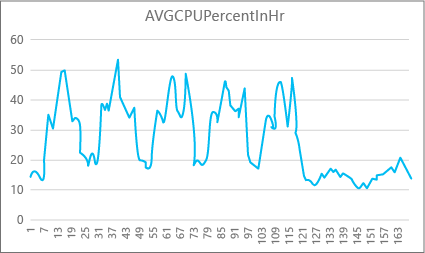
Verilerden bu veritabanı şu anda P2 işlem boyutuna göre (Salı günü öğle) göre yüzde 50'nin üzerinde CPU kullanımına sahip en yüksek CPU yüküne sahiptir. Cpu, uygulamanın kaynak profilindeki baskın faktörse, iş yükünün her zaman uygun olduğunu garanti etmek için P2'nin doğru işlem boyutu olduğuna karar vekleyebilirsiniz. Bir uygulamanın zaman içinde büyümesini bekliyorsanız, uygulamanın performans düzeyi sınırına ulaşmaması için ek kaynak arabelleğine sahip olmak iyi bir fikirdir. İşlem boyutunu artırırsanız, özellikle gecikme süresine duyarlı ortamlarda bir veritabanının istekleri etkili bir şekilde işlemek için yeterli gücü olmadığında ortaya çıkabilecek müşteri görünür hatalarından kaçınmaya yardımcı olabilirsiniz.
Diğer uygulama türleri için aynı grafiği farklı yorumlayabilirsiniz. Örneğin, bir uygulama her gün bordro verilerini işlemeye çalışırsa ve aynı grafiğe sahipse, bu tür bir "toplu iş" modeli P1 işlem boyutunda iyi olabilir. P1 işlem boyutu, P2 işlem boyutundaki 200 DTU ile karşılaştırıldığında 100 DTU'ya sahiptir. P1 işlem boyutu, P2 işlem boyutunun performansının yarısını sağlar. Bu nedenle, P2'de CPU kullanımının yüzde 50'si P1'de yüzde 100 CPU kullanımına eşittir. Uygulamanın zaman aşımları yoksa, bir işin tamamlanmasının 2 saat veya 2,5 saat sürmesi (bugün yapılması durumunda) önemli olmayabilir. Bu kategorideki bir uygulama büyük olasılıkla P1 işlem boyutu kullanabilir. Gün içinde kaynak kullanımının daha düşük olduğu zaman aralıkları olduğundan yararlanabilirsiniz, böylece herhangi bir "büyük tepe" günün ilerleyen saatlerinde oluklardan birine taşabilir. P1 işlem boyutu, işlerin her gün zamanında bitebileceği sürece bu tür uygulamalar için iyi olabilir (ve tasarruf edebilirsiniz).
Veritabanı altyapısı, her mantıksal sunucudaki veritabanının sys.resource_stats master görünümünde her etkin veritabanı için tüketilen kaynak bilgilerini kullanıma sunar. Görünümdeki veriler 5 dakikalık aralıklarla toplanır. Bu verilerin tabloda görünmesi birkaç dakika sürebilir, bu nedenle sys.resource_stats gerçek zamanlıya yakın analiz yerine geçmiş çözümleme için daha kullanışlıdır. Veritabanının sys.resource_stats son geçmişini görmek için görünümü sorgulayın ve seçtiğiniz işlem boyutunun gerektiğinde istediğiniz performansı verip vermediğini doğrulayın.
Not
Aşağıdaki örneklerde sorgulamak sys.resource_stats için master veritabanına bağlı olmanız gerekir.
Bu örnekte içindeki sys.resource_statsveriler gösterilir:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
Sonraki örnekte, veritabanınızın kaynakları nasıl kullandığı hakkında bilgi almak için katalog görünümünü kullanabileceğiniz sys.resource_stats farklı yollar gösterilmektedir:
Kullanıcı veritabanı
userdb1için geçen haftanın kaynak kullanımına bakmak için, kendi veritabanı adınızı değiştirerek şu sorguyu çalıştırabilirsiniz:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;İş yükünüzün işlem boyutuna ne kadar uygun olduğunu değerlendirmek için kaynak ölçümlerinin her yönüne göz atmalısınız: CPU, veri G/Ç, günlük yazma, çalışan sayısı ve oturum sayısı. Veritabanının sağlandığı her işlem boyutu için bu kaynak ölçümlerinin ortalama ve en yüksek değerlerini raporlamak için kullanılan
sys.resource_statsdüzeltilmiş bir sorgu aşağıda verilmiştir:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Her kaynak ölçümünün ortalama ve maksimum değerleri hakkındaki bu bilgilerle, iş yükünüzün seçtiğiniz işlem boyutuna ne kadar uygun olduğunu değerlendirebilirsiniz. Genellikle, ortalama değerleri
sys.resource_statshedef boyuta göre kullanmak için iyi bir taban çizgisi sağlar.DTU satın alma modeli veritabanları için:
Örneğin, Standart hizmet katmanını S2 işlem boyutuyla kullanıyor olabilirsiniz. CPU ve G/Ç okuma ve yazma işlemleri için ortalama kullanım yüzdeleri yüzde 40'ın altında, ortalama çalışan sayısı 50'nin altında ve ortalama oturum sayısı 200'ün altındadır. İş yükünüz S1 işlem boyutuna sığabilir. Veritabanınızın çalışan ve oturum sınırlarına uygun olup olmadığını kolayca görebilirsiniz. Veritabanının daha düşük bir işlem boyutuna sığıp sığmadığını görmek için, daha düşük işlem boyutunun DTU sayısını geçerli işlem boyutunuzun DTU sayısına bölün ve ardından sonucu 100 ile çarpın:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Sonuç, yüzde cinsinden iki işlem boyutu arasındaki göreli performans farkıdır. Kaynak kullanımınız bu yüzdeyi geçmezse, iş yükünüz daha düşük işlem boyutuna sığabilir. Ancak, tüm kaynak kullanım değerleri aralıklarına bakmanız ve veritabanı iş yükünüzün daha düşük işlem boyutuna ne sıklıkta sığacağını yüzdeye göre belirlemeniz gerekir. Aşağıdaki sorgu, bu örnekte hesapladığımız yüzde 40 eşiğine göre kaynak boyutu başına sığdırma yüzdesini döndürür:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Veritabanı hizmet katmanınıza bağlı olarak, iş yükünüzün daha düşük işlem boyutuna uygun olup olmadığına karar vekleyebilirsiniz. Veritabanı iş yükü hedefiniz yüzde 99,9 ise ve önceki sorgu üç kaynak boyutu için de yüzde 99,9'dan büyük değerler döndürüyorsa, iş yükünüz büyük olasılıkla daha düşük işlem boyutuna uyar.
Sığdırma yüzdesine bakmak, amacınıza ulaşmak için bir sonraki daha yüksek işlem boyutuna geçmeniz gerekip gerekmediği konusunda da içgörü sağlar. Örneğin, geçen hafta örnek bir veritabanı için CPU kullanımı:
Ortalama CPU yüzdesi En fazla CPU yüzdesi 24.5 100.00 Ortalama CPU, işlem boyutu sınırının yaklaşık dörtte biri kadardır ve bu da veritabanının işlem boyutuna iyi sığar.
DTU satın alma modeli ve sanal çekirdek satın alma modeli veritabanları için:
Maksimum değer, veritabanının işlem boyutu sınırına ulaştığını gösterir. Sonraki daha yüksek işlem boyutuna geçmeniz gerekiyor mu? İş yükünüzün yüzde 100'e kaç kez ulaştığına bakın ve ardından bunu veritabanı iş yükü hedefinizle karşılaştırın.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Bu yüzdeler, iş yükünüzün geçerli işlem boyutuna sığan örnek sayısıdır. Bu sorgu üç kaynak boyutundan herhangi biri için yüzde 99,9'dan küçük bir değer döndürürse, örneklenen ortalama iş yükünüz sınırları aşmış olur. Bir sonraki daha yüksek işlem boyutuna geçmeyi veya veritabanındaki yükü azaltmak için uygulama ayarlama tekniklerini kullanmayı göz önünde bulundurun.
sys.dm_elastic_pool_resource_stats
benzer şekilde sys.dm_db_resource_stats, sys.dm_elastic_pool_resource_stats elastik havuz için son ve ayrıntılı kaynak kullanım verilerini sağlar. Görünüm, belirli bir veritabanı yerine havuzun tamamı için kaynak kullanım verileri sağlamak üzere elastik havuzdaki herhangi bir veritabanında sorgulanabilir. Bu DMV tarafından bildirilen yüzde değerleri elastik havuzun sınırlarına doğrudur ve bu da havuzdaki bir veritabanının sınırlarından daha yüksek olabilir.
Bu örnekte, son 15 dakika içinde geçerli elastik havuz için özetlenmiş kaynak kullanım verileri gösterilmektedir:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Herhangi bir kaynak kullanımının önemli bir süre boyunca %100'e yaklaştığını fark ederseniz, her veritabanının havuz düzeyinde kaynak kullanımına ne kadar katkıda bulunduğunu belirlemek için aynı elastik havuzdaki veritabanları için kaynak kullanımını gözden geçirmeniz gerekebilir.
sys.elastic_pool_resource_stats
benzer şekildesys.resource_stats, veritabanındaki master sys.elastic_pool_resource_stats mantıksal sunucudaki tüm elastik havuzlar için geçmiş kaynak kullanım verileri sağlar. Kullanım eğilimi analizi de dahil olmak üzere son 14 gün içindeki geçmiş izleme için kullanabilirsiniz sys.elastic_pool_resource_stats .
Bu örnekte, geçerli mantıksal sunucudaki tüm elastik havuzlar için son yedi gün içindeki özetlenmiş kaynak kullanım verileri gösterilmektedir. Sorguyu veritabanında yürütür master .
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Eş zamanlı istekler
Geçerli eşzamanlı istek sayısını görmek için bu sorguyu kullanıcı veritabanınızda çalıştırın:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Bu yalnızca tek bir zaman noktasındaki bir anlık görüntüdür. İş yükünüzü ve eşzamanlı istek gereksinimlerinizi daha iyi anlamak için zaman içinde birçok örnek toplamanız gerekir.
Ortalama istek oranı
Bu örnekte, bir zaman aralığında bir veritabanı için veya elastik havuzdaki veritabanları için ortalama istek oranının nasıl bulunacakları gösterilmektedir. Bu örnekte, zaman aralığı 30 saniye olarak ayarlanmıştır. Deyimini değiştirerek WAITFOR DELAY ayarlayabilirsiniz. Bu sorguyu kullanıcı veritabanınızda yürütür. Veritabanı bir elastik havuzdaysa ve yeterli izinlere sahipseniz, sonuçlar elastik havuzdaki diğer veritabanlarını içerir.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Geçerli oturumlar
Geçerli etkin oturum sayısını görmek için veritabanınızda şu sorguyu çalıştırın:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Bu sorgu belirli bir nokta sayısı döndürür. Zaman içinde birden çok örnek toplarsanız oturum kullanımınızı en iyi şekilde anlarsınız.
İsteklerin, oturumların ve çalışanların son geçmişi
Bu örnek, bir veritabanı veya elastik havuzdaki veritabanları için isteklerin, oturumların ve çalışan iş parçacıklarının son geçmiş kullanımını döndürür. Her satır, bir veritabanı için belirli bir noktada kaynak kullanımının anlık görüntüsünü temsil eder. requests_per_second sütunu, ile biten snapshot_timezaman aralığındaki ortalama istek oranıdır. Veritabanı bir elastik havuzdaysa ve yeterli izinlere sahipseniz, sonuçlar elastik havuzdaki diğer veritabanlarını içerir.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Veritabanı ve nesne boyutlarını hesaplama
Aşağıdaki sorgu veritabanınızdaki veri boyutunu döndürür (megabayt cinsinden):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Aşağıdaki sorgu veritabanınızdaki tek tek nesnelerin boyutunu döndürür (megabayt cinsinden):
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
CPU performansı sorunlarını belirleme
Bu bölüm, en çok CPU kullanan sorguları belirlemenize yardımcı olur.
CPU tüketimi uzun süreler için %80'in üzerindeyse, CPU sorununun şu anda mı yoksa geçmişte mi oluştuğuna ilişkin aşağıdaki sorun giderme adımlarını göz önünde bulundurun. Ayrıca en çok CPU kullanan sorguları proaktif olarak belirlemek ve ayarlamak için bu bölümdeki adımları izleyebilirsiniz. Bazı durumlarda CPU tüketimini azaltmak veritabanlarınızın ve elastik havuzlarınızın ölçeğini azaltmanıza ve maliyetlerden tasarruf etmenizi sağlar.
Sorun giderme adımları, elastik havuzdaki tek başına veritabanları ve veritabanları için aynıdır. Kullanıcı veritabanındaki tüm sorguları yürütür.
CPU sorunu şu anda oluşuyor
Sorun şu anda oluşuyorsa iki olası senaryo vardır:
Yüksek CPU'ları birikmeli olarak kullanan tek tek sorguların çoğu
Sorgu karması tarafından en çok kullanılan sorguları belirlemek için aşağıdaki sorguyu kullanın:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
CPU kullanan ve uzun süre çalışan sorgular hala çalışıyor
Bu sorguları tanımlamak için aşağıdaki sorguyu kullanın:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
CPU sorunu geçmişte oluştu
Sorun geçmişte oluştuysa ve kök neden analizi yapmak istiyorsanız Sorgu Deposu'nı kullanın. Veritabanı erişimi olan kullanıcılar Sorgu Deposu verilerini sorgulamak için T-SQL kullanabilir. Varsayılan olarak, Sorgu Deposu bir saatlik aralıklar için toplam sorgu istatistiklerini yakalar.
Yüksek CPU kullanan sorguların etkinliğine bakmak için aşağıdaki sorguyu kullanın. Bu sorgu en çok CPU kullanan 15 sorguyu döndürür. Son iki saat dışında bir zaman aralığına bakmak için değiştirmeyi
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()unutmayın:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Sorunlu sorguları tanımladıktan sonra, CPU kullanımını azaltmak için bu sorguları ayarlamanın zamanı geldi. Alternatif olarak, soruna geçici bir çözüm olarak veritabanının veya elastik havuzun işlem boyutunu artırmayı seçebilirsiniz.
Azure SQL Veritabanı CPU performans sorunlarını işleme hakkında daha fazla bilgi için bkz. Azure SQL Veritabanı yüksek CPU tanılama ve sorunlarını giderme.
G/Ç performansı sorunlarını belirleme
Depolama girişi/çıkışı (G/Ç) performans sorunlarını tanımlarken en fazla bekleme türleri şunlardır:
PAGEIOLATCH_*Veri dosyası G/Ç sorunları için (, ,
PAGEIOLATCH_EXPAGEIOLATCH_UPdahilPAGEIOLATCH_SH). Bekleme türü adında GÇ varsa bir G/Ç sorununa işaret eder. Sayfa mandal bekleme adında GÇ yoksa, depolama performansıyla (örneğin çekişmetempdb) ilgili olmayan farklı bir sorun türüne işaret eder.WRITE_LOGİşlem günlüğü G/Ç sorunları için.
G/Ç sorunu şu anda oluşuyorsa
ve wait_timeöğesini görmek wait_type için sys.dm_exec_requests veya sys.dm_os_waiting_tasks kullanın.
Verileri tanımlama ve G/Ç kullanımını günlüğe kaydetme
Verileri tanımlamak ve G/Ç kullanımını günlüğe kaydetmek için aşağıdaki sorguyu kullanın.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
kullanan sys.dm_db_resource_statsdiğer örnekler için bu makalenin devamında yer alan Kaynak kullanımını izleme bölümüne bakın.
G/Ç sınırına ulaşıldıysa iki seçeneğiniz vardır:
- İşlem boyutunu veya hizmet katmanını yükseltin
- En çok G/Ç tüketen sorguları belirleyin ve ayarlayın.
Sorgu Deposu'nı kullanarak arabellekle ilgili G/Ç'yi görüntüleme
G/Ç ile ilgili beklemelere göre en çok kullanılan sorguları belirlemek için, izlenen etkinliğin son iki saatini görüntülemek için aşağıdaki Sorgu Deposu sorgusunu kullanabilirsiniz:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
ve sütunlarında avg_physical_io_reads avg_num_physical_io_reads büyük değerlere sahip sorgulara odaklanarak sys.query_store_runtime_stats görünümünü de kullanabilirsiniz.
WRITELOG beklemeleri için toplam günlük G/Ç'sini görüntüleme
Bekleme türü ise WRITELOG, deyime göre toplam günlük G/Ç'sini görüntülemek için aşağıdaki sorguyu kullanın:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Tempdb performans sorunlarını belirleme
Sorunlarla tempdb ilişkili yaygın bekleme türleri : PAGELATCH_* (değil PAGEIOLATCH_*). Ancak, PAGELATCH_* beklemeler her zaman çekişmeye sahip tempdb olduğunuz anlamına gelmez. Bu bekleme aynı veri sayfasını hedefleyen eşzamanlı isteklerden dolayı kullanıcı-nesne veri sayfası çekişmesiyle karşılaştığınızı gösteriyor da olabilir. Çakışmayı daha fazla onaylamak tempdb için sys.dm_exec_requests kullanarak değerin wait_resource 2 tempdb ile 2:x:y başladığını, veritabanı kimliği, x dosya kimliği ve y sayfa kimliği olduğunu onaylayın.
Çekişme için tempdb yaygın bir yöntem, kullanan tempdbuygulama kodunu azaltmak veya yeniden yazmaktır. Yaygın tempdb kullanım alanları şunlardır:
- Geçici tablolar
- Tablo değişkenleri
- Tablo değerli parametreler
- Sıralama, karma ile birleştirme ve biriktirici kullanan sorgu planlarına sahip sorgular
Daha fazla bilgi için bkz . Azure SQL'de tempdb.
Elastik havuzdaki tüm veritabanları aynı tempdb veritabanını paylaşır. Bir veritabanının yüksek tempdb alan kullanımı, aynı elastik havuzdaki diğer veritabanlarını etkileyebilir.
Tablo değişkenlerini ve geçici tabloları kullanan en önemli sorgular
Tablo değişkenlerini ve geçici tabloları kullanan en çok kullanılan sorguları belirlemek için aşağıdaki sorguyu kullanın:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Uzun süre çalışan işlemleri tanımlama
Uzun süre çalışan işlemleri tanımlamak için aşağıdaki sorguyu kullanın. Uzun süre çalışan işlemler kalıcı sürüm deposu (PVS) temizlemesini engeller. Daha fazla bilgi için bkz. Hızlandırılmış veritabanı kurtarma sorunlarını giderme.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Bellek verme bekleme performansı sorunlarını belirleme
En fazla bekleme türünüz ise RESOURCE_SEMAPHORE, sorguların yeterince büyük bir bellek izni alıncaya kadar yürütülmeye başlayamayacağı bir bellek verme bekleme sorununuz olabilir.
RESOURCE_SEMAPHORE beklemenin en iyi bekleme olup olmadığını belirleme
Beklemenin ilk bekleme olup olmadığını RESOURCE_SEMAPHORE belirlemek için aşağıdaki sorguyu kullanın. Ayrıca, yakın tarihte artan bekleme süresi sıralaması RESOURCE_SEMAPHORE da gösterilebilir. Bellek verme bekleme sorunlarını giderme hakkında daha fazla bilgi için bkz . SQL Server'da bellek atamalarının neden olduğu yavaş performans veya düşük bellek sorunlarını giderme.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Yüksek bellek tüketen deyimleri tanımlama
Azure SQL Veritabanı bellek yetersiz hatalarıyla karşılaşırsanız sys.dm_os_out_of_memory_events gözden geçirin. Daha fazla bilgi için bkz. Azure SQL Veritabanı ile yetersiz bellek hatalarını giderme.
İlk olarak, ve end_timeile ilgili değerlerini start_time güncelleştirmek için aşağıdaki betiği değiştirin. Ardından, yüksek bellek tüketen deyimleri tanımlamak için aşağıdaki sorguyu çalıştırın:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
İlk 10 etkin bellek iznini belirleme
İlk 10 etkin bellek iznini belirlemek için aşağıdaki sorguyu kullanın:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Bağlantıları izleme
Belirli bir veritabanına kurulan bağlantılarla ilgili bilgileri ve her bağlantının ayrıntılarını almak için sys.dm_exec_connections görünümünü kullanabilirsiniz. Bir veritabanı elastik havuzdaysa ve yeterli izinlere sahipseniz, görünüm elastik havuzdaki tüm veritabanları için bağlantı kümesini döndürür. Ayrıca, sys.dm_exec_sessions görünümü tüm etkin kullanıcı bağlantıları ve iç görevler hakkında bilgi alınırken yararlıdır.
Geçerli oturumları görüntüleme
Aşağıdaki sorgu, geçerli bağlantınız ve oturumunuzla ilgili bilgileri alır. Tüm bağlantıları ve oturumları görüntülemek için yan tümcesini WHERE kaldırın.
Veritabanındaki tüm yürütme oturumlarını yalnızca ve sys.dm_exec_sessions görünümlerini yürütürken sys.dm_exec_requests veritabanı üzerinde izniniz varsa VIEW DATABASE STATE görürsünüz. Aksi takdirde yalnızca geçerli oturumu görürsünüz.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Sorgu performansını izleme
Yavaş veya uzun süre çalışan sorgular önemli sistem kaynaklarını tüketebilir. Bu bölümde, sys.dm_exec_query_stats dinamik yönetim görünümünü kullanarak birkaç yaygın sorgu performansı sorununu algılamak için dinamik yönetim görünümlerinin nasıl kullanılacağı gösterilmektedir. Görünüm, önbelleğe alınmış plan içindeki sorgu deyimi başına bir satır içerir ve satırların ömrü planın kendisine bağlıdır. Önbellekten bir plan kaldırıldığında, ilgili satırlar bu görünümden kaldırılır. Örneğin OPTION (RECOMPILE) kullanıldığından sorgunun önbelleğe alınmış bir planı yoksa, bu görünümdeki sonuçlarda mevcut değildir.
CPU süresine göre en çok sorgu bulma
Aşağıdaki örnek, yürütme başına ortalama CPU süresine göre derecelenen ilk 15 sorgu hakkında bilgi döndürür. Bu örnek sorguları sorgu karmalarına göre toplayarak mantıksal olarak eşdeğer sorguların birikmeli kaynak tüketimine göre gruplandırılmış olmasını sağlar.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Birikmeli CPU süresi için sorgu planlarını izleme
Verimsiz bir sorgu planı DA CPU tüketimini artırabilir. Aşağıdaki örnek, hangi sorgunun yakın geçmişteki en kümülatif CPU'yu kullandığını belirler.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Engellenen sorguları izleme
Yavaş veya uzun süre çalışan sorgular aşırı kaynak tüketimine katkıda bulunabilir ve engellenen sorguların sonucu olabilir. Engellemenin nedeni kötü uygulama tasarımı, hatalı sorgu planları, yararlı dizinlerin olmaması vb. olabilir.
Veritabanındaki sys.dm_tran_locks geçerli kilitleme etkinliği hakkında bilgi almak için görünümü kullanabilirsiniz. Kod örnekleri için bkz . sys.dm_tran_locks. Engelleme sorunlarını giderme hakkında daha fazla bilgi için bkz . Azure SQL engelleme sorunlarını anlama ve çözme.
Kilitlenmeleri izleme
Bazı durumlarda, iki veya daha fazla sorgu bir diğerini engelleyebilir ve kilitlenmeye neden olabilir.
Kilitlenme olaylarını yakalamak için bir Genişletilmiş Olaylar izlemesi oluşturabilir, ardından sorgu deposu'nda ilgili sorguları ve bunların yürütme planlarını bulabilirsiniz. AdventureWorksLT'de kilitlenmeye neden olacak laboratuvar da dahil olmak üzere Azure SQL Veritabanı'de kilitlenmeleri analiz etme ve önleme bölümünde daha fazla bilgi edinin. Kilitlenmeye neden olabilecek kaynak türleri hakkında daha fazla bilgi edinin.
İlgili içerik
- Azure SQL Veritabanı ve Azure SQL Yönetilen Örneği giriş
- Azure SQL Veritabanı’nda yüksek CPU sorunlarını tanılama ve giderme
- Azure SQL Veritabanı’nda uygulamaları ve veritabanlarını performans için ayarlama
- Azure SQL Veritabanı engelleme sorunlarını anlama ve çözme
- Azure SQL Veritabanı'de kilitlenmeleri analiz etme ve önleme
- Veritabanı izleyicisi ile Azure SQL iş yüklerini izleme (önizleme)