MongoDB için sanal çekirdek tabanlı Azure Cosmos DB ile RAG
Hızlı gelişen üretken yapay zeka alanında GPT-3.5 gibi Büyük Dil Modelleri (LLM) doğal dil işlemeyi dönüştürmüştür. Ancak yapay zekada ortaya çıkan eğilimlerden biri, yapay zeka uygulamalarının geliştirilmesinde önemli bir rol oynayan vektör depolarının kullanılmasıdır.
Bu öğreticide, LLM'lerin ve bunların sınırlamalarının tartışılmasıyla birlikte üstün yapay zeka performansı için Alma Artırılmış Nesil (RAG) uygulamak üzere MongoDB (sanal çekirdek), LangChain ve OpenAI için Azure Cosmos DB'nin nasıl kullanılacağı açıklanır. "Alma artırılmış nesil" (RAG) için hızla benimsenen paradigmayı keşfediyoruz ve LangChain çerçevesi olan Azure OpenAI modellerini kısaca ele alıyoruz. Son olarak, bu kavramları gerçek bir uygulamayla tümleştiririz. Sonunda okuyucular bu kavramlar hakkında sağlam bir anlayışa sahip olacaklardır.
Büyük Dil Modellerini (LLM) ve bunların sınırlamalarını anlama
Büyük Dil Modelleri (LLM'ler), kapsamlı metin veri kümeleri üzerinde eğitilen gelişmiş derin sinir ağı modelleridir ve bu sayede insan benzeri metinleri anlayıp oluşturabilirler. Doğal dil işlemede devrim niteliğinde olsa da LLM'lerin doğal sınırlamaları vardır:
- Halüsinasyonlar: LLM'ler bazen "halüsinasyonlar" olarak bilinen olgusal olarak yanlış veya ön planda olmayan bilgiler üretir.
- Eski Veriler: LLM'ler en son bilgileri içermeyecek statik veri kümeleri üzerinde eğitilir ve geçerli ilgilerini sınırlar.
- Kullanıcının Yerel Verilerine Erişim Yok: LLM'lerin kişisel veya yerelleştirilmiş verilere doğrudan erişimi yoktur ve bu da kişiselleştirilmiş yanıtlar sağlama becerisini kısıtlar.
- Belirteç Sınırları: LLM'ler etkileşim başına en yüksek belirteç sınırına sahiptir ve aynı anda işleyebilecekleri metin miktarını kısıtlar. Örneğin, OpenAI gpt-3.5-turbo'nun belirteç sınırı 4096'dır.
Alma Artırılmış Nesil 'i (RAG) kullanma
Alma artırılmış nesil (RAG), LLM sınırlamalarını aşmak için tasarlanmış bir mimaridir. RAG, giriş sorgusuna dayalı olarak ilgili belgeleri almak için vektör araması kullanır ve bu belgeleri daha doğru yanıtlar oluşturmak için LLM'ye bağlam olarak sağlar. RAG, yalnızca önceden eğitilmiş desenlere güvenmek yerine güncel ve ilgili bilgileri birleştirerek yanıtları geliştirir. Bu yaklaşım aşağıdakilere yardımcı olur:
- Minimize Halüsinasyonlar: Olgusal bilgilerdeki temel tepkiler.
- Güncel Bilgileri Sağla: Güncel yanıtları sağlamak için en son verileri alma.
- Dış Veritabanlarını Kullanma: Kişisel verilere doğrudan erişim vermese de, RAG dış, kullanıcıya özgü bilgi bankası tümleştirmeye olanak tanır.
- Belirteç Kullanımını İyileştirme: RAG, en ilgili belgelere odaklanarak belirteç kullanımını daha verimli hale getirir.
Bu öğreticide, verilerinize göre uyarlanmış bir soru-cevap uygulaması oluşturmak için RAG'nin MongoDB için Azure Cosmos DB (sanal çekirdek) kullanılarak nasıl uygulanabileceği gösterilmektedir.
Uygulama mimarisine genel bakış
Aşağıdaki mimari diyagramıNDA RAG uygulamamızın temel bileşenleri gösterilmektedir:
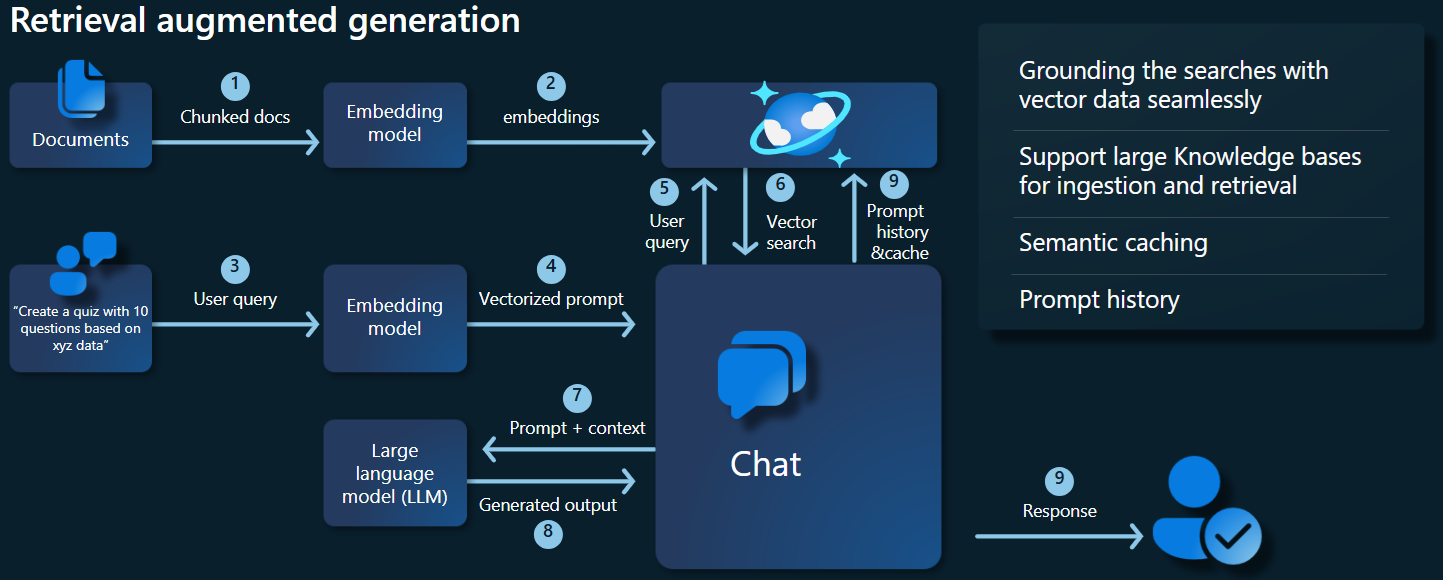
Temel bileşenler ve çerçeveler
Şimdi bu öğreticide kullanılan çeşitli çerçeveleri, modelleri ve bileşenleri ele alacağız ve bunların rollerini ve nüanslarını vurgulayacağız.
MongoDB için Azure Cosmos DB (sanal çekirdek)
MongoDB için Azure Cosmos DB (sanal çekirdek), yapay zeka destekli uygulamalar için gerekli olan anlamsal benzerlik aramalarını destekler. Çeşitli biçimlerdeki verilerin, kaynak veriler ve meta veriler ile birlikte depolanabilen vektör eklemeleri olarak temsil edilmesini sağlar. Hiyerarşik gezinilebilir küçük dünya (HNSW) gibi yaklaşık en yakın komşular algoritması kullanılarak, bu eklemeler hızlı anlamsal benzerlik aramaları için sorgulanabilir.
LangChain çerçevesi
LangChain, ortak görevler için zincirler, birden çok araç tümleştirmesi ve uçtan uca zincirler için standart bir arabirim sağlayarak LLM uygulamalarının oluşturulmasını basitleştirir. Yapay zeka geliştiricilerinin dış veri kaynaklarından yararlanan LLM uygulamaları oluşturmasına olanak tanır.
LangChain'in önemli yönleri:
- Zincirler: Belirli görevleri çözen bileşen dizileri.
- Bileşenler: LLM sarmalayıcıları, vektör deposu sarmalayıcıları, istem şablonları, veri yükleyicileri, metin ayırıcıları ve alıcıları gibi modüller.
- Modülerlik: Geliştirme, hata ayıklama ve bakımı basitleştirir.
- Popülerlik: Kullanıcı gereksinimlerini karşılamak için hızla benimsenen ve gelişen açık kaynak bir proje.
Azure Uygulaması Hizmetleri arabirimi
Uygulama hizmetleri, Gen-AI uygulamaları için kullanıcı dostu web arabirimleri oluşturmaya yönelik sağlam bir platform sağlar. Bu öğreticide, uygulama için etkileşimli bir web arabirimi oluşturmak üzere Azure Uygulaması hizmetleri kullanılır.
OpenAI modelleri
OpenAI, dil oluşturma, metin vektörleştirme, görüntü oluşturma ve ses-metin dönüştürme için çeşitli modeller sağlayan yapay zeka araştırmalarında liderdir. Bu öğreticide, dil tabanlı uygulamaları anlamak ve oluşturmak için çok önemli olan OpenAI'nin ekleme ve dil modellerini kullanacağız.
Katıştırma modelleri ile Dil oluşturma modelleri karşılaştırması
| Kategori | Metin Ekleme Modeli | Dil Modeli |
|---|---|---|
| Amaç | Metni vektör eklemelerine dönüştürme. | Doğal dili anlama ve oluşturma. |
| İşlev | Metinsel verileri yüksek boyutlu sayı dizilerine dönüştürerek metnin anlamsal anlamını yakalar. | Verilen girişe göre insan benzeri metinleri kavrar ve üretir. |
| Çıktı | Sayı dizisi (vektör eklemeleri). | Metin, yanıt, çeviri, kod vb. |
| Örnek Çıkış | Her ekleme, sayısal biçimdeki metnin anlamsal anlamını temsil eder ve model tarafından belirlenen bir boyutsallık gösterir. Örneğin, text-embedding-ada-002 1536 boyutlu vektörler oluşturur. |
Sağlanan girişe göre oluşturulan bağlamsal olarak ilgili ve tutarlı metin. Örneğin, gpt-3.5-turbo sorulara yanıtlar oluşturabilir, metin çevirebilir, kod yazabilir ve daha fazlasını yapabilirsiniz. |
| Tipik Kullanım Örnekleri | - Anlamsal arama | - Sohbet botları |
| - Öneri sistemleri | - Otomatik içerik oluşturma | |
| - Metin verilerini kümeleme ve sınıflandırma | - Dil çevirisi | |
| - Bilgi alma | -Özetleme | |
| Veri Gösterimi | Sayısal gösterim (eklemeler) | Doğal dil metni |
| Dimensionality | Dizinin uzunluğu, ekleme alanında bulunan boyut sayısına (örneğin, 1536 boyut) karşılık gelir. | Genellikle bağlamı uzunluğu belirleyen belirteç dizisi olarak temsil edilir. |
Uygulamanın ana bileşenleri
- MongoDB için Azure Cosmos DB sanal çekirdeği: Vektör eklemelerini depolama ve sorgulama.
- LangChain: Uygulamanın LLM iş akışını oluşturma. Şunlar gibi araçları kullanır:
- Belge Yükleyici: Bir dizinden belgeleri yüklemek ve işlemek için.
- Vektör Deposu Tümleştirmesi: Azure Cosmos DB'de vektör eklemelerini depolamak ve sorgulamak için.
- AzureCosmosDBVectorSearch: Cosmos DB Vektör araması çevresinde sarmalayıcı
- Azure Uygulaması Hizmetleri: Kozmik Gıda uygulaması için kullanıcı arabirimi oluşturma.
- Azure OpenAI: LLM ve ekleme modelleri sağlamak için, örneğin:
- text-embedding-ada-002: Metni 1536 boyutlu vektör eklemelerine dönüştüren bir metin ekleme modeli.
- gpt-3.5-turbo: Doğal dili anlamak ve oluşturmak için bir dil modeli.
Ortamı ayarlama
MongoDB için Azure Cosmos DB'yi (sanal çekirdek) kullanarak alma artırılmış nesli (RAG) iyileştirmeye başlamak için şu adımları izleyin:
- Microsoft Azure'da aşağıdaki kaynakları oluşturun:
- MongoDB için Azure Cosmos DB sanal çekirdek kümesi: Hızlı Başlangıç kılavuzuna buradan bakın.
- Azure OpenAI kaynağı:
- Model dağıtımı ekleme (örneğin,
text-embedding-ada-002). - Sohbet modeli dağıtımı (örneğin,
gpt-35-turbo).
- Model dağıtımı ekleme (örneğin,
Örnek belgeler
Bu öğreticide, Belge kullanarak tek bir metin dosyası yükleyeceğiz. Bu dosyalar src klasöründeki data adlı bir dizine kaydedilmelidir. içindekiler şunlardır:
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
Belge yükleme
- MongoDB (sanal çekirdek) bağlantı dizesi, Veritabanı Adı, Koleksiyon Adı ve Dizin için Cosmos DB'yi ayarlayın:
mongo_client = MongoClient(mongo_connection_string)
database_name = "Contoso"
db = mongo_client[database_name]
collection_name = "ContosoCollection"
index_name = "ContosoIndex"
collection = db[collection_name]
- Ekleme İstemcisi'ni başlatın.
from langchain_openai import AzureOpenAIEmbeddings
openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002")
openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding")
azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings(
model=openai_embeddings_model,
azure_deployment=openai_embeddings_deployment,
)
- Verilerden eklemeler oluşturun, veritabanına kaydedin ve MongoDB için Cosmos DB (sanal çekirdek) vektör deponuza bir bağlantı döndürin.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents(
json_data,
azure_openai_embeddings,
collection=collection,
index_name=index_name,
)
- Koleksiyonda aşağıdaki HNSW vektör Dizinini oluşturun (Dizinin adının yukarıdakiyle aynı olduğuna dikkat edin).
num_lists = 100
dimensions = 1536
similarity_algorithm = CosmosDBSimilarityType.COS
kind = CosmosDBVectorSearchType.VECTOR_HNSW
m = 16
ef_construction = 64
vector_store.create_index(
num_lists, dimensions, similarity_algorithm, kind, m, ef_construction
)
MongoDB için Cosmos DB kullanarak Vektör araması yapma (sanal çekirdek)
- Vektör deponuza bağlanın.
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string(
connection_string=mongo_connection_string,
namespace=f"{database_name}.{collection_name}",
embedding=azure_openai_embeddings,
)
- Sorguda Cosmos DB Vektör Araması kullanarak anlamsal benzerlik araması yapan bir işlev tanımlayın (bu kod parçacığının yalnızca bir test işlevi olduğunu unutmayın).
query = "beef dishes"
docs = vector_store.similarity_search(query)
print(docs[0].page_content)
- RAG işlevi uygulamak için Sohbet İstemcisi'ni başlatın.
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI(
model=openai_chat_model,
azure_deployment=openai_chat_deployment,
)
- RAG işlevi oluşturma.
history_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
(
"user",
"""Given the above conversation,
generate a search query to look up to get information relevant to the conversation""",
),
]
)
context_prompt = ChatPromptTemplate.from_messages(
[
("system", "Answer the user's questions based on the below context:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
]
)
- Vektör depoyu, belirtilen parametrelere göre ilgili belgeleri arayabilen bir retriever'a dönüştürür.
vector_store_retriever = vector_store.as_retriever(
search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold}
)
- azure_openai_chat modeli ve vector_store_retriever kullanarak bağlamsal olarak ilgili belge alımını sağlayarak konuşma geçmişinin farkında olan bir retriever zinciri oluşturun.
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)
- Dil modelini (azure_openai_chat) ve belirtilen istemi (context_prompt) kullanarak alınan belgeleri tutarlı bir yanıtta birleştiren bir zincir oluşturun.
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)
- Geçmişe duyarlı retriever zincirini ve belge birleşim zincirini tümleştirerek alma işleminin tamamını işleyen bir zincir oluşturun. Bu RAG zinciri bağlamsal olarak doğru yanıtlar almak ve oluşturmak için yürütülebilir.
rag_chain: Runnable = create_retrieval_chain(
retriever=retriever_chain,
combine_docs_chain=context_chain,
)
Örnek çıkışlar
Aşağıdaki ekran görüntüsünde çeşitli soruların çıkışları gösterilmektedir. Tamamen anlamsal benzerlik araması kaynak belgelerden ham metni döndürürken, RAG mimarisini kullanan soru-cevap uygulaması alınan belge içeriğini dil modeliyle birleştirerek hassas ve kişiselleştirilmiş yanıtlar oluşturur.
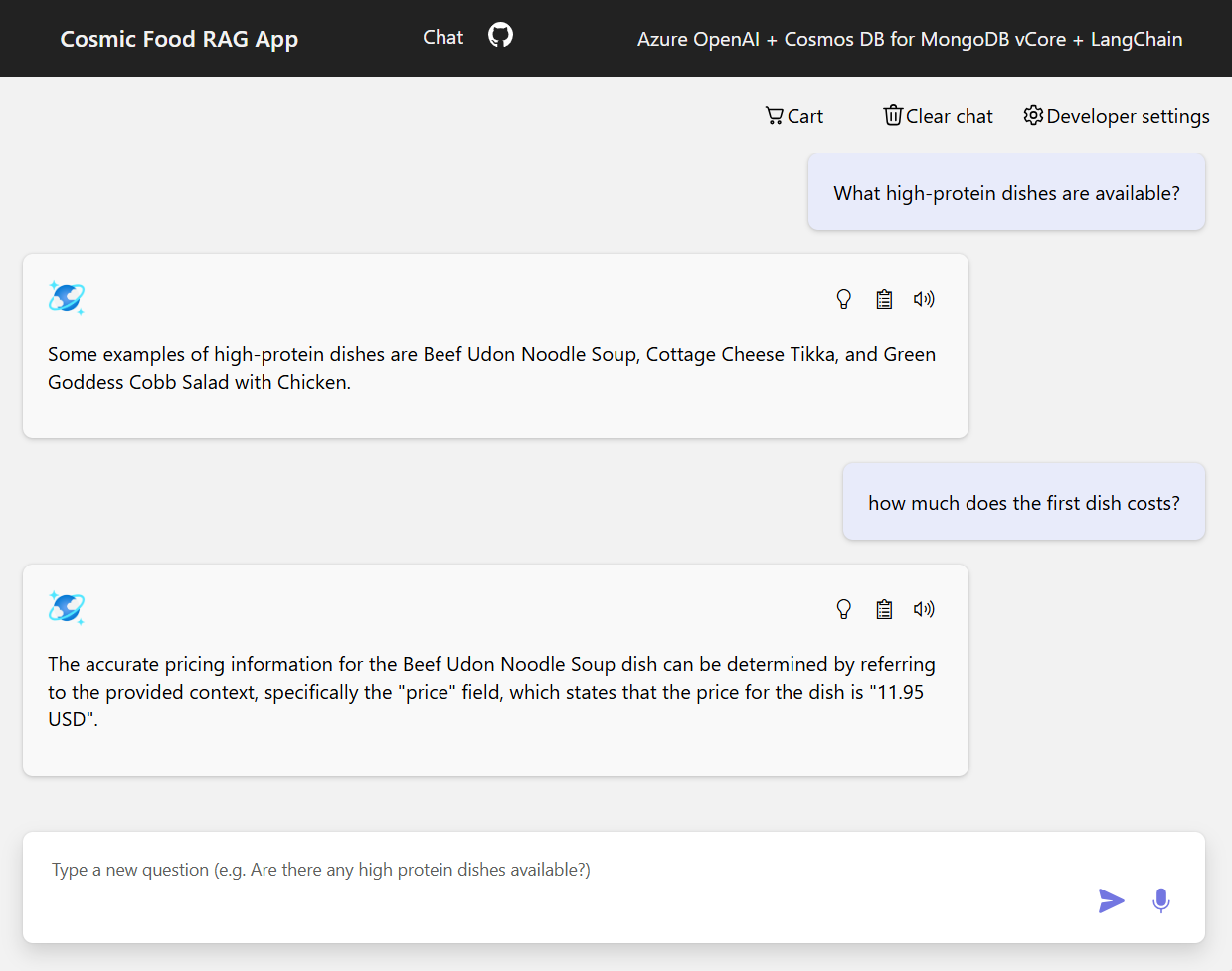
Sonuç
Bu öğreticide, vektör deposu olarak Cosmos DB kullanarak özel verilerinizle etkileşim kuran bir soru-cevap uygulaması oluşturmayı inceledik. LangChain ve Azure OpenAI ile alma artırılmış nesil (RAG) mimarisinden yararlanarak, vektör depolarının LLM uygulamaları için nasıl gerekli olduğunu gösterdik.
RAG yapay zekada özellikle doğal dil işlemede önemli bir ilerlemedir ve bu teknolojilerin birleştirilmesi, çeşitli kullanım örnekleri için güçlü yapay zeka temelli uygulamalar oluşturulmasına olanak tanır.
Sonraki adımlar
Ayrıntılı, uygulamalı bir deneyim için ve RAG'nin MongoDB için Azure Cosmos DB (sanal çekirdek), LangChain ve OpenAI modelleri kullanılarak nasıl uygulanabileceğini görmek için GitHub depomuzu ziyaret edin.