Gerçek dünyadan bir örnek kullanarak Azure Cosmos DB'de verileri modelleme ve bölümleme
UYGULANANLAR: ![]() NoSQL
NoSQL
Bu makale, gerçek dünya veri tasarımı alıştırmasını nasıl çözeceklerini göstermek için veri modelleme, bölümleme ve sağlanan aktarım hızı gibi çeşitli Azure Cosmos DB kavramlarını temel alır.
Genellikle ilişkisel veritabanlarıyla çalışıyorsanız, büyük olasılıkla veri modelini tasarlamaya yönelik alışkanlıklar ve sezgiler oluşturmüstür. Belirli kısıtlamalar ve Azure Cosmos DB'nin benzersiz güçlü yönleri nedeniyle, bu en iyi uygulamaların çoğu iyi sonuç vermez ve sizi en iyi olmayan çözümlere sürükleyebilir. Bu makalenin amacı, öğe modellemeden varlık birlikte bulundurma ve kapsayıcı bölümlemeye kadar Azure Cosmos DB'de gerçek dünya kullanım örneğini modelleme sürecinde size yol göstermektir.
Bu makaledeki kavramları gösteren topluluk tarafından oluşturulan bir kaynak kodunu indirin veya görüntüleyin.
Önemli
Bir topluluk katkıda bulunanı bu kod örneğine katkıda bulundu ve Azure Cosmos DB ekibi bu kodun bakımını desteklemiyor.
Senaryo
Bu alıştırmada kullanıcıların gönderi oluşturabileceği bir blog platformunun etki alanını ele aacağız. Kullanıcılar ayrıca bu gönderileri beğenebilir ve bu gönderilere yorum ekleyebilir.
İpucu
Bazı sözcükleri italik olarak vurguladık; bu sözcükler modelimizin manipüle etmek zorunda olacağı "şeylerin" türünü tanımlar.
Belirtimimize daha fazla gereksinim ekleme:
- Ön sayfada son oluşturulan gönderilerin bir akışı görüntülenir,
- Bir kullanıcının tüm gönderilerini, bir gönderinin tüm yorumlarını ve bir gönderinin tüm beğenilerini getirebiliriz,
- Gönderiler, yazarlarının kullanıcı adı ve sahip oldukları yorum ve beğeni sayısıyla birlikte döndürülür,
- Açıklamalar ve beğeniler, bunları oluşturan kullanıcıların kullanıcı adıyla da döndürülür,
- Listeler olarak görüntülendiğinde, gönderilerin yalnızca içeriklerinin kesilmiş bir özetini sunmaları gerekir.
Ana erişim desenlerini tanımlama
Başlamak için çözümümüzün erişim desenlerini tanımlayarak ilk belirtimimize bir yapı vereceğiz. Azure Cosmos DB için bir veri modeli tasarlarken, modelin bu isteklere verimli bir şekilde hizmet ettiğinden emin olmak için modelimizin hangi isteklere hizmet ettiğini anlamak önemlidir.
Genel sürecin daha kolay takip edilebilir olmasını sağlamak için bu farklı istekleri komut veya sorgu olarak kategorilere ayırarak CQRS'den bazı sözlükleri ödünç alıyoruz. CQRS'de komutlar yazma istekleri (sistemi güncelleştirme amaçları) ve sorgular salt okunur isteklerdir.
Platformumuzun kullanıma sunduğumuz isteklerin listesi aşağıdadır:
- [C1] Kullanıcı oluşturma/düzenleme
- [S1] Kullanıcı alma
- [C2] Gönderi oluşturma/düzenleme
- [Q2] Gönderi alma
- [Q3] Kullanıcının gönderilerini kısa formda listeleme
- [C3] Açıklama oluşturma
- [Q4] Gönderinin açıklamalarını listeleme
- [C4] Gönderiyi beğenme
- [Q5] Gönderinin beğenilerini listeleme
- [Q6] Kısa formda (akış) oluşturulan en son x gönderiyi listeleme
Bu aşamada, her varlığın (kullanıcı, gönderi vb.) ne içerdiğinin ayrıntılarını düşünmedik. Bu adım genellikle ilişkisel bir mağaza tasarlanırken ilk ele alınanlar arasındadır. Öncelikle bu adımla başlayacağız çünkü bu varlıkların tablolar, sütunlar, yabancı anahtarlar vb. açısından nasıl çevrildiği hakkında bilgi edinmeliyiz. Yazma sırasında herhangi bir şemayı zorlamayan bir belge veritabanıyla ilgili daha az endişeye neden olur.
Erişim desenlerimizi en baştan tanımlamanın önemli olmasının temel nedeni, bu istek listesinin test paketimiz olmasıdır. Veri modelimizi her yinelediğimizde isteklerin her birini gözden geçiriyor ve performans ile ölçeklenebilirliğini kontrol ediyoruz. Her modelde kullanılan istek birimlerini hesaplayıp iyileştiriyoruz. Tüm bu modeller varsayılan dizin oluşturma ilkesini kullanır ve ru tüketimini ve gecikme süresini daha da geliştirebilecek belirli özellikleri dizinleyerek bu ilkeyi geçersiz kılabilirsiniz.
V1: İlk sürüm
İki kapsayıcıyla başlıyoruz: users ve posts.
Kullanıcılar kapsayıcısı
Bu kapsayıcı yalnızca kullanıcı öğelerini depolar:
{
"id": "<user-id>",
"username": "<username>"
}
Bu kapsayıcıyı ile idbölümleyeceğiz; bu da kapsayıcıdaki her mantıksal bölümün yalnızca bir öğe içerdiği anlamına gelir.
Gönderiler kapsayıcısı
Bu kapsayıcı gönderiler, açıklamalar ve beğeniler gibi varlıkları barındırır:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Bu kapsayıcıyı ile postIdbölümleyeceğiz, bu da kapsayıcıdaki her mantıksal bölümün bir gönderi, o gönderiye yönelik tüm açıklamaları ve bu gönderinin tüm beğenilerini içerdiği anlamına gelir.
Bu kapsayıcının barındırmış olduğu üç varlık türünü ayırt etmek için bu kapsayıcıda depolanan öğelerde bir type özellik kullanıma sunulmuştur.
Ayrıca, ekleme yerine ilgili verilere başvurmayı seçtik (bu kavramlar hakkındaki ayrıntılar için bu bölüme bakın):
- kullanıcının oluşturabileceği gönderilerin üst sınırı yoktur,
- gönderiler rastgele uzun olabilir,
- bir gönderinin kaç yorum ve beğeniye sahip olabileceğinin üst sınırı yoktur,
- gönderinin kendisini güncelleştirmek zorunda kalmadan gönderiye yorum veya beğeni ekleyebilmek istiyoruz.
Modelimiz ne kadar iyi performans gösterir?
Şimdi ilk sürümümüzün performansını ve ölçeklenebilirliğini değerlendirme zamanı geldi. Daha önce tanımlanan isteklerin her biri için gecikme süresini ve kaç istek birimi tükettiği ölçüyoruz. Bu ölçüm, kullanıcı başına 5 ila 50 gönderi içeren 100.000 kullanıcı ve gönderi başına en fazla 25 yorum ve 100 beğeni içeren sahte bir veri kümesine karşı yapılır.
[C1] Kullanıcı oluşturma/düzenleme
Kapsayıcıda yalnızca bir öğe oluşturduğumuz veya güncelleştirdiğimiz için bu isteğin users uygulanması kolaydır. İstekler, bölüm anahtarı sayesinde tüm bölümlere id düzgün bir şekilde yayılır.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
7 Ms |
5.71 RU |
✅ |
[S1] Kullanıcı alma
Kullanıcı alma işlemi, kapsayıcıdan users ilgili öğe okunarak yapılır.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
2 Ms |
1 RU |
✅ |
[C2] Gönderi oluşturma/düzenleme
[C1] ile benzer şekilde kapsayıcıya posts yazmamız gerekir.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
9 Ms |
8.76 RU |
✅ |
[Q2] Gönderi alma
Kapsayıcıdan posts ilgili belgeyi alarak başlayacağız. Ancak bu yeterli değildir, belirtimimize göre gönderinin yazarının kullanıcı adını, yorum sayısını ve gönderi için beğeni sayısını toplamamız da gerekir. Listelenen toplamalar, 3 SQL sorgusunun daha verilmesini gerektirir.
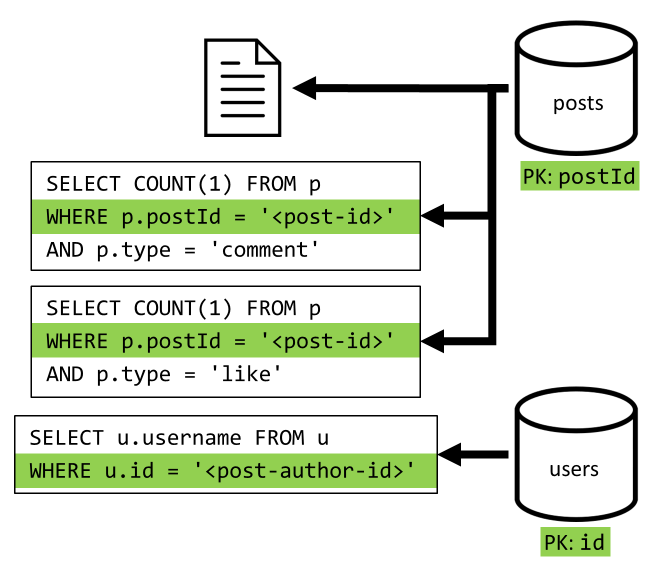
Daha fazla sorgunun her biri ilgili kapsayıcısının bölüm anahtarına filtre ekler. Bu da tam olarak performansı ve ölçeklenebilirliği en üst düzeye çıkarmak istediğimiz şey. Ancak sonunda tek bir gönderi döndürmek için dört işlem yapmamız gerekir, bu nedenle bunu bir sonraki yinelemede iyileştireceğiz.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
9 Ms |
19.54 RU |
⚠ |
[Q3] Kullanıcının gönderilerini kısa formda listeleme
İlk olarak, belirli bir kullanıcıya karşılık gelen gönderileri getiren bir SQL sorgusuyla istenen gönderileri almak zorundayız. Ancak yazarın kullanıcı adını ve açıklama ve beğeni sayısını toplamak için daha fazla sorgu da yapmamız gerekir.
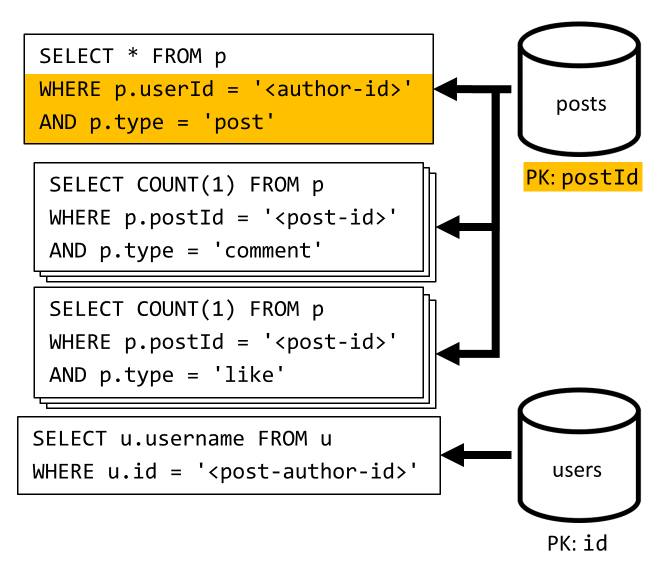
Bu uygulama birçok dezavantaj sunar:
- açıklama ve beğeni sayılarını toplayarak ilk sorgu tarafından döndürülen her gönderi için sorgunun verilmesi gerekir.
- ana sorgu kapsayıcının bölüm anahtarına
postsgöre filtre uygulamaz ve kapsayıcıda bir yayma ve bölüm taramasına yol açar.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
130 Ms |
619.41 RU |
⚠ |
[C3] Açıklama oluşturma
Kapsayıcıya karşılık gelen öğe posts yazılarak bir açıklama oluşturulur.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
7 Ms |
8.57 RU |
✅ |
[Q4] Gönderinin açıklamalarını listeleme
Bu gönderinin tüm açıklamalarını getiren bir sorguyla başlıyoruz ve bir kez daha, her açıklama için kullanıcı adlarını ayrı olarak toplamamız gerekiyor.
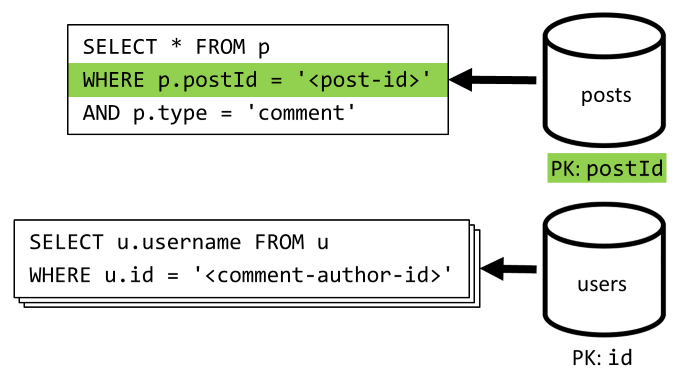
Ana sorgu kapsayıcının bölüm anahtarına göre filtre uygulasa da, kullanıcı adlarının ayrı ayrı toplanıyor olması genel performansı cezaya dönüştürür. Bunu daha sonra geliştireceğiz.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
23 Ms |
27.72 RU |
⚠ |
[C4] Gönderiyi beğenme
[C3] gibi kapsayıcıda ilgili öğeyi posts de oluştururuz.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
6 Ms |
7.05 RU |
✅ |
[Q5] Gönderinin beğenilerini listeleme
[Q4] gibi, bu gönderinin beğenilerini sorgular ve kullanıcı adlarını toplarız.
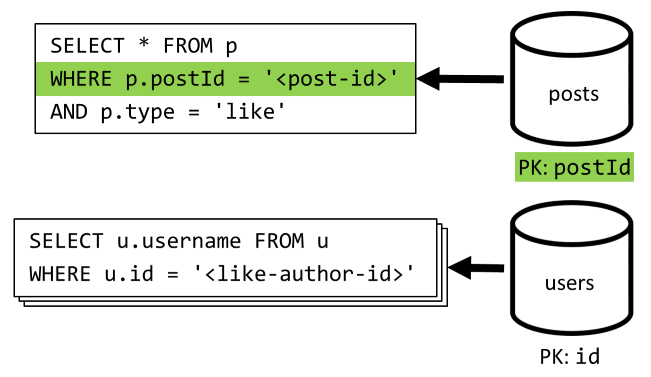
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
59 Ms |
58.92 RU |
⚠ |
[Q6] Kısa formda (akış) oluşturulan en son x gönderiyi listeleme
Kapsayıcıyı azalan oluşturma tarihine göre sıralanmış olarak sorgulayarak posts en son gönderileri getiriyoruz, ardından gönderilerin her biri için kullanıcı adlarını ve açıklama ve beğeni sayısını bir araya getiriyoruz.
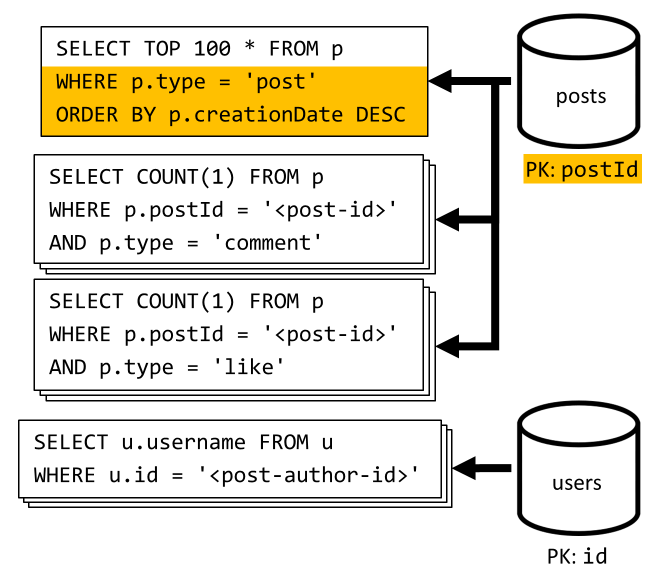
İlk sorgumuz bir kez daha kapsayıcının bölüm anahtarına posts göre filtre uygulamaz ve bu da yüksek maliyetli bir çıkış tetikler. Daha büyük bir sonuç kümesini hedeflediğimiz ve sonuçları bir ORDER BY yan tümcesiyle sıraladığımız için bu durum daha da kötüdür ve bu da istek birimleri açısından daha pahalı olmasını sağlar.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
306 Ms |
2063.54 RU |
⚠ |
V1'in performansını yansıtma
Önceki bölümde karşılaştığımız performans sorunlarına baktığımızda iki ana sorun sınıfı belirleyebiliriz:
- bazı istekler, döndürmemiz gereken tüm verileri toplamak için birden çok sorgunun verilmesini gerektirir,
- bazı sorgular hedefledikleri kapsayıcıların bölüm anahtarına göre filtre uygulamaz ve bu da ölçeklenebilirliğimizi engelleyen bir yaymayla sonuçlanır.
İlk sorundan başlayarak bu sorunların her birini çözelim.
V2: Okuma sorgularını iyileştirmek için normal dışıleştirmeye giriş
Bazı durumlarda daha fazla istek göndermemiz gerektiğinin nedeni, ilk isteğin sonuçlarının döndürmemiz gereken tüm verileri içermemesidir. Verileri normalden çıkarma, Azure Cosmos DB gibi ilişkisel olmayan bir veri deposuyla çalışırken veri kümemiz genelinde bu tür sorunları çözer.
Örneğimizde, gönderi öğelerini gönderinin yazarının kullanıcı adını, açıklama sayısını ve beğeni sayısını eklemek için değiştiririz:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Ayrıca açıklamayı ve beğen öğelerini değiştirerek bunları oluşturan kullanıcının kullanıcı adını ekleriz:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Açıklamayı ve beğeni sayılarını normalleştirme
Başarmak istediğimiz şey, her yorum veya benzerini eklediğimizde, ilgili gönderideki veya likeCount değerini de artırmamızdırcommentCount. Kapsayıcımızı posts bölümlere ayırırkenpostId, yeni öğe (açıklama veya beğenme) ve buna karşılık gelen gönderi aynı mantıksal bölümde yer alır. Sonuç olarak, bu işlemi gerçekleştirmek için bir saklı yordam kullanabiliriz.
Bir açıklama ([C3]) oluşturduğunuzda, kapsayıcıya posts yeni bir öğe eklemek yerine bu kapsayıcıda aşağıdaki saklı yordamı çağırırız:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Bu saklı yordam, gönderinin kimliğini ve yeni açıklamanın gövdesini parametre olarak alır, ardından:
- gönderiyi alır
commentCount- gönderinin yerini alır
- yeni açıklamayı ekler
Saklı yordamlar atomik işlemler olarak yürütüldükçe, değeri commentCount ve gerçek açıklama sayısı her zaman eşitlenmiş durumda kalır.
Değerini artırmak likeCountiçin yeni beğeniler eklerken benzer bir saklı yordam çağırırız.
Kullanıcı adlarını normalleştirme
Kullanıcı adları farklı bir yaklaşım gerektirir çünkü kullanıcılar yalnızca farklı bölümlerde değil, farklı bir kapsayıcıda da yer alır. Bölümler ve kapsayıcılar arasında verileri normalden çıkarmak zorunda olduğumuzda, kaynak kapsayıcının değişiklik akışını kullanabiliriz.
Örneğimizde, kullanıcılar kullanıcı adlarını güncelleştirdiğinde tepki vermek için kapsayıcının users değişiklik akışını kullanırız. Böyle bir durumda, kapsayıcıda posts başka bir saklı yordam çağırarak değişikliği yayacağız:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Bu saklı yordam, kullanıcının kimliğini ve kullanıcının yeni kullanıcı adını parametre olarak alır, ardından:
- ile eşleşen
userIdtüm öğeleri getirir (gönderiler, açıklamalar veya beğeniler olabilir) - bu öğelerin her biri için
- şunun yerine
userUsername - öğesini değiştirir
- şunun yerine
Önemli
Bu saklı yordamın kapsayıcının her bölümünde yürütülmesini gerektirdiğinden bu işlem maliyetlidir posts . Kullanıcıların çoğunun kaydolma sırasında uygun bir kullanıcı adı seçtiğini ve bunu asla değiştirmeyeceğini varsayarız, bu nedenle bu güncelleştirme çok seyrek çalışır.
V2'nin performans kazanımları nelerdir?
V2'nin bazı performans kazançlarından bahsedelim.
[Q2] Gönderi alma
Artık normal dışıleştirmemiz uygulandığına göre, bu isteği işlemek için yalnızca tek bir öğe getirmemiz gerekir.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
2 Ms |
1 RU |
✅ |
[Q4] Gönderinin açıklamalarını listeleme
Burada da kullanıcı adlarını getiren ek istekleri yedekleyebilir ve bölüm anahtarında filtreleyen tek bir sorguyla sonuçlanabilir.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
4 Ms |
7.72 RU |
✅ |
[Q5] Gönderinin beğenilerini listeleme
Beğenileri listelerken de tam olarak aynı durum.
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
4 Ms |
8.92 RU |
✅ |
V3: Tüm isteklerin ölçeklenebilir olduğundan emin olun
Genel performans geliştirmelerimize bakarken henüz tam olarak iyileştirilmemiş iki istek var. Bu istekler [Q3] ve [Q6] şeklindedir. Bu istekler, hedefledikleri kapsayıcıların bölüm anahtarına göre filtrelemeyen sorgular içeren isteklerdir.
[Q3] Kullanıcının gönderilerini kısa formda listeleme
Bu istek, V2'de sunulan ve daha fazla sorguyu yedekleyen geliştirmelerden zaten yararlanır.

Ancak kalan sorgu yine de kapsayıcının bölüm anahtarına posts göre filtrelenmiyor.
Bu durumu düşünmenin yolu basittir:
- Belirli bir kullanıcı için tüm gönderileri getirmek istediğimiz için bu isteğin
userIdfiltrelemesi gerekir. - Kapsayıcı üzerinde yürütülür
postsve bölümleme özelliği olmadığındanuserIdiyi performans göstermez. - Açıkça belirterek, ile
userIdbölümlenmiş bir kapsayıcıda bu isteği yürüterek performans sorunumuzu çözeceğiz. - Zaten böyle bir kapsayıcımız olduğu ortaya çıktı:
userskapsayıcı!
Bu nedenle, tüm gönderileri users kapsayıcıya çoğaltarak ikinci bir normal dışıleştirme düzeyi sunacağız. Bunu yaparak, gönderilerimizin yalnızca farklı bir boyut boyunca bölümlenmiş bir kopyasını etkili bir şekilde elde ederiz ve bu sayede gönderilerimizin userIdtarafından alınması daha verimli hale gelir.
Kapsayıcı users artık iki tür öğe içeriyor:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Bu örnekte:
- Kullanıcı öğesinde, kullanıcıları gönderilerden ayırmak için bir
typealan kullanıma sunulmuştur. - Ayrıca, kullanıcı öğesine, alanla
idyedekli olan ancak kapsayıcı artık (daha önce olduğu gibi değilid) ileuserIdbölümlendiğindenusersgerekli olan biruserIdalan ekledik
Bu normalden çıkarma işlemini gerçekleştirmek için değişiklik akışını bir kez daha kullanırız. Bu kez, kapsayıcıya yeni veya güncelleştirilmiş herhangi bir gönderi göndermek için kapsayıcının değişiklik akışına posts users tepki gösteririz. Gönderileri listelemek için içeriklerinin tamamının döndürülmesi gerekmediğinden, bu süreçte bunları kesebiliriz.
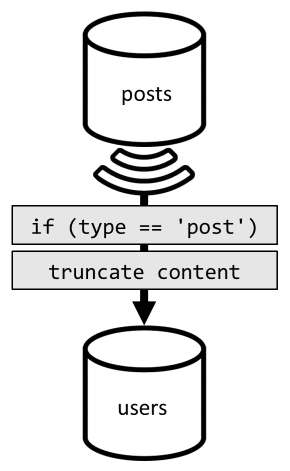
Artık sorgumuzu kapsayıcının users bölüm anahtarına göre filtreleyerek kapsayıcıya yönlendirebiliriz.

| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
4 Ms |
6.46 RU |
✅ |
[Q6] Kısa formda (akış) oluşturulan en son x gönderiyi listeleme
Burada benzer bir durumla ilgilenmemiz gerekir: V2'de kullanıma sunulan normal dışı bırakma işlemiyle gereksiz bırakılan sorguların sayısı azaldıktan sonra bile, kalan sorgu kapsayıcının bölüm anahtarına filtre uygulamaz:
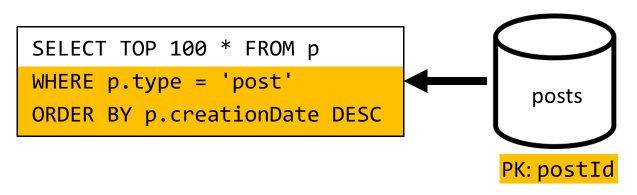
Aynı yaklaşımı izleyerek bu isteğin performansını ve ölçeklenebilirliğini en üst düzeye çıkarmak yalnızca bir bölüme isabet eder. Yalnızca sınırlı sayıda öğe döndürmemiz gerektiğinden tek bir bölüme isabet etmek mümkündür. Blog platformumuzun giriş sayfasını doldurmak için, veri kümesinin tamamında sayfalandırmaya gerek kalmadan en son 100 gönderiyi almalıyız.
Bu nedenle, bu son isteği iyileştirmek için tasarımımıza tamamen bu isteği sunmayı adanmış üçüncü bir kapsayıcı tanıtacağız. Gönderilerimizi bu yeni feed kapsayıcıya normalleştiriyoruz:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
alanı type , her zaman post öğelerimizde olan bu kapsayıcıyı bölümler. Bunu yapmak, bu kapsayıcıdaki tüm öğelerin aynı bölümde olmasını sağlar.
Normal dışıleştirmeyi başarmak için, gönderileri bu yeni kapsayıcıya göndermek için daha önce sunduğumuz değişiklik akışı işlem hattına bağlanmamız gerekir. Aklınızda bulundurmanız gereken önemli noktalardan biri, yalnızca en son 100 gönderiyi sakladığımızdan emin olmamız gerektiğidir; aksi takdirde, kapsayıcının içeriği bir bölümün boyutu üst sınırını aşabilir. Bu sınırlama, kapsayıcıya her belge eklendiğinde bir son tetikleyici çağrılarak uygulanabilir:
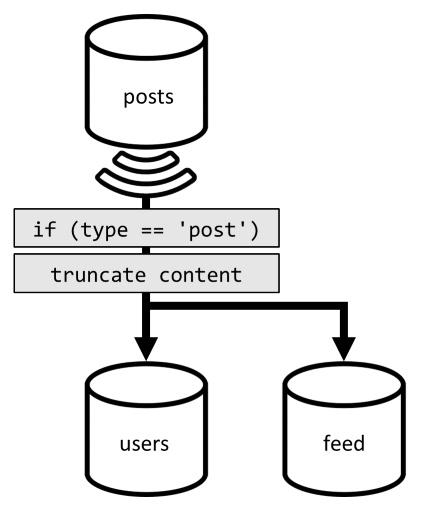
Koleksiyonu kesen son tetikleyicinin gövdesi aşağıdadır:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Son adım sorgumuzu yeni feed kapsayıcımıza yeniden yönlendirmektir:
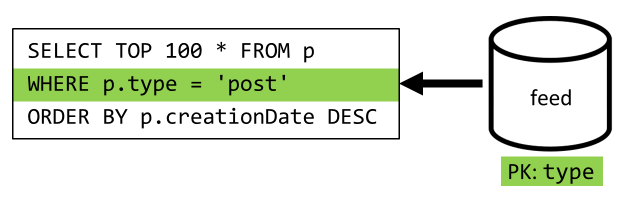
| Gecikme süresi | RU ücreti | Performans |
|---|---|---|
9 Ms |
16.97 RU |
✅ |
Sonuç
Şimdi tasarımımızın farklı sürümleri üzerinde sunduğumuz genel performans ve ölçeklenebilirlik geliştirmelerine göz atalım.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [S1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Yoğun okuma senaryolarını iyileştirdik
Yazma istekleri (komutlar) pahasına okuma isteklerinin (sorguların) performansını artırmaya yönelik çalışmalarımızı yoğunlaştığımızı fark etmiş olabilirsiniz. Çoğu durumda, yazma işlemleri artık değişiklik akışları aracılığıyla sonraki normalleştirmeyi tetikler ve bu da işlem açısından daha pahalı ve gerçekleştirilmesi daha uzun sürer.
Bir bloglama platformunun (çoğu sosyal uygulama gibi) okuma performansına odaklanmasını gerekçelendiriyoruz. Yoğun okuma içeren bir iş yükü, hizmet vermesi gereken okuma isteği miktarının genellikle yazma isteği sayısından daha yüksek olan siparişler olduğunu gösterir. Bu nedenle, okuma isteklerinin daha ucuz ve daha iyi performans göstermesini sağlamak için yazma isteklerinin yürütülmesini daha pahalı hale getirmek mantıklıdır.
Yaptığımız en aşırı iyileştirmeye bakacak olursak [ Q6] 2000'den fazla RU'dan yalnızca 17 RU'ya geçti; gönderileri öğe başına yaklaşık 10 RU maliyetle normal dışı bırakarak bunu başardık. Gönderilerin oluşturulmasından veya güncelleştirilmesinden çok daha fazla akış isteğinde bulunacağımızdan, genel tasarruf dikkate alındığında bu normal dışıleştirmenin maliyeti göz ardı edilebilir.
Normalleştirme artımlı olarak uygulanabilir
Bu makalede incelediğimiz ölçeklenebilirlik iyileştirmeleri, verilerin veri kümesi genelinde normal dışı bırakma ve yinelenenleri kaldırmayı içerir. Bu iyileştirmelerin 1. günde yerine getirilmesi gerekmediği belirtilmelidir. Bölüm anahtarları üzerinde filtre uygulayan sorgular büyük ölçekte daha iyi performans gösterir, ancak bölümler arası sorgular nadiren veya sınırlı bir veri kümesine karşı çağrılırsa kabul edilebilir. Yalnızca bir prototip oluşturuyorsanız veya küçük ve denetimli bir kullanıcı tabanına sahip bir ürün piyasaya sürülüyorsanız, büyük olasılıkla bu iyileştirmeleri daha sonraya bırakabilirsiniz. O zaman önemli olan modelinizin performansını izlemektir; böylece bunları ne zaman ve ne zaman getirebileceğinize karar verebilirsiniz.
Güncelleştirmeleri diğer kapsayıcılara dağıtmak için kullandığımız değişiklik akışı, tüm bu güncelleştirmeleri kalıcı olarak depolar. Bu kalıcılık, sisteminizde zaten çok fazla veri olsa bile kapsayıcı ve bootstrap normalleştirilmiş görünümler tek seferlik bir yakalama işlemi olarak oluşturulduğundan bu yana tüm güncelleştirmelerin istenmesini mümkün kılar.
Sonraki adımlar
Pratik veri modellemeye ve bölümlemeye giriş yaptıktan sonra, ele aldığımız kavramları gözden geçirmek için aşağıdaki makaleleri gözden geçirmek isteyebilirsiniz: