Azure SQL Veritabanında kaynak yönetimi
Şunlar için geçerlidir: ![]() Azure SQL Veritabanı
Azure SQL Veritabanı
Bu makalede, Azure SQL Veritabanı kaynak yönetimine genel bir bakış sağlanır. Kaynak sınırlarına ulaşıldığında ne olacağı hakkında bilgi sağlar ve bu sınırları zorlamak için kullanılan kaynak idare mekanizmalarını açıklar.
Tek veritabanları için fiyatlandırma katmanı başına belirli kaynak sınırları için
Elastik havuz kaynak sınırları için şunlardan birini inceleyin:
Azure Synapse Analytics ayrılmış SQL havuzu sınırları için bkz:
Bölge başına abonelik sanal çekirdek sınırları
Mart 2024'den itibaren abonelikler, her abonelik için bölge başına aşağıdaki sanal çekirdek sınırlarına sahiptir:
| Abonelik türü | Varsayılan sanal çekirdek sınırları |
|---|---|
| Enterprise Sözleşmesi (EA) | Kategori 2000 |
| Ücretsiz denemeler | 10 |
| Startup'lar için Microsoft | 100 |
| MSDN / MPN / Imagine / AzurePass / Öğrenciler için Azure | 40 |
| Kullandıkça Öde (PAYG) | 150 |
Aşağıdaki topluluklara bir göz atın:
- Bu sınırlar yeni ve mevcut abonelikler için geçerlidir.
- DTU satın alma modeliyle sağlanan veritabanları ve elastik havuzlar sanal çekirdek kotasına göre sayılır ve tam tersi de geçerlidir. Tüketilen her sanal çekirdek, sunucu düzeyinde kota için kullanılan 100 DTU'ya eşdeğer olarak kabul edilir.
- Varsayılan sınırlar hem sağlanan işlem veritabanları /elastik havuzlar için yapılandırılan sanal çekirdekleri hem de sunucusuz veritabanları için yapılandırılan maksimum sanal çekirdekleri içerir.
- Aboneliğiniz için geçerli sanal çekirdek kullanımınızı belirlemek için Abonelik Kullanımları - REST API alma çağrısını kullanabilirsiniz.
- Varsayılandan daha yüksek bir sanal çekirdek kotası istemek için Azure portalında yeni bir destek isteği gönderin. Daha fazla bilgi için bkz. Azure SQL Veritabanı için kota artışı isteme.
Mantıksal sunucu sınırları
| Kaynak | Sınır |
|---|---|
| Mantıksal sunucu başına veritabanları | Kategori 5000 |
| Bir bölgedeki abonelik başına varsayılan mantıksal sunucu sayısı | 250 |
| Bir bölgedeki abonelik başına en fazla mantıksal sunucu sayısı | 250 |
| Mantıksal sunucu başına en fazla elastik havuz | DTU veya sanal çekirdek sayısıyla sınırlıdır. Örneğin, her havuz 1000 DTU ise, bir sunucu 54 havuzu destekleyebilir. |
Önemli
Veritabanı sayısı mantıksal sunucu başına sınıra yaklaştıkça aşağıdakiler oluşabilir:
- Veritabanında sorgu çalıştırma gecikme süresini
masterartırma. Bu, gibisys.resource_statskaynak kullanım istatistiklerinin görünümlerini içerir. - Yönetim işlemlerinde gecikme süresini artırma ve sunucudaki veritabanlarını listelemeyi içeren portal görünüm noktalarını işleme.
Kaynak sınırlarına ulaşıldığında ne olur?
İşlem CPU'su
Veritabanı işlem CPU kullanımı yüksek olduğunda sorgu gecikme süresi artar ve sorgular zaman aşımına bile neden olabilir. Bu koşullar altında, sorgular hizmet tarafından kuyruğa alınmış olabilir ve kaynaklar serbest hale geldikçe yürütülecek kaynaklar sağlanır.
Yüksek işlem kullanımı gözlemlerseniz azaltma seçenekleri şunlardır:
- Veritabanına daha fazla işlem kaynağı sağlamak için veritabanının veya elastik havuzun işlem boyutunu artırma. Bkz . Tek veritabanı kaynaklarını ölçeklendirme ve Elastik havuz kaynaklarını ölçeklendirme.
- Her sorgunun CPU kaynak kullanımını azaltmak için sorguları iyileştirme. Daha fazla bilgi için bkz. Sorgu Ayarlama/İpucu Sağlama.
Depolama
Kullanılan veri alanı veritabanı düzeyinde veya elastik havuz düzeyinde maksimum veri boyutu sınırına ulaştığında, veri boyutunu artıran eklemeler ve güncelleştirmeler başarısız olur ve istemciler bir hata iletisi alır. SELECT ve DELETE deyimleri etkilenmez.
Premium ve İş Açısından Kritik hizmet katmanlarında, veriler, işlem günlüğü ve tek bir veritabanı veya tempdb elastik havuz için birleştirilmiş depolama tüketimi en büyük yerel depolama boyutunu aşarsa istemciler bir hata iletisi alır. Daha fazla bilgi için bkz . Depolama alanı idaresi.
Yüksek depolama alanı kullanımı gözlemlerseniz azaltma seçenekleri şunlardır:
- Veritabanının veya elastik havuzun maksimum veri boyutunu artırın veya en yüksek veri boyutu sınırına sahip bir hizmet hedefine ölçeklendirin. Bkz . Tek veritabanı kaynaklarını ölçeklendirme ve Elastik havuz kaynaklarını ölçeklendirme.
- Veritabanı elastik bir havuzdaysa, alternatif olarak veritabanı havuzun dışına taşınabilir, böylece depolama alanı diğer veritabanlarıyla paylaşılmamalıdır.
- Kullanılmayan alanı geri kazanmak için veritabanını küçültün. Daha fazla bilgi için bkz. Azure SQL Veritabanı'da dosya alanını yönetme.
- Elastik havuzlarda veritabanını küçültmek, havuzdaki diğer veritabanları için daha fazla depolama alanı sağlar.
- Yüksek alan kullanımının Kalıcı Sürüm Deposu (PVS) boyutunda ani bir artışa bağlı olup olmadığını denetleyin. PVS her veritabanının bir parçasıdır ve Hızlandırılmış Veritabanı Kurtarma'yı uygulamak için kullanılır. Geçerli PVS boyutunu belirlemek için bkz . PVS sorunlarını giderme. Büyük PVS boyutunun yaygın bir nedeni, PVS'deki eski satır sürümlerinin temizlenmesini önleyen, uzun süre (saat) açık olan bir işlemdir.
- Premium ve İş Açısından Kritik hizmet katmanlarında büyük miktarda depolama alanı kullanan veritabanları ve elastik havuzlar için, veritabanında veya elastik havuzda kullanılan alan maksimum veri boyutu sınırının altında olsa bile yetersiz alan hatası alabilirsiniz. Bu durum, veya işlem günlüğü dosyaları en yüksek yerel depolama sınırına doğru büyük miktarda depolama alanı tüketirse
tempdboluşabilir. Veritabanının veya elastik havuzun yükünü yük devrederek ilk küçük boyutuna sıfırlayıntempdbveya yerel depolama tüketimini azaltmak için işlem günlüğünü küçültün .
Oturumlar, çalışanlar ve istekler
Oturumlar, çalışanlar ve istekler aşağıdaki gibi tanımlanır:
- Oturum, veritabanı altyapısına bağlı bir işlemi temsil eder.
- İstek, sorgunun veya toplu işlemin mantıksal gösterimidir. İstek, oturuma bağlı bir istemci tarafından verilir. Zaman içinde, aynı oturumda birden çok istek yayımlanabilir.
- Çalışan veya iş parçacığı olarak da bilinen bir çalışan iş parçacığı, işletim sistemi iş parçacığının mantıksal bir gösterimidir. Bir istek, paralel sorgu yürütme planıyla yürütülürken çok sayıda çalışana veya seri (tek iş parçacıklı) yürütme planıyla yürütülürken tek bir çalışana sahip olabilir. Çalışanların, isteklerin dışındaki etkinlikleri de desteklemesi gerekir: örneğin, oturum açma isteğini oturum bağlantısı olarak işlemek için bir çalışan gereklidir.
Bu kavramlar hakkında daha fazla bilgi için bkz . İş Parçacığı ve Görev Mimarisi Kılavuzu.
En fazla çalışan sayısı, hizmet katmanı ve işlem boyutuna göre belirlenir. Oturum veya çalışan sınırlarına ulaşıldığında yeni istekler reddedilir ve istemciler bir hata iletisi alır. Bağlantı sayısı uygulama tarafından denetlenebilir ancak eş zamanlı çalışan sayısını tahmin etmek ve denetlemek genellikle daha zordur. Bu durum özellikle veritabanı kaynak sınırlarına ulaşıldığında ve çalışanların daha uzun süre çalışan sorgular, büyük engelleme zincirleri veya aşırı sorgu paralelliği nedeniyle biriktiği yoğun yük dönemlerinde geçerlidir.
Not
Azure SQL Veritabanı ilk teklifi yalnızca tek iş parçacıklı sorguları destekledi. O sırada istek sayısı her zaman çalışan sayısına eşdeğerdi. Azure SQL Veritabanı'daki 10928 hata iletisi yalnızca geriye dönük uyumluluk amacıyla ifadeyi The request limit for the database is *N* and has been reached içeriyor. Ulaşılan sınır aslında çalışan sayısı sınırıdır.
En yüksek paralellik derecesi (MAXDOP) ayarınız sıfıra eşitse veya birden büyükse, çalışan sayısı istek sayısından çok daha yüksek olabilir ve MAXDOP bire eşit olduğunda sınıra çok daha erken ulaşılabilir.
- Kaynak idaresi hataları bölümünde 10928 hatası hakkında daha fazla bilgi edinin.
- Hata 10928 ve 10936'da istek sınırı tükenmesi hakkında daha fazla bilgi edinin.
Çalışan veya oturum sınırlarına yaklaşmayı veya bu sınırlara çarpmayı şu şekilde azaltabilirsiniz:
- Veritabanının veya elastik havuzun hizmet katmanını veya işlem boyutunu artırma. Bkz . Tek veritabanı kaynaklarını ölçeklendirme ve Elastik havuz kaynaklarını ölçeklendirme.
- Artan çalışanların nedeni işlem kaynaklarına yönelik çekişmeyse, kaynak kullanımını azaltmak için sorguları iyileştirme. Daha fazla bilgi için bkz. Sorgu Ayarlama/İpucu Sağlama.
- Sorgu engellemenin oluşum sayısını ve süresini azaltmak için sorgu iş yükünü iyileştirme. Daha fazla bilgi için bkz . Azure SQL engelleme sorunlarını anlama ve çözme.
- Uygun olduğunda MAXDOP ayarını azaltma.
Hizmet katmanına ve işlem boyutuna göre Azure SQL Veritabanı için çalışan ve oturum sınırlarını bulun:
- Sanal çekirdek satın alma modeli kullanıldığında tek veritabanları için kaynak sınırları
- Sanal çekirdek satın alma modeli kullanıldığında elastik havuzlar için kaynak sınırları
- DTU satın alma modeli kullanıldığında tek veritabanları için kaynak sınırları
- DTU satın alma modelini kullanan elastik havuzlar için kaynak sınırları
Kaynak idaresi hatalarında oturum veya çalışan sınırları için belirli hataları giderme hakkında daha fazla bilgi edinin.
Dış bağlantılar
sp_invoke_external_rest_endpoint aracılığıyla dış uç noktalara yapılan eş zamanlı bağlantı sayısı, en fazla 150 çalışan sabit üst sınırıyla çalışan iş parçacıklarının %10'una eşlenir.
Bellek
Diğer kaynaklardan (CPU, çalışanlar, depolama) farklı olarak bellek sınırına ulaşmak sorgu performansını olumsuz etkilemez ve hatalara ve hatalara neden olmaz. Bellek Yönetimi Mimarisi Kılavuzu'nda ayrıntılı olarak açıklandığı gibi, veritabanı altyapısı genellikle tüm kullanılabilir belleği tasarım gereği kullanır. Bellek, daha yavaş depolama erişimini önlemek için öncelikli olarak verileri önbelleğe almak için kullanılır. Bu nedenle yüksek bellek kullanımı genellikle depolama alanından yapılan yavaş okumalar yerine bellekten yapılan daha hızlı okumalar sayesinde sorgu performansını iyileştirir.
Veritabanı altyapısı başlatıldıktan sonra, iş yükü depolamadan veri okumaya başladığında, veritabanı altyapısı verileri agresif bir şekilde bellekte önbelleğe alır. Bu ilk artış döneminden sonra, özellikle boşta olmayan ve belleğe tam olarak sığmayan veritabanları için sys.dm_db_resource_stats ve sql_instance_memory_percentavg_instance_memory_percent Azure İzleyici ölçümlerinin %100'e yakın olması yaygın ve beklenen avg_memory_usage_percent bir durumdur.
Not
Ölçüm, sql_instance_memory_percent veritabanı altyapısının toplam bellek tüketimini yansıtır. Bu ölçüm, yüksek yoğunluklu iş yükleri çalışırken bile %100'e ulaşamayabilir. Bunun nedeni, kullanılabilir belleğin küçük bir bölümünün iş parçacığı yığınları ve yürütülebilir modüller gibi veri önbelleği dışındaki kritik bellek ayırmaları için ayrılmış olmasıdır.
Veri önbelleğinin yanı sıra, veritabanı altyapısının diğer bileşenlerinde de bellek kullanılır. Bellek talebi olduğunda ve kullanılabilir tüm bellek veri önbelleği tarafından kullanıldığında, veritabanı altyapısı belleği diğer bileşenler için kullanılabilir hale getirmek için veri önbelleği boyutunu küçültür ve diğer bileşenler belleği serbest bıraktığında veri önbelleğini dinamik olarak büyütür.
Nadir durumlarda, yeterince zorlu bir iş yükü yetersiz bellek koşuluna neden olabilir ve bellek yetersiz hatalarına yol açabilir. Bellek yetersiz hataları her düzeyde %0 ile %100 arasında bellek kullanımıyla gerçekleşebilir. Bellek yetersiz hataları, orantılı olarak daha küçük bellek sınırlarına sahip daha küçük işlem boyutlarında ve / veya yoğun elastik havuzlar gibi sorgu işleme için daha fazla bellek kullanan iş yüklerinde ortaya çıkabilir.
Bellek yetersiz hatalarıyla karşınıza çıkarsa, azaltma seçenekleri şunlardır:
- sys.dm_os_out_of_memory_events'da OOM koşulunun ayrıntılarını gözden geçirin.
- Veritabanının veya elastik havuzun hizmet katmanını veya işlem boyutunu artırma. Bkz . Tek veritabanı kaynaklarını ölçeklendirme ve Elastik havuz kaynaklarını ölçeklendirme.
- Bellek kullanımını azaltmak için sorguları ve yapılandırmayı iyileştirme. Yaygın çözümler aşağıdaki tabloda açıklanmıştır.
| Çözüm | Açıklama |
|---|---|
| Bellek atamalarının boyutunu küçültme | Bellek izinleri hakkında daha fazla bilgi için BKZ . SQL Server bellek vermelerini anlama blog gönderisi. Aşırı büyük bellek atamalarını önlemeye yönelik yaygın bir çözüm, istatistikleri güncel tutmaktır. Bu, sorgu altyapısı tarafından daha doğru bellek tüketimi tahminlerine neden olur ve büyük bellek atamalarını önler. Varsayılan olarak, uyumluluk düzeyi 140 ve üzerini kullanan veritabanlarında veritabanı altyapısı Batch modu bellek verme geri bildirimini kullanarak bellek verme boyutunu otomatik olarak ayarlayabilir. Benzer şekilde, uyumluluk düzeyi 150 ve üzerini kullanan veritabanlarında veritabanı altyapısı daha yaygın satır modu sorguları için Satır modu bellek verme geri bildirimini de kullanır. Bu yerleşik işlevsellik, büyük bellek izinleri nedeniyle yetersiz bellek hatalarını önlemeye yardımcı olur. |
| Sorgu planı önbelleğinin boyutunu küçültme | Veritabanı altyapısı, her sorgu yürütmesine yönelik bir sorgu planı derlemekten kaçınmak için sorgu planlarını bellekte önbelleğe alır. Yalnızca bir kez kullanılan önbelleğe alma planlarının neden olduğu sorgu planı önbelleği kabarmasını önlemek için parametreli sorgular kullandığınızdan emin olun ve veritabanı kapsamlı OPTIMIZE_FOR_AD_HOC_WORKLOADS yapılandırmayı etkinleştirmeyi göz önünde bulundurun. |
| Kilit belleği boyutunu küçültme | Veritabanı altyapısı kilitler için bellek kullanır. Mümkün olduğunda, çok fazla sayıda kilit elde edip yüksek kilit bellek tüketimine neden olabilecek büyük işlemlerden kaçının. |
Kullanıcı iş yüklerine ve iç işlemlere göre kaynak tüketimi
Azure SQL Veritabanı yüksek kullanılabilirlik ve olağanüstü durum kurtarma, veritabanı yedekleme ve geri yükleme, izleme, Sorgu Deposu, Otomatik ayarlama gibi temel hizmet özelliklerini uygulamak için işlem kaynaklarını gerektirir. Sistem, kaynak idare mekanizmalarını kullanarak bu iç işlemler için genel kaynakların sınırlı bir bölümünü ayırarak kaynakların geri kalanını kullanıcı iş yükleri için kullanılabilir hale getirir. İç işlemlerin işlem kaynaklarını kullanmadığında, sistem bunları kullanıcı iş yükleri için kullanılabilir hale getirir.
Kullanıcı iş yüklerine ve iç işlemlere göre toplam CPU ve bellek tüketimi, ve sütunlarında sys.dm_db_resource_stats ve sys.resource_stats görünümlerinde avg_instance_cpu_percent avg_instance_memory_percent bildirilir. Bu veriler, havuz düzeyindeki tek veritabanları ve elastik havuzlar için ve sql_instance_memory_percent Azure İzleyici ölçümleri aracılığıyla sql_instance_cpu_percent da bildirilir.
Not
sql_instance_cpu_percent ve sql_instance_memory_percent Azure İzleyici ölçümleri Temmuz 2023'ten itibaren kullanılabilir. Bunlar, sırasıyla daha önce kullanılabilir sqlserver_process_core_percent olan ölçümlere sqlserver_process_memory_percent tamamen eşdeğerdir. İkinci iki ölçüm kullanılabilir durumda kalır, ancak gelecekte kaldırılacaktır. Veritabanı izlemesinde kesinti yaşanmasını önlemek için eski ölçümleri kullanmayın.
Bu ölçümler Temel, S1 ve S2 hizmet hedeflerini kullanan veritabanlarında kullanılamaz. Aynı veriler aşağıdaki dinamik yönetim görünümlerinde de kullanılabilir.
Her veritabanındaki kullanıcı iş yüklerinin CPU ve bellek tüketimi, ve sütunlarında sys.dm_db_resource_stats ve sys.resource_stats görünümlerinde avg_cpu_percent avg_memory_usage_percent bildirilir. Elastik havuzlar için havuz düzeyinde kaynak tüketimi sys.elastic_pool_resource_stats görünümünde (geçmiş raporlama senaryoları için) ve sys.dm_elastic_pool_resource_stats gerçek zamanlı izleme için bildirilir. Kullanıcı iş yükü CPU tüketimi, havuz düzeyindeki cpu_percent tek veritabanları ve elastik havuzlar için Azure İzleyici ölçümü aracılığıyla da bildirilir.
Kullanıcı iş yüklerine ve iç işlemlere göre son kaynak tüketiminin daha ayrıntılı dökümü sys.dm_resource_governor_resource_pools_history_ex ve sys.dm_resource_governor_workload_groups_history_ex görünümlerinde bildirilir. Bu görünümlerde başvuruda bulunan kaynak havuzları ve iş yükü grupları hakkında ayrıntılı bilgi için bkz . Kaynak idaresi. Bu görünümler, ilişkili kaynak havuzları ve iş yükü gruplarında kullanıcı iş yüklerine ve belirli iç işlemlere göre kaynak kullanımını bildirir.
İpucu
İş yükü performansını izlerken veya sorun giderirken, hem kullanıcı CPU tüketimini (, cpu_percent) hem de kullanıcı iş yüklerine ve iç işlemlere (avg_cpu_percentavg_instance_cpu_percent,sql_instance_cpu_percent) göre toplam CPU tüketimini göz önünde bulundurmak önemlidir. Bu ölçümlerden biri %70-100 aralığındaysa performans önemli ölçüde etkilenebilir.
Kullanıcı CPU tüketimi , her hizmet hedefinde kullanıcı iş yükü CPU sınırına yönelik bir yüzde olarak tanımlanır. Benzer şekilde, toplam CPU tüketimi de tüm iş yükleri için CPU sınırına doğru yüzde olarak tanımlanır. İki sınır farklı olduğundan, kullanıcı ve toplam CPU tüketimi farklı ölçeklerde ölçülür ve birbirleriyle doğrudan karşılaştırılamaz.
Kullanıcı CPU tüketimi %100'e ulaşırsa, toplam CPU tüketimi %100'in altında kalsa bile, kullanıcı iş yükünün seçili hizmet hedefinde sağlanan CPU kapasitesini tam olarak kullandığı anlamına gelir.
Toplam CPU tüketimi %70-100 aralığına ulaştığında, kullanıcı CPU tüketimi önemli ölçüde %100'ün altında kalsa bile kullanıcı iş yükü aktarım hızının düzleştirme ve sorgu gecikme süresinin arttığını görmek mümkündür. Bu durum, işlem kaynaklarının orta düzeyde ayrılmasıyla daha küçük hizmet hedefleri kullanılırken ancak yoğun elastik havuzlar gibi nispeten yoğun kullanıcı iş yükleri kullanıldığında ortaya çıkabilir. Bu durum, örneğin veritabanının yeni bir çoğaltmasını oluştururken veya veritabanını yedeklerken iç işlemler geçici olarak ek kaynaklar gerektirdiğinde daha küçük hizmet hedefleriyle de ortaya çıkabilir.
Benzer şekilde, kullanıcı CPU tüketimi %70-100 aralığına ulaştığında, toplam CPU tüketimi sınırının çok altında olsa bile kullanıcı iş yükü aktarım hızı düzlenir ve sorgu gecikme süresi artar.
Kullanıcı CPU tüketimi veya toplam CPU tüketimi yüksek olduğunda, azaltma seçenekleri İşlem CPU'sunda belirtilenle aynıdır ve hizmet hedefi artışını ve/veya kullanıcı iş yükü iyileştirmesini içerir.
Not
Tamamen boşta olan bir veritabanında veya elastik havuzda bile arka plan veritabanı altyapısı etkinlikleri nedeniyle toplam CPU tüketimi hiçbir zaman sıfır değildir. Belirli arka plan etkinliklerine, işlem boyutuna ve önceki kullanıcı iş yüküne bağlı olarak geniş bir aralıkta dalgalanabilir.
Kaynak idaresi
Kaynak sınırlarını zorlamak için Azure SQL Veritabanı, SQL Server Resource Governor'ı temel alan, bulutta çalıştırılacak şekilde değiştirilmiş ve genişletilmiş bir kaynak idaresi uygulaması kullanır. SQL Veritabanı'da, hem havuz hem de grup düzeylerinde ayarlanan kaynak sınırlarına sahip birden çok kaynak havuzu ve iş yükü grubu dengeli bir Hizmet Olarak Veritabanı sağlar. Kullanıcı iş yükü ve iç iş yükleri ayrı kaynak havuzları ve iş yükü grupları olarak sınıflandırılır. Coğrafi çoğaltmalar da dahil olmak üzere birincil ve okunabilir ikincil çoğaltmalardaki kullanıcı iş yükü kaynak havuzuna ve iş yükü gruplarına SloSharedPool1 sınıflandırılır ve UserPrimaryGroup.DBId[N] burada [N] veritabanı kimliği değeri anlamına gelir. Ayrıca, çeşitli iç iş yükleri için birden çok kaynak havuzu ve iş yükü grubu vardır.
Azure SQL Veritabanı, veritabanı altyapısındaki kaynakları yönetmek için Resource Governor'ı kullanmanın yanı sıra, işlem düzeyi kaynak idaresi için Windows İş Nesneleri'ni ve depolama kotası yönetimi için De Windows Dosya Sunucusu Kaynak Yöneticisi'ni (FSRM) kullanır.
Azure SQL Veritabanı kaynak idaresi doğası gereği hiyerarşiktir. Yukarıdan aşağıya, işletim sistemi kaynak idare mekanizmaları ve Resource Governor kullanılarak işletim sistemi düzeyinde ve depolama birimi düzeyinde, ardından Resource Governor kullanılarak kaynak havuzu düzeyinde ve ardından Resource Governor kullanılarak iş yükü grubu düzeyinde sınırlar uygulanır. Geçerli veritabanı veya elastik havuz için geçerli olan kaynak idare sınırları sys.dm_user_db_resource_governance görünümünde bildirilir.
Veri G/Ç idaresi
Veri G/Ç idaresi, Azure SQL Veritabanı bir veritabanının veri dosyalarıyla hem okuma hem de yazma fiziksel G/Ç'yi sınırlamak için kullanılan bir işlemdir. "Gürültülü komşu" etkisini en aza indirmek, çok kiracılı bir hizmette kaynak ayırma eşitliği sağlamak ve temel donanım ve depolama özelliklerinin içinde kalmak için her hizmet düzeyi için IOPS sınırları ayarlanır.
Tek veritabanları için, iş yükü grubu sınırları veritabanına karşı tüm depolama G/Ç'sine uygulanır. Elastik havuzlar için iş yükü grubu sınırları havuzdaki her veritabanına uygulanır. Ayrıca kaynak havuzu sınırı, elastik havuzun toplu G/Ç'sine de uygulanır. 'de tempdbG/Ç, daha yüksek tempdb G/Ç sınırlarının geçerli olduğu Temel, Standart ve Genel Amaçlı hizmet katmanı dışında iş yükü grubu sınırlarına tabidir. Genel olarak, iş yükü grubu sınırları kaynak havuzu sınırlarından daha düşük olduğundan ve IOPS/aktarım hızını daha erken sınırladığından, kaynak havuzu sınırları bir veritabanına (tek veya havuza alınan) karşı iş yükü tarafından ulaşılamayabilir. Ancak havuz sınırları, aynı havuzdaki birden çok veritabanı için birleştirilmiş iş yükü tarafından ulaşılabilir.
Örneğin, bir sorgu G/Ç kaynak idaresi olmadan 1000 IOPS oluşturuyorsa ancak iş yükü grubu üst sınırı 900 IOPS olarak ayarlandıysa, sorgu 900'den fazla IOPS oluşturamaz. Ancak kaynak havuzu üst sınırı 1500 IOPS olarak ayarlanırsa ve kaynak havuzuyla ilişkili tüm iş yükü gruplarından toplam G/Ç 1500 IOPS'yi aşarsa, aynı sorgunun G/Ç değeri 900 IOPS çalışma grubu sınırının altına düşürülebilir.
sys.dm_user_db_resource_governance görünümü tarafından döndürülen IOPS ve aktarım hızı maksimum değerleri garanti olarak değil sınır/üst sınır olarak hareket eder. Ayrıca, kaynak idaresi belirli bir depolama gecikme süresini garanti etmez. Belirli bir kullanıcı iş yükü için en iyi ulaşılabilir gecikme süresi, IOPS ve aktarım hızı yalnızca G/Ç kaynak idare sınırlarına değil, aynı zamanda kullanılan G/Ç boyutlarının karışımına ve temel depolamanın özelliklerine de bağlıdır. SQL Veritabanı, boyutu 512 bayt ile 4 MB arasında değişen G/Ç işlemlerini kullanır. IOPS sınırlarını zorunlu tutma amacıyla, Azure Depolama'da veri dosyaları olan veritabanları dışında her G/Ç boyutuna bakılmaksızın hesaba eklenir. Bu durumda, 256 KB'tan büyük G/Ç'ler, Azure Depolama G/Ç hesabıyla uyumlu hale getirmek için birden çok 256 KB G/Ç olarak hesaba katılır.
Azure Depolama'da veri dosyalarını kullanan Temel, Standart ve Genel Amaçlı veritabanlarında, primary_group_max_io bir veritabanında bu sayıda IOPS sağlamak için yeterli veri dosyası yoksa veya veriler dosyalar arasında eşit dağıtılmadıysa veya temel blobların performans katmanı kaynak idare sınırlarının altında IOPS/aktarım hızını sınırlıyorsa bu değer elde edilemeyebilir. Benzer şekilde, işlemlerin sık yapılan işlemeleri tarafından oluşturulan küçük günlük G/Ç işlemleriyle, primary_max_log_rate temel alınan Azure Depolama blobundaki IOPS sınırı nedeniyle bir iş yükü tarafından değere ulaşılamayabilir. Azure Premium Depolama kullanan veritabanlarında Azure SQL Veritabanı, veritabanı boyutundan bağımsız olarak gerekli IOPS/aktarım hızını elde etmek için yeterince büyük depolama blobları kullanır. Daha büyük veritabanları için, toplam IOPS/aktarım hızı kapasitesini artırmak için birden çok veri dosyası oluşturulur.
sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats ve sys.elastic_pool_resource_stats görünümlerinde bildirilen ve gibi avg_data_io_percent avg_log_write_percentkaynak kullanım değerleri, en yüksek kaynak idare sınırlarının yüzdesi olarak hesaplanır. Bu nedenle, kaynak idaresi sınırı IOPS/aktarım hızı dışındaki faktörlerde, bildirilen kaynak kullanımı %100'ün altında kalsa bile iş yükü arttıkça IOPS/aktarım hızı düzleştirme ve gecikme sürelerinin arttığını görmek mümkündür.
Veritabanı dosyası başına okuma ve yazma IOPS, aktarım hızı ve gecikme süresini izlemek için sys.dm_io_virtual_file_stats() işlevini kullanın. Bu işlev, arka plan G/Ç'si dahil olmak üzere veritabanına karşı tüm G/Ç'yi avg_data_io_percentortaya çıkararak temel alınan depolamanın IOPS ve aktarım hızını kullanır ve gözlemlenen depolama gecikme süresini etkileyebilir. İşlev, sırasıyla ve io_stall_queued_write_ms sütunlarında io_stall_queued_read_ms okuma ve yazma işlemleri için G/Ç kaynak idaresi tarafından getirilebilen ek gecikme süresi bildirir.
İşlem günlüğü oranı idaresi
İşlem günlüğü hızı idaresi Azure SQL Veritabanı toplu ekleme, SELECT INTO ve dizin derlemeleri gibi iş yükleri için yüksek alım oranlarını sınırlamak için kullanılan bir işlemdir. Bu sınırlar, altsaniye düzeyinde günlük kaydı oluşturma hızına kadar izlenir ve zorlanır ve veri dosyalarına karşı kaç GO verileceğinden bağımsız olarak aktarım hızını sınırlandırır. İşlem günlüğü oluşturma hızları şu anda doğrusal olarak donanıma ve hizmet katmanına bağımlı bir noktaya kadar ölçeklendirilmektedir.
Günlük oranları, çeşitli senaryolarda elde edilebilecek ve sürdürülebilecek şekilde ayarlanırken, genel sistem kullanıcı yüküne en aza indirgenmiş etkiyle işlevselliğini koruyabilir. Günlük hızı idaresi, işlem günlüğü yedeklemelerinin yayımlanan kurtarılabilirlik SLA'larında kalmasını sağlar. Bu idare ayrıca ikincil çoğaltmalarda yük devretme sırasında beklenenden daha uzun kapalı kalma süresine yol açabilecek aşırı bir kapsamı önler.
İşlem günlüğü dosyalarına gerçek fiziksel G/Ç'ler yönetilmiyor veya sınırlı değil. Günlük kayıtları oluşturuldukçe, her işlem, istenen en yüksek günlük hızını (mb/sn/sn) korumak için geciktirilip geciktirilmeyeceği için değerlendirilir ve değerlendirilir. Günlük kayıtları depolama alanına boşaltıldığında gecikmeler eklenmez, günlük hızı yönetimi günlük hızı oluşturma sırasında uygulanır.
Çalışma zamanında uygulanan gerçek günlük oluşturma hızları da geri bildirim mekanizmalarından etkilenir ve sistemin kararlı olabilmesi için izin verilebilen günlük oranlarını geçici olarak azaltır. Günlük dosyası alanı yönetimi, günlük alanı koşullarının ve veri çoğaltma mekanizmalarının dolmasını önlemek, genel sistem sınırlarını geçici olarak azaltabilir.
Günlük hızı vali trafik şekillendirmesi aşağıdaki bekleme türleri (sys.dm_exec_requests ve sys.dm_os_wait_stats görünümlerinde gösterilir) aracılığıyla ortaya çıkar:
| Bekleme Türü | Notlar |
|---|---|
LOG_RATE_GOVERNOR |
Veritabanı sınırlama |
POOL_LOG_RATE_GOVERNOR |
Havuz sınırlama |
INSTANCE_LOG_RATE_GOVERNOR |
Örnek düzeyi sınırlama |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Geri bildirim denetimi, Premium'da kullanılabilirlik grubu fiziksel çoğaltma/İş Açısından Kritik devam etme |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Geri bildirim denetimi, günlük alanı dışında kalma koşulunu önlemek için hızları sınırlama |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Coğrafi çoğaltma geri bildirim denetimi, yüksek veri gecikme süresi ve coğrafi ikincillerin kullanılamamasını önlemek için günlük hızını sınırlama |
İstenen ölçeklenebilirliği engelleyen bir günlük hızı sınırıyla karşılaşırken aşağıdaki seçenekleri göz önünde bulundurun:
- Bir hizmet katmanının en yüksek günlük hızını elde etmek veya farklı bir hizmet katmanına geçmek için ölçeği daha yüksek bir hizmet düzeyine yükseltin. Hiper Ölçek hizmet katmanı, seçilen hizmet düzeyinden bağımsız olarak veritabanı başına 100 MB/sn günlük hızı ve elastik havuz başına 125 MB/sn sağlar. 150 MB/sn günlük oluşturma hızı, bir kabul önizleme özelliği olarak kullanılabilir. Daha fazla bilgi edinmek ve 150 MB/sn'yi kabul etmek için bkz . Blog: Kasım 2024 Hiper Ölçek geliştirmeleri.
- ETL işlemindeki hazırlama verileri gibi geçici veriler yükleniyorsa, bunlar
tempdb(çok az günlüğe kaydedilir) konumuna yüklenebilir. - Analiz senaryolarında kümelenmiş columnstore tablosuna veya veri sıkıştırma kullanan dizinlere sahip bir tabloya yükleyin. Bu teknik gereken günlük oranını azaltır. Ama CPU kullanımını artırır ve yalnızca kümelenmiş columnstore dizinlerinden veya veri sıkıştırmadan yararlanan veri kümelerine uygulanabilir.
Depolama alanı idaresi
Premium ve İş Açısından Kritik hizmet katmanlarında veri dosyaları, işlem günlüğü dosyaları ve tempdb dosyalar dahil olmak üzere müşteri verileri, veritabanını veya elastik havuzu barındıran makinenin yerel SSD depolama alanında depolanır. Yerel SSD depolama, yüksek IOPS ve aktarım hızı ile düşük G/Ç gecikme süresi sağlar. Müşteri verilerine ek olarak, işletim sistemi, yönetim yazılımı, izleme verileri ve günlükleri ve sistem işlemi için gerekli diğer dosyalar için yerel depolama kullanılır.
Yerel depolamanın boyutu sınırlıdır ve en yüksek yerel depolama sınırını veya müşteri verileri için ayrılmış yerel depolama alanını belirleyen donanım özelliklerine bağlıdır. Bu sınır, güvenli ve güvenilir sistem çalışmasını sağlarken müşteri veri depolamasını en üst düzeye çıkarmak için ayarlanır. Her hizmet hedefi için en yüksek yerel depolama değerini bulmak için tek veritabanları ve elastik havuzlar için kaynak sınırları belgelerine bakın.
Aşağıdaki sorguyu kullanarak bu değeri ve belirli bir veritabanı veya elastik havuz tarafından şu anda kullanılan yerel depolama miktarını da bulabilirsiniz:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Sütun | Açıklama |
|---|---|
server_name |
Mantıksal sunucu adı |
database_name |
Veritabanı adı |
slo_name |
Donanım oluşturma dahil olmak üzere hizmet hedefi adı |
user_data_directory_space_quota_mb |
MB cinsinden en yüksek yerel depolama alanı |
user_data_directory_space_usage_mb |
Mb cinsinden veri dosyalarına, işlem günlüğü dosyalarına ve tempdb dosyalara göre geçerli yerel depolama tüketimi. Beş dakikada bir güncelleştirildi. |
Bu sorgu veritabanında değil master kullanıcı veritabanında yürütülmelidir. Elastik havuzlar için sorgu havuzdaki herhangi bir veritabanında yürütülebilir. Bildirilen değerler havuzun tamamına uygulanır.
Önemli
Premium ve İş Açısından Kritik hizmet katmanlarında, iş yükü veri dosyaları, işlem günlüğü dosyaları ve tempdb dosyalar tarafından maksimum yerel depolama sınırı üzerinden birleştirilmiş yerel depolama tüketimini artırmaya çalışırsa, yetersiz alan hatası oluşur. Veritabanı dosyasında kullanılan alan dosyanın boyutu üst sınırına ulaşmamış olsa bile bu durum oluşur.
Yerel SSD depolama, premium ve İş Açısından Kritik dışındaki hizmet katmanlarındaki veritabanları tarafından veritabanı ve Hiper Ölçek RBPEX önbelleği için tempdb de kullanılır. Veritabanları oluşturulduktan, silindikçe ve boyut arttıkça veya azaldıkça, makinedeki toplam yerel depolama tüketimi zaman içinde dalgalanıyor. Sistem bir makinedeki kullanılabilir yerel depolama alanının düşük olduğunu algılarsa ve veritabanı veya elastik havuzun alanı dolma riski varsa, veritabanını veya elastik havuzu yeterli yerel depolama alanı olan farklı bir makineye taşır.
Bu taşıma işlemi, veritabanı ölçeklendirme işlemine benzer şekilde çevrimiçi olarak gerçekleşir ve işlemin sonundaki kısa (saniye) yük devretme de dahil olmak üzere benzer bir etkiye sahiptir. Bu yük devretme açık bağlantıları sonlandırır ve işlemleri geri alır ve bu durumda veritabanını kullanan uygulamaları etkileyebilir.
Tüm veriler farklı makinelerdeki yerel depolama birimlerine kopyalandığından, Premium ve İş Açısından Kritik hizmet katmanlarında daha büyük veritabanlarının taşınması önemli miktarda zaman gerektirebilir. Bu süre boyunca, bir veritabanı veya elastik havuz veya veritabanı tarafından tempdb yerel alan tüketimi hızla artarsa, alanın tükenme riski artar. Sistem, gereksiz yük devretmeleri önlerken yer dışı hataları en aza indirmek için veritabanı hareketini dengeli bir şekilde başlatır.
tempdb Boyut
Azure SQL Veritabanı için boyut sınırları tempdb satın alma ve dağıtım modeline bağlıdır.
Daha fazla bilgi edinmek için boyut sınırlarını gözden geçirin tempdb :
- Sanal çekirdek satın alma modeli: tek veritabanları, havuza alınan veritabanları
- DTU satın alma modeli: tek veritabanları, havuza alınan veritabanları.
Önceden kullanılabilir donanım
Bu bölüm, daha önce kullanılabilir donanımla ilgili ayrıntıları içerir.
- 4. Nesil donanım kullanımdan kaldırılmıştır ve sağlama, yükseltme veya azaltma için kullanılamaz. Daha geniş bir sanal çekirdek ve depolama ölçeklenebilirliği, hızlandırılmış ağ, en iyi GÇ performansı ve en düşük gecikme süresi için veritabanınızı desteklenen bir donanım nesline geçirin. Daha fazla bilgi için bkz. Azure SQL Veritabanı 4. Nesil donanım desteği sona erdi.
Şu anda 4. Nesil donanımını kullanan tüm Azure SQL Veritabanı kaynaklarını belirlemek için Azure Kaynak Grafı Gezgini'ni kullanabilir veya Azure portalında belirli bir mantıksal sunucu için kaynaklar tarafından kullanılan donanımı de kontrol edebilirsiniz.
Azure Kaynak Grafı Gezgini'nde sonuçları görmek için en azından read Azure nesne veya nesne grubu izinlerine sahip olmanız gerekir.
Kaynak Grafı Gezgini'ni kullanarak 4. Nesil donanımlarını kullanmaya devam eden Azure SQL kaynaklarını tanımlamak için şu adımları izleyin:
Azure portala gidin.
Arama kutusunda öğesini
Resource grapharayın ve arama sonuçlarından Kaynak Grafı Gezgini hizmetini seçin.Sorgu penceresinde aşağıdaki sorguyu yazın ve sorguyu çalıştır'ı seçin:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"Sonuçlar bölmesi, Azure'da 4. Nesil donanımı kullanan şu anda dağıtılan tüm kaynakları görüntüler.
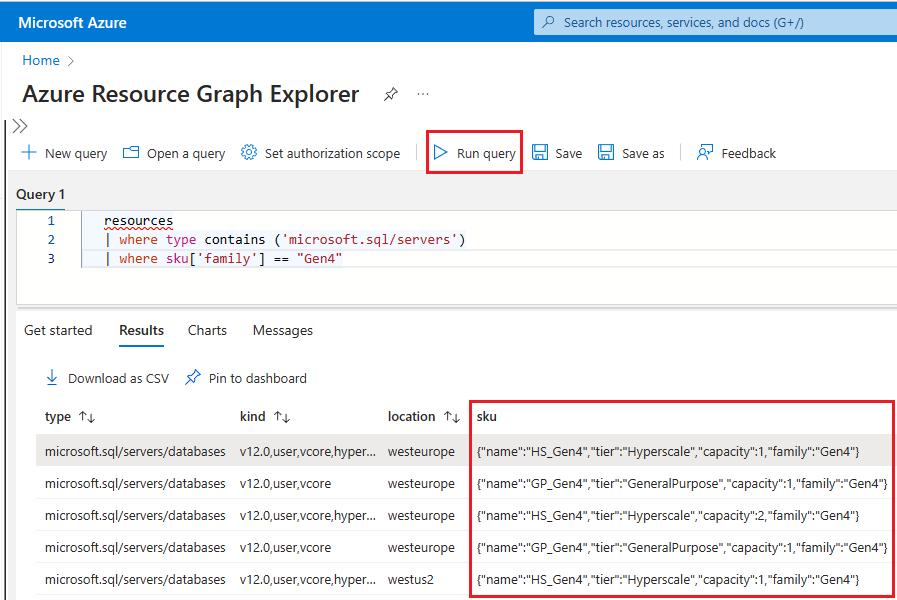
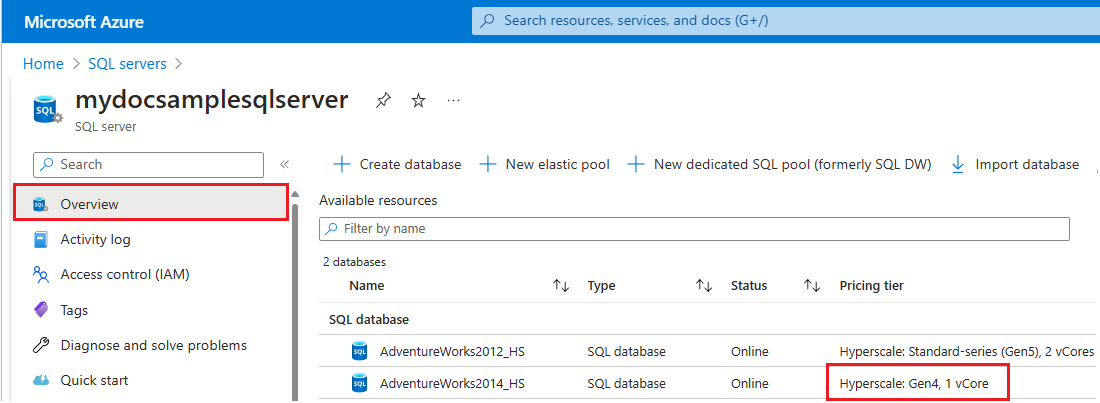
Azure'da belirli bir mantıksal sunucu için kaynaklar tarafından kullanılan donanımı denetlemek için şu adımları izleyin:
- Azure portala gidin.
SQL serversArama kutusunda arama yapın ve arama sonuçlarından SQL sunucuları'nı seçerek SQL sunucuları sayfasını açın ve seçilen abonelikler için tüm sunucuları görüntüleyin.- sunucunun Genel Bakış sayfasını açmak için ilgili sunucuyu seçin.
- Kullanılabilir kaynaklara kadar aşağı kaydırın ve 4. nesil donanımı kullanan kaynaklar için Fiyatlandırma katmanı sütununu denetleyin.
Kaynakları standart seri donanıma geçirmek için Donanımı değiştirme'yi gözden geçirin.
İlgili içerik
- Genel Azure sınırları hakkında bilgi için bkz . Azure aboneliği ve hizmet sınırları, kotalar ve kısıtlamalar.
- DTU'lar ve eDTU'lar hakkında bilgi için bkz . DTU'lar ve eDTU'lar.
- Boyut sınırları hakkında
tempdbbilgi için bkz . Tek sanal çekirdek veritabanları, havuza alınan sanal çekirdek veritabanları, tek DTU veritabanları ve havuza alınan DTU veritabanları.